
 Technology peripherals
AI
Jia Qianghuai: Construction and application of large-scale knowledge graph of ants
Technology peripherals
AI
Jia Qianghuai: Construction and application of large-scale knowledge graph of ants
Jia Qianghuai: Construction and application of large-scale knowledge graph of ants


1. Overview of the graph
First introduce some basic concepts of the knowledge graph.
1. What is a knowledge graph?
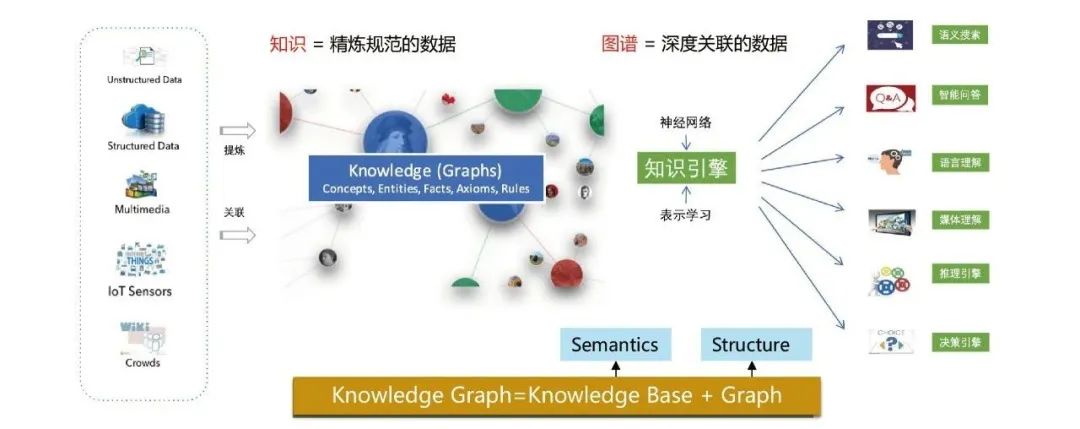
The knowledge graph aims to use graph structures to model, identify and infer the relationships between things. Complex relationships and accumulated domain knowledge are important cornerstones for realizing cognitive intelligence and have been widely used in many fields such as search engines, intelligent question answering, language semantic understanding, and big data decision analysis.
Knowledge graph models both the semantic relationship and the structural relationship between data. Combined with deep learning technology, the two relationships can be better integrated and represented.
2. Why should we build a knowledge graph?
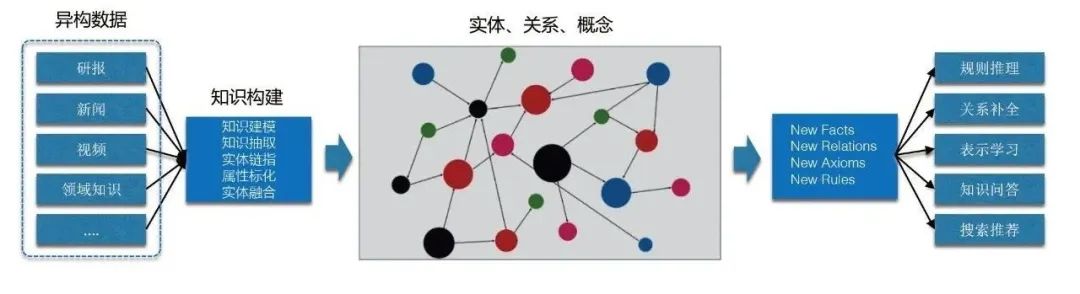
We want to build a knowledge graph mainly from the following two points: on the one hand It is the background characteristics of the data source of the ants themselves, and on the other hand, it is the benefits that the knowledge graph can bring.
[1] The data sources themselves are diverse and heterogeneous, lacking a unified knowledge understanding system.
[2] Knowledge graph can bring many benefits, including:
- Semantic standardization: using graph construction Technology improves the level of standardization and normalization of entities, relationships, concepts, etc.
- Domain knowledge accumulation: realize knowledge representation and interconnection based on semantics and graph structure, thereby accumulating rich domain knowledge.
- Knowledge reuse: Build a high-quality Ant knowledge graph and provide multiple downstream services through integration, linking and other services to reduce business costs and improve efficiency.
- Knowledge reasoning discovery: Discover more long-tail knowledge based on graph reasoning technology, serving scenarios such as risk control, credit, claims, merchant operations, marketing recommendations, etc.
3. Overview of how to build knowledge graphs
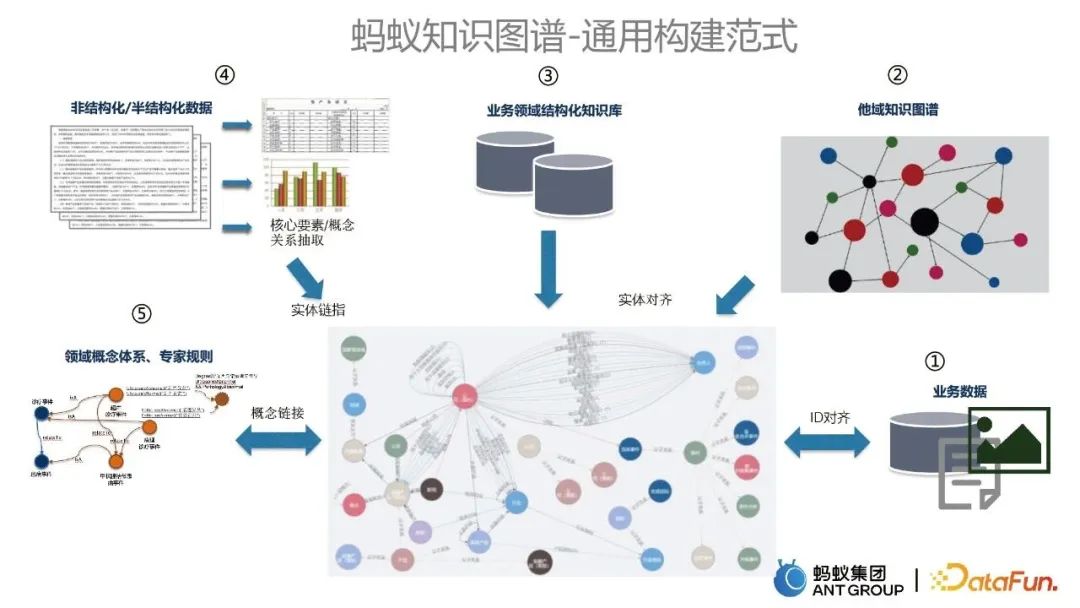
In the process of building various business knowledge graphs , we have precipitated a set of general construction paradigms for ant knowledge graphs, which are mainly divided into the following five parts:
- Starting from business data, as an important part of the cold start of the graph Data Sources.
- The knowledge graph of other domains is integrated with the existing graph, which is achieved through entity alignment technology.
- The integration of the structured knowledge base in the business domain and the existing knowledge graph is also achieved through entity alignment technology.
- Unstructured and semi-structured data, such as text, will be used to extract information and update existing maps through entity linking technology.
- The integration of domain concept systems and expert rules links relevant concepts and rules with existing knowledge graphs.
