
 Technology peripherals
AI
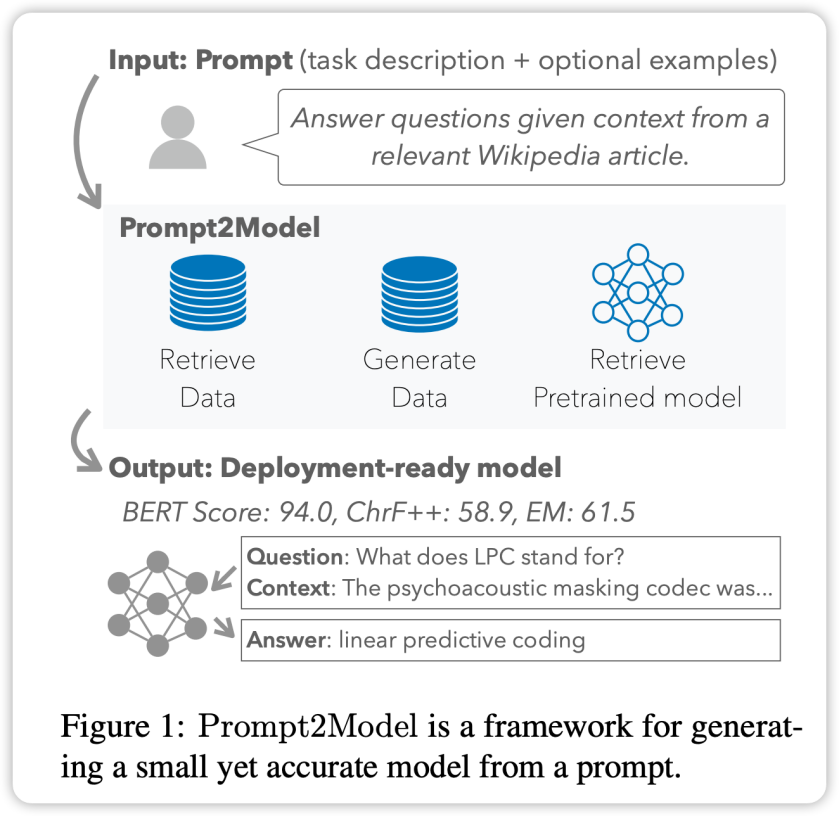
Quickly train small professional models: Just 1 command, $5, and 20 minutes, try Prompt2Model!
Technology peripherals
AI
Quickly train small professional models: Just 1 command, $5, and 20 minutes, try Prompt2Model!
Quickly train small professional models: Just 1 command, $5, and 20 minutes, try Prompt2Model!

Large-Scale Language Models (LLM) enable users to build powerful natural language processing systems through hints and contextual learning. However, from another perspective, LLM shows certain regression in some specific natural language processing tasks: the deployment of these models requires a lot of computing resources, and interacting with the models through APIs may raise potential privacy issues.
In order to deal with these problems, researchers from Carnegie Mellon University (CMU) and Tsinghua University jointly launched the Prompt2Model framework. The goal of this framework is to combine LLM-based data generation and retrieval methods to overcome the above challenges. Using the Prompt2Model framework, users can automatically collect data and efficiently train small specialized models suitable for specific tasks by simply providing the same prompts as LLM.
Researchers conducted an experiment , were studied on three natural language processing subtasks. They used a small number of sample prompts as input and spent only $5 to collect the data and 20 minutes of training. The performance of the model generated through the Prompt2Model framework is 20% higher than that of the powerful LLM model gpt-3.5-turbo. At the same time, the size of the model has shrunk 700 times. The researchers further verified the impact of these data on model performance in real-life scenarios, allowing model developers to estimate the reliability of the model before deployment. The framework has been provided in open source form:

- ## GitHub repository address of the framework: https:/ /github.com/neulab/prompt2model
- Framework demonstration video link: youtu.be/LYYQ_EhGd-Q
- Framework related paper link: https ://arxiv.org/abs/2308.12261
Background
Building systems for specific natural language processing tasks is often quite complex. of. The builder of the system needs to clearly define the scope of the task, obtain a specific data set, select an appropriate model architecture, train and evaluate the model, and then deploy it for practical application
Large-scale language models (LLM) such as GPT-3 provide a simpler solution to this process. Users only need to provide task instructions and some examples, and LLM can generate corresponding text output. However, generating text from hints can be computationally intensive, and using hints is less stable than a specially trained model. In addition, the usability of LLM is also limited by cost, speed, and privacy.
