
 Technology peripherals
AI
New breakthrough in 'interactive generation of people and scenes'! Tianda University and Tsinghua University release Narrator: text-driven, naturally controllable | ICCV 2023
Technology peripherals
AI
New breakthrough in 'interactive generation of people and scenes'! Tianda University and Tsinghua University release Narrator: text-driven, naturally controllable | ICCV 2023
New breakthrough in 'interactive generation of people and scenes'! Tianda University and Tsinghua University release Narrator: text-driven, naturally controllable | ICCV 2023

Natural and controllable Human Scene Interaction (HSI) generation plays an important role in many fields such as virtual reality/augmented reality (VR/AR) content creation and human-centered artificial intelligence.
However, the existing methods have limited controllability, limited types of interactions, and unnatural generated results, which seriously limit their practical application scenarios
In research at ICCV 2023, teams from Tianjin University and Tsinghua University proposed a solution called Narrator to explore this problem. This solution focuses on the challenging task of naturally and controllably generating realistic and diverse human-scene interactions from textual descriptions
 Picture
Picture
Project homepage link: http://cic.tju.edu.cn/faculty/likun/projects/Narrator
The rewritten content is: Code link: https: //github.com/HaibiaoXuan/Narrator
From a human cognitive perspective, an ideal generative model should be able to correctly reason about spatial relationships and explore the degrees of freedom of interaction.
Therefore, the author proposes a generative model based on relational reasoning. This model models the spatial relationships in scenes and descriptions through scene graphs, and introduces a part-level interaction mechanism that represents interactive actions as atomic body part states
Especially , the author proposed a simple but effective multi-person generation strategy through relational reasoning, which is the first exploration of controllable multi-person scene interactive generation
Finally, after extensive experiments and User research, the author proved that Narrator can generate diverse interactions in a controllable way, and its effect is significantly better than the existing work
Method Motivation
Existing human-scene interaction generation methods mostly focus on the physical geometric relationship of interaction, but lack semantic control over generation and are limited to single-person generation.
Therefore, the authors focus on the challenging task of controllably generating realistic and diverse human-scene interactions from natural language descriptions. The authors observed that humans typically use spatial perception and action recognition to naturally describe people engaging in various interactions in different locations.
 Picture
Picture
The rewritten content is as follows: According to Figure 1, Narrator can naturally and controllably generate semantically consistent and physically reasonable Human-scene interaction is suitable for the following situations: (a) interaction guided by spatial relationships, (b) interaction guided by multiple actions, (c) multi-person scene interaction, and (d) combination of the above interaction types Human-scene interaction
Specifically, spatial relationships can be used to describe the mutual relationships between different objects in a scene or local area. The interactive actions are specified by the state of the atomic body parts, such as a person's feet on the ground, leaning on the torso, tapping with the right hand, lowering the head, etc.
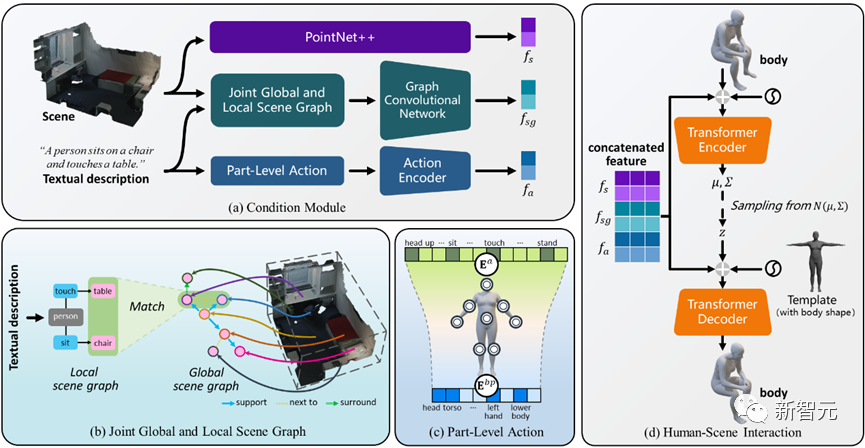
With this as a starting point, the author uses Scene graphs are used to represent spatial relationships, and the Joint Global and Local Scene Graph (JGLSG) mechanism is proposed to provide global position awareness for subsequent generation.