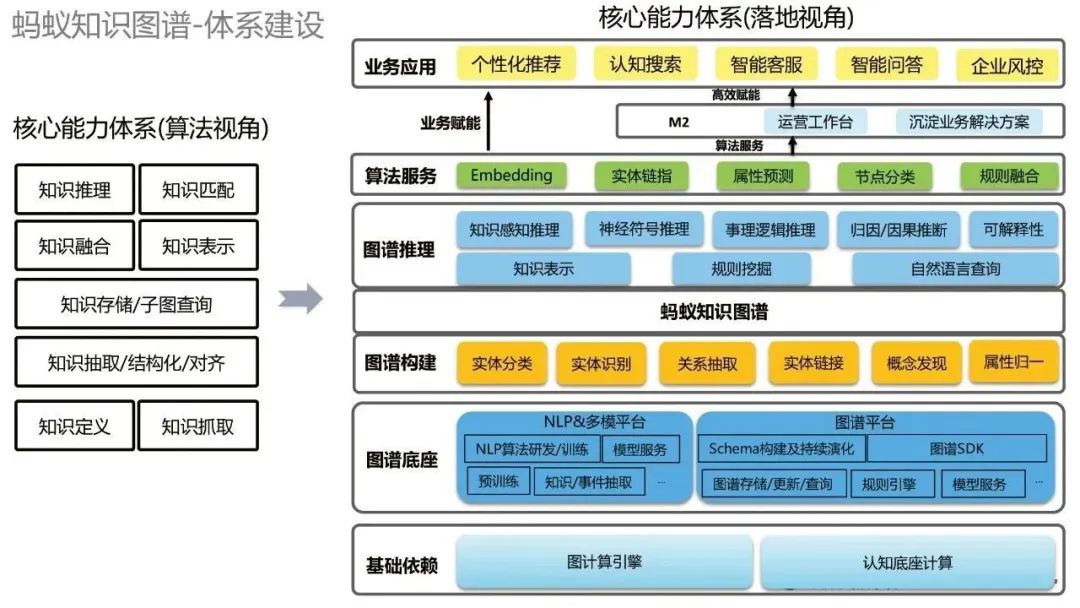
After we have a common construction paradigm, we need to carry out systematic construction. Look at the systematic construction of the Ant Knowledge Graph from two perspectives. First, from an algorithmic perspective, there are various algorithmic capabilities, such as knowledge reasoning, knowledge matching, etc. From the perspective of implementation, from bottom to top, the lowest basic dependencies include graph computing engine and cognitive base computing; above it is the graph base, including NLP & multi-modal platform and graph platform; above it are various graph construction technologies, Based on this, we can build the ant knowledge graph; on the basis of the knowledge graph, we can do some graph reasoning; further up, we provide some general algorithm capabilities; at the top are business applications.
2. Graph Construction
Next, we will share some of Ant Group’s core capabilities in building knowledge graphs, including graph construction, graph fusion, and graph cognition.
1. Graph construction
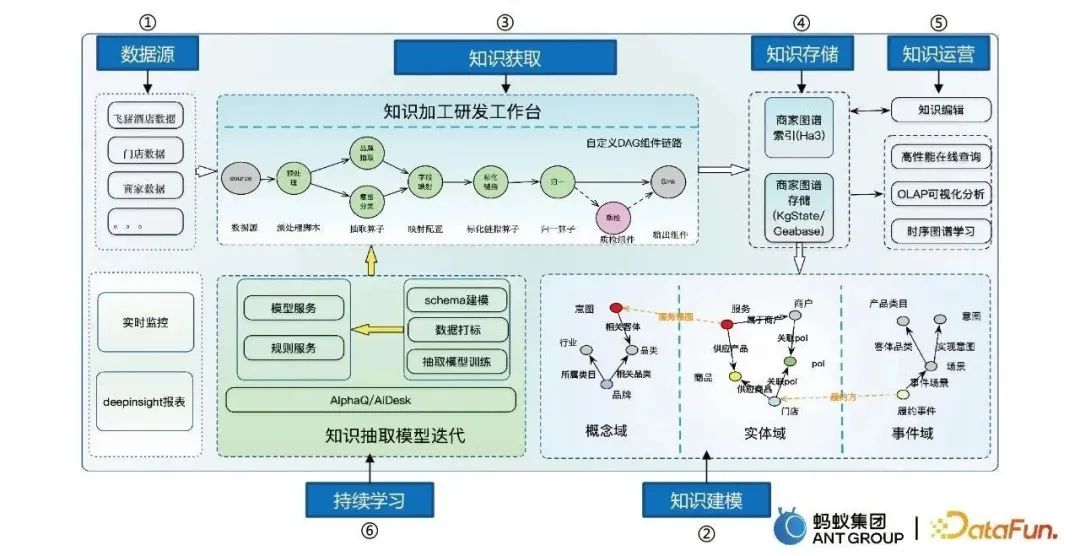
The graph construction process mainly includes six steps:
- Data source to obtain multivariate data.
- Knowledge modeling converts massive data into structured data and models it from the three domains of concepts, entities and events.
- Knowledge acquisition and building a knowledge processing R&D platform.
- Knowledge storage, including Ha3 storage and graph storage, etc.
- Knowledge operation, including knowledge editing, online query, extraction, etc.
- Continuous learning allows the model to automatically and iteratively learn.
Three experiences and skills in the construction process
Entity classification integrating expert knowledge
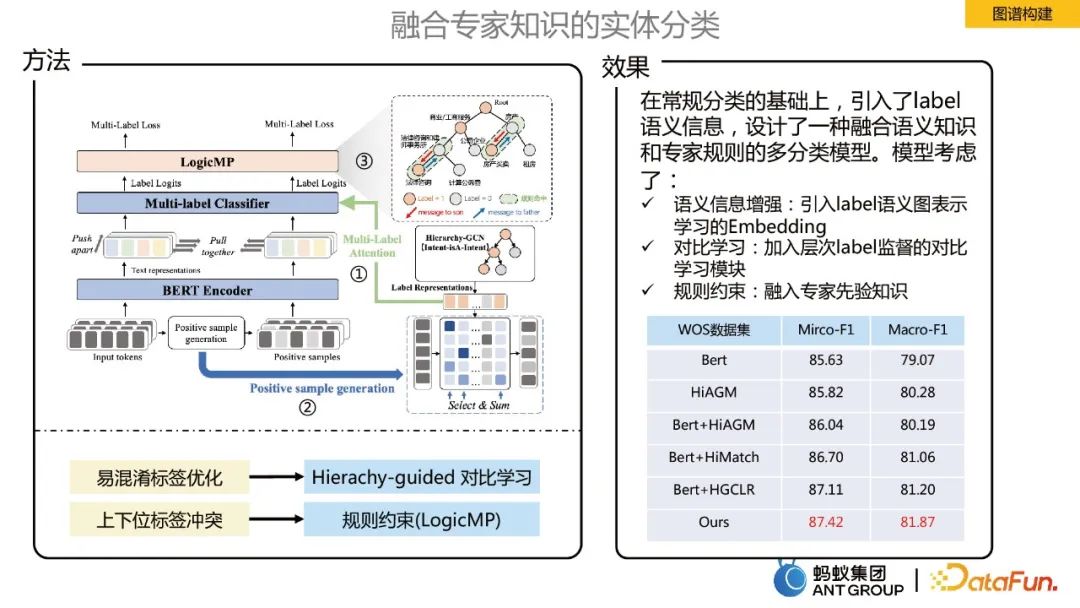
In building a knowledge graph, it is necessary to classify the input entities. In the ant scenario, it is a large-scale multi-label classification task. In order to integrate expert knowledge for entity classification, the following three optimizations are mainly made:
- Semantic information enhancement: Introduce Embedding of label semantic graph representation learning.
