

How to implement speech recognition and speech synthesis in C++?


How to implement speech recognition and speech synthesis in C?
Speech recognition and speech synthesis are one of the popular research directions in the field of artificial intelligence today, and they play an important role in many application scenarios. This article will introduce how to use C to implement speech recognition and speech synthesis functions based on Baidu AI open platform, and provide relevant code examples.
1. Speech recognition
Speech recognition is a technology that converts human speech into text. It is widely used in voice assistants, smart homes, autonomous driving and other fields. The following is a sample code for speech recognition using C:
#include <iostream>
#include <string>
#include "bd_asr.h"
int main() {
std::string api_key = "your_api_key"; // 替换为自己的API Key
std::string secret_key = "your_secret_key"; // 替换为自己的Secret Key
// 创建语音识别对象
bd_asr::ASR asr(api_key, secret_key);
// 设置识别参数
asr.setFormat("pcm"); // 输入语音格式为pcm
asr.setRate(16000); // 采样率为16000Hz
// 识别语音
std::string result = asr.recognize("audio.pcm"); // 替换为自己的语音文件路径
// 输出识别结果
std::cout << "识别结果:" << result << std::endl;
return 0;
} In the above example, we first need to replace api_key and secret_key, which are provided by Baidu AI Open Platform API Key and Secret Key for authentication. Then create an ASR object, set the recognized input speech format and sampling rate, and finally call the recognize method to perform speech recognition and print the results.
2. Speech synthesis
Speech synthesis is a technology that converts text into human voice. It is widely used in speech engines, intelligent customer service, education and other fields. The following is a sample code for speech synthesis using C:
#include <iostream>
#include <string>
#include "bd_tts.h"
int main() {
std::string api_key = "your_api_key"; // 替换为自己的API Key
std::string secret_key = "your_secret_key"; // 替换为自己的Secret Key
// 创建语音合成对象
bd_tts::TTS tts(api_key, secret_key);
// 设置合成参数
tts.setSpeaker(0); // 设置发音人为度小宇
tts.setSpeed(5); // 设置语速为正常
tts.setVolume(5); // 设置音量为正常
// 合成语音
std::string result = tts.synthesize("你好,欢迎使用百度语音合成!"); // 替换为自己的合成文本
// 保存合成语音到文件
tts.save(result, "output.mp3"); // 替换为自己的保存路径
std::cout << "语音合成完成!" << std::endl;
return 0;
}In the above example, we also need to replace api_key and secret_key, and then create a TTS object, set the synthesized speaker, speaking speed and volume, and finally call the synthesize method to perform speech synthesis and save the synthesis result to a file.
Through the above code examples, we can briefly understand how to implement speech recognition and speech synthesis functions in C. Of course, in actual development, we also need to consider some other factors, such as audio stream processing, error handling, etc. I hope this article will be helpful to readers further exploring the world of speech recognition and speech synthesis.
The above is the detailed content of How to implement speech recognition and speech synthesis in C++?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1376
1376
 52
52