At the same time, considering that the state of body parts is the key to simulating realistic interactions consistent with the text, the author introduced the Part-Level Action (PLA) mechanism to establish human body parts and actions correspondence between them.
Benefiting from the effective observational cognition and the flexibility and reusability of the proposed relational reasoning, the author further proposes a simple and effective multi-person generation strategy, which was then The first naturally controllable and user-friendly multi-Human Scene Interaction (MHSI) generation solution.
Method ideas
Overview of Narrator framework
The goal of Narrator is to be natural and controllable way to generate interactions between characters and scenes that are semantically consistent with textual descriptions and physically match the three-dimensional scene
 Picture
Picture
Figure 2 Narrator framework overview
As shown in Figure 2, this method uses a Transformer-based conditional variational autoencoder (cVAE), which mainly includes the following Several parts:
Compared with existing research, we design a joint global and local scene graph mechanism to reason about complex spatial relationships and achieve global positioning awareness
2) Based on the observation that people will complete interactive actions through different body parts at the same time, a component-level action mechanism is introduced to achieve realistic and diverse interactions;
During the scene-aware optimization process, we additionally introduced interactive bifacial loss in order to obtain better generation results
4) Further extends to multi-person interaction generation, and ultimately promotes the first step in multi-person scene interaction.
Combined global and local scene graph mechanism
The reasoning of spatial relationships can provide the model with clues about specific scenes, which is important for realizing human-scene interaction. The natural controllability plays an important role.
To achieve this goal, the author proposes a global and local scene graph joint mechanism, which is implemented through the following three steps:
1. Global scene graph generation: Given a scene, use a pre-trained scene graph model to generate a global scene graph, that is, 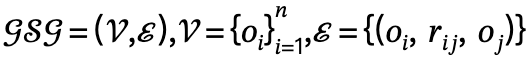 , where
, where 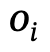 ,
, 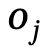 are objects with category labels,
are objects with category labels, 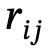 is the relationship between
is the relationship between 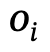 and
and 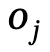 , n is the number of objects, m is the number of relationships;
, n is the number of objects, m is the number of relationships;
2. Local scene graph generation: Use semantic analysis tools to identify and describe The sentence structure is extracted and generated to generate a local scene 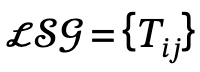 , where
, where 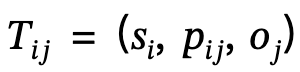 defines the triplet of subject-predicate-object;
defines the triplet of subject-predicate-object;
Scene graph matching: through the same object semantics Label, the model corresponds to the nodes in the global scene graph and the local scene graph, and adds a virtual human node by extending the edge relationship to provide location information
Component Level Action (PLA ) Mechanism
The author proposes a fine-grained part-level action mechanism through which the model is able to notice important body part states and ignore irrelevant parts from a given interaction
Specifically, the author explores rich and diverse interactive actions and maps these possible actions to five main parts of the human body: head, torso, left/right arm , left/right hand and left/right lower body.
In subsequent encoding, we can use One-Hot to represent these actions and body parts at the same time, and connect them according to the corresponding relationship
The author uses an attention mechanism in the interaction generation of multi-actions to learn the status of different parts of the body structure
In a given combination of interactive actions , the attention between the body part corresponding to each action and all other actions is automatically blocked.