To solve these problems, researchers developed the Prompt2Model framework. This framework combines LLM-based data generation and retrieval techniques to overcome the above limitations. The system first extracts key information from prompt information, then generates and retrieves training data, and finally generates a specialized model ready for deployment
The Prompt2Model framework automatically performs the following core steps: 1. Data preprocessing: Clean and standardize the input data to ensure that it is suitable for model training. 2. Model selection: Select the appropriate model architecture and parameters according to the requirements of the task. 3. Model training: Use the preprocessed data to train the selected model to optimize the performance of the model. 4. Model evaluation: Performance evaluation of the trained model through evaluation indicators to determine its performance on specific tasks. 5. Model tuning: Based on the evaluation results, tune the model to further improve its performance. 6. Model deployment: Deploy the trained model to the actual application environment to achieve prediction or inference functions. By automating these core steps, the Prompt2Model framework can help users quickly build and deploy high-performance natural language processing models
- Dataset and model retrieval: Collect relevant datasets and pre- Train the model.
- Dataset generation: Use LLM to create pseudo-labeled datasets.
- Model fine-tuning: Fine-tune the model by mixing retrieved data and generated data.
- Model testing: Test the model on the test data set and the real data set provided by the user.
Through empirical evaluation on multiple different tasks, we found that the cost of Prompt2Model is significantly reduced, and the size of the model is also significantly reduced, but the performance exceeds gpt-3.5-turbo . The Prompt2Model framework can not only be used as a tool to efficiently build natural language processing systems, but also as a platform to explore model integration training technology
Framework
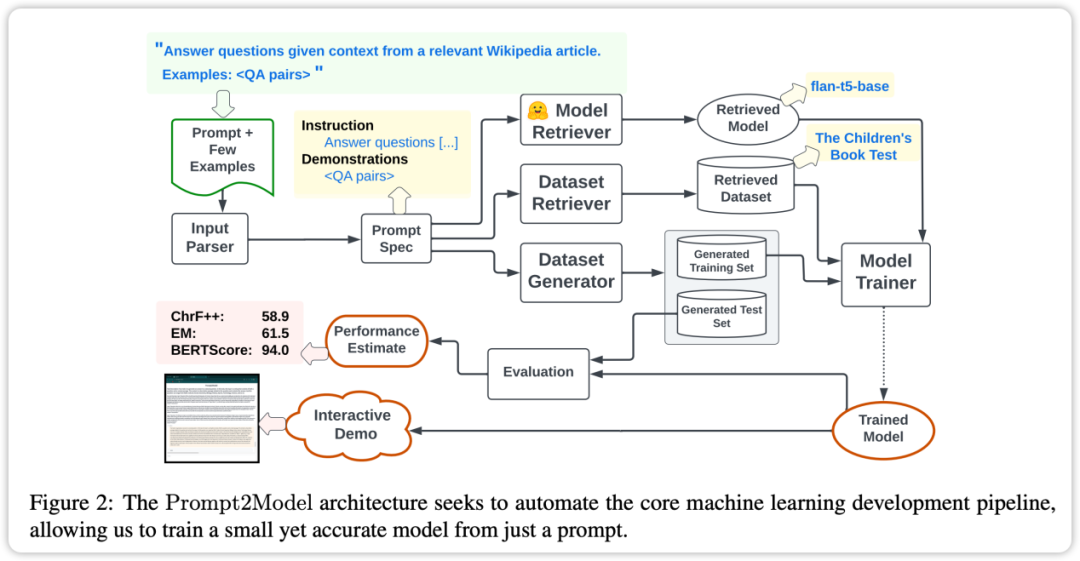
The core feature of the Prompt2Model framework is a high degree of automation. Its process includes data collection, model training, evaluation and deployment, as shown in the figure above. Among them, the automated data collection system plays a key role by obtaining data closely related to user needs through data set retrieval and LLM-based data generation. Next, the pre-trained model is retrieved and fine-tuned on the acquired dataset. Finally, the trained model is evaluated on the test set and a web user interface (UI) is created for interacting with the model
Key features of the Prompt2Model framework include:
- Prompt driver: The core idea of Prompt2Model is to use prompt as the driver. Users can directly describe the required tasks without in-depth understanding of the specific implementation details of machine learning.
- Automatic data collection: The framework uses data set retrieval and generation technology to obtain data that highly matches the user's tasks, thereby establishing the data sets required for training.
- Pre-trained model: The framework utilizes pre-trained models and fine-tunes them, thereby saving a lot of training costs and time.
- Effectiveness evaluation: Prompt2Model supports model testing and evaluation on actual data sets, allowing preliminary predictions and performance evaluations to be made before deploying the model, thus improving the reliability of the model.
