#With the rise of telemedicine, patients are increasingly inclined to choose online consultation and consultation to seek convenient and efficient medical support. Recently, large language models (LLM) have demonstrated powerful natural language interaction capabilities, bringing hope for health medical assistants to enter people's lives
Medical and health consultation scenarios are usually complex. Personal assistants need to have rich medical knowledge and the ability to understand the patient's intentions through multiple rounds of dialogue and give professional and detailed responses. When facing medical and health consultations, general language models often avoid talking or answer questions that are not asked due to lack of medical knowledge; at the same time, they tend to complete the consultation on the current round of questions and lack the satisfactory ability to follow up multiple rounds of questions. In addition, high-quality Chinese medical data sets are currently very rare, which poses a challenge to training powerful language models in the medical field. Fudan University Data Intelligence and Social Computing Laboratory (FudanDISC) released a Chinese medical and health personal assistant - DISC-MedLLM. In the medical and health consultation evaluation of single-round question and answer and multi-round dialogue, the performance of the model shows obvious advantages compared with existing large medical dialogue models. The research team also released a high-quality supervised fine-tuning (SFT) data set - DISC-Med-SFT containing 470,000 people. The model parameters and technical reports are also open source.
- Homepage address: https://med.fudan-disc.com
- Github address: https://github.com/FudanDISC/DISC-MedLLM
- Technical report: https://arxiv.org/abs/2308.14346

##Figure 1 : Dialogue exampleWhen patients feel unwell, they can consult the model and describe their symptoms, and the model will give possible causes, recommended treatment plans, etc. As a reference, detailed descriptions of symptoms were proactively sought when information was lacking.
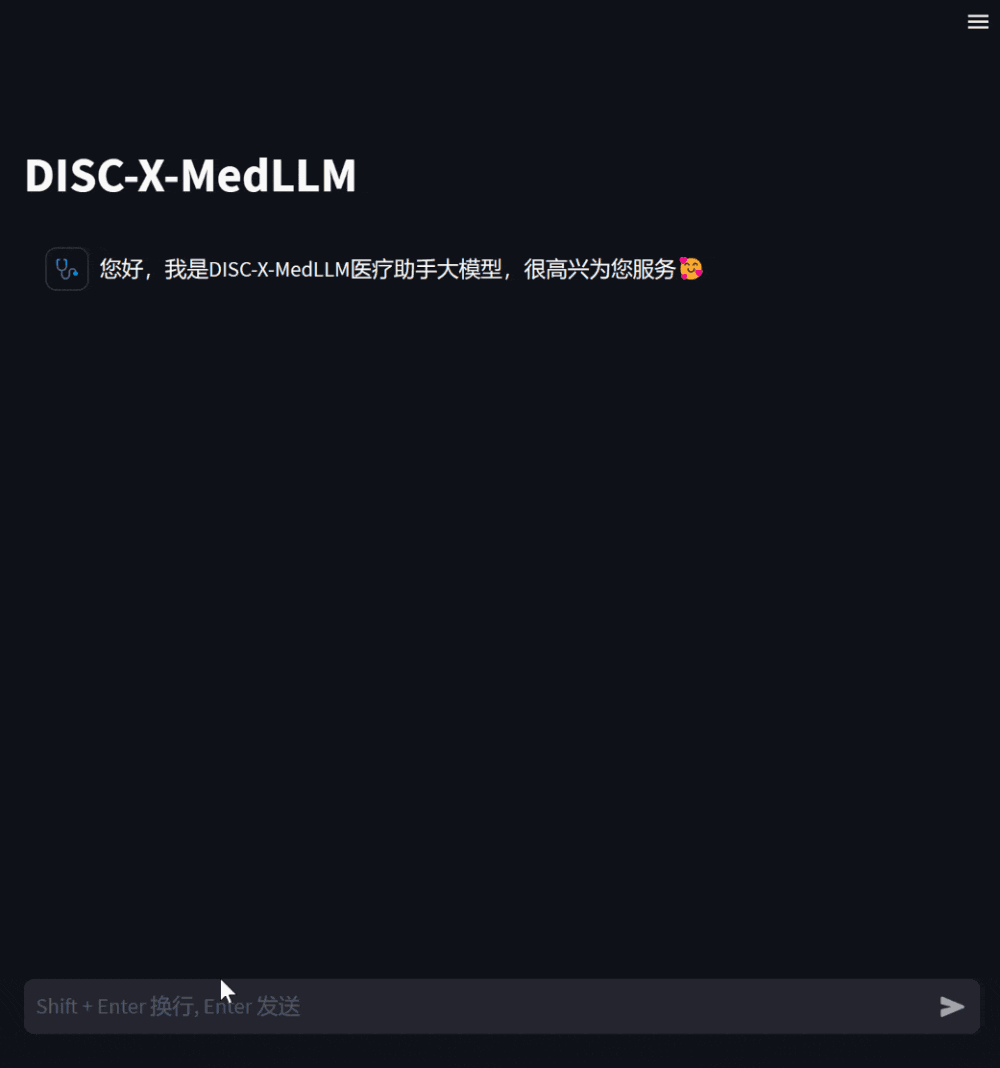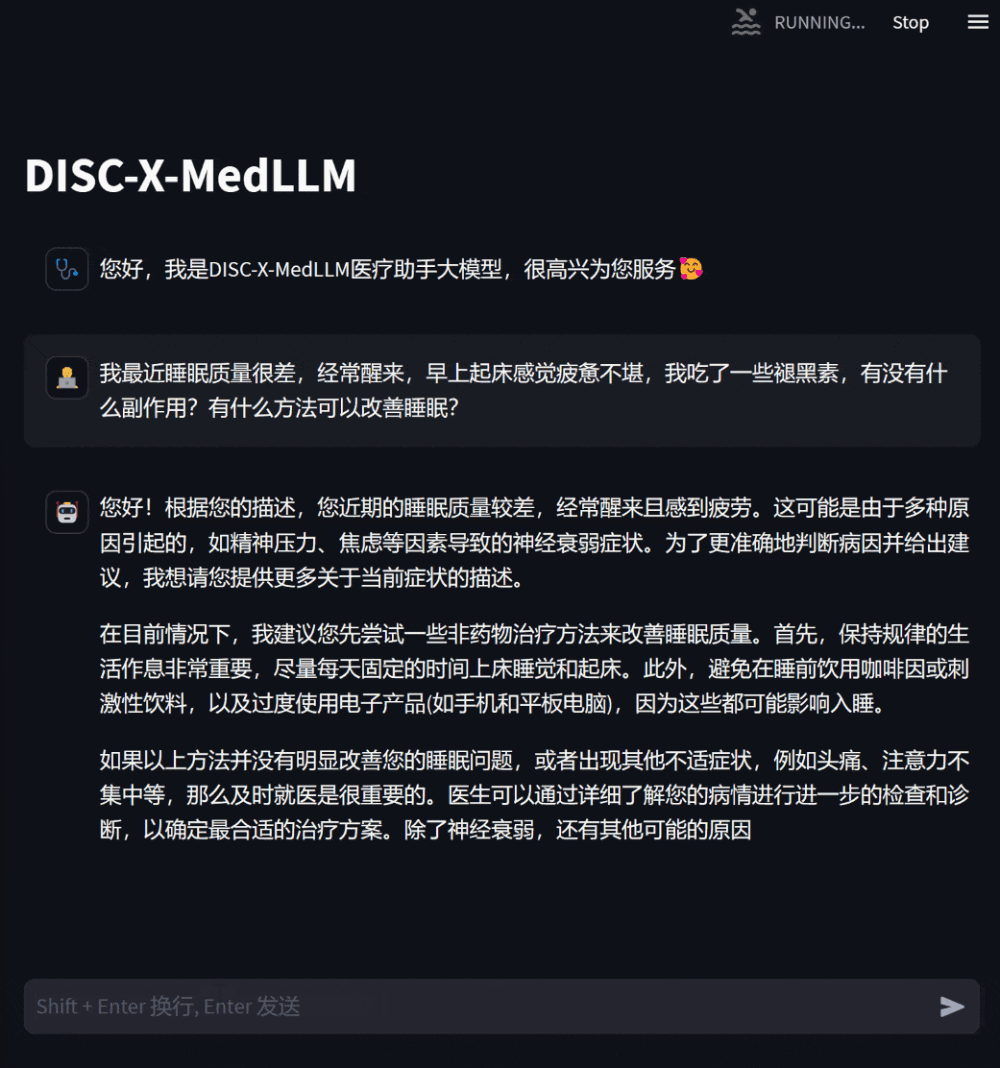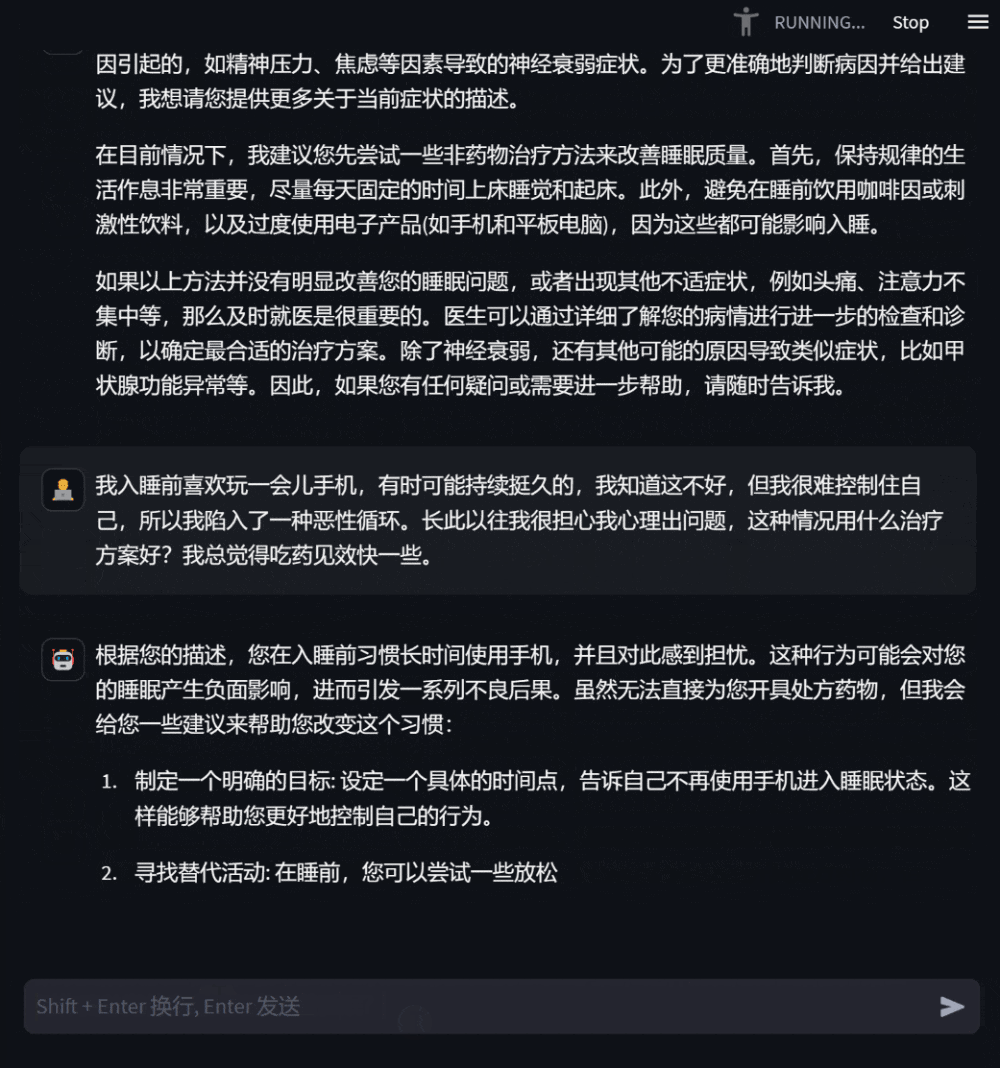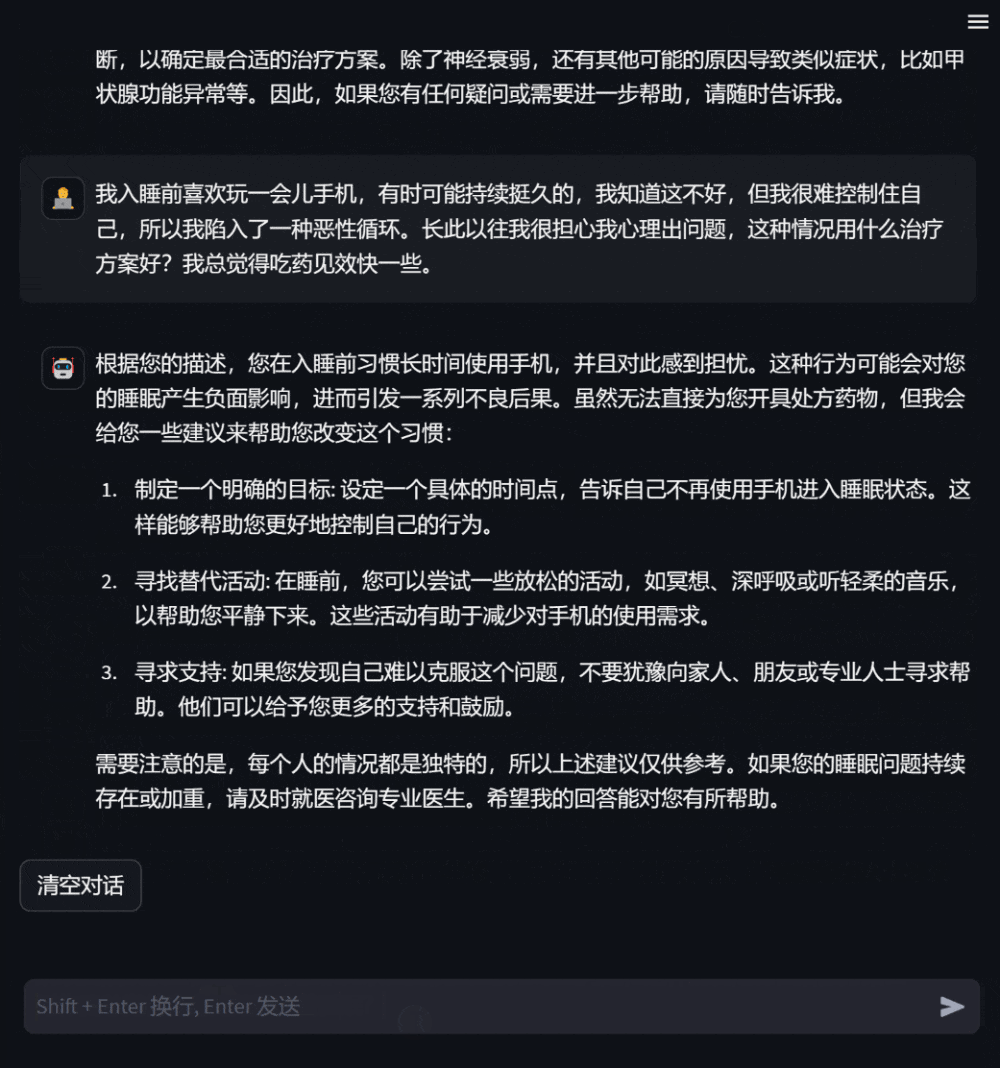
