

Boruvka algorithm in C++ for minimum spanning tree


In graph theory, finding the minimum spanning tree (MST) of a connected weighted graph is a common problem. MST is a subset of graph edges that connects all vertices and minimizes the total edge weight. An efficient algorithm to solve this problem is Boruvka algorithm.
grammar
1 2 3 4 5 6 7 8 |
|
algorithm
Now, let us outline the steps involved in finding the minimum spanning tree in the Boruvka algorithm −
Initialize MST to the empty set.
Create a subset for each vertex, where each subset contains only one vertex.
Repeat the following steps until the minimum spanning tree (MST) has V-1 edges (V is the number of vertices in the graph) −
For each subset, find the cheapest edge connecting it to the other subset.
Add selected edges to the minimum spanning tree.
Perform a union operation on a subset of selected edges.
Output the minimum spanning tree.
method
In the Boruvka algorithm, there are multiple ways to find the cheapest edge connecting each subset. The following are two common methods −
Method 1: Simple method
For each subset, traverse all edges and find the smallest edge connecting it to another subset.
Track selected edges and perform joint operations.
Example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 |
|
Output
1 2 3 4 5 6 7 |
|
Explanation
is:Explanation
We first define two structures - Edge and Subset. Edge represents an edge in the graph, including the source, destination and weight of the edge. Subset represents a subset of the union query data structure, including parent and ranking information.
The find function is a helper function that uses path compression to find a subset of elements. It recursively finds the representatives (parent nodes) of the subset to which the element belongs and compresses the path to optimize future queries.
The unionSets function is another auxiliary function that uses rank-based merging to merge two subsets. It finds representatives of two subsets and merges them based on rank to maintain a balanced tree.
The boruvkaMST function takes as input an edge vector and a number of vertices (V). It implements Boruvka algorithm to find MST.
Inside the boruvkaMST function, we create a vector selectedEdges to store the edges of MST.
We create an array of Subset structures to represent subsets and initialize them with default values.
We also create an array cheapest to keep track of the cheapest edge for each subset.
The variable numTrees is initialized to the number of vertices, and MSTWeight is initialized to 0.
The algorithm proceeds by repeatedly combining components until all components are in a tree. The main loop runs until numTrees becomes 1.
In each iteration of the main loop, we iterate over all edges and find the minimum weighted edge for each subset. If an edge connects two different subsets, we update the cheapest array with the index of the least weighted edge.
Next, we traverse all subsets. If a subset has an edge with minimum weight, we add it to the selectedEdges vector, update MSTWeight, perform the union operation of the subsets, and reduce the value of numTrees.
Finally, we output the MST weights and selected edges.
The main function prompts the user to enter the number of vertices and edges. It then takes the input (source, target, weight) for each edge and calls the boruvkaMST function with the input.
Method 2: Use priority queue
Create a priority queue sorted by weight to store edges.
For each subset, find the minimum weight edge connecting it to another subset from the priority queue.
Track selected edges and perform joint operations.
Example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
|
Output
1 2 3 4 5 |
|
Explanation
is:Explanation
In this approach, we use a priority queue to optimize the process of finding the minimum weighted edge for each subset. The following is a detailed explanation of the code −
The code structure and helper functions (such as find and unionSets) remain the same as the previous method.
The boruvkaMST function is modified to use a priority queue to efficiently find the minimum weighted edge for each subset.
Instead of using the cheapest array, we now create a edge priority queue (pq). We initialize it with the edges of the graph.
The main loop runs until numTrees becomes 1, similar to the previous method.
In each iteration, we extract the minimum weight edge (minEdge) from the priority queue.
Then we use the find function to find the subset to which the source and target of minEdge belong.
If the subsets are different, we add minEdge to the selectedEdges vector, update MSTWeight, perform a merge of the subsets, and reduce numTrees.
The process will continue until all components are in a tree.
Finally, we output the MST weights and selected edges.
The main functionality is the same as the previous method, we have predefined inputs for testing purposes.
in conclusion
Boruvka's algorithm provides an efficient solution for finding the minimum spanning tree of a weighted graph. Our team explored two different paths in depth when implementing the algorithm in C: a traditional or "naive" approach. Another utilizes priority queues. Depends on the specific requirements of the given problem at hand. Each method has certain advantages and can be implemented accordingly. By understanding and implementing Boruvka's algorithm, you can efficiently solve minimum spanning tree problems in C projects.
The above is the detailed content of Boruvka algorithm in C++ for minimum spanning tree. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1393
1393
 52
1207
24
52
1207
24

