
 Technology peripherals
AI
Use BigDL-LLM to instantly accelerate tens of billions of parameter LLM inferences
Technology peripherals
AI
Use BigDL-LLM to instantly accelerate tens of billions of parameter LLM inferences
Use BigDL-LLM to instantly accelerate tens of billions of parameter LLM inferences

We are entering a new era of AI driven by Large Language Model (LLM). LLM is playing an increasingly important role in various applications such as customer service, virtual assistants, content creation, and programming assistance. role.
However, as the scale of LLM continues to expand, the resource consumption required to run large models is also increasing, causing it to run slower and slower, which brings considerable challenges to AI application developers. challenge.
To this end, Intel recently launched a large model open source library called BigDL-LLM[1], which can help AI developers and researchers in Intel ® accelerates the optimization of large language models on the platform and improves the experience of using large language models on the Intel ® platform.

The following shows the 33 billion parameter large language model Vicuna-33b-v1.3[2] accelerated using BigDL-LLM Real-time effects running on a server equipped with Intel® Xeon® Platinum 8468 processor.
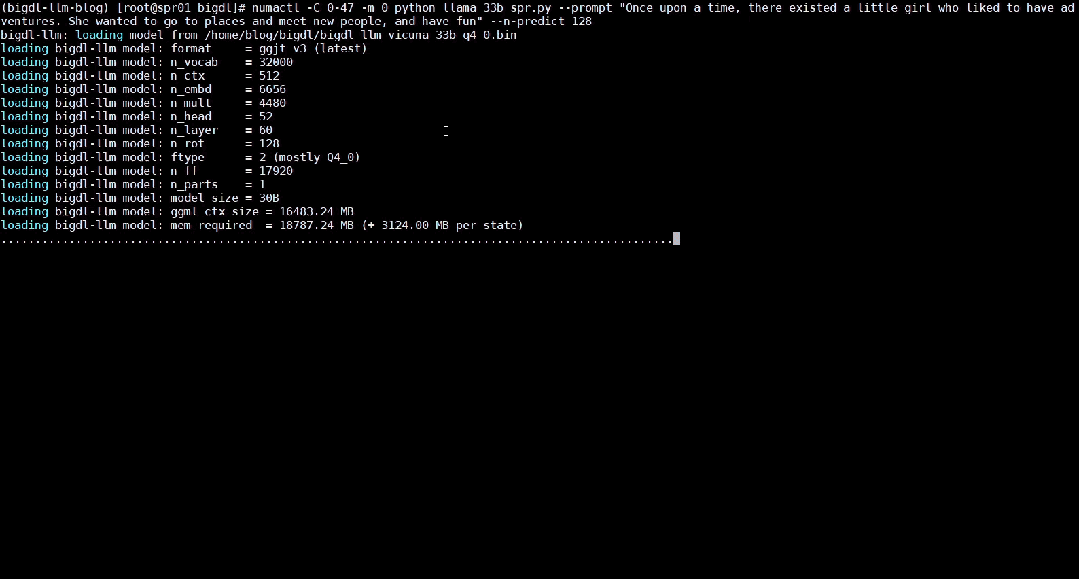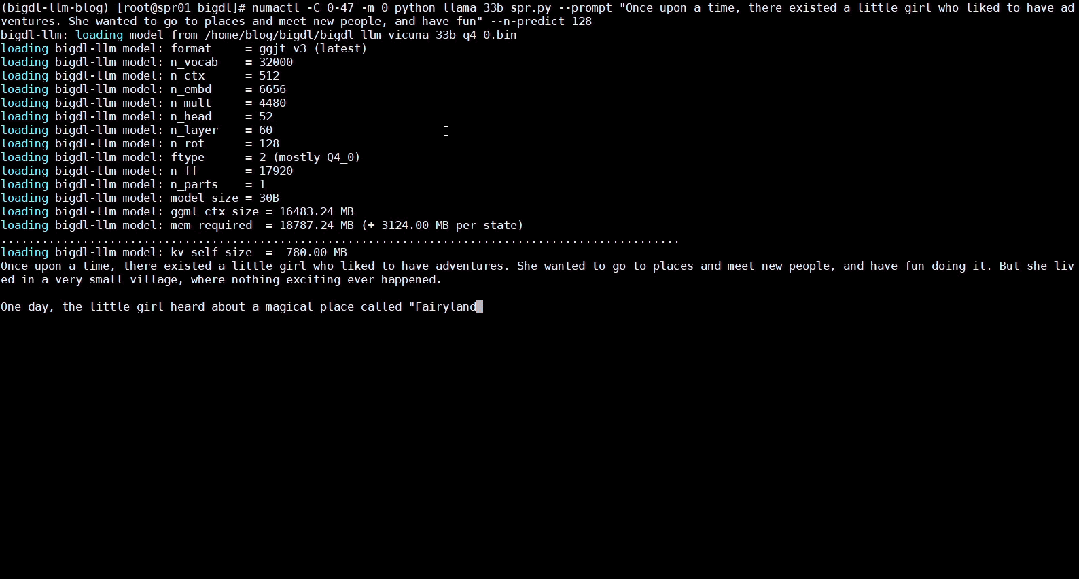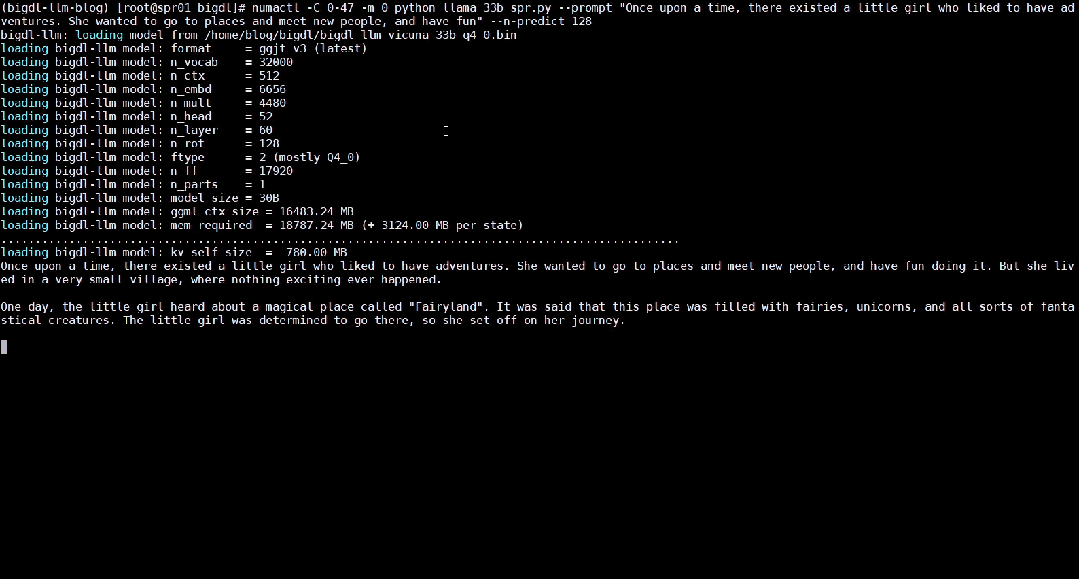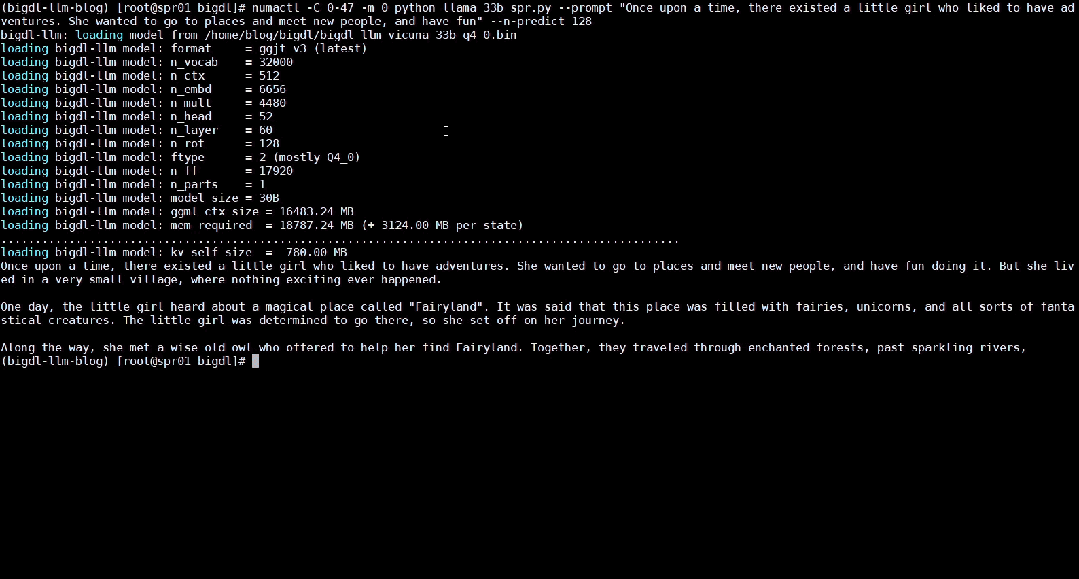