The Prompt2Model framework has the following features, making it a powerful tool that can efficiently complete the building process of natural language processing systems and provide advanced features such as data Automatic collection, model evaluation, and creation of user interaction interface
Experiments and results
In order to evaluate the performance of the Prompt2Model system, in the experimental design, The researchers chose three different tasks
- Machine Reading QA: using SQuAD as the actual evaluation data set.
- Japanese NL-to-Code: Using MCoNaLa as the actual evaluation dataset.
- Temporal Expression Normalization: Use the Temporal data set as the actual evaluation data set.
In addition, the researchers also used GPT-3.5-turbo as a baseline model for comparison. The experimental results lead to the following conclusions:
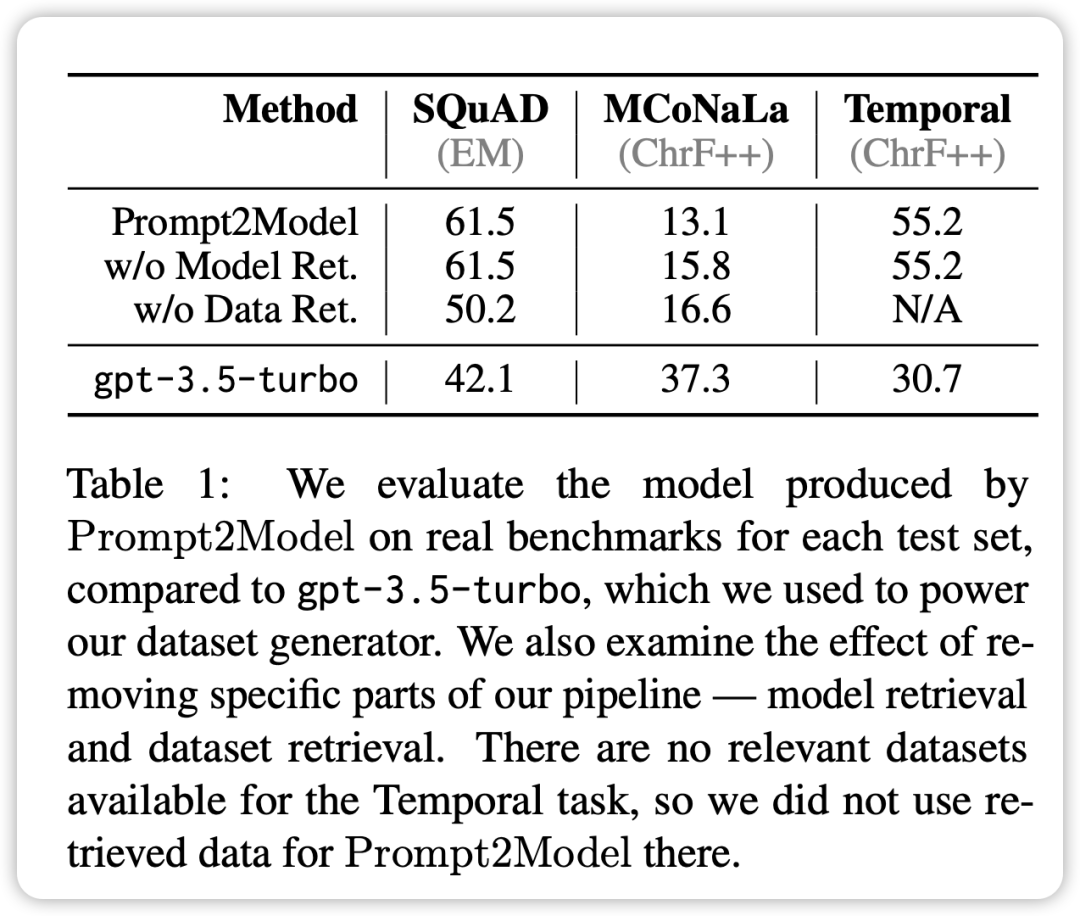
- In all tasks except the code generation task, the model generated by the Prompt2Model system is significantly better than the benchmark model GPT-3.5- turbo, although the generated model parameter size is much smaller than GPT-3.5-turbo.