- Contrastive learning: Add hierarchical label supervision for comparison.
- Logical rule constraints: Incorporate expert prior knowledge.
Entity recognition injected into domain vocabulary
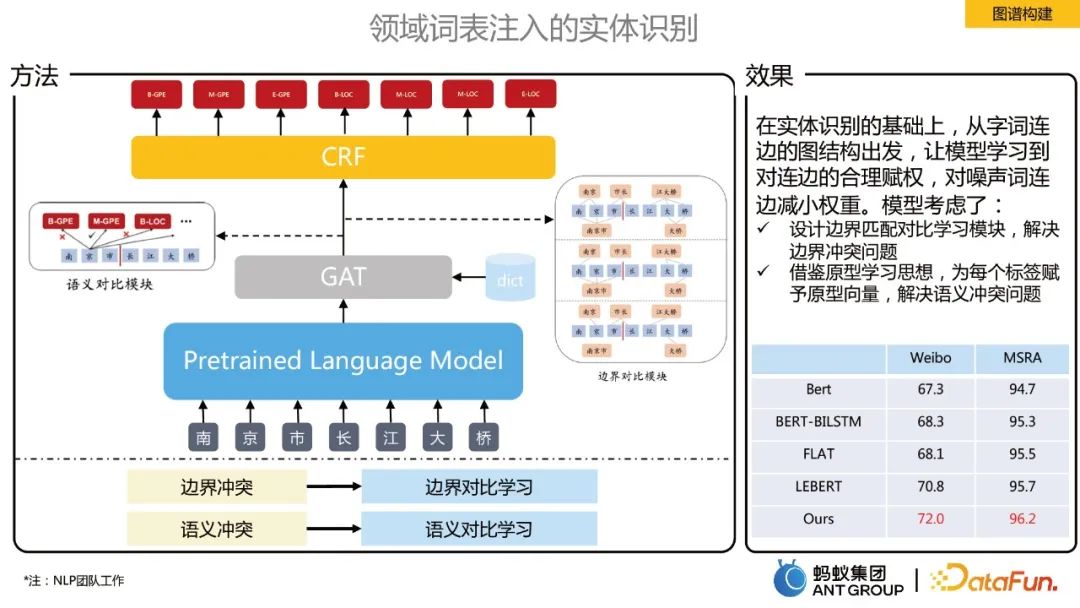
#On the basis of entity recognition, from word to edge Starting from the graph structure, the model learns reasonable weighting of the connected edges and reduces the weight of the noisy word connected edges. Two modules of boundary contrast learning and semantic contrast learning are proposed:
- Boundary contrast learning is used to solve boundary conflict problems. After the vocabulary is injected, a fully connected graph is constructed, and GAT is used to learn the representation of each token. The correct part of the boundary classification constructs a positive example graph, and the incorrect part constructs a negative example graph. Through comparison, the model learns each token. Boundary information of a token.
- #Semantic contrastive learning is used to solve semantic conflict problems. Drawing on the idea of prototype learning, the semantic representation of the label is added to strengthen the association between each token and the semantics of the label.
Small sample relationship extraction constrained by logical rules
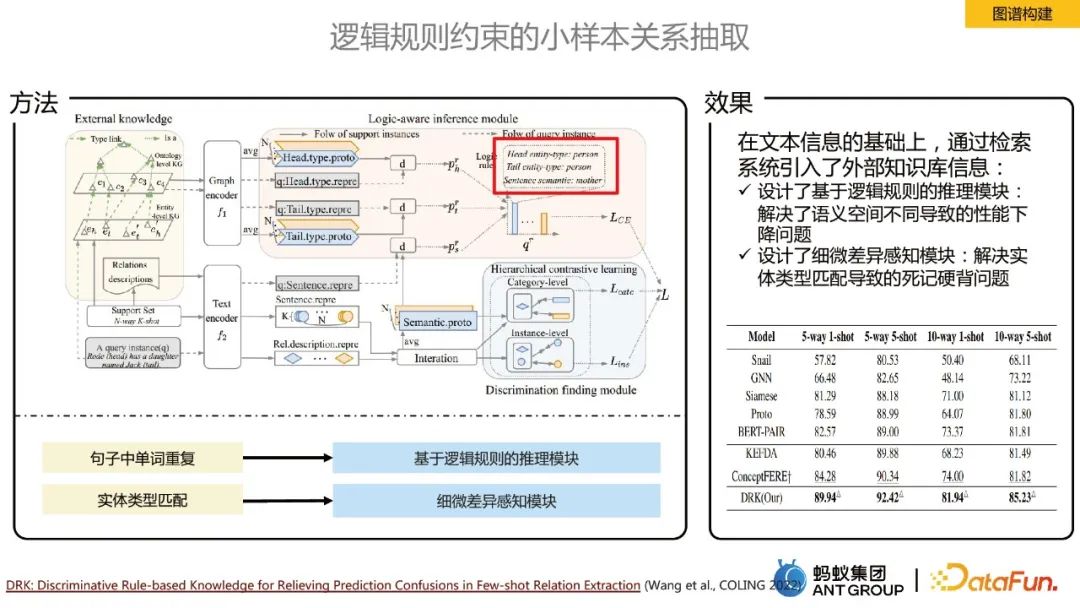
Our annotation samples are very large in domain issues If it is less, you will face a few-shot or zero-shot scenario. In this case, the core idea of relation extraction is to introduce an external knowledge base. In order to solve the problem of performance degradation caused by different semantic spaces, a reasoning module based on logical rules is designed. ;In order to solve the rote learning problem caused by entity type matching, a subtle difference perception module is designed.
2. Graph fusion
Graph fusion refers to the fusion of information between graphs in different business fields.
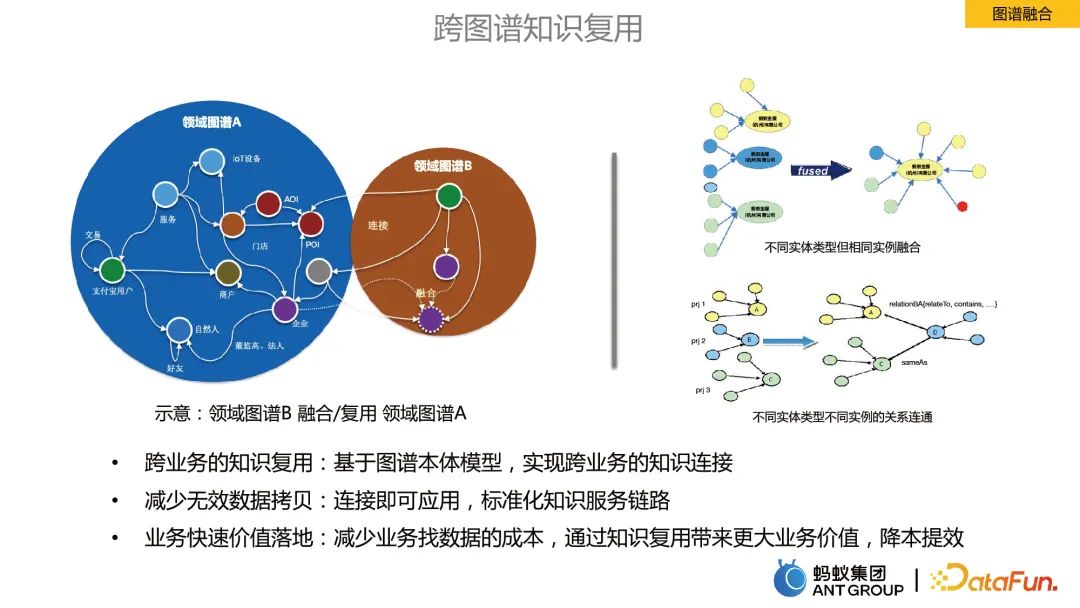
Benefits of graph fusion:
- Cross-business knowledge reuse: Based on the graph ontology model, Realize cross-business knowledge connection.