△Running a 33 billion parameter large language on a server equipped with Intel® Xeon® Platinum 8468 processor Actual speed of the model (real-time screen recording)
BigDL-LLM: An open source large language model acceleration library on the Intel® platform
BigDL-LLM is a library focused on optimization and an open source library for accelerating large language models. It is part of BigDL and released under the Apache 2.0 license
It provides various low-precision optimizations (such as INT4/INT5/INT8) and can leverage a variety of Intel® CPU integrated hardware acceleration technology (AVX/VNNI/AMX, etc.) and the latest software optimization enable large language models to achieve more efficient optimization on the Intel® platform and run faster.
An important feature of BigDL-LLM is that for models based on the Hugging Face Transformers API, you only need to change one line of code to accelerate the model. In theory, it can support running any Transformers model, which is very friendly to developers who are familiar with the Transformers API.
In addition to Transformers API, many people also use LangChain to develop large language model applications.
To this end, BigDL-LLM also provides easy-to-use LangChain integration[3], allowing developers to easily use BigDL-LLM to develop new applications or migrate existing, Applications based on Transformers API or LangChain API.
In addition, for general PyTorch large language models (models that do not use Transformer or LangChain API), you can also use BigDL-LLM optimize_model API one-click acceleration to improve performance. For details, please refer to GitHub README[4] and official documentation[5].
BigDL-LLM also provides a large number of commonly used open source LLM acceleration examples (e.g. examples using Transformers API[6] and examples using LangChain API[7] , and tutorials (including supporting jupyter notebooks) [8], to facilitate developers to quickly get started.
Installation and use: simple installation process and easy-to-use API interface
Installing BigDL-LLM is very convenient, just execute the following command:
pip install --pre --upgrade bigdl-llm[all]
△If the code is not fully displayed, please leave Sliding
It is also very easy to use BigDL-LLM to accelerate large models (only the Transformers style API is used as an example here).
Use BigDL-LLM Transformer style API to accelerate the model , only the model loading part needs to be changed, and the subsequent use process is completely consistent with the native Transformers.
The method of loading the model using the BigDL-LLM API is almost the same as the Transformers API - the user only needs to change the import, in the from_pretrained parameter Just set load_in_4bit=True .