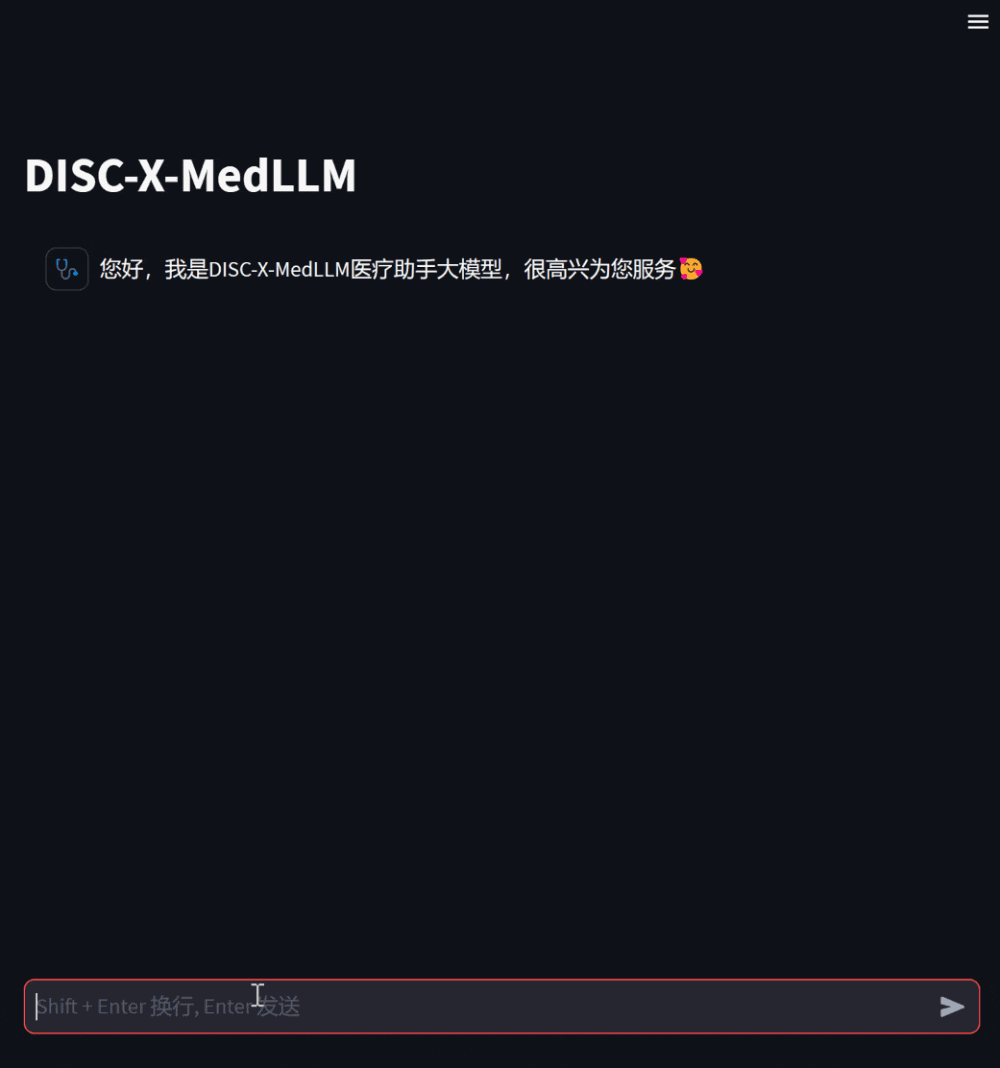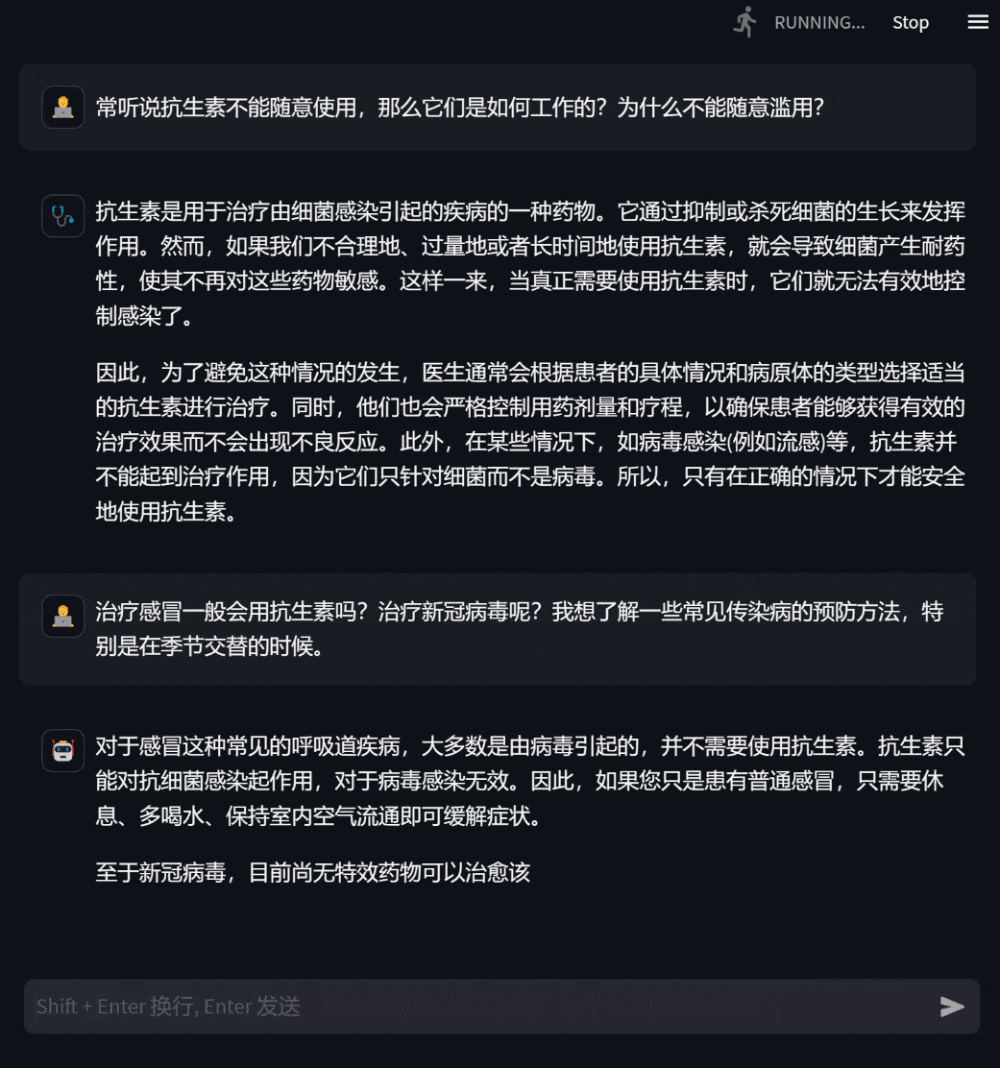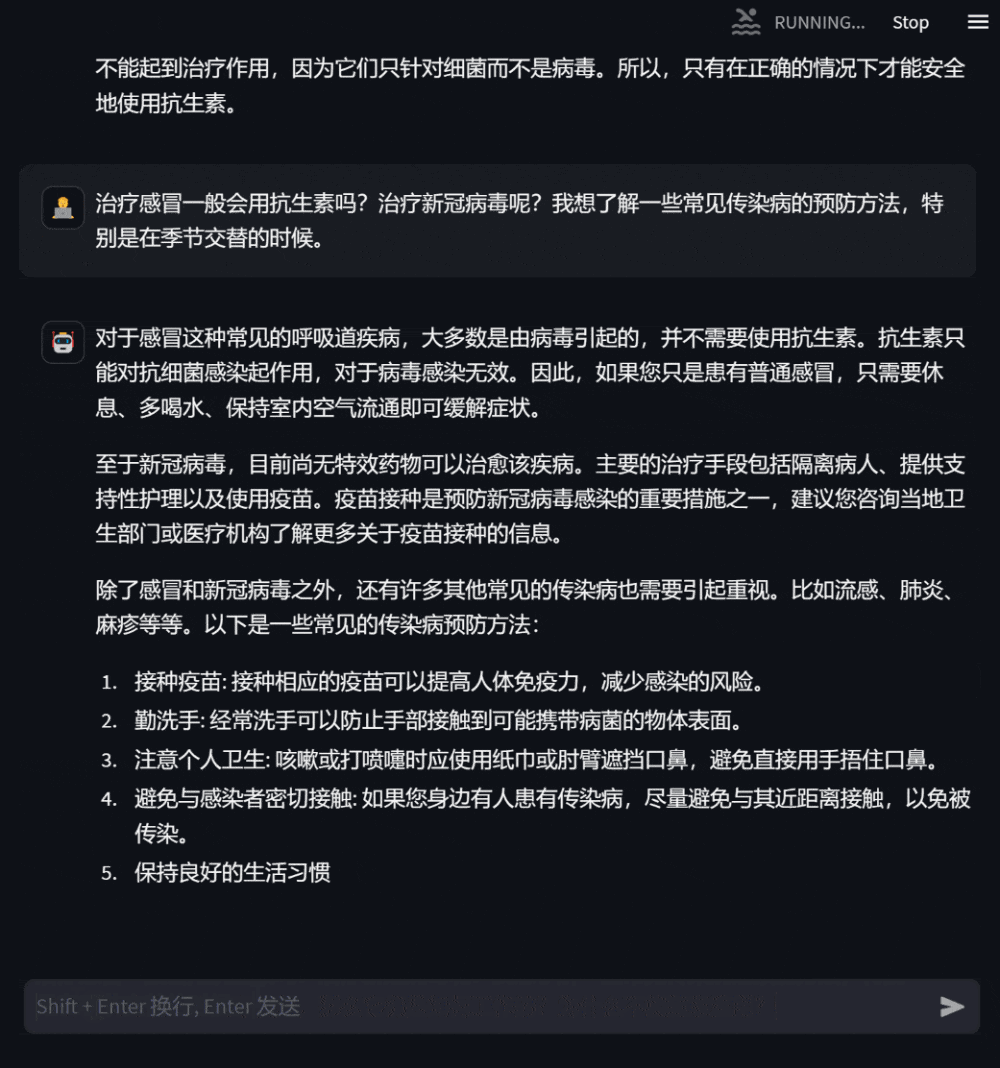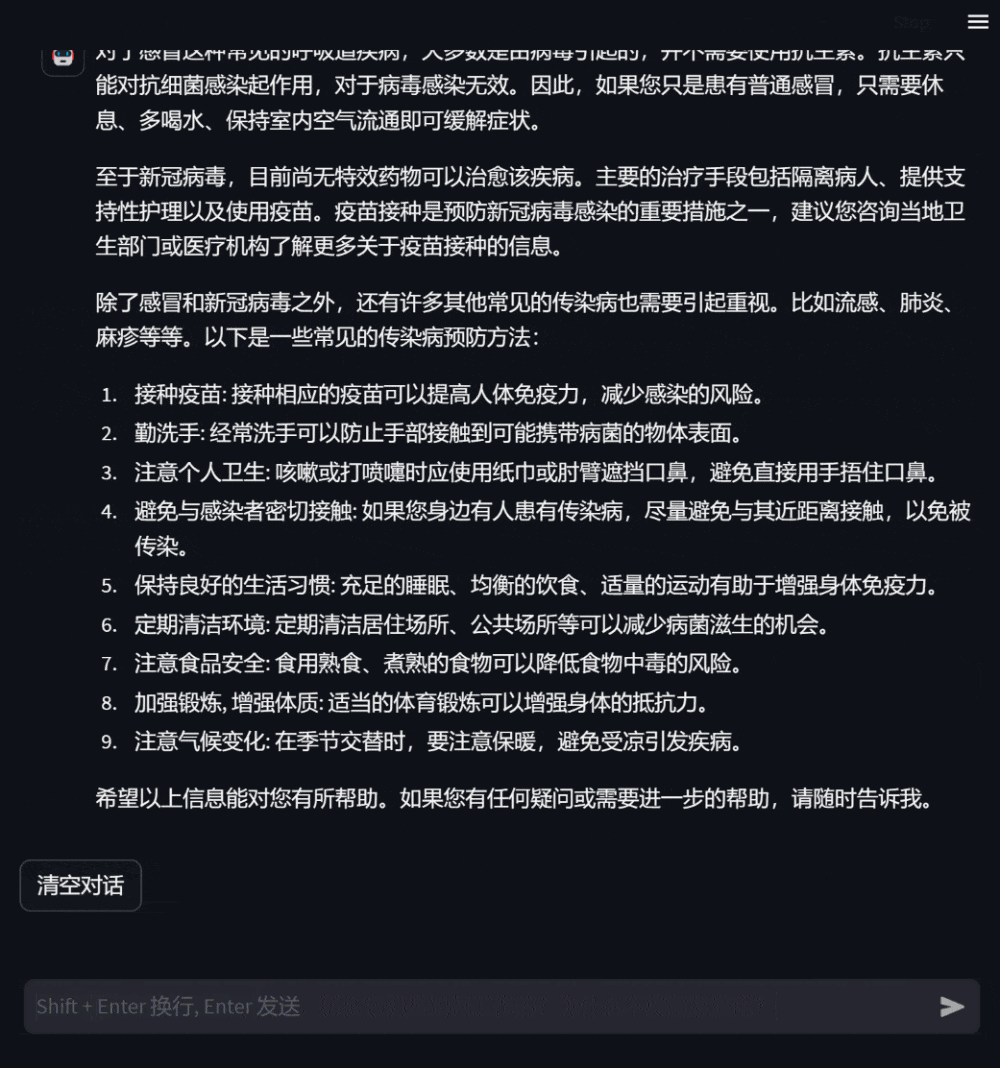
Figure 2: Dialogue in the consultation sceneUsers can also ask the model specific consultation questions based on their own health conditions, and the model will give detailed and helpful answers, and proactively ask questions when information is lacking to enhance the pertinence and accuracy of the responses.
