

Using the Requests module in Python

Requests is a Python module that can be used to send various HTTP requests. It is an easy-to-use library with many features, from passing parameters in URLs to sending custom headers and SSL verification. In this tutorial, you will learn how to use this library to send simple HTTP requests in Python.
You can use requests in Python versions 2.6–2.7 and 3.3–3.6. Before continuing, you should know that Requests is an external module, so you must install it before trying the examples in this tutorial. You can install it by running the following command in the terminal:
pip install requests
After installing the module, you can use the following command to import the module to verify whether it has been successfully installed:
import requests
If the installation is successful, you will not see any error message.
Issuing a GET request
Sending HTTP requests is very easy using Requests. You import the module first and then make the request. Here is an example:
import requests
req = requests.get('https://tutsplus.com/')
All information about our request is now stored in a response object named req. For example, you can use the req.encoding property to get the encoding of a web page. You can also get the status code of a request using the req.status_code property.
req.encoding # returns 'utf-8' req.status_code # returns 200
You can access the cookies sent back by the server using req.cookies. Likewise, you can use req.headers to get the response headers. req.headers Property returns a case-insensitive dictionary of response headers. This means req.headers['Content-Length'], req.headers['content-length'] and req. headers['CONTENT-LENGTH'] will return the value of 'Content-Length' response header.
You can check whether the response is a well-formed HTTP redirect, which can be handled automatically using the req.is_redirect property. It will return True or False depending on the response. You can also use the req.elapsed property to get the time elapsed between sending the request and getting the response.
The URL you initially pass to the get() function may differ from the final URL of the response for a number of reasons, including redirects. To view the final response URL, you can use the req.url property.
import requests
req = requests.get('https://www.tutsplus.com/')
req.encoding # returns 'utf-8'
req.status_code # returns 200
req.elapsed # returns datetime.timedelta(0, 1, 666890)
req.url # returns 'https://tutsplus.com/'
req.history
# returns [<Response [301]>, <Response [301]>]
req.headers['Content-Type']
# returns 'text/html; charset=utf-8'
It's great to have all this information about the web page you're visiting, but you'll most likely want to access the actual content. If the content you are accessing is text, you can use the req.text property to access it. The content is then parsed into unicode. You can pass the encoding used to decode the text using the req.encoding property.
For non-text responses, you can access them in binary form using req.content. This module will automatically decode gzip and deflate transfer encodings. This can be helpful when you're working with media files. Likewise, you can use req.json() to access the json-encoded content of the response, if present.
You can also use req.raw to get the raw response from the server. Remember, you must pass stream=True in the request to get the raw response.
Some files you download from the Internet using the requests module may be large. In this case, it is unwise to load the entire response or file into memory immediately. You can download the file in chunks or chunks using the iter_content(chunk_size = 1,decode_unicode=False) method.
This method iterates the response data in chunk_size bytes at a time. This method will avoid reading the entire file into memory at once for a large response when stream=True is set on the request. chunk_size The parameter can be an integer or None. When set to an integer value, chunk_size determines the number of bytes that should be read into memory.
When chunk_size is set to None and stream is set to True, data will be read in whatever chunk is received No matter the size, it will arrive. When chunk_size is set to None and stream is set to False , all data is returned as a single chunk.