BigDL-LLM will perform 4-bit low-precision quantization during the model loading process and use it in the subsequent inference process Various software and hardware acceleration technologies are optimized
#Load Hugging Face Transformers model with INT4 optimizationsfrom bigdl.llm. transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_4bit=True)△If the code is not fully displayed, please slide left or right
示例:快速实现一个基于大语言模型的语音助手应用
下文将以 LLM 常见应用场景“语音助手”为例,展示采用 BigDL-LLM 快速实现 LLM 应用的案例。通常情况下,语音助手应用的工作流程分为以下两个部分:
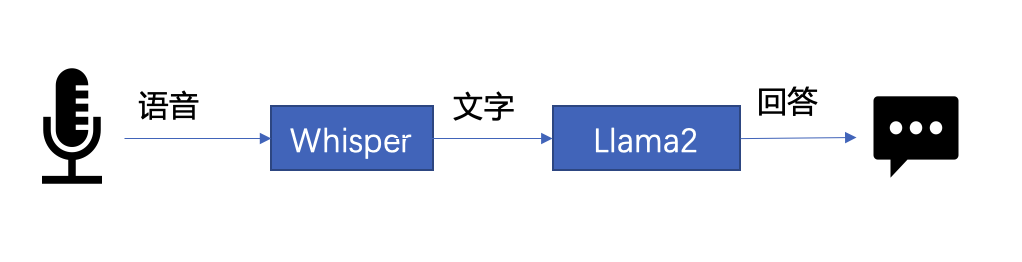
△图 1. 语音助手工作流程示意
- 语音识别——使用语音识别模型(本示例采用了 Whisper 模型[9] )将用户的语音转换为文本;
- 文本生成——将 1 中输出的文本作为提示语 (prompt),使用一个大语言模型(本示例采用了 Llama2[10] )生成回复。
以下是本文使用 BigDL-LLM 和 LangChain[11] 来搭建语音助手应用的过程:
在语音识别阶段:第一步,加载预处理器 processor 和语音识别模型 recog_model。本示例中使用的识别模型 Whisper 是一个 Transformers 模型。
只需使用 BigDL-LLM 中的 AutoModelForSpeechSeq2Seq 并设置参数 load_in_4bit=True,就能够以 INT4 精度加载并加速这一模型,从而显著缩短模型推理用时。
#processor = WhisperProcessor .from_pretrained(recog_model_path)recog_model = AutoModelForSpeechSeq2Seq .from_pretrained(recog_model_path, load_in_4bit=True)
△若代码显示不全,请左右滑动
第二步,进行语音识别。首先使用处理器从输入语音中提取输入特征,然后使用识别模型预测 token,并再次使用处理器将 token 解码为自然语言文本。
input_features = processor(frame_data,sampling_rate=audio.sample_rate,return_tensor=“pt”).input_featurespredicted_ids = recogn_model.generate(input_features, forced_decoder_ids=forced_decoder_ids)text = processor.batch_decode(predicted_ids, skip_special_tokens=True)[0]
△若代码显示不全,请左右滑动
在文本生成阶段,首先使用 BigDL-LLM 的 TransformersLLM API 创建一个 LangChain 语言模型(TransformersLLM 是在 BigDL-LLM 中定义的语言链 LLM 集成)。
可以使用这个 API 来加载 Hugging Face Transformers 的任何模型
llm = TransformersLLM . from_model_id(model_id=llm_model_path,model_kwargs={"temperature": 0, "max_length": args.max_length, "trust_remote_code": True},)△若代码显示不全,请左右滑动
然后,创建一个正常的对话链 LLMChain,并将已经创建的 llm 设置为输入参数。
# The following code is complete the same as the use-casevoiceassistant_chain = LLMChain(llm=llm, prompt=prompt,verbose=True,memory=ConversationBufferWindowMemory(k=2),)
△若代码显示不全,请左右滑动
以下代码将使用一个链条来记录所有对话历史,并将其适当地格式化为大型语言模型的输入。这样,我们可以生成合适的回复。只需将识别模型生成的文本作为 "human_input" 输入即可。代码如下:
response_text = voiceassistant_chain .predict(human_input=text, stop=”\n\n”)
△若代码显示不全,请左右滑动
最后,将语音识别和文本生成步骤放入循环中,即可在多轮对话中与该“语音助手”交谈。您可访问底部 [12] 链接,查看完整的示例代码,并使用自己的电脑进行尝试。快用 BigDL-LLM 来快速搭建自己的语音助手吧!