- # Reduce invalid data copies: apply immediately after connection, standardized knowledge service links.
- Rapid business value implementation: reduce the cost of finding data for the business, bring greater business value through knowledge reuse, reduce costs and improve efficiency.
Entity alignment in graph fusion
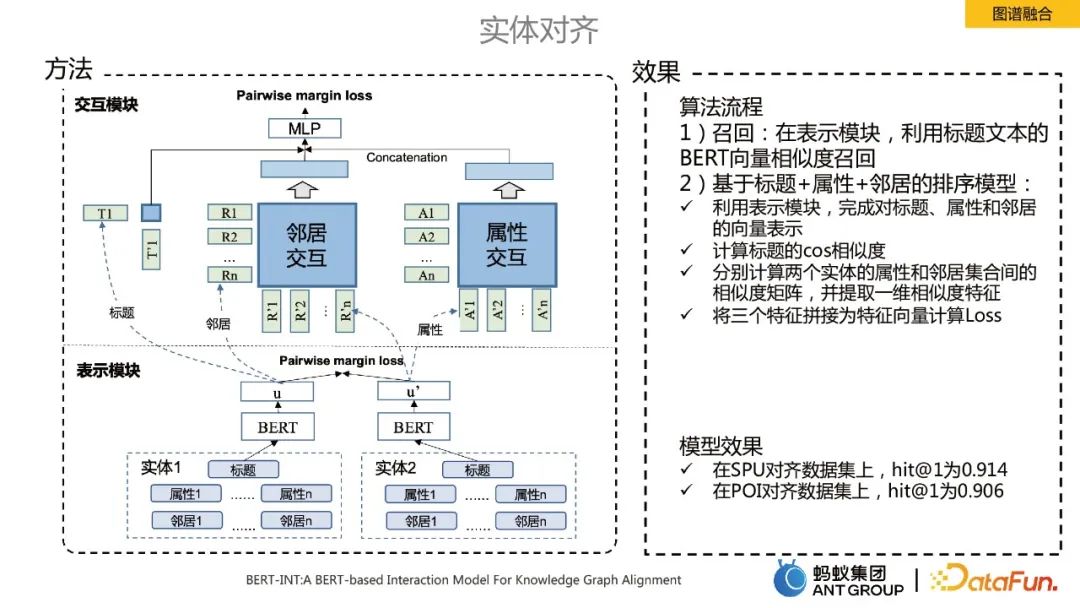
A core technical point in the knowledge graph fusion process is entity alignment. Here we use the SOTA algorithm BERT-INT, which mainly includes two modules, one is the presentation module and the other is the interaction module.
The implementation process of the algorithm mainly includes recall and sorting:
Recall: In the presentation module, the title text is used BERT vector similarity recall.
Sorting model based on title attribute neighbors: ü Use the representation module to complete the vector representation of titles, attributes and neighbors:
- Calculate the cos similarity of the title.
- Calculate the similarity matrix between the attributes and neighbor sets of two entities respectively, and extract one-dimensional similarity features.
- # Splice three features into a feature vector to calculate Loss.
3. Graph cognition
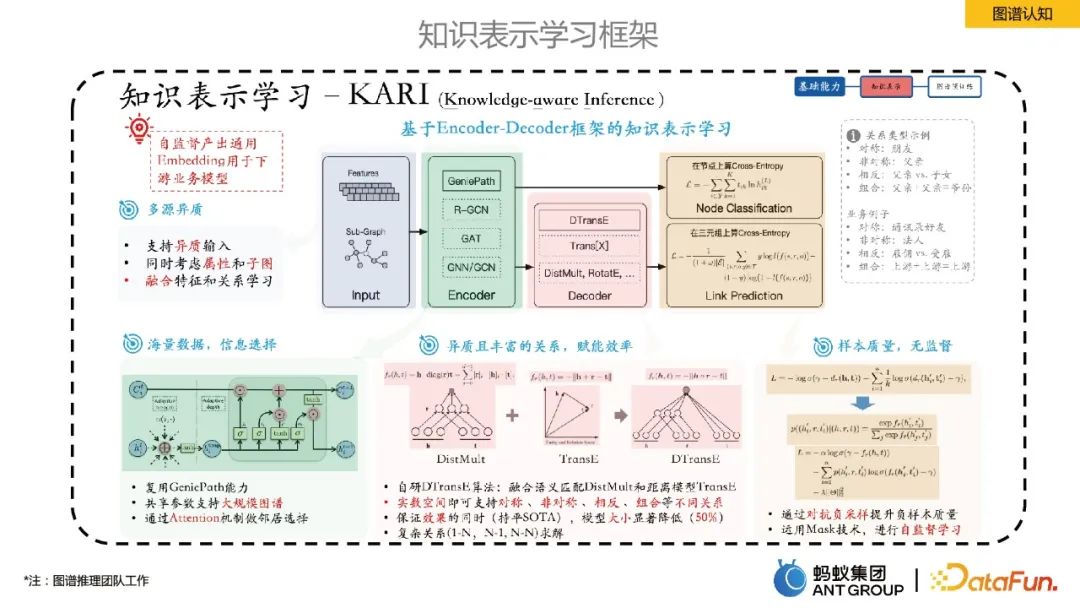
This part mainly introduces the internal knowledge representation learning of ants frame.
Ant proposed a knowledge representation learning based on the Encoder-Decoder framework. Among them, Encoder is some graph neural learning methods, and Decoder is some knowledge representation learning, such as link prediction. This representation learning framework can self-supervise the production of universal entity/relationship Embeddings, which has several benefits: 1) Embedding Size is much smaller than the original feature space, reducing storage costs; 2) Low-dimensional vectors are denser, effectively alleviating the problem of data sparseness. ; 3) Learning in the same vector space makes the fusion of heterogeneous data from multiple sources more natural; 4) Embedding has certain universality and is convenient for downstream business use.
3. Graph Application
Next, I will share some typical application cases of knowledge graph in Ant Group.
1. Scenario application modes of the graph
Before introducing specific cases, let’s first introduce several modes of scenario application of the Ant Knowledge Graph, including knowledge acquisition, Knowledge management and reasoning, and knowledge services. As shown below.