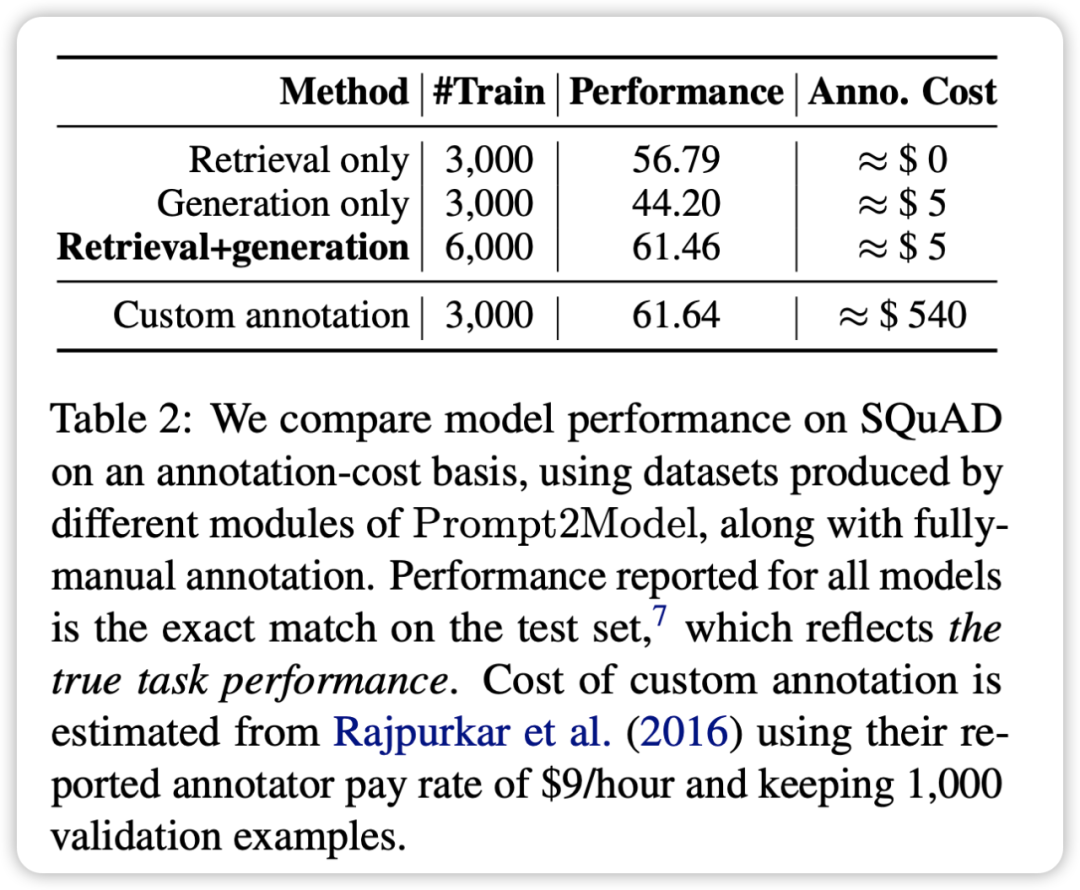
- By mixing the retrieval data set and the generated data set for training, you can achieve results comparable to directly using the actual data set for training. This verifies that the Prompt2Model framework can greatly reduce the cost of manual annotation.
- The test data set generated by the data generator can effectively distinguish the performance of different models on actual data sets. This indicates that the generated data is of high quality and has sufficient effectiveness in model training.
- The Prompt2Model system performs worse than GPT-3.5-turbo on the Japanese-to-code conversion task.
It may be caused by the low quality of the generated data set and the lack of appropriate pre-trained models
Comprehensive In general, the Prompt2Model system successfully generates high-quality small models on multiple tasks, greatly reducing the need for manual annotation of data. However, further improvements are still needed on some tasks
##Summary
The Prompt2Model framework is an innovative technology developed by a research team that automatically builds task-specific models through natural language prompts. The introduction of this technology greatly reduces the difficulty of building customized natural language processing models and further expands the application scope of NLP technology
The verification experiment results show that the size of the model generated by the Prompt2Model framework is significantly reduced compared to the larger language model, and it performs better than GPT-3.5-turbo and other models on multiple tasks. At the same time, the evaluation data set generated by this framework has also been proven to be effective in evaluating the performance of different models on real data sets. This provides important value in guiding the final deployment of the model
The Prompt2Model framework provides the industry and users with a low-cost, easy-to-use way to obtain NLP models that meet specific needs. . This is of great significance in promoting the widespread application of NLP technology. Future work will continue to be dedicated to further optimizing the performance of the framework
In order of the articles, the authors of this article are as follows: Rewritten content: According to the order of the articles, the authors of this article are as follows:
Vijay Viswanathan: http://www.cs.cmu.edu/~ vijayv/
Zhao Chenyang: https://zhaochenyang20.github.io/Eren_Chenyang_Zhao/
Amanda Bertsch: https://www.cs .cmu.edu/~abertsch/ Amanda Belsch: https://www.cs.cmu.edu/~abertsch/
Wu Tongshuang: https://www.cs.cmu.edu/~sherryw/
Graham Newbig: http://www.phontron.com/
The above is the detailed content of Quickly train small professional models: Just 1 command, $5, and 20 minutes, try Prompt2Model!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 What is the syntax for adding columns in SQL
Apr 09, 2025 pm 02:51 PM
What is the syntax for adding columns in SQL
Apr 09, 2025 pm 02:51 PM
The syntax for adding columns in SQL is ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value]; where table_name is the table name, column_name is the new column name, data_type is the data type, NOT NULL specifies whether null values are allowed, and DEFAULT default_value specifies the default value.