Take "a person squatting on the ground using a cabinet" as an example. Squatting corresponds to the lower body state, so the attention marked by other parts will be blocked to zero. Rewritten content: Take "a person squatting on the ground using a cabinet" as an example. Squatting corresponds to the state of the lower body, so the attention of other body parts will be completely blocked
Scene-aware optimization
The author uses geometric and physical constraints to perform scene-aware optimization to improve the generation results. Throughout the optimization process, this method ensures that the generated pose does not deviate, while encouraging contact with the scene and constraining the body to avoid interpenetration with the scene
Given a three-dimensional scene S After adding the generated SMPL-X parameters, the optimization loss is:
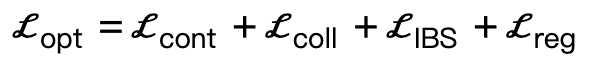
Among them, 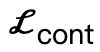 encourages body vertices to contact the scene;
encourages body vertices to contact the scene; 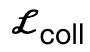 is a collision term based on signed distance;
is a collision term based on signed distance; 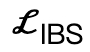 is an interactive bipartite (IBS) loss introduced additionally compared to existing work, which is sampled from A collection of equidistant points between the scene and the human body;
is an interactive bipartite (IBS) loss introduced additionally compared to existing work, which is sampled from A collection of equidistant points between the scene and the human body; 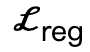 is a regularization factor used to penalize parameters that deviate from initialization.
is a regularization factor used to penalize parameters that deviate from initialization.
Multi-person scene interaction (MHSI)
In real-world scenes, in many cases there is not only one person interacting with the scene, but multiple people interacting independently or interact in a relational manner.
However, due to the lack of MHSI datasets, existing methods usually require additional manual efforts and cannot handle this task in a controlled and automatic manner.
To this end, the author only utilizes the existing single-person data set and proposes a simple and effective strategy for multi-person generation direction.
After given a multi-person related text description, the author first parses it into multiple local scene graphs 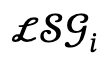 and interactive actions
and interactive actions 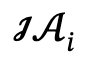 , and defines the candidate set as
, and defines the candidate set as 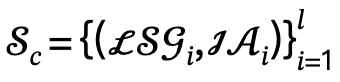 , where l is the number of people.
, where l is the number of people.
For each item in the candidate set, it is first input into Narrator together with the scene 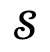 and the corresponding global scene graph
and the corresponding global scene graph 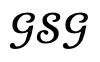 , and then the optimization process is performed.
, and then the optimization process is performed.
In order to handle collisions between people, an additional loss 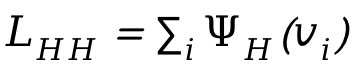 is introduced during the optimization process, where
is introduced during the optimization process, where 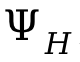 is the symbolic distance between people.
is the symbolic distance between people.
Then, when the optimization loss is lower than the threshold determined based on experimental experience, the generated result is accepted and updated by adding human nodes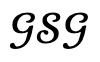 ; otherwise, the generated result is considered untrustworthy and the corresponding object is shielded node to update
; otherwise, the generated result is considered untrustworthy and the corresponding object is shielded node to update 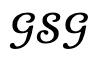 .
.
It is worth noting that this update method establishes the relationship between the results of each generation and the results of the previous generation, avoids a certain degree of crowding, and is consistent with simple multiple generation. More reasonable and interactive than spatial distribution.
The above process can be expressed as:
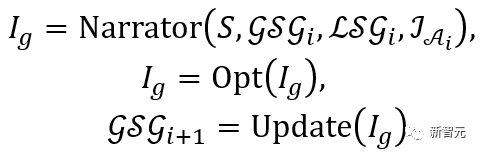
In view of the fact that the existing methods cannot naturally and controllably generate human-scene interactions directly from text descriptions, we use PiGraph [1], POSA [2], and COINS [3] to reasonably extended to work with textual descriptions and used the same dataset to train their official models. After modification, we named these methods PiGraph-Text, POSA-Text and COINS-Text
 Picture
Picture
Figure 3 Qualitative comparison results of different methods
Narrator and three baselines are shown in Figure 3 Qualitative comparison results. Due to the representation limitations of PiGraph-Text, it has more serious penetration problems
POSA-Text often falls into local minima during the optimization process, resulting in bad interactive contacts. COINS-Text binds actions to specific objects, lacks global awareness of the scene, leads to penetration with unspecified objects, and is difficult to handle complex spatial relationships.