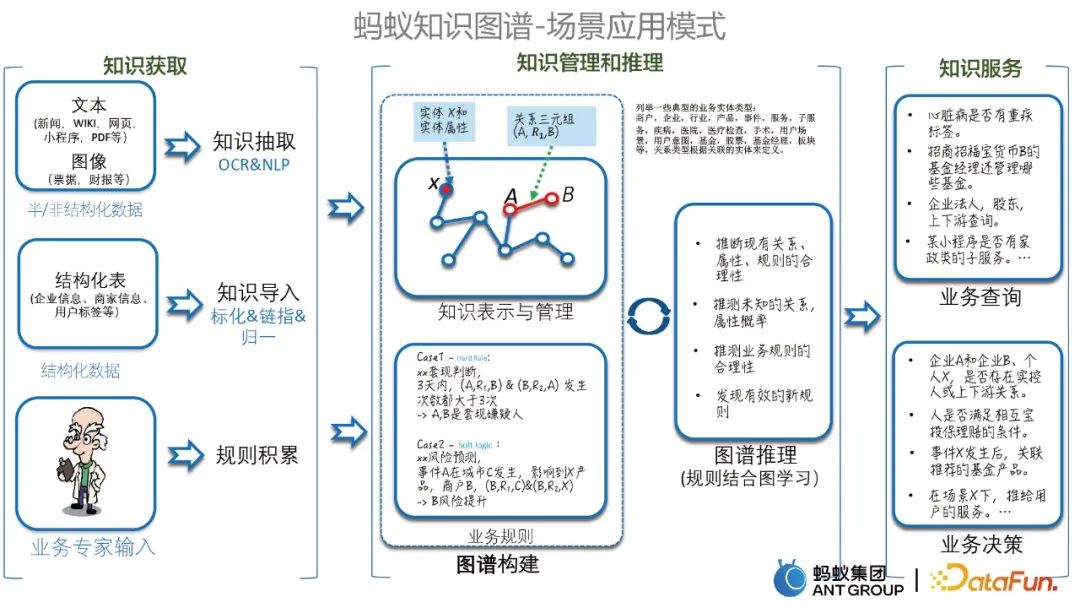
#2. Some typical cases
Case 1: Structured matching recall based on knowledge graph
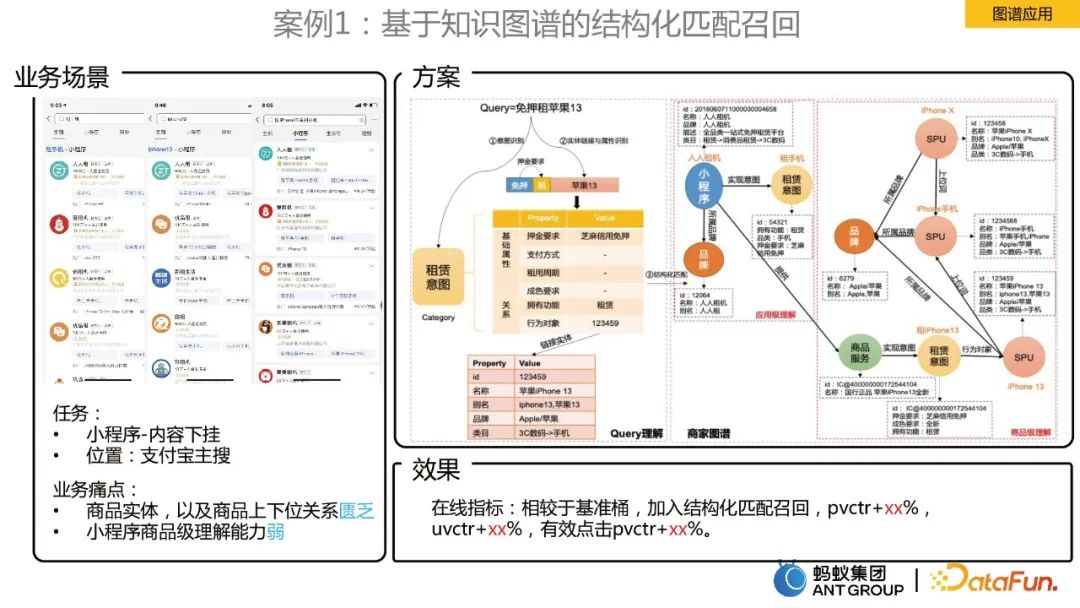
The business scenario is to download the content of the mini program in Alipay’s main search. The business pain points to be solved are:
- products There is a lack of entities, as well as the relationship between goods and products.
- #Weak product-level understanding of small programs.
#The solution is to build a merchant knowledge graph. Combined with the product relationship of the merchant map, a structured understanding of the user query product level is achieved.
Case 2: Real-time prediction of user intent in recommendation system
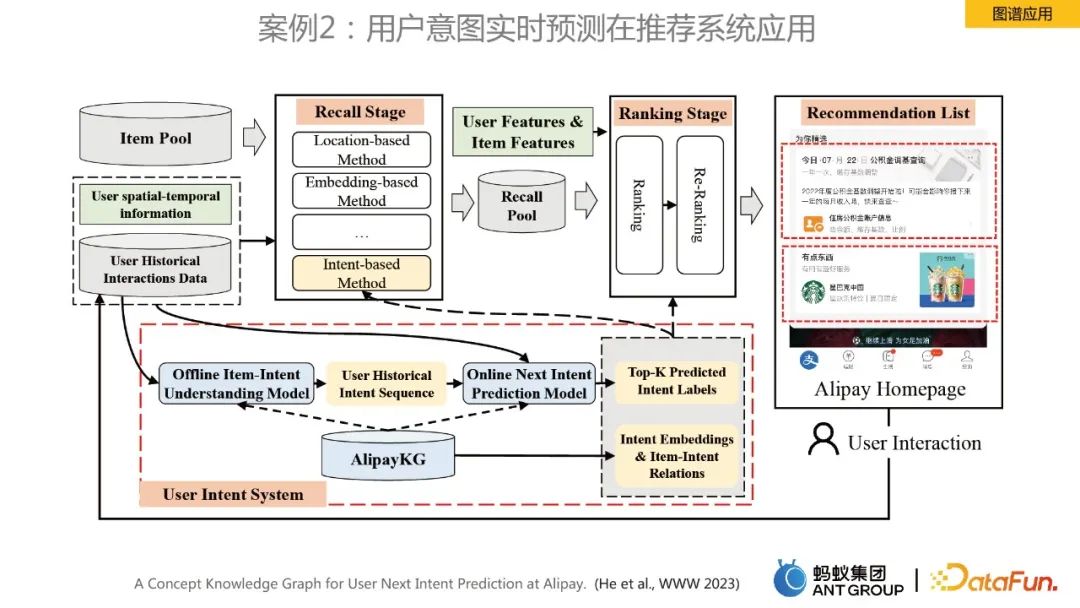
This case is for real-time prediction of user intent for homepage recommendations , AlipayKG was built, and the framework is shown in the figure above. Related work was also published on the top conference www 2023. You can refer to the paper for further understanding.