Figure 3: Dialogue based on consultation on one’s own health conditionUsers can also ask for medical knowledge that has nothing to do with themselves. At this time, the model will answer as professionally as possible so that users can understand it comprehensively and accurately.
Figure 4: Medical knowledge inquiry dialogue that has nothing to do with yourself2. Introduction to DISC-MedLLM DISC-MedLLM is a large medical model trained on the general domain Chinese large model Baichuan-13B based on the high-quality data set DISC-Med-SFT we constructed. It is worth noting that our training data and training methods can be adapted to any base large model. DISC-MedLLM has three key characteristics:
- Reliable and rich expertise . We use the medical knowledge graph as the information source, sample triples, and use the language capabilities of the general large model to construct dialogue samples.
- Inquiry ability for multiple rounds of dialogue. We use real consultation dialogue records as the information source and use large models to reconstruct the dialogue. During the construction process, the model is required to completely align the medical information in the dialogue.
- Align responses to human preferences. Patients hope to obtain richer supporting information and background knowledge during the consultation process, but human doctors' answers are often concise; through manual screening, we construct high-quality, small-scale instruction samples to align with patients' needs.
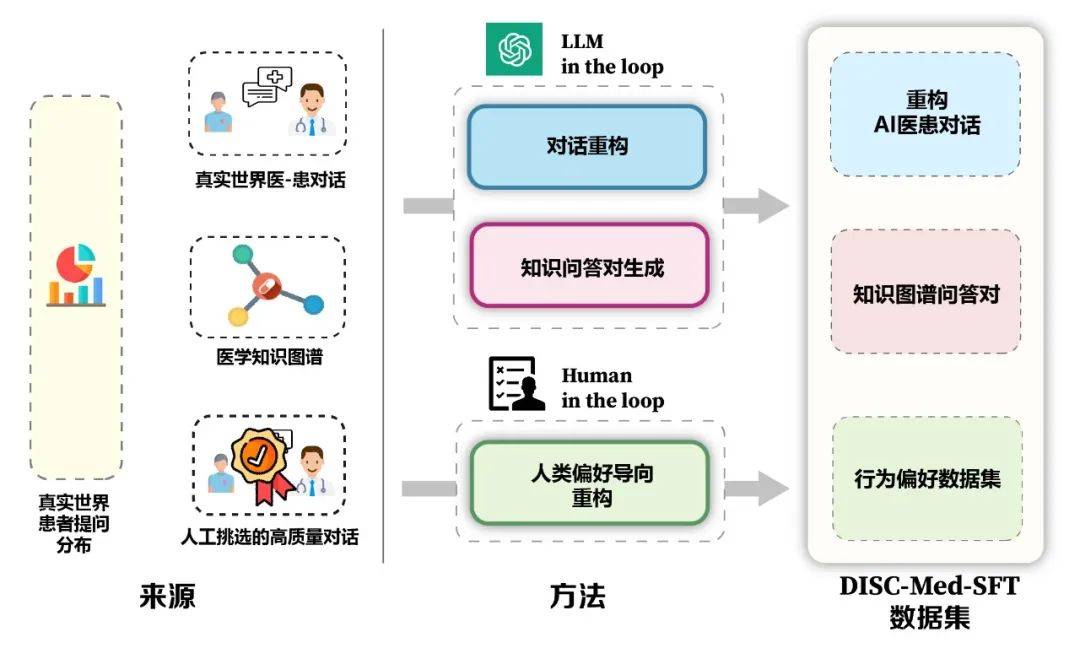
The advantages of the model and the data construction framework are shown in Figure 5. We calculated the real distribution of patients from real consultation scenarios to guide the sample construction of the data set. Based on the medical knowledge graph and real consultation data, we used two ideas: large model-in-the-loop and people-in-the-loop to construct the data set. .
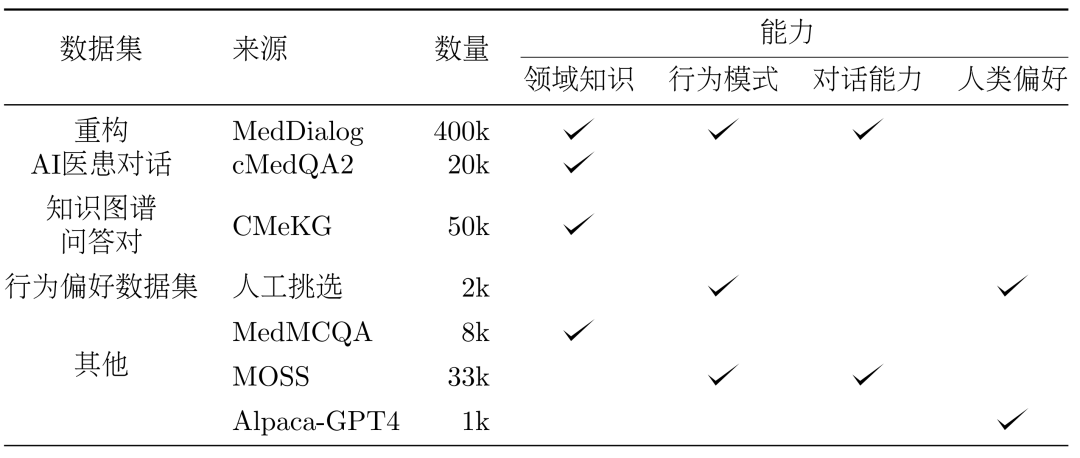
##Figure 5: Structure of DISC-Med-SFT3. Method: Construction of the data set DISC-Med-SFTIn the process of model training, we asked DISC- Med-SFT is supplemented with general domain datasets and data samples from existing corpora to form DISC-Med-SFT-ext, details of which are presented in Table 1.