In contrast, Narrator can correctly reason about spatial relationships based on different levels of text descriptions, and analyze body states under multiple actions, thereby achieving better generation results.
In terms of quantitative comparison, as shown in Table 1, Narrator outperforms other methods on five indicators, showing that the results generated by this method have more accurate text consistency and Better physical plausibility.
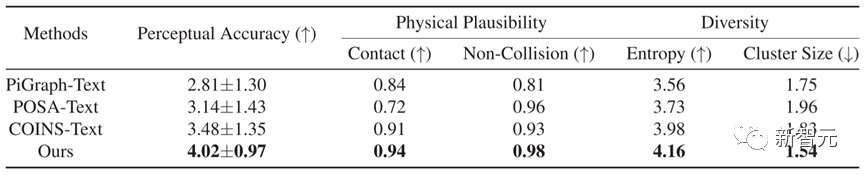 Table 1 Quantitative comparison results of different methods
Table 1 Quantitative comparison results of different methods
In addition, the author also provides Detailed comparison and analysis are conducted to better understand the effectiveness of the proposed MHSI strategy.
Considering that there is currently no work on MHSI, they chose a straightforward approach as a baseline, namely sequential generation and optimization with COINS.
In order to make a fair comparison, artificial collision losses are also introduced. Figure 4 and Table 2 show the qualitative and quantitative results respectively, both of which strongly prove that the strategy proposed by the author is semantically consistent and physically reasonable on MHSI.
 Figure 4 Qualitative comparison with MHSI using COINS sequential generation and optimization method
Figure 4 Qualitative comparison with MHSI using COINS sequential generation and optimization method

About the author




##The research direction mainly focuses on human-centered computer vision and graphics


Main research directions: three-dimensional vision, intelligent reconstruction and generation
Personal homepage: http://cic .tju.edu.cn/faculty/likun
References:
[1] Savva M, Chang A X, Hanrahan P, et al. Pigraphs: From Observation Learning interactive snapshots[J]. ACM Transactions on Graphics (TOG), 2016, 35(4): 1-12.
[2] Hassan M, Ghosh P, Tesch J, et al. Populating 3D scenes by learning human-scene interaction[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 14708-14718.
[3] Zhao K, Wang S, Zhang Y, et al . Compositional human-scene interaction synthesis with semantic control[C]. European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022: 311-327.
The above is the detailed content of New breakthrough in 'interactive generation of people and scenes'! Tianda University and Tsinghua University release Narrator: text-driven, naturally controllable | ICCV 2023. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 The perfect guide to Tsinghua Mirror Source: Make your software installation smoother
Jan 16, 2024 am 10:08 AM
The perfect guide to Tsinghua Mirror Source: Make your software installation smoother
Jan 16, 2024 am 10:08 AM
Tsinghua mirror source usage guide: To make your software installation smoother, specific code examples are needed. In the process of daily use of computers, we often need to install various software to meet different needs. However, when installing software, we often encounter problems such as slow download speed and inability to connect, especially when using foreign mirror sources. In order to solve this problem, Tsinghua University provides a mirror source, which provides rich software resources and has very fast download speed. Next, let us learn about the usage strategy of Tsinghua mirror source. first,
 In what scenarios does ClassCastException occur in Java?
Jun 25, 2023 pm 09:19 PM
In what scenarios does ClassCastException occur in Java?
Jun 25, 2023 pm 09:19 PM
Java is a strongly typed language that requires data type matching at runtime. Due to Java's strict type conversion mechanism, if there is a data type mismatch in the code, a ClassCastException will occur. ClassCastException is one of the very common exceptions in the Java language. This article will introduce the causes of ClassCastException and how to avoid it. What is ClassCastException
 Have you used these stress testing tools for Linux systems?