Let’s use the requests module to download some images of mushrooms. This is the actual image:

This is the code you need:
import requests
req = requests.get('path/to/mushrooms.jpg', stream=True)
req.raise_for_status()
with open('mushrooms.jpg', 'wb') as fd:
for chunk in req.iter_content(chunk_size=50000):
print('Received a Chunk')
fd.write(chunk)
'path/to/mushrooms.jpg' 是实际的图像 URL。您可以将任何其他图像的 URL 放在这里来下载其他内容。给定的图像文件大小为 162kb,并且您已将 chunk_size 设置为 50,000 字节。这意味着“Received a Chunk”消息应在终端中打印四次。最后一个块的大小将仅为 32350 字节,因为前三次迭代后仍待接收的文件部分为 32350 字节。
您还可以用类似的方式下载视频。我们可以简单地将其值设置为 None,而不是指定固定的 chunk_size,然后视频将以提供的任何块大小下载。以下代码片段将从 Mixkit 下载高速公路的视频:
import requests
req = requests.get('path/to/highway/video.mp4', stream=True)
req.raise_for_status()
with open('highway.mp4', 'wb') as fd:
for chunk in req.iter_content(chunk_size=None):
print('Received a Chunk')
fd.write(chunk)
尝试运行代码,您将看到视频作为单个块下载。
如果您决定使用 stream 参数,则应记住以下几点。响应正文的下载会被推迟,直到您使用 content 属性实际访问其值。这样,如果某些标头值之一看起来不正确,您就可以避免下载文件。
另请记住,在将流的值设置为 True 时启动的任何连接都不会关闭,除非您消耗所有数据或使用 close() 方法。确保连接始终关闭的更好方法是在 with 语句中发出请求,即使您部分读取了响应,如下所示:
import requests
with requests.get('path/to/highway/video.mp4', stream=True) as rq:
with open('highway.mp4', 'wb') as fd:
for chunk in rq.iter_content(chunk_size=None):
print('Received a Chunk')
fd.write(chunk)
由于我们之前下载的图片文件比较小,您也可以使用以下代码一次性下载:
import requests
req = requests.get('path/to/mushrooms.jpg')
req.raise_for_status()
with open('mushrooms.jpg', 'wb') as fd:
fd.write(req.content)
我们跳过了设置 stream 参数的值,因此默认设置为 False。这意味着所有响应内容将立即下载。借助 content 属性,将响应内容捕获为二进制数据。
请求还允许您在 URL 中传递参数。当您在网页上搜索某些结果(例如特定图像或教程)时,这会很有帮助。您可以使用 GET 请求中的 params 关键字将这些查询字符串作为字符串字典提供。这是一个例子:
import requests
query = {'q': 'Forest', 'order': 'popular', 'min_width': '800', 'min_height': '600'}
req = requests.get('https://pixabay.com/en/photos/', params=query)
req.url
# returns 'https://pixabay.com/en/photos/?order=popular&min_height=600&q=Forest&min_width=800'
发出 POST 请求
发出 POST 请求与发出 GET 请求一样简单。您只需使用 post() 方法而不是 get() 即可。当您自动提交表单时,这会很有用。例如,以下代码将向 httpbin.org 域发送 post 请求,并将响应 JSON 作为文本输出。
import requests
req = requests.post('https://httpbin.org/post', data = {'username': 'monty', 'password': 'something_complicated'})
req.raise_for_status()
print(req.text)
'''
{
"args": {},
"data": "",
"files": {},
"form": {
"password": "something_complicated",
"username": "monty"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "45",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-63ad437e-67f5db6a161314861484f2eb"
},
"json": null,
"origin": "YOUR.IP.ADDRESS",
"url": "https://httpbin.org/post"
}
'''
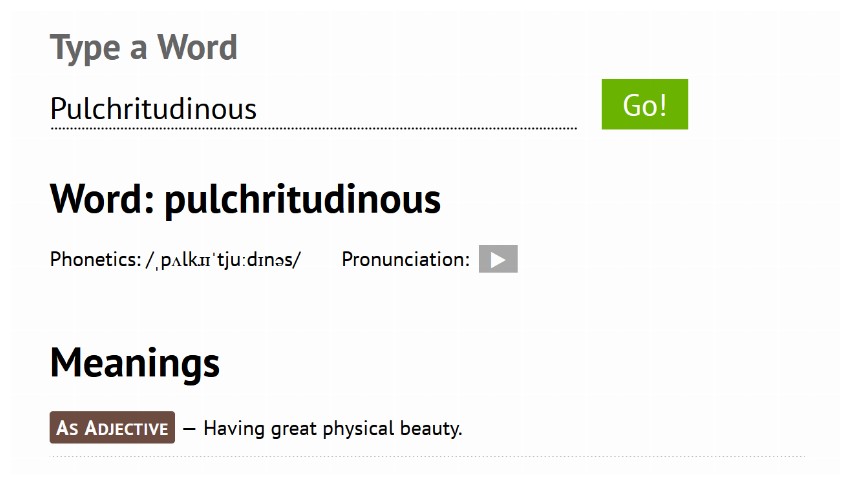
您可以将这些 POST 请求发送到任何可以处理它们的 URL。举个例子,我的一位朋友创建了一个网页,用户可以在其中输入单词并使用 API 获取其含义以及发音和其他信息。我们可以用我们查询的单词向URL发出POST请求,然后将结果保存为HTML页面,如下所示:
import requests
word = 'Pulchritudinous'
filename = word.lower() + '.html'
req = requests.post('https://tutorialio.com/tools/dictionary.php', data = {'query': word})
req.raise_for_status()
with open(filename, 'wb') as fd:
fd.write(req.content)
执行上面的代码,它会返回一个包含该单词信息的页面,如下图所示。
发送 Cookie 和标头
如前所述,您可以使用 req.cookies 和 req.headers 访问服务器发回给您的 cookie 和标头。请求还允许您通过请求发送您自己的自定义 cookie 和标头。当您想要为您的请求设置自定义用户代理时,这会很有帮助。
要将 HTTP 标头添加到请求中,您只需将它们通过 dict 传递到 headers 参数即可。同样,您还可以使用传递给 cookies 参数的 dict 将自己的 cookie 发送到服务器。
import requests
url = 'http://some-domain.com/set/cookies/headers'
