

How to deal with data statistics issues in C++ big data development?


How to deal with data statistics problems in C big data development?
With the advent of the big data era, data statistics has become indispensable in various fields part. In C big data development, we often need to perform statistical analysis on large amounts of data in order to obtain useful information and insights. This article will introduce some methods of handling data statistics problems in C big data development and provide corresponding code examples.
- Use STL library for data statistics
C The STL (Standard Template Library) in the C standard library contains various template classes and functions for containers and algorithms. Data can be stored and processed conveniently. Here is a simple example that shows how to use vector containers and arithmetic functions from the STL library to calculate the sum, average and maximum of a set of integers:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
- Use third-party libraries for efficiency Data statistics
In addition to the STL library, C also has many third-party libraries that can be used to perform data statistics more efficiently. For example, the Boost library provides a wealth of mathematical and statistical functions that can easily perform various statistical calculations. The following is an example of using the Boost library for linear regression analysis:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
- Parallel computing to accelerate data statistics
In big data development, the amount of data is often very large, and a single Threaded calculations may be too slow. Using parallel computing technology can improve the speed of data statistics. There are libraries in C that enable parallel computing, such as OpenMP and TBB. The following is an example of using the OpenMP library for parallel summation:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
The above example shows how to handle data statistics problems in C big data development by using the STL library, third-party libraries, and parallel computing technology. Of course, this is just the tip of the iceberg, C has many other powerful features and tools for statistics. I hope this article can provide some reference and inspiration for readers and help everyone deal with data statistics issues in C big data development more efficiently.
The above is the detailed content of How to deal with data statistics issues in C++ big data development?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1392
1392
 52
36
110
52
36
110

 Reasons why tables are locked in Oracle and how to deal with them
Mar 03, 2024 am 09:36 AM
Reasons why tables are locked in Oracle and how to deal with them
Mar 03, 2024 am 09:36 AM
Reasons for table locking in Oracle and how to deal with it In Oracle database, table locking is a common phenomenon, and there are many reasons for table locking. This article will explore some common reasons why tables are locked, and provide some processing methods and related code examples. 1. Types of locks In the Oracle database, locks are mainly divided into shared locks (SharedLock) and exclusive locks (ExclusiveLock). Shared locks are used for read operations, allowing multiple sessions to read the same resource at the same time.
 JSON processing methods and implementation in C++
Aug 21, 2023 pm 11:58 PM
JSON processing methods and implementation in C++
Aug 21, 2023 pm 11:58 PM
JSON is a lightweight data exchange format that is easy to read and write, as well as easy for machines to parse and generate. Using JSON format makes it easy to transfer data between various systems. In C++, there are many open source JSON libraries for JSON processing. This article will introduce some commonly used JSON processing methods and implementations in C++. JSON processing methods in C++ RapidJSON RapidJSON is a fast C++ JSON parser/generator that provides DOM, SAX and
 How to handle the unavailable rpc server in Win7 system
Jul 19, 2023 pm 04:57 PM
How to handle the unavailable rpc server in Win7 system
Jul 19, 2023 pm 04:57 PM
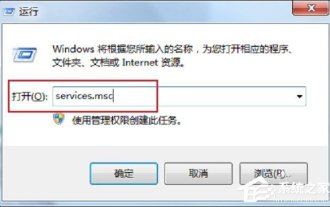
In the process of using computers, we often encounter some problems, some of which can make people overwhelmed. Some users encounter this problem. When they turn on the computer and use the printer, a message that the RPC server is unavailable pops up. What happened? what do I do? In response to this problem, let us share the solution to Win7rpc server being unavailable. 1. Press the Win+R keys to open Run, and enter services.msc in the Run input box. 2. After entering the service list, find the RemoteProcedureCall(RPC)Locator service. 3. Select the service and double-click. The default state is as shown below: 4. Change the startup type of the RPCLoader service to automatic
 How to deal with array out-of-bounds problems in C++ development
Aug 21, 2023 pm 10:04 PM
How to deal with array out-of-bounds problems in C++ development
Aug 21, 2023 pm 10:04 PM
How to deal with the array out-of-bounds problem in C++ development In C++ development, array out-of-bounds is a common error, which can lead to program crashes, data corruption and even security vulnerabilities. Therefore, correctly handling array out-of-bounds problems is an important part of ensuring program quality. This article will introduce some common processing methods and suggestions to help developers avoid array out-of-bounds problems. First, it is key to understand the cause of the array out-of-bounds problem. Array out-of-bounds refers to an index that exceeds its definition range when accessing an array. This usually happens in the following scenario: Negative numbers are used when accessing the array
 How to use PHP functions to process large amounts of data
Jun 16, 2023 am 10:45 AM
How to use PHP functions to process large amounts of data
Jun 16, 2023 am 10:45 AM
With the development of the Internet, we are exposed to large amounts of data every day, which needs to be stored, processed and analyzed. PHP is a server-side scripting language that is widely used today and is also used for large-scale data processing. When processing large-scale data, it is easy to face memory overflow and performance bottlenecks. This article will introduce how to use PHP functions to process large amounts of data. 1. Turn on memory limit By default, PHP’s memory limit size is 128M, which may become a problem when processing large amounts of data. To handle larger
 What to do if MySQL connection error 1017 occurs?
Jun 30, 2023 am 11:57 AM
What to do if MySQL connection error 1017 occurs?
Jun 30, 2023 am 11:57 AM
How to deal with MySQL connection error 1017? MySQL is an open source relational database management system that is widely used in website development and data storage. However, when using MySQL, you may encounter a variety of errors. One of the common errors is connection error 1017 (MySQL error code 1017). Connection error 1017 indicates a database connection failure, usually caused by an incorrect username or password. When MySQL fails to authenticate using the provided username and password
 How to solve QQ remote desktop connection problems
Dec 26, 2023 am 11:55 AM
How to solve QQ remote desktop connection problems
Dec 26, 2023 am 11:55 AM
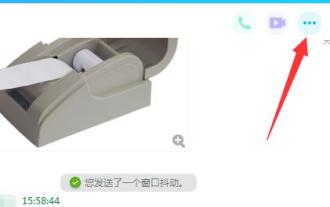
QQ is a chat software produced by Tencent. Almost everyone has a QQ account and can remotely connect and operate when chatting. However, some users encounter the problem of being unable to connect, so what should they do? Let’s take a look below. What to do if QQ Remote Desktop cannot connect: 1. Open the chat interface, click the "..." icon in the upper right corner 2. Select the red computer icon and click "Settings" 3. Click "Set Permissions—>Remote Desktop" 4. Check "Allow Remote Desktop to connect to this computer"
 How to deal with cross-domain request issues in PHP development
Jun 29, 2023 am 08:31 AM
How to deal with cross-domain request issues in PHP development
Jun 29, 2023 am 08:31 AM
How to deal with cross-domain request issues in PHP development In web development, cross-domain requests are a common problem. When the Javascript code in a web page initiates an HTTP request to access resources under different domain names, a cross-domain request occurs. Cross-domain requests are restricted by the browser's Same-Origin Policy, so in PHP development, we need to take some measures to deal with cross-domain request issues. Using a proxy server to forward requests is a common way to handle cross-domain