Case 3: Marketing coupon recommendation integrating knowledge representation
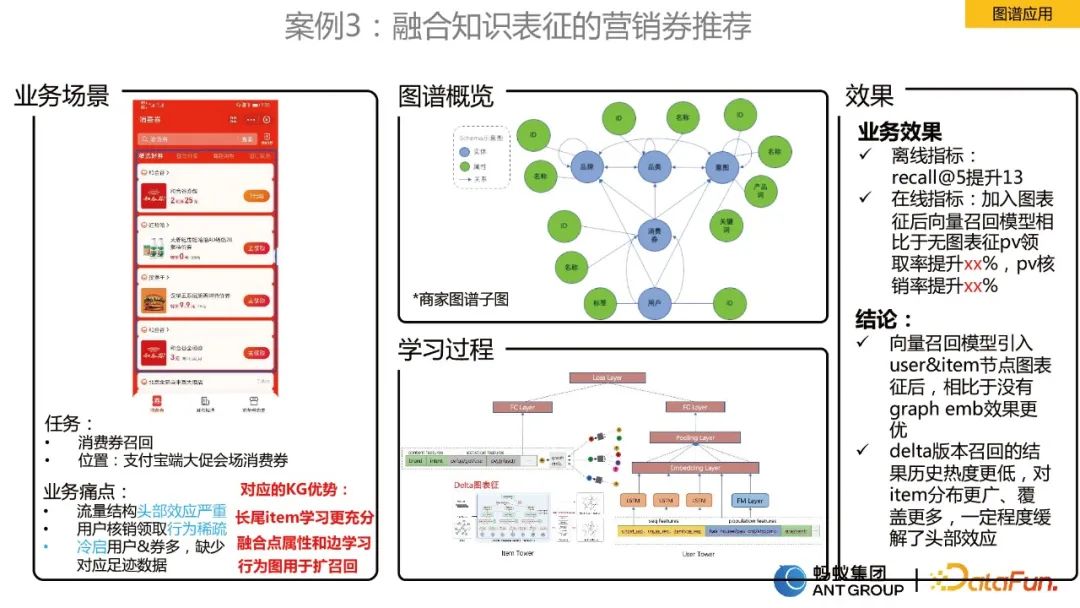
#This scenario is a scenario of consumer coupon recommendation, and the business faces The pain points are:
- The head effect is serious.
- # User verification and collection behavior is sparse.
- #There are many cold start users and coupons, but the corresponding footprint data is lacking.
#In order to solve the above problems, we designed a deep vector recall algorithm that integrates dynamic graph representation. Because we found that the behavior of user consumption coupons is cyclical, a static single edge cannot model this cyclical behavior. To this end, we first constructed a dynamic graph, and then used the team's self-developed dynamic graph algorithm to learn the Embedding representation. After obtaining the representation, we put it into the twin tower model for vector recall.
Case 4: Intelligent claims expert rule reasoning based on diagnosis and treatment events
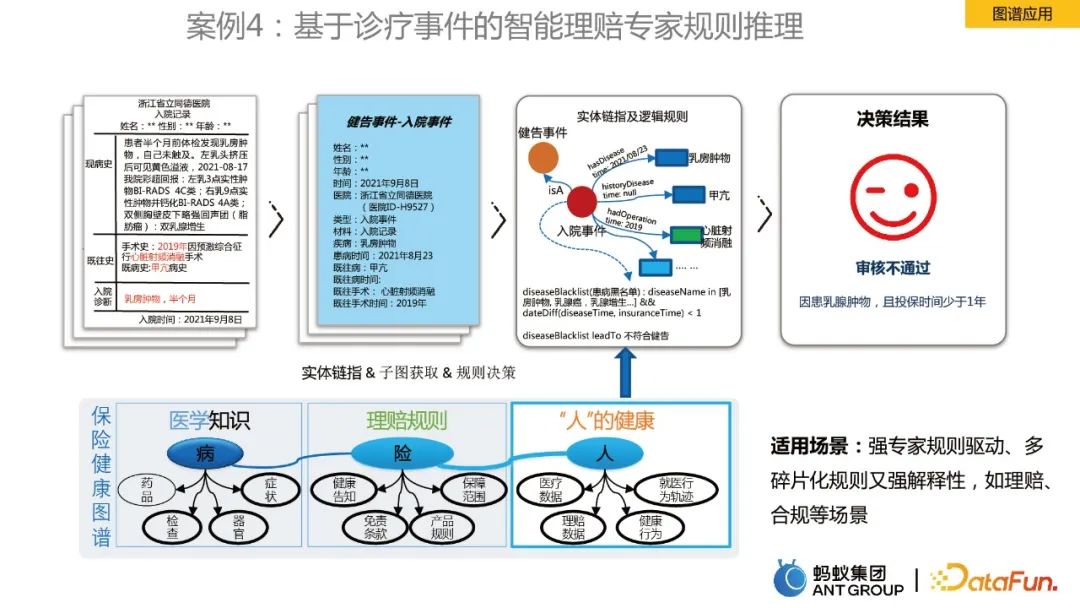
The last case is about graph rule reasoning. Taking the medical insurance health map as an example, it includes medical knowledge, claims rules, and "person" health information, which are linked to entities and coupled with logical rules as the basis for decision-making. Through the map, the efficiency of expert claims settlement has been improved.
4. Graphs and large models
Finally, let’s briefly discuss the opportunities of knowledge graphs in the context of the current rapid development of large models.
1. The relationship between knowledge graph and large model
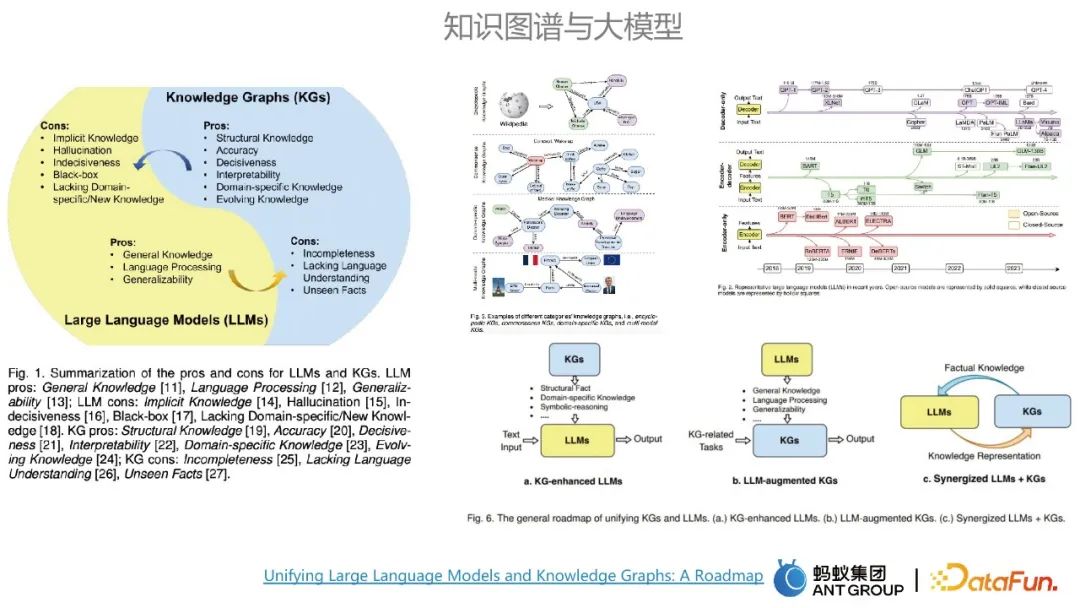
Knowledge graph and large model each have their own advantages and disadvantages. The main advantages of large model are It has the advantages of general knowledge modeling and universality, and the shortcomings of large models can be made up for by the advantages of knowledge graphs. The advantages of the map include high accuracy and strong interpretability. Large models and knowledge graphs can influence each other.
There are usually three routes to the integration of graphs and large models. One is to use knowledge graphs to enhance large models; the second is to use large models to enhance knowledge graphs; the third is to use knowledge graphs to enhance large models. The large model and the knowledge graph work together and complement each other. The large model can be considered as a parameterized knowledge base, and the knowledge graph can be considered as a displayed knowledge base.