Mar 21, 2024 pm 04:12 PM
Have you used these stress testing tools for Linux systems?
Mar 21, 2024 pm 04:12 PM
As an operation and maintenance personnel, have you ever encountered this scenario? You need to use tools to test high system CPU or memory usage to trigger alarms, or test the concurrency capabilities of the service through stress testing. As an operation and maintenance engineer, you can also use these commands to reproduce fault scenarios. Then this article can help you master commonly used testing commands and tools. 1. Introduction In some cases, in order to locate and reproduce problems in the project, tools must be used to conduct systematic stress testing to simulate and restore fault scenarios. At this time testing or stress testing tools become particularly important. Next, we will explore the use of these tools according to different scenarios. 2. Test Tools 2.1 Network speed limiting tool tctc is a command line tool used to adjust network parameters in Linux. It can be used to simulate various networks.
 In two sentences, let AI generate VR scenes! Or the kind of 3D or HDR panorama?
Apr 12, 2023 am 09:46 AM
In two sentences, let AI generate VR scenes! Or the kind of 3D or HDR panorama?
Apr 12, 2023 am 09:46 AM
Big Data Digest Produced by: Caleb Recently, ChatGPT can be said to be extremely popular. On November 30, OpenAI released the chat robot ChatGPT and opened it to the public for free for testing. Since then, it has been widely used in China. To talk to a robot is to ask the robot to execute a certain instruction, such as entering a keyword and letting the AI generate the corresponding picture. This doesn’t seem to be unusual. Didn’t OpenAI also update a new version of DALL-E in April? OpenAI, how old are you? (Why is it always you?) What if Digest said that the generated images are 3D images, HDR panoramas, or VR-based image content? Recently, Singapore
 Tsinghua Optics AI appears in Nature! Physical neural network, backpropagation is no longer needed
Aug 10, 2024 pm 10:15 PM
Tsinghua Optics AI appears in Nature! Physical neural network, backpropagation is no longer needed
Aug 10, 2024 pm 10:15 PM
Using light to train neural networks, Tsinghua University results were recently published in Nature! What should I do if I cannot apply the backpropagation algorithm? They proposed a Fully Forward Mode (FFM) training method that directly performs the training process in the physical optical system, overcoming the limitations of traditional digital computer simulations. To put it simply, it used to be necessary to model the physical system in detail and then simulate these models on a computer to train the network. The FFM method eliminates the modeling process and allows the system to directly use experimental data for learning and optimization. This also means that training no longer needs to check each layer from back to front (backpropagation), but can directly update the parameters of the network from front to back. To use an analogy, like a puzzle, backpropagation
 Learn to use common Kafka commands and flexibly respond to various scenarios.
Jan 31, 2024 pm 09:22 PM
Learn to use common Kafka commands and flexibly respond to various scenarios.
Jan 31, 2024 pm 09:22 PM
Essentials for learning Kafka: master common commands and easily cope with various scenarios 1. Create Topicbin/kafka-topics.sh--create--topicmy-topic--partitions3--replication-factor22. List Topicbin/kafka-topics.sh --list3. View Topic details bin/kafka-to
 Let's talk about the model fusion method of large models
Mar 11, 2024 pm 01:10 PM
Let's talk about the model fusion method of large models
Mar 11, 2024 pm 01:10 PM
In previous practices, model fusion has been widely used, especially in discriminant models, where it is considered a method that can steadily improve performance. However, for generative language models, the way they operate is not as straightforward as for discriminative models because of the decoding process involved. In addition, due to the increase in the number of parameters of large models, in scenarios with larger parameter scales, the methods that can be considered by simple ensemble learning are more limited than low-parameter machine learning, such as classic stacking, boosting and other methods, because stacking models The parameter problem cannot be easily expanded. Therefore, ensemble learning for large models requires careful consideration. Below we explain five basic integration methods, namely model integration, probabilistic integration, grafting learning, crowdsourcing voting, and MOE