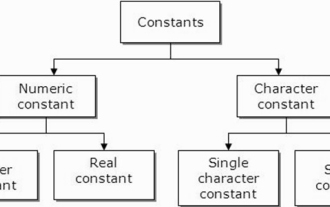 What are constants in C language? Can you give an example?
Aug 28, 2023 pm 10:45 PM
What are constants in C language? Can you give an example?
Aug 28, 2023 pm 10:45 PM
A constant is also called a variable and once defined, its value does not change during the execution of the program. Therefore, we can declare a variable as a constant referencing a fixed value. It is also called text. Constants must be defined using the Const keyword. Syntax The syntax of constants used in C programming language is as follows - consttypeVariableName; (or) consttype*VariableName; Different types of constants The different types of constants used in C programming language are as follows: Integer constants - For example: 1,0,34, 4567 Floating point constants - Example: 0.0, 156.89, 23.456 Octal and Hexadecimal constants - Example: Hex: 0x2a, 0xaa.. Octal
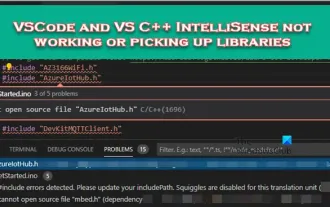 VSCode and VS C++ IntelliSense not working or picking up libraries
Feb 29, 2024 pm 01:28 PM
VSCode and VS C++ IntelliSense not working or picking up libraries
Feb 29, 2024 pm 01:28 PM
VS Code and Visual Studio C++ IntelliSense may not be able to pick up libraries, especially when working on large projects. When we hover over #Include<wx/wx.h>, we see the error message "CannotOpen source file 'string.h'" (depends on "wx/wx.h") and sometimes, autocomplete Function is unresponsive. In this article we will see what you can do if VSCode and VSC++ IntelliSense are not working or extracting libraries. Why doesn't my Intellisense work in C++? When working with large files, IntelliSense sometimes
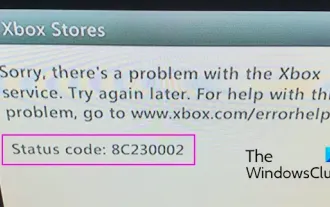 Fix Xbox error code 8C230002
Feb 27, 2024 pm 03:55 PM
Fix Xbox error code 8C230002
Feb 27, 2024 pm 03:55 PM
Are you unable to purchase or watch content on your Xbox due to error code 8C230002? Some users keep getting this error when trying to purchase or watch content on their console. Sorry, there's a problem with the Xbox service. Try again later. For help with this issue, visit www.xbox.com/errorhelp. Status Code: 8C230002 This error code is usually caused by temporary server or network problems. However, there may be other reasons, such as your account's privacy settings or parental controls, that may prevent you from purchasing or viewing specific content. Fix Xbox Error Code 8C230002 If you receive error code 8C when trying to watch or purchase content on your Xbox console
 Recursive program to find minimum and maximum elements of array in C++
Aug 31, 2023 pm 07:37 PM
Recursive program to find minimum and maximum elements of array in C++
Aug 31, 2023 pm 07:37 PM
We take the integer array Arr[] as input. The goal is to find the largest and smallest elements in an array using a recursive method. Since we are using recursion, we will iterate through the entire array until we reach length = 1 and then return A[0], which forms the base case. Otherwise, the current element is compared to the current minimum or maximum value and its value is updated recursively for subsequent elements. Let’s look at various input and output scenarios for this −Input −Arr={12,67,99,76,32}; Output −Maximum value in the array: 99 Explanation &mi
 How to use Prim's algorithm in C++
Sep 20, 2023 pm 12:31 PM
How to use Prim's algorithm in C++
Sep 20, 2023 pm 12:31 PM
Title: Use of Prim algorithm and code examples in C++ Introduction: Prim algorithm is a commonly used minimum spanning tree algorithm, mainly used to solve the minimum spanning tree problem in graph theory. In C++, Prim's algorithm can be used effectively through reasonable data structures and algorithm implementation. This article will introduce how to use Prim's algorithm in C++ and provide specific code examples. 1. Introduction to Prim algorithm Prim algorithm is a greedy algorithm. It starts from a vertex and gradually expands the vertex set of the minimum spanning tree until it contains
 China Eastern Airlines announces that C919 passenger aircraft will soon be put into actual operation
May 28, 2023 pm 11:43 PM
China Eastern Airlines announces that C919 passenger aircraft will soon be put into actual operation
May 28, 2023 pm 11:43 PM
According to news on May 25, China Eastern Airlines disclosed the latest progress on the C919 passenger aircraft at the performance briefing meeting. According to the company, the C919 purchase agreement signed with COMAC has officially come into effect in March 2021, and the first C919 aircraft has been delivered by the end of 2022. It is expected that the aircraft will be officially put into actual operation soon. China Eastern Airlines will use Shanghai as its main base for commercial operations of the C919, and plans to introduce a total of five C919 passenger aircraft in 2022 and 2023. The company stated that future introduction plans will be determined based on actual operating conditions and route network planning. According to the editor's understanding, the C919 is China's new generation of single-aisle mainline passenger aircraft with completely independent intellectual property rights in the world, and it complies with internationally accepted airworthiness standards. Should
 C++ program to print spiral pattern of numbers
Sep 05, 2023 pm 06:25 PM
C++ program to print spiral pattern of numbers
Sep 05, 2023 pm 06:25 PM
Displaying numbers in different formats is one of the basic coding problems of learning. Different coding concepts like conditional statements and loop statements. There are different programs in which we use special characters like asterisks to print triangles or squares. In this article, we will print numbers in spiral form, just like squares in C++. We take the number of rows n as input and start from the top left corner and move to the right, then down, then left, then up, then right again, and so on and so on. Spiral pattern with numbers 123456724252627282982340414243309223948494431102138474645321120373635343312191817161514
 The function of void keyword in C language
Feb 19, 2024 pm 11:33 PM
The function of void keyword in C language
Feb 19, 2024 pm 11:33 PM
void in C is a special keyword used to represent an empty type, which means data without a specific type. In C language, void is usually used in the following three aspects. The function return type is void. In C language, functions can have different return types, such as int, float, char, etc. However, if the function does not return any value, the return type can be set to void. This means that after the function is executed, it does not return a specific value. For example: voidhelloWorld()