##Table 1: DISC-Med-SFT-ext data content introduction
Reconstructing AI doctor-patient dialogue
data set. 400,000 and 20,000 samples were randomly selected from two public data sets, MedDialog and cMedQA2, respectively, as source samples for SFT data set construction.
Refactoring. In order to adjust the real-world doctor answers into the required high-quality uniformly formatted answers, we utilized GPT-3.5 to complete the reconstruction process of this dataset. Prompts require rewriting to follow the following principles: Remove verbal expressions, extract unified expressions, and correct inconsistencies in doctors’ language use place. Stick to the key information in the original doctor's answer and provide appropriate explanations to be more thorough and logical. Rewrite or delete responses that AI doctors should not send, such as asking patients to make an appointment.
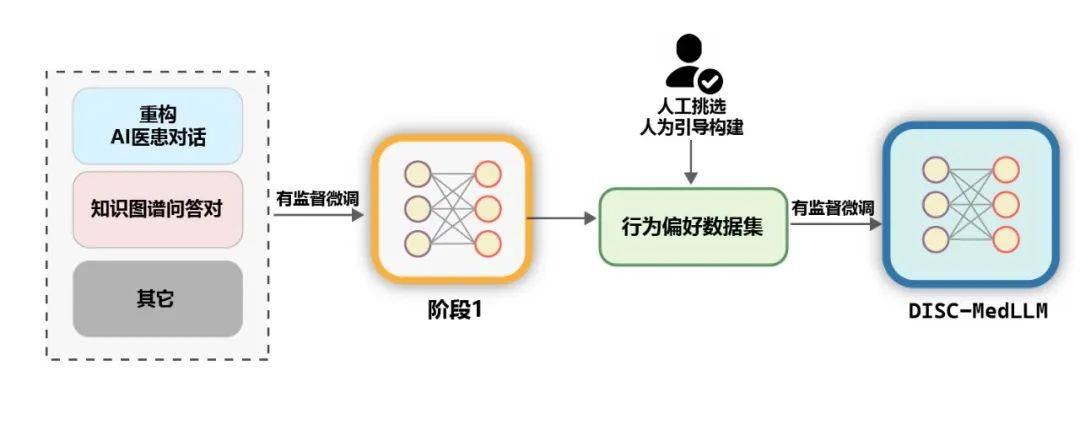
# Figure 6 shows an example of refactoring. The adjusted doctor's answers are consistent with the identity of the AI medical assistant, adhering to the key information provided by the original doctor while providing richer and more comprehensive help to the patient. Figure 6: Example of dialogue rewritingKnowledge graph question and answer pairThe medical knowledge graph contains a large amount of well-organized medical expertise, based on which QA training samples with lower noise can be generated. Based on CMeKG, we sampled in the knowledge graph according to the department information of disease nodes, and used appropriately designed GPT-3.5 model Prompts to generate a total of more than 50,000 diverse medical scene dialogue samples. Behavioral preference data setIn the final stage of training, in order to further improve the model To improve the performance, we use a data set that is more consistent with human behavioral preferences for secondary supervised fine-tuning. About 2000 high-quality, diverse samples were manually selected from the two data sets of MedDialog and cMedQA2. After rewriting several examples and manually revising them to GPT-4, we used the small sample method to provide them to GPT-3.5 ,generate high-quality behavioral preference data sets. General data. In order to enrich the diversity of the training set and mitigate the risk of model degradation in basic capabilities during the SFT training stage, we randomly selected several samples from two common supervised fine-tuning data sets, moss-sft-003 and alpaca gpt4 data zh. MedMCQA. To enhance the Q&A capabilities of the model, we selected MedMCQA, a multiple-choice question data set in the English medical field, and used GPT-3.5 to optimize the questions and correct answers in the multiple-choice questions, generating about 8,000 professional Chinese medical Q&A samples. . Training. As shown in the figure below, the training process of DISC-MedLLM is divided into two SFT stages.
##Figure 7: Two-stage training processReview. The performance of medical LLMs is evaluated in two scenarios, namely single-round QA and multi-round dialogue.
- Single-round QA evaluation: In order to evaluate the accuracy of the model in terms of medical knowledge, we collected data from the Chinese National Medical Licensing Examination (NMLEC) and The National Entrance Examination for Masters (NEEP) Western Medicine 306 major selected 1,500 multiple-choice questions to evaluate the performance of the model in a single round of QA.
- Multi-round dialogue evaluation: In order to systematically evaluate the dialogue ability of the model, we use three public data sets - Chinese Medical Benchmark Evaluation (CMB-Clin), Chinese Medical Dialogue Dataset (CMD) and Chinese Medical Intention Dataset (CMID), and GPT-3.5 randomly selects samples to play the role of patients and dialogue with the model. Four evaluation indicators are proposed - initiative, accuracy, usefulness and language quality. GPT-3.5 4 ratings.
##Review results
Compare models. Our model is compared with three general LLMs and two Chinese medical conversational LLMs. Including OpenAI's GPT-3.5, GPT-4, Baichuan-13B-Chat; BianQue-2 and HuatuoGPT-13B.
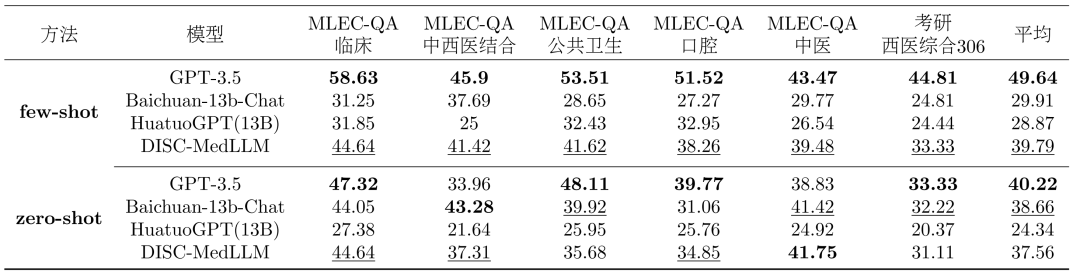
Single round QA results. The overall results of the multiple-choice assessment are shown in Table 2. GPT-3.5 shows a clear lead. DISC-MedLLM achieved second place in the small-sample setting and ranked third behind Baichuan-13B-Chat in the zero-sample setting. Notably, we outperform HuatuoGPT (13B) trained with a reinforcement learning setting.