headers = {'user-agent': 'your-own-user-agent/0.0.1'}
cookies = {'visit-month': 'February'}
req = requests.get(url, headers=headers, cookies=cookies)
Cookie 也可以在 Cookie Jar 中传递。它们提供了更完整的界面,允许您通过多个路径使用这些 cookie。这是一个例子:
import requests
jar = requests.cookies.RequestsCookieJar()
jar.set('first_cookie', 'first', domain='httpbin.org', path='/cookies')
jar.set('second_cookie', 'second', domain='httpbin.org', path='/extra')
jar.set('third_cookie', 'third', domain='httpbin.org', path='/cookies')
url = 'http://httpbin.org/cookies'
req = requests.get(url, cookies=jar)
req.text
# returns '{ "cookies": { "first_cookie": "first", "third_cookie": "third" }}'
会话对象
有时,在多个请求中保留某些参数很有用。 Session 对象正是这样做的。例如,它将在使用同一会话发出的所有请求中保留 cookie 数据。 Session 对象使用 urllib3 的连接池。这意味着底层 TCP 连接将被重复用于向同一主机发出的所有请求。这可以显着提高性能。您还可以将 Requests 对象的方法与 Session 对象一起使用。
以下是使用和不使用会话发送的多个请求的示例:
import requests
reqOne = requests.get('https://tutsplus.com/')
reqOne.cookies['_tuts_session']
#returns 'cc118d94a84f0ea37c64f14dd868a175'
reqTwo = requests.get('https://code.tutsplus.com/tutorials')
reqTwo.cookies['_tuts_session']
#returns '3775e1f1d7f3448e25881dfc35b8a69a'
ssnOne = requests.Session()
ssnOne.get('https://tutsplus.com/')
ssnOne.cookies['_tuts_session']
#returns '4c3dd2f41d2362108fbb191448eab3b4'
reqThree = ssnOne.get('https://code.tutsplus.com/tutorials')
reqThree.cookies['_tuts_session']
#returns '4c3dd2f41d2362108fbb191448eab3b4'
正如您所看到的,会话cookie在第一个和第二个请求中具有不同的值,但当我们使用Session对象时它具有相同的值。当您尝试此代码时,您将获得不同的值,但在您的情况下,使用会话对象发出的请求的 cookie 将具有相同的值。
当您想要在所有请求中发送相同的数据时,会话也很有用。例如,如果您决定将 cookie 或用户代理标头与所有请求一起发送到给定域,则可以使用 Session 对象。这是一个例子:
import requests
ssn = requests.Session()
ssn.cookies.update({'visit-month': 'February'})
reqOne = ssn.get('http://httpbin.org/cookies')
print(reqOne.text)
# prints information about "visit-month" cookie
reqTwo = ssn.get('http://httpbin.org/cookies', cookies={'visit-year': '2017'})
print(reqTwo.text)
# prints information about "visit-month" and "visit-year" cookie
reqThree = ssn.get('http://httpbin.org/cookies')
print(reqThree.text)
# prints information about "visit-month" cookie
如您所见,"visit-month" 会话 cookie 随所有三个请求一起发送。但是, "visit-year" cookie 仅在第二次请求期间发送。第三个请求中也没有提及 "vist-year" cookie。这证实了单个请求上设置的 cookie 或其他数据不会与其他会话请求一起发送。
结论
本教程中讨论的概念应该可以帮助您通过传递特定标头、cookie 或查询字符串来向服务器发出基本请求。当您尝试抓取网页以获取信息时,这将非常方便。现在,一旦您找出 URL 中的模式,您还应该能够自动从不同的网站下载音乐文件和壁纸。
学习 Python
无论您是刚刚入门还是希望学习新技能的经验丰富的程序员,都可以通过我们完整的 Python 教程指南学习 Python。
The above is the detailed content of Using the Requests module in Python. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
In VS Code, you can run the program in the terminal through the following steps: Prepare the code and open the integrated terminal to ensure that the code directory is consistent with the terminal working directory. Select the run command according to the programming language (such as Python's python your_file_name.py) to check whether it runs successfully and resolve errors. Use the debugger to improve debugging efficiency.
 Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