2. Cases of application of large models and knowledge graphs
Application of large models to knowledge graph construction
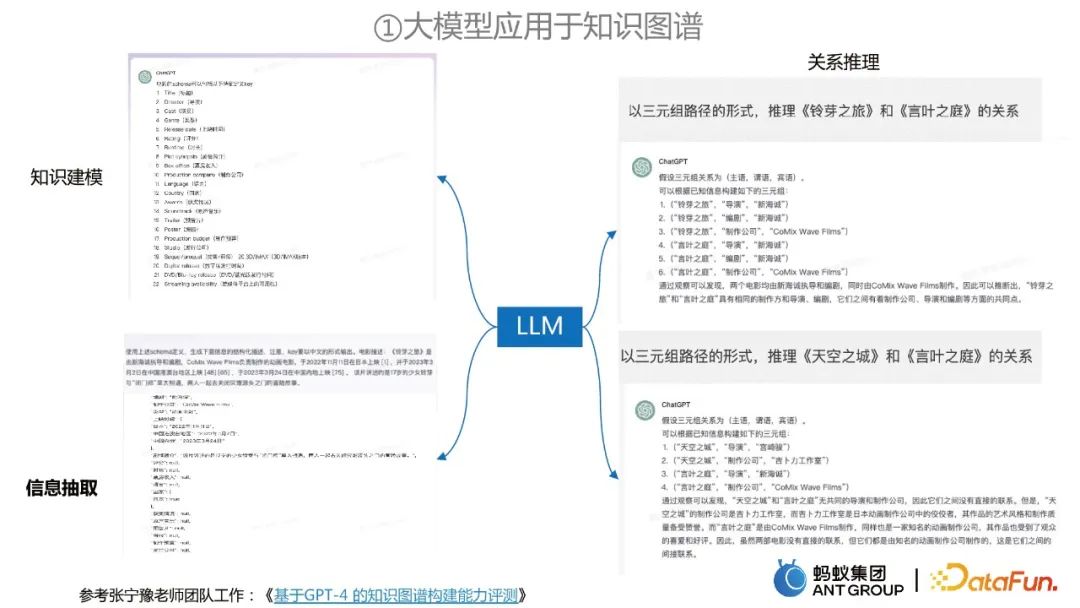
In the process of knowledge graph construction, large models can be used for information extraction, knowledge modeling and relationship reasoning.
How to use large models to apply to information extraction from knowledge graphs

This work of DAMO Academy decomposes the information extraction problem It becomes two stages:
- In the first stage, we want to find the entities, relationships or event types that exist in the text to reduce the search space and Computational complexity.
- #In the second stage, we further extract relevant information based on the previously extracted types and the given corresponding list.
Applying knowledge graph to large model
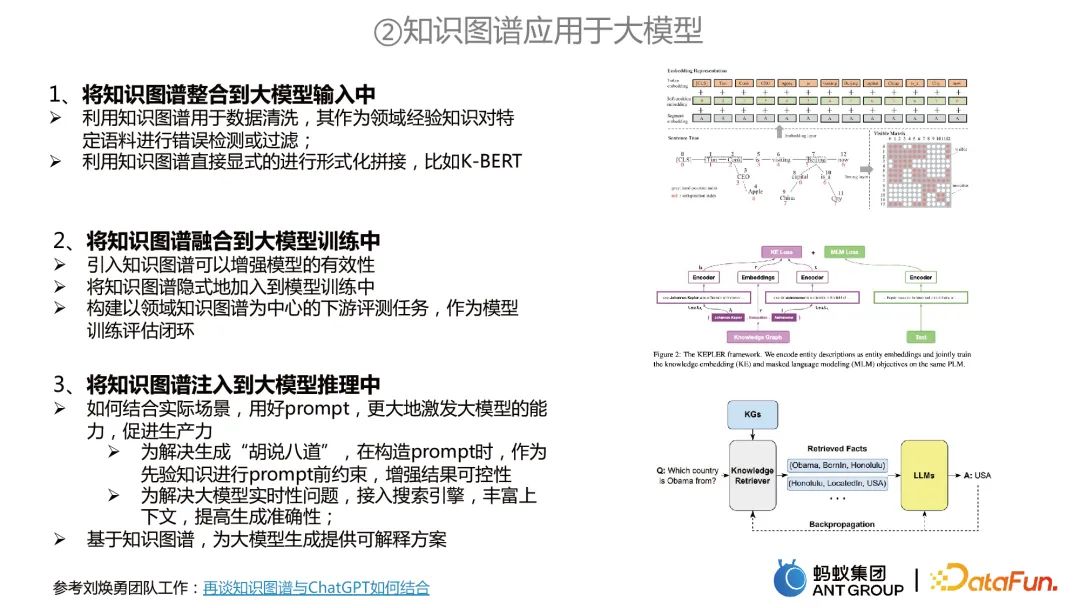
##Applying knowledge graph to large model mainly includes three aspects: Aspects:
Integrate the knowledge graph into the large model input. The knowledge graph can be used for data cleaning, or the knowledge graph can be used to directly perform formal splicing.
Integrate knowledge graph into large model training. For example, two tasks are trained at the same time. The knowledge graph can be used for knowledge representation tasks, and the large model can be used for pre-training of MLM, and the two are jointly modeled.
Inject knowledge graph into large model reasoning. First, two problems with large models can be solved. One is to use the knowledge graph as a priori constraints to avoid the "nonsense" of large models; the second is to solve the problem of timeliness of large models. On the other hand, based on knowledge graphs, interpretable solutions can be provided for large model generation.
Knowledge-enhanced question and answer system
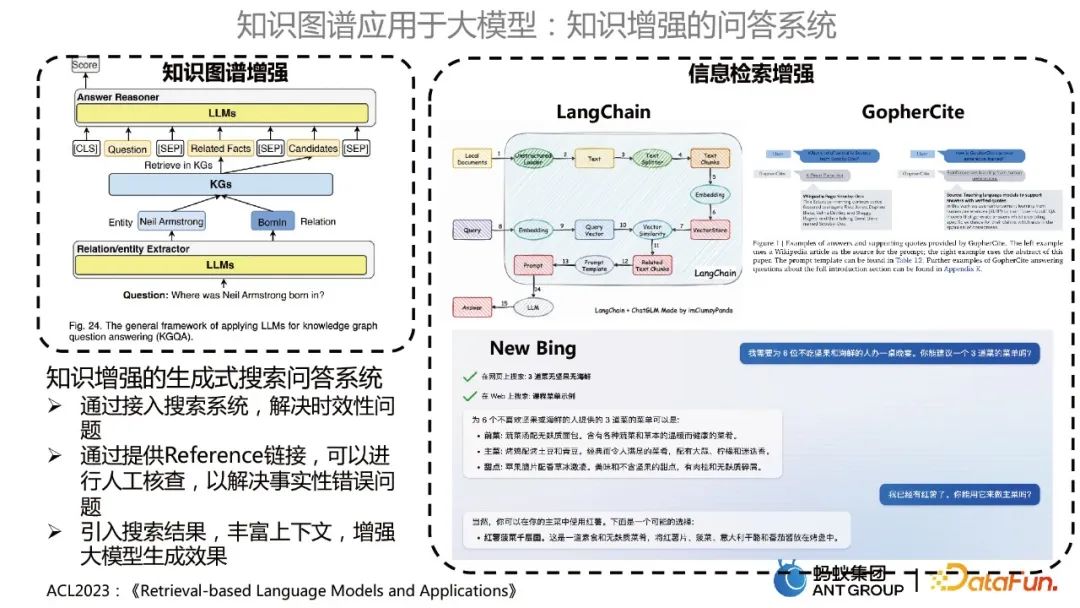
Mainly includes two categories. One is the knowledge graph-enhanced question and answer system, which uses a large model to optimize the KBQA model; The other is information retrieval enhancement, similar to how LangChain, GopherCite, New Bing, etc. use large models to do knowledge base question and answer.