 How to forward WeChat voice messages How to forward WeChat voice messages
Feb 22, 2024 pm 05:30 PM
How to forward WeChat voice messages How to forward WeChat voice messages
Feb 22, 2024 pm 05:30 PM
Just convert your voice into notes and send them to others. Tutorial Applicable Model: iPhone13 System: iOS15.5 Version: WeChat 8.0.7 Analysis 1 First add the voice message to the collection, and then open the voice on the collection page. 2 Click the three dots in the upper right corner of the voice interface. 3 Then click Save as Notes in the list below. 4Finally, click Send to Friends on the note interface. Supplement: How to convert WeChat voice to text 1. First, long press the voice you want to convert on the WeChat chat interface. 2 Then click Convert to text in the pop-up window. 3Finally, the voice is converted into text. Summary/Notes WeChat voice messages cannot be forwarded directly and need to be converted into notes first.
 Why can't I hear the sound on WeChat Voice? What should I do if I can't hear the sound on WeChat Voice?
Mar 13, 2024 pm 02:31 PM
Why can't I hear the sound on WeChat Voice? What should I do if I can't hear the sound on WeChat Voice?
Mar 13, 2024 pm 02:31 PM
Why can’t I hear the sound on WeChat Voice? WeChat is an indispensable communication tool in our daily lives. Many users have encountered problems during use. For example, cannot hear the sound in WeChat voice? So what to do? Now let this site give users a detailed introduction to what to do if you can’t hear the sound in WeChat voice. What should I do if I can’t hear the sound in WeChat voice? 1. The sound set by the mobile phone system is relatively low or in a mute state. In this case, you can increase the volume or turn off the silent mode. 2. It is also possible that the WeChat speaker function is not turned on. Open "Settings" and select "Chat" option. 3. After clicking the "Chat" option
 How to make your voice clearer during calls on iPhone 15
Nov 17, 2023 pm 12:18 PM
How to make your voice clearer during calls on iPhone 15
Nov 17, 2023 pm 12:18 PM
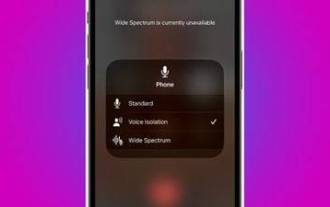
Apple's iPhones include a calling feature that allows your voice to come through more clearly to the person you're talking to during a call, even in busy environments. It's called voice isolation, and here's how it works. In iOS15 and later, Apple has included several features to make video conferencing using FaceTime and other video calling apps more attractive on iPhone. One of the features, called Voice Isolation, makes it easier for people to hear you on video calls, and on devices running iOS 16.4 and above, it also works on regular phone calls. When you're on a call, your device's microphone typically picks up a variety of sounds in the environment, but with voice isolation, machine learning can differentiate between these
 How to set the ringtone for voice and video calls on WeChat Android version in 4 simple steps
Dec 30, 2023 pm 01:49 PM
How to set the ringtone for voice and video calls on WeChat Android version in 4 simple steps
Dec 30, 2023 pm 01:49 PM
In our daily life and work, using WeChat for simple and important communication has become something that everyone will encounter. At the same time, WeChat has also become an indispensable communication tool in our lives. Recently, some friends using the Android version of WeChat encountered a problem. When you make a WeChat call to a friend, not only can you hear the friend's incoming call ringtone, but the friend's WeChat call ringtone is different from other people's, and is no longer a monotonous and boring unified ringtone. So, how to set the ringtone for voice and video calls on the Android version of WeChat? Download The editor of this website will introduce the specific method to you. I hope it will be helpful to friends who have this need. How to set the ringtone for incoming calls in the WeChat Android version? Open the WeChat interface, find the [Me] option and click to enter, then find the [Settings] option
 What to do if the WeChat voice call on your Xiaomi phone doesn't ring
Mar 02, 2024 am 11:40 AM
What to do if the WeChat voice call on your Xiaomi phone doesn't ring
Mar 02, 2024 am 11:40 AM
What should I do if the WeChat voice call on Xiaomi mobile phone does not ring? In Xiaomi mobile phones, WeChat phone calls do not ring. However, most users do not know how to solve the problem of WeChat phone not ringing on Xiaomi mobile phones. Next, the editor will provide users with Xiaomi mobile phone WeChat voice call does not ring tutorial, interested users come and take a look! What to do if the WeChat voice call on Xiaomi mobile phone does not ring. 1. First open the WeChat APP on Xiaomi mobile phone, enter the main page, click [Me] in the lower right corner and select [Settings]; 2. Then click the [New Message Notification] function in the settings page; 3. Finally, jump to the page below and slide [Voice and Video Call Reminder] to solve the problem.
 How to implement speech recognition and speech synthesis in C++?
Aug 26, 2023 pm 02:49 PM
How to implement speech recognition and speech synthesis in C++?
Aug 26, 2023 pm 02:49 PM
How to implement speech recognition and speech synthesis in C++? Speech recognition and speech synthesis are one of the popular research directions in the field of artificial intelligence today, and they play an important role in many application scenarios. This article will introduce how to use C++ to implement speech recognition and speech synthesis functions based on Baidu AI open platform, and provide relevant code examples. 1. Speech recognition Speech recognition is a technology that converts human speech into text. It is widely used in voice assistants, smart homes, autonomous driving and other fields. The following is the implementation of speech recognition using C++
 How to fix WeChat voice sending failure? How to solve the problem of WeChat voice sending
Jan 01, 2024 pm 12:19 PM
How to fix WeChat voice sending failure? How to solve the problem of WeChat voice sending
Jan 01, 2024 pm 12:19 PM
When using WeChat, a chat software, many people will encounter the problem of being unable to send or receive WeChat voices. Below, this article will introduce you to some solutions. If you are interested in this, follow the editor to take a look at the solution to the problem that WeChat voice cannot be sent. First, open the settings on your phone. Then, click on Privacy Options. In the page that opens, find the Microphone option and click on it. Next, click the switch button behind WeChat. In this way, WeChat can send voice messages. How to forward WeChat voice messages. First, you need to find the WeChat voice message you want to forward. Then, press and hold the WeChat voice message, and a forwarding option will appear. Next, click the forward option and find the WeChat friend you want to forward to in the WeChat address book. Finally, open the WeChat friend’s
 Face detection and recognition technology implemented using Java
Jun 18, 2023 am 09:08 AM
Face detection and recognition technology implemented using Java
Jun 18, 2023 am 09:08 AM
With the continuous development of artificial intelligence technology, face detection and recognition technology has become more and more widely used in daily life. Face detection and recognition technologies are widely used in various occasions, such as face access control systems, face payment systems, face search engines, etc. As a widely used programming language, Java can also implement face detection and recognition technology. This article will introduce how to use Java to implement face detection and recognition technology. 1. Face detection technology Face detection technology refers to the technology that detects faces in images or videos. in J