VS Code can be used to write Python and provides many features that make it an ideal tool for developing Python applications. It allows users to: install Python extensions to get functions such as code completion, syntax highlighting, and debugging. Use the debugger to track code step by step, find and fix errors. Integrate Git for version control. Use code formatting tools to maintain code consistency. Use the Linting tool to spot potential problems ahead of time.
 Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
VS Code extensions pose malicious risks, such as hiding malicious code, exploiting vulnerabilities, and masturbating as legitimate extensions. Methods to identify malicious extensions include: checking publishers, reading comments, checking code, and installing with caution. Security measures also include: security awareness, good habits, regular updates and antivirus software.
 Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
 Python: Automation, Scripting, and Task Management
Apr 16, 2025 am 12:14 AM
Python: Automation, Scripting, and Task Management
Apr 16, 2025 am 12:14 AM
Python excels in automation, scripting, and task management. 1) Automation: File backup is realized through standard libraries such as os and shutil. 2) Script writing: Use the psutil library to monitor system resources. 3) Task management: Use the schedule library to schedule tasks. Python's ease of use and rich library support makes it the preferred tool in these areas.
 What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
VS Code is the full name Visual Studio Code, which is a free and open source cross-platform code editor and development environment developed by Microsoft. It supports a wide range of programming languages and provides syntax highlighting, code automatic completion, code snippets and smart prompts to improve development efficiency. Through a rich extension ecosystem, users can add extensions to specific needs and languages, such as debuggers, code formatting tools, and Git integrations. VS Code also includes an intuitive debugger that helps quickly find and resolve bugs in your code.
 Can visual studio code run python
Apr 15, 2025 pm 08:00 PM
Can visual studio code run python
Apr 15, 2025 pm 08:00 PM
VS Code not only can run Python, but also provides powerful functions, including: automatically identifying Python files after installing Python extensions, providing functions such as code completion, syntax highlighting, and debugging. Relying on the installed Python environment, extensions act as bridge connection editing and Python environment. The debugging functions include setting breakpoints, step-by-step debugging, viewing variable values, and improving debugging efficiency. The integrated terminal supports running complex commands such as unit testing and package management. Supports extended configuration and enhances features such as code formatting, analysis and version control.
 Can vs code run python
Apr 15, 2025 pm 08:21 PM
Can vs code run python
Apr 15, 2025 pm 08:21 PM
Yes, VS Code can run Python code. To run Python efficiently in VS Code, complete the following steps: Install the Python interpreter and configure environment variables. Install the Python extension in VS Code. Run Python code in VS Code's terminal via the command line. Use VS Code's debugging capabilities and code formatting to improve development efficiency. Adopt good programming habits and use performance analysis tools to optimize code performance.