Table 2: Multiple choice evaluation results
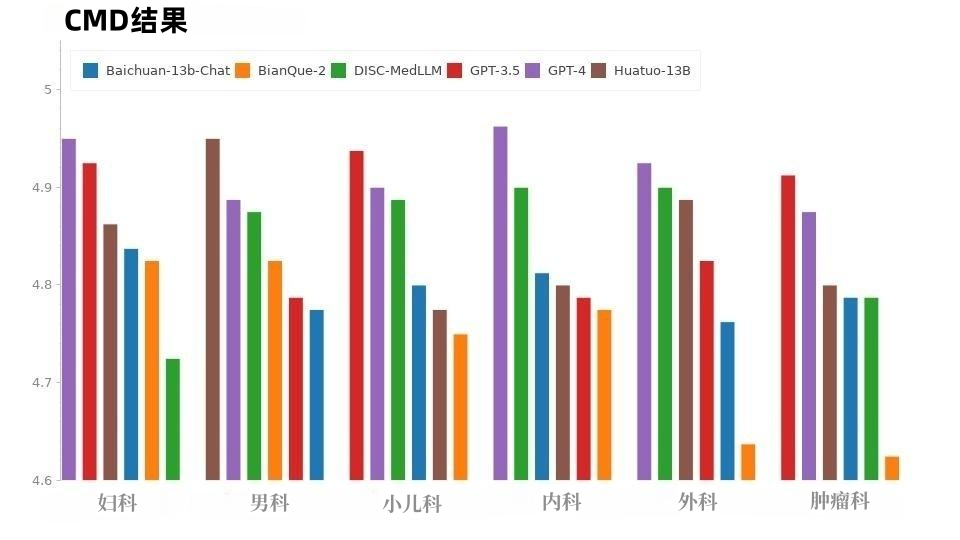
Results of multiple rounds of dialogue. In the CMB-Clin evaluation, DISC-MedLLM achieved the highest overall score, followed closely by HuatuoGPT. Our model scored highest in the positivity criterion, highlighting the effectiveness of our training approach that biases medical behavior patterns. The results are shown in Table 3. Table 3: CMB-clin resultsIn the CMD sample, as shown in Figure 8, GPT-4 obtained the highest score, Next is GPT-3.5. The models in the medical field, DISC-MedLLM and HuatuoGPT, have the same overall performance scores, and their performance in different departments is outstanding.
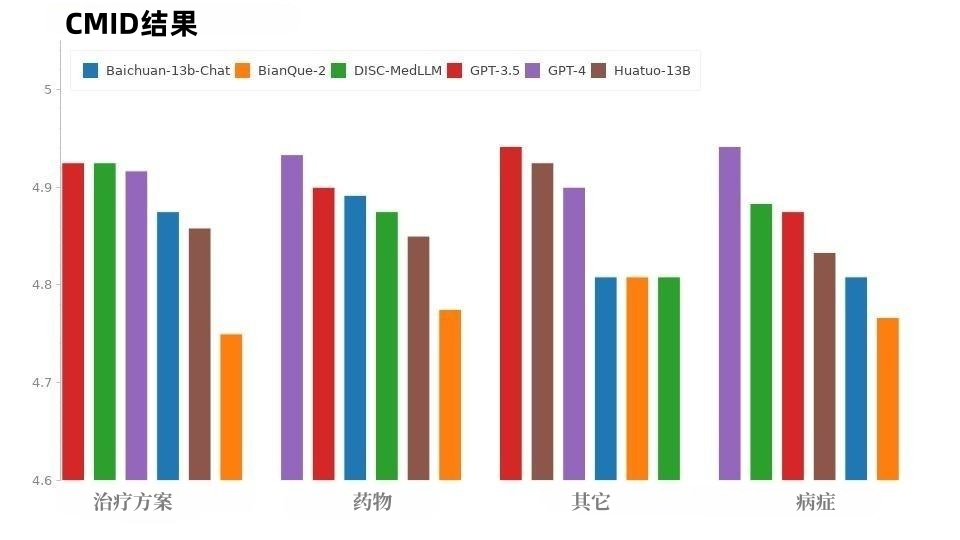
The situation of CMID is similar to that of CMD, as shown in Figure 9, GPT-4 and GPT-3.5 maintain the lead. Except for the GPT series, DISC-MedLLM performed best. It outperformed HuatuoGPT in three intents: condition, treatment regimen, and medication.
The inconsistent performance of each model between CMB-Clin and CMD/CMID may be due to the different data distribution between the three datasets. CMD and CMID contain a more explicit sample of questions, and patients may have received a diagnosis and expressed clear needs when describing symptoms, and the patient's questions and needs may even have nothing to do with their personal health status. The general-purpose models GPT-3.5 and GPT-4, which excel in many aspects, are better at handling this situation. ##DISC-Med-SFT dataset leverages real-world conversations and the advantages and capabilities of general domain LLM, and targeted enhancements in three aspects: domain knowledge, medical conversation skills and human preferences; high-quality data sets trained the excellent large medical model DISC-MedLLM, in terms of medical interaction Significant improvements have been achieved, high usability has been demonstrated, and huge application potential has been demonstrated.
Research in this field will bring more prospects and possibilities for reducing online medical costs, promoting medical resources, and achieving balance. DISC-MedLLM will bring convenient and personalized medical services to more people and contribute to the cause of general health.
The above is the detailed content of Fudan University team releases Chinese medical and health personal assistant, while open source 470,000 high-quality data sets. For more information, please follow other related articles on the PHP Chinese website!




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