 SQL Clear Table: Performance Optimization Tips
Apr 09, 2025 pm 02:54 PM
SQL Clear Table: Performance Optimization Tips
Apr 09, 2025 pm 02:54 PM
Tips to improve SQL table clearing performance: Use TRUNCATE TABLE instead of DELETE, free up space and reset the identity column. Disable foreign key constraints to prevent cascading deletion. Use transaction encapsulation operations to ensure data consistency. Batch delete big data and limit the number of rows through LIMIT. Rebuild the index after clearing to improve query efficiency.
 Use DELETE statement to clear SQL tables
Apr 09, 2025 pm 03:00 PM
Use DELETE statement to clear SQL tables
Apr 09, 2025 pm 03:00 PM
Yes, the DELETE statement can be used to clear a SQL table, the steps are as follows: Use the DELETE statement: DELETE FROM table_name; Replace table_name with the name of the table to be cleared.
 phpmyadmin creates data table
Apr 10, 2025 pm 11:00 PM
phpmyadmin creates data table
Apr 10, 2025 pm 11:00 PM
To create a data table using phpMyAdmin, the following steps are essential: Connect to the database and click the New tab. Name the table and select the storage engine (InnoDB recommended). Add column details by clicking the Add Column button, including column name, data type, whether to allow null values, and other properties. Select one or more columns as primary keys. Click the Save button to create tables and columns.
 How to deal with Redis memory fragmentation?
Apr 10, 2025 pm 02:24 PM
How to deal with Redis memory fragmentation?
Apr 10, 2025 pm 02:24 PM
Redis memory fragmentation refers to the existence of small free areas in the allocated memory that cannot be reassigned. Coping strategies include: Restart Redis: completely clear the memory, but interrupt service. Optimize data structures: Use a structure that is more suitable for Redis to reduce the number of memory allocations and releases. Adjust configuration parameters: Use the policy to eliminate the least recently used key-value pairs. Use persistence mechanism: Back up data regularly and restart Redis to clean up fragments. Monitor memory usage: Discover problems in a timely manner and take measures.
 How to create an oracle database How to create an oracle database
Apr 11, 2025 pm 02:33 PM
How to create an oracle database How to create an oracle database
Apr 11, 2025 pm 02:33 PM
Creating an Oracle database is not easy, you need to understand the underlying mechanism. 1. You need to understand the concepts of database and Oracle DBMS; 2. Master the core concepts such as SID, CDB (container database), PDB (pluggable database); 3. Use SQL*Plus to create CDB, and then create PDB, you need to specify parameters such as size, number of data files, and paths; 4. Advanced applications need to adjust the character set, memory and other parameters, and perform performance tuning; 5. Pay attention to disk space, permissions and parameter settings, and continuously monitor and optimize database performance. Only by mastering it skillfully requires continuous practice can you truly understand the creation and management of Oracle databases.
 How to create oracle database How to create oracle database
Apr 11, 2025 pm 02:36 PM
How to create oracle database How to create oracle database
Apr 11, 2025 pm 02:36 PM
To create an Oracle database, the common method is to use the dbca graphical tool. The steps are as follows: 1. Use the dbca tool to set the dbName to specify the database name; 2. Set sysPassword and systemPassword to strong passwords; 3. Set characterSet and nationalCharacterSet to AL32UTF8; 4. Set memorySize and tablespaceSize to adjust according to actual needs; 5. Specify the logFile path. Advanced methods are created manually using SQL commands, but are more complex and prone to errors. Pay attention to password strength, character set selection, tablespace size and memory
 Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Effective monitoring of Redis databases is critical to maintaining optimal performance, identifying potential bottlenecks, and ensuring overall system reliability. Redis Exporter Service is a powerful utility designed to monitor Redis databases using Prometheus. This tutorial will guide you through the complete setup and configuration of Redis Exporter Service, ensuring you seamlessly build monitoring solutions. By studying this tutorial, you will achieve fully operational monitoring settings
