

Metadata scraping using the New York Times API

简介
上周,我写了一篇关于抓取网页以收集元数据的介绍,并提到不可能抓取《纽约时报》网站。 《纽约时报》付费墙会阻止您收集基本元数据的尝试。但有一种方法可以使用纽约时报 API 来解决这个问题。
最近我开始在 Yii 平台上构建一个社区网站,我将在以后的教程中发布该网站。我希望能够轻松添加与网站内容相关的链接。虽然人们可以轻松地将 URL 粘贴到表单中,但提供标题和来源信息却非常耗时。
因此,在今天的教程中,我将扩展我最近编写的抓取代码,以在添加《纽约时报》链接时利用《纽约时报》API 来收集头条新闻。
请记住,我参与了下面的评论主题,所以请告诉我您的想法!您还可以通过 Twitter @lookahead_io 与我联系。
开始使用
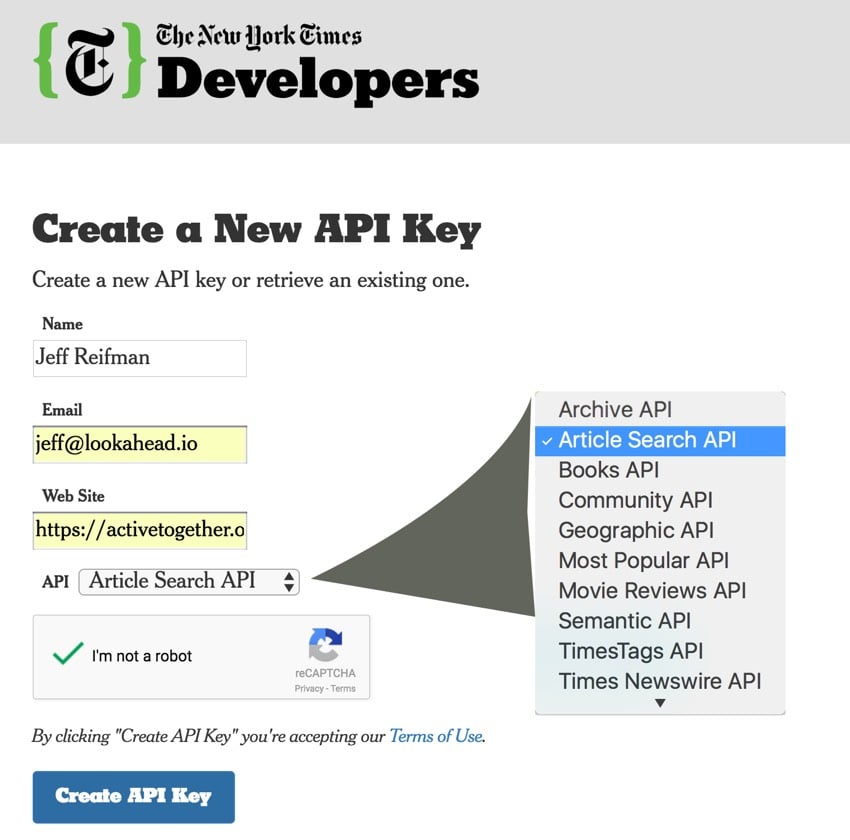
注册 API 密钥

首先,让我们注册并请求 API 密钥:
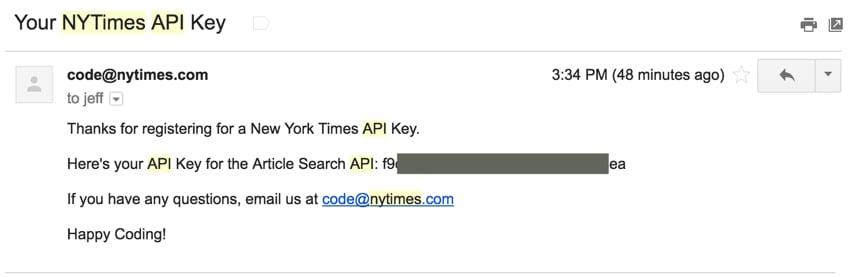
提交表单后,您将通过电子邮件收到密钥:
探索纽约时报 API