The knowledge-enhanced generative search Q&A system has the following advantages:
- By accessing the search system, it solves Timeliness issues.
- By providing a Reference link, manual verification can be performed to resolve factual errors.
- #Introduces search results, enriches context, and enhances the effect of large model generation.
3. Summary and Outlook

How to better interact and collaborate with knowledge graphs and large models Progress includes the following three directions:
- Promote the in-depth application of knowledge graphs and large models in NLP, question answering systems and other fields.
- Use knowledge graphs for hallucination detection and detoxification of large models.
- Research and development of large domain models combined with knowledge graphs.
The above is the detailed content of Jia Qianghuai: Construction and application of large-scale knowledge graph of ants. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1389
1389
 52
52

 Methods and steps for using BERT for sentiment analysis in Python
Jan 22, 2024 pm 04:24 PM
Methods and steps for using BERT for sentiment analysis in Python
Jan 22, 2024 pm 04:24 PM
BERT is a pre-trained deep learning language model proposed by Google in 2018. The full name is BidirectionalEncoderRepresentationsfromTransformers, which is based on the Transformer architecture and has the characteristics of bidirectional encoding. Compared with traditional one-way coding models, BERT can consider contextual information at the same time when processing text, so it performs well in natural language processing tasks. Its bidirectionality enables BERT to better understand the semantic relationships in sentences, thereby improving the expressive ability of the model. Through pre-training and fine-tuning methods, BERT can be used for various natural language processing tasks, such as sentiment analysis, naming
 Analysis of commonly used AI activation functions: deep learning practice of Sigmoid, Tanh, ReLU and Softmax
Dec 28, 2023 pm 11:35 PM
Analysis of commonly used AI activation functions: deep learning practice of Sigmoid, Tanh, ReLU and Softmax
Dec 28, 2023 pm 11:35 PM
Activation functions play a crucial role in deep learning. They can introduce nonlinear characteristics into neural networks, allowing the network to better learn and simulate complex input-output relationships. The correct selection and use of activation functions has an important impact on the performance and training results of neural networks. This article will introduce four commonly used activation functions: Sigmoid, Tanh, ReLU and Softmax, starting from the introduction, usage scenarios, advantages, disadvantages and optimization solutions. Dimensions are discussed to provide you with a comprehensive understanding of activation functions. 1. Sigmoid function Introduction to SIgmoid function formula: The Sigmoid function is a commonly used nonlinear function that can map any real number to between 0 and 1. It is usually used to unify the
 Latent space embedding: explanation and demonstration
Jan 22, 2024 pm 05:30 PM
Latent space embedding: explanation and demonstration
Jan 22, 2024 pm 05:30 PM
Latent Space Embedding (LatentSpaceEmbedding) is the process of mapping high-dimensional data to low-dimensional space. In the field of machine learning and deep learning, latent space embedding is usually a neural network model that maps high-dimensional input data into a set of low-dimensional vector representations. This set of vectors is often called "latent vectors" or "latent encodings". The purpose of latent space embedding is to capture important features in the data and represent them into a more concise and understandable form. Through latent space embedding, we can perform operations such as visualizing, classifying, and clustering data in low-dimensional space to better understand and utilize the data. Latent space embedding has wide applications in many fields, such as image generation, feature extraction, dimensionality reduction, etc. Latent space embedding is the main
 Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Written previously, today we discuss how deep learning technology can improve the performance of vision-based SLAM (simultaneous localization and mapping) in complex environments. By combining deep feature extraction and depth matching methods, here we introduce a versatile hybrid visual SLAM system designed to improve adaptation in challenging scenarios such as low-light conditions, dynamic lighting, weakly textured areas, and severe jitter. sex. Our system supports multiple modes, including extended monocular, stereo, monocular-inertial, and stereo-inertial configurations. In addition, it also analyzes how to combine visual SLAM with deep learning methods to inspire other research. Through extensive experiments on public datasets and self-sampled data, we demonstrate the superiority of SL-SLAM in terms of positioning accuracy and tracking robustness.
 Understand in one article: the connections and differences between AI, machine learning and deep learning
Mar 02, 2024 am 11:19 AM
Understand in one article: the connections and differences between AI, machine learning and deep learning
Mar 02, 2024 am 11:19 AM
In today's wave of rapid technological changes, Artificial Intelligence (AI), Machine Learning (ML) and Deep Learning (DL) are like bright stars, leading the new wave of information technology. These three words frequently appear in various cutting-edge discussions and practical applications, but for many explorers who are new to this field, their specific meanings and their internal connections may still be shrouded in mystery. So let's take a look at this picture first. It can be seen that there is a close correlation and progressive relationship between deep learning, machine learning and artificial intelligence. Deep learning is a specific field of machine learning, and machine learning
 Advanced practice of industrial knowledge graph
Jun 13, 2024 am 11:59 AM
Advanced practice of industrial knowledge graph
Jun 13, 2024 am 11:59 AM
1. Background Introduction First, let’s introduce the development history of Yunwen Technology. Yunwen Technology Company...2023 is the period when large models are prevalent. Many companies believe that the importance of graphs has been greatly reduced after large models, and the preset information systems studied previously are no longer important. However, with the promotion of RAG and the prevalence of data governance, we have found that more efficient data governance and high-quality data are important prerequisites for improving the effectiveness of privatized large models. Therefore, more and more companies are beginning to pay attention to knowledge construction related content. This also promotes the construction and processing of knowledge to a higher level, where there are many techniques and methods that can be explored. It can be seen that the emergence of a new technology does not necessarily defeat all old technologies. It is also possible that the new technology and the old technology will be integrated with each other.
 From basics to practice, review the development history of Elasticsearch vector retrieval
Oct 23, 2023 pm 05:17 PM
From basics to practice, review the development history of Elasticsearch vector retrieval
Oct 23, 2023 pm 05:17 PM
1. Introduction Vector retrieval has become a core component of modern search and recommendation systems. It enables efficient query matching and recommendations by converting complex objects (such as text, images, or sounds) into numerical vectors and performing similarity searches in multidimensional spaces. From basics to practice, review the development history of Elasticsearch vector retrieval_elasticsearch As a popular open source search engine, Elasticsearch's development in vector retrieval has always attracted much attention. This article will review the development history of Elasticsearch vector retrieval, focusing on the characteristics and progress of each stage. Taking history as a guide, it is convenient for everyone to establish a full range of Elasticsearch vector retrieval.
 Super strong! Top 10 deep learning algorithms!
Mar 15, 2024 pm 03:46 PM
Super strong! Top 10 deep learning algorithms!
Mar 15, 2024 pm 03:46 PM
Almost 20 years have passed since the concept of deep learning was proposed in 2006. Deep learning, as a revolution in the field of artificial intelligence, has spawned many influential algorithms. So, what do you think are the top 10 algorithms for deep learning? The following are the top algorithms for deep learning in my opinion. They all occupy an important position in terms of innovation, application value and influence. 1. Deep neural network (DNN) background: Deep neural network (DNN), also called multi-layer perceptron, is the most common deep learning algorithm. When it was first invented, it was questioned due to the computing power bottleneck. Until recent years, computing power, The breakthrough came with the explosion of data. DNN is a neural network model that contains multiple hidden layers. In this model, each layer passes input to the next layer and