作者简介
黄晟盛是英特尔公司的资深架构师,黄凯是英特尔公司的AI框架工程师,戴金权是英特尔院士、大数据技术全球CTO和BigDL项目的创始人,他们都从事着与大数据和AI相关的工作
The above is the detailed content of Use BigDL-LLM to instantly accelerate tens of billions of parameter LLM inferences. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1385
1385
 52
52

 Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
This site reported on June 27 that Jianying is a video editing software developed by FaceMeng Technology, a subsidiary of ByteDance. It relies on the Douyin platform and basically produces short video content for users of the platform. It is compatible with iOS, Android, and Windows. , MacOS and other operating systems. Jianying officially announced the upgrade of its membership system and launched a new SVIP, which includes a variety of AI black technologies, such as intelligent translation, intelligent highlighting, intelligent packaging, digital human synthesis, etc. In terms of price, the monthly fee for clipping SVIP is 79 yuan, the annual fee is 599 yuan (note on this site: equivalent to 49.9 yuan per month), the continuous monthly subscription is 59 yuan per month, and the continuous annual subscription is 499 yuan per year (equivalent to 41.6 yuan per month) . In addition, the cut official also stated that in order to improve the user experience, those who have subscribed to the original VIP
 Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Improve developer productivity, efficiency, and accuracy by incorporating retrieval-enhanced generation and semantic memory into AI coding assistants. Translated from EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, author JanakiramMSV. While basic AI programming assistants are naturally helpful, they often fail to provide the most relevant and correct code suggestions because they rely on a general understanding of the software language and the most common patterns of writing software. The code generated by these coding assistants is suitable for solving the problems they are responsible for solving, but often does not conform to the coding standards, conventions and styles of the individual teams. This often results in suggestions that need to be modified or refined in order for the code to be accepted into the application
 Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) are trained on huge text databases, where they acquire large amounts of real-world knowledge. This knowledge is embedded into their parameters and can then be used when needed. The knowledge of these models is "reified" at the end of training. At the end of pre-training, the model actually stops learning. Align or fine-tune the model to learn how to leverage this knowledge and respond more naturally to user questions. But sometimes model knowledge is not enough, and although the model can access external content through RAG, it is considered beneficial to adapt the model to new domains through fine-tuning. This fine-tuning is performed using input from human annotators or other LLM creations, where the model encounters additional real-world knowledge and integrates it
 Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
To learn more about AIGC, please visit: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou is different from the traditional question bank that can be seen everywhere on the Internet. These questions It requires thinking outside the box. Large Language Models (LLMs) are increasingly important in the fields of data science, generative artificial intelligence (GenAI), and artificial intelligence. These complex algorithms enhance human skills and drive efficiency and innovation in many industries, becoming the key for companies to remain competitive. LLM has a wide range of applications. It can be used in fields such as natural language processing, text generation, speech recognition and recommendation systems. By learning from large amounts of data, LLM is able to generate text
 Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Machine learning is an important branch of artificial intelligence that gives computers the ability to learn from data and improve their capabilities without being explicitly programmed. Machine learning has a wide range of applications in various fields, from image recognition and natural language processing to recommendation systems and fraud detection, and it is changing the way we live. There are many different methods and theories in the field of machine learning, among which the five most influential methods are called the "Five Schools of Machine Learning". The five major schools are the symbolic school, the connectionist school, the evolutionary school, the Bayesian school and the analogy school. 1. Symbolism, also known as symbolism, emphasizes the use of symbols for logical reasoning and expression of knowledge. This school of thought believes that learning is a process of reverse deduction, through existing
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 AI startups collectively switched jobs to OpenAI, and the security team regrouped after Ilya left!
Jun 08, 2024 pm 01:00 PM
AI startups collectively switched jobs to OpenAI, and the security team regrouped after Ilya left!
Jun 08, 2024 pm 01:00 PM
Last week, amid the internal wave of resignations and external criticism, OpenAI was plagued by internal and external troubles: - The infringement of the widow sister sparked global heated discussions - Employees signing "overlord clauses" were exposed one after another - Netizens listed Ultraman's "seven deadly sins" Rumors refuting: According to leaked information and documents obtained by Vox, OpenAI’s senior leadership, including Altman, was well aware of these equity recovery provisions and signed off on them. In addition, there is a serious and urgent issue facing OpenAI - AI safety. The recent departures of five security-related employees, including two of its most prominent employees, and the dissolution of the "Super Alignment" team have once again put OpenAI's security issues in the spotlight. Fortune magazine reported that OpenA
 SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
Editor | KX In the field of drug research and development, accurately and effectively predicting the binding affinity of proteins and ligands is crucial for drug screening and optimization. However, current studies do not take into account the important role of molecular surface information in protein-ligand interactions. Based on this, researchers from Xiamen University proposed a novel multi-modal feature extraction (MFE) framework, which for the first time combines information on protein surface, 3D structure and sequence, and uses a cross-attention mechanism to compare different modalities. feature alignment. Experimental results demonstrate that this method achieves state-of-the-art performance in predicting protein-ligand binding affinities. Furthermore, ablation studies demonstrate the effectiveness and necessity of protein surface information and multimodal feature alignment within this framework. Related research begins with "S