The Times 提供以下类别的 API:
- 存档
- 文章搜索
- 书籍
- 社区
- 地理
- 最受欢迎
- 电影评论
- 语义
- 泰晤士报
- 时代标签
- 头条新闻
很多。并且,在“图库”页面中,您可以单击任何主题来查看各个 API 类别文档:
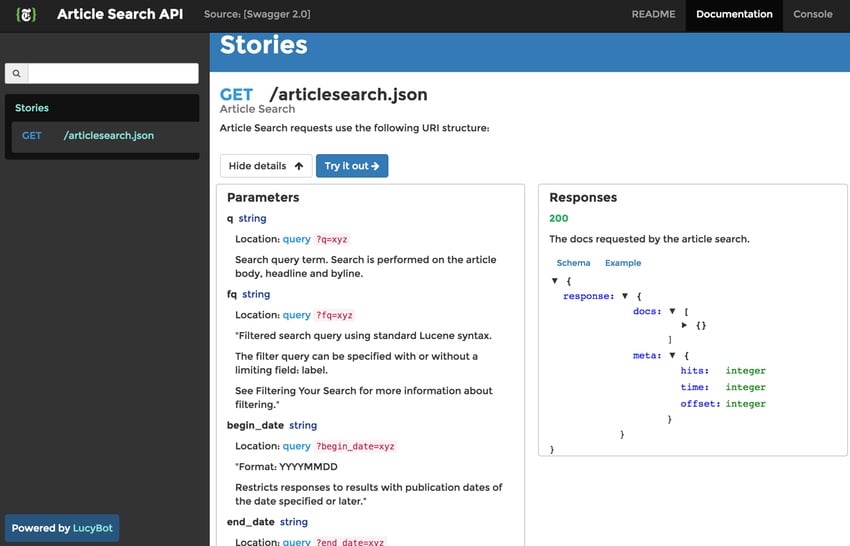
《纽约时报》使用 LucyBot 为其 API 文档提供支持,并且有一个有用的常见问题解答:

他们甚至向您展示如何快速获取 API 使用限制(您需要插入密钥):
curl --head
https://api.nytimes.com/svc/books/v3/lists/overview.json?api-key=<your-api-key>
2>/dev/null | grep -i "X-RateLimit"
X-RateLimit-Limit-day: 1000
X-RateLimit-Limit-second: 5
X-RateLimit-Remaining-day: 180
X-RateLimit-Remaining-second: 5
我最初很难理解该文档 - 它是基于参数的规范,而不是编程指南。不过,我在纽约时报 API GitHub 页面上发布了一些问题,这些问题很快就得到了有用的解答。
使用文章搜索
在今天的节目中,我将重点介绍如何使用《纽约时报》文章搜索。基本上,我们将扩展上一个教程中的创建链接表单:
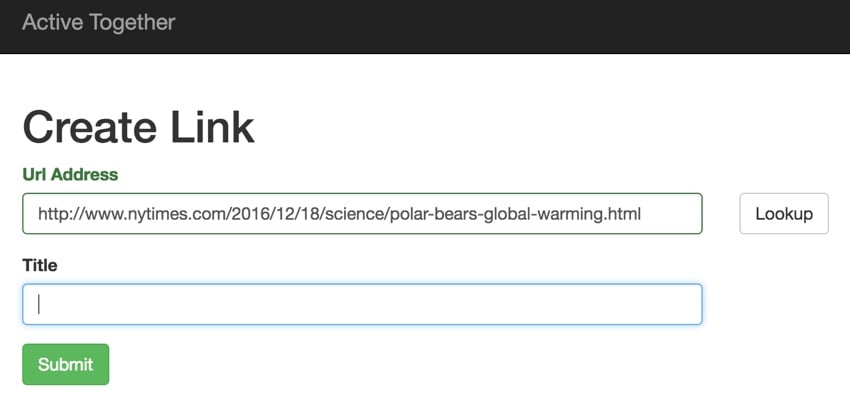
当用户点击查找时,我们将向 链接::grab($url)。这是 jQuery:
$(document).on("click", '[id=lookup]', function(event) {
$.ajax({
url: $('#url_prefix').val()+'/link/grab',
data: {url: $('#url').val()},
success: function(data) {
$('#title').val(data);
return true;
}
});
});
这是控制器和模型方法:
// Controller call via AJAX Lookup request
public static function actionGrab($url) {
Yii::$app->response->format = Response::FORMAT_JSON;
return Link::grab($url);
}
...
// Link::grab() method
public static function grab($url) {
//clean up url for hostname
$source_url = parse_url($url);
$source_url = $source_url['host'];
$source_url=str_ireplace('www.','',$source_url);
$source_url = trim($source_url,' \\');
// use the NYT API when hostname == nytimes.com
if ($source_url=='nytimes.com') {
...
接下来,让我们使用 API 密钥发出文章搜索请求:
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com
/svc/search/v2/articlesearch.json?fl=headline&fq=web_url:%22'.
$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
$title = $result->response->docs[0]->headline->main;
} else {
// not NYT, use the standard metatag scraper from last episode
...
}
}
return $title;
}
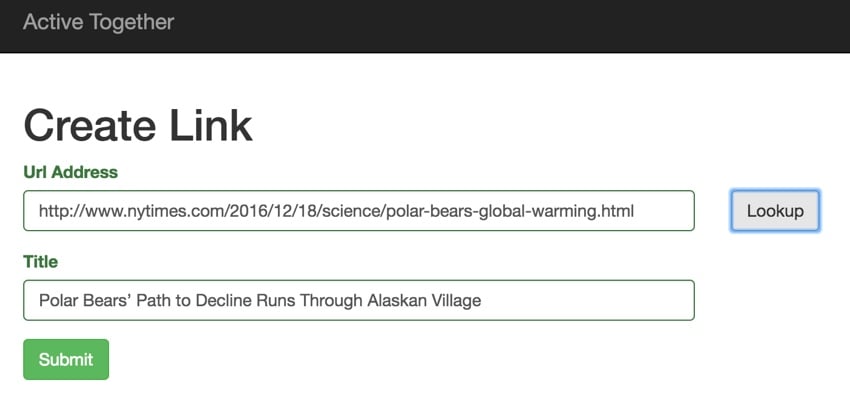
它的工作原理非常简单 - 这是生成的标题(顺便说一句,气候变化正在杀死北极熊,我们应该关心):
如果您想了解 API 请求的更多详细信息,只需向 ?fl 添加其他参数即可=headline 请求例如 关键字 和 lead_paragraph:
Yii::$app->response->format = Response::FORMAT_JSON; $nytKey=Yii::$app->params['nytapi']; $curl_dest = 'http://api.nytimes.com/svc/search/v2/articlesearch.json?'. 'fl=headline,keywords,lead_paragraph&fq=web_url:%22'.$url.'%22&api-key='.$nytKey; $curl = curl_init(); curl_setopt($curl, CURLOPT_RETURNTRANSFER, true); curl_setopt($curl, CURLOPT_URL,$curl_dest); $result = json_decode(curl_exec($curl)); var_dump($result);
结果如下:

也许我会在接下来的剧集中编写一个 PHP 库来更好地解析 NYT API,但此代码打破了关键字和引导段落:
Yii::$app->response->format = Response::FORMAT_JSON;
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com/svc/search/v2/articlesearch.json?'.
'fl=headline,keywords,lead_paragraph&fq=web_url:%22'.$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
echo $result->response->docs[0]->headline->main.'<br />'.'<br />';
echo $result->response->docs[0]->lead_paragraph.'<br />'.'<br />';
foreach ($result->response->docs[0]->keywords as $k) {
echo $k->value.'<br/>';
}
以下是本文显示的内容:
Polar Bears’ Path to Decline Runs Through Alaskan Village The bears that come here are climate refugees, on land because the sea ice they rely on for hunting seals is receding. Polar Bears Greenhouse Gas Emissions Alaska Global Warming Endangered and Extinct Species International Union for Conservation of Nature National Snow and Ice Data Center Polar Bears International United States Geological Survey
希望这能开始扩展您对如何使用这些 API 的想象力。现在可能实现的事情非常令人兴奋。
结束中
纽约时报 API 非常有用,我很高兴看到他们向开发者社区提供它。通过 GitHub 获得如此快速的 API 支持也令人耳目一新——我只是没想到会这样。请记住,它适用于非商业项目。如果您有一些赚钱的想法,请给他们留言,看看他们是否愿意与您合作。出版商渴望新的收入来源。
I hope you find these web scraping snippets helpful and implement them into your projects. If you want to watch today's show, you can try some web scraping on my website Active Together .
Please share any thoughts and feedback in the comments. You can also always contact me directly on Twitter @lookahead_io. Be sure to check out my instructor page and other series: Building Your Startup with PHP and Programming with Yii2.
Related Links
- New York Times API Library
- The New York Times Public API Specification on GitHub
- How to crawl metadata in web pages (Envato Tuts)
- How to use Node.js and jQuery to crawl web pages (Envato Tuts)
- Build your first Web Scraper in Ruby (Envato Tuts)
The above is the detailed content of Metadata scraping using the New York Times API. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1376
1376
 52
52

 Metadata scraping using the New York Times API
Sep 02, 2023 pm 10:13 PM
Metadata scraping using the New York Times API
Sep 02, 2023 pm 10:13 PM
Introduction Last week, I wrote an introduction about scraping web pages to collect metadata, and mentioned that it was impossible to scrape the New York Times website. The New York Times paywall blocks your attempts to collect basic metadata. But there is a way to solve this problem using New York Times API. Recently I started building a community website on the Yii platform, which I will publish in a future tutorial. I want to be able to easily add links that are relevant to the content on my site. While people can easily paste URLs into forms, providing title and source information is time-consuming. So in today's tutorial I'm going to extend the scraping code I recently wrote to leverage the New York Times API to collect headlines when adding a New York Times link. Remember, I'm involved
 Access metadata of various audio and video files using Python
Sep 05, 2023 am 11:41 AM
Access metadata of various audio and video files using Python
Sep 05, 2023 am 11:41 AM
We can access the metadata of audio files using Mutagen and the eyeD3 module in Python. For video metadata we can use movies and the OpenCV library in Python. Metadata is data that provides information about other data, such as audio and video data. Metadata for audio and video files includes file format, file resolution, file size, duration, bitrate, etc. By accessing this metadata, we can manage media more efficiently and analyze the metadata to obtain some useful information. In this article, we will take a look at some of the libraries or modules provided by Python for accessing metadata of audio and video files. Access audio metadata Some libraries for accessing audio file metadata are - using mutagenesis
 How to crawl and process data by calling API interface in PHP project?
Sep 05, 2023 am 08:41 AM
How to crawl and process data by calling API interface in PHP project?
Sep 05, 2023 am 08:41 AM
How to crawl and process data by calling API interface in PHP project? 1. Introduction In PHP projects, we often need to crawl data from other websites and process these data. Many websites provide API interfaces, and we can obtain data by calling these interfaces. This article will introduce how to use PHP to call the API interface to crawl and process data. 2. Obtain the URL and parameters of the API interface. Before starting, we need to obtain the URL of the target API interface and the required parameters.
 Microsoft launches new tabular model definition language for Power BI
Apr 13, 2023 pm 04:13 PM
Microsoft launches new tabular model definition language for Power BI
Apr 13, 2023 pm 04:13 PM
Microsoft has announced the end of support date for Power BI Desktop on Windows 8.1. Recently, the tech giant’s premier data analytics platform also introduced TypeScript support and other new features. Today, a new Tabular Model Definition Language (TMDL) for Power BI was launched and is now available in public preview. TMDL is required due to the highly complex BIM files extracted from the huge semantic data model created using Power BI. Traditionally containing model metadata in Tabular Model Scripting Language (TMSL), this file is considered difficult to process further. Additionally, with multiple developers working on
 Vue development experience summary: tips for optimizing SEO and search engine crawling
Nov 22, 2023 am 10:56 AM
Vue development experience summary: tips for optimizing SEO and search engine crawling
Nov 22, 2023 am 10:56 AM
Summary of Vue development experience: Tips for optimizing SEO and search engine crawling. With the rapid development of the Internet, website SEO (SearchEngineOptimization, search engine optimization) has become more and more important. For websites developed using Vue, optimizing for SEO and search engine crawling is crucial. This article will summarize some Vue development experience and share some tips for optimizing SEO and search engine crawling. Using prerendering technology Vue
 How to add metadata to a DataFrame or Series using Pandas in Python?
Aug 19, 2023 pm 08:33 PM
How to add metadata to a DataFrame or Series using Pandas in Python?
Aug 19, 2023 pm 08:33 PM
A key feature of Pandas is the ability to handle metadata that can provide additional information about the data present in a DataFrame or Series. Pandas is a powerful and widely used library in Python for data manipulation and analysis. In this article, we will explore how to add metadata to a DataFrame or Series in Python using Pandas. What is metadata in Pandas? Metadata is information about the data in a DataFrame or Series. It can include the data type about the column, the unit of measurement, or any other important and relevant information to provide context about the data provided. You can use Pandas to
 How to use Scrapy to crawl Douban books and their ratings and comments?
Jun 22, 2023 am 10:21 AM
How to use Scrapy to crawl Douban books and their ratings and comments?
Jun 22, 2023 am 10:21 AM
With the development of the Internet, people increasingly rely on the Internet to obtain information. For book lovers, Douban Books has become an indispensable platform. In addition, Douban Books also provides a wealth of book ratings and reviews, allowing readers to understand a book more comprehensively. However, manually obtaining this information is tantamount to finding a needle in a haystack. At this time, we can use the Scrapy tool to crawl data. Scrapy is an open source web crawler framework based on Python, which can help us efficiently
 Scrapy in action: crawling Baidu news data
Jun 23, 2023 am 08:50 AM
Scrapy in action: crawling Baidu news data
Jun 23, 2023 am 08:50 AM
Scrapy in action: Crawling Baidu news data With the development of the Internet, the main way people obtain information has shifted from traditional media to the Internet, and people increasingly rely on the Internet to obtain news information. For researchers or analysts, a large amount of data is needed for analysis and research. Therefore, this article will introduce how to use Scrapy to crawl Baidu news data. Scrapy is an open source Python crawler framework that can crawl website data quickly and efficiently. Scrapy provides powerful web page parsing and crawling functions
