
 Technology peripherals
AI
180 billion parameters, the world's top open source large model Falcon is officially announced! Crush LLaMA 2, performance is close to GPT-4
Technology peripherals
AI
180 billion parameters, the world's top open source large model Falcon is officially announced! Crush LLaMA 2, performance is close to GPT-4
180 billion parameters, the world's top open source large model Falcon is officially announced! Crush LLaMA 2, performance is close to GPT-4

Overnight, the world’s most powerful open source large model Falcon 180B detonated the entire network!
180 billion parameters, Falcon completed training on 3.5 trillion tokens and directly topped the Hugging Face rankings.
In the benchmark test, Falcon 180B defeated Llama 2 in various tasks such as reasoning, coding, proficiency and knowledge testing.
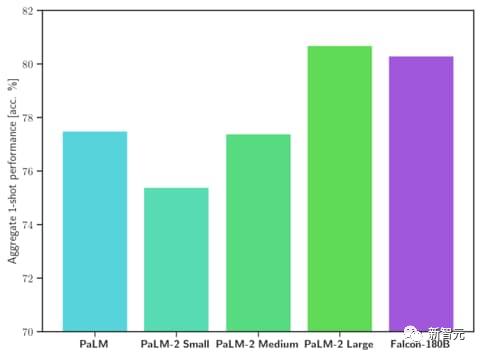
Even, Falcon 180B can be as good as Google PaLM 2, and its performance is close to GPT-4.
However, NVIDIA senior scientist Jim Fan questioned this.
-In the training data of Falcon-180B, the code only Accounting for 5%.
And code is by far the most useful data for improving reasoning capabilities, mastering tool usage, and enhancing AI agents. In fact, GPT-3.5 is fine-tuned based on Codex.
- No encoded baseline data.
Without coding ability, you cannot claim to be "better than GPT-3.5" or "close to GPT-4". It should be an integral part of the pre-training recipe, not a tweak afterward.
#- For language models with parameters larger than 30B, it is time to adopt a hybrid expert system (MoE). So far we have only seen OSS MoE LLM
Let’s take a look, what is Falcon 180B?

The world’s most powerful open source large model
Previously, Falcon has launched three model sizes, They are 1.3B, 7.5B, and 40B respectively.
According to the official introduction, Falcon 180B is an upgraded version of 40B. It was launched by TII, the world's leading technology research center in Abu Dhabi, and is available for free commercial use.

This time, the researchers made technical innovations in the base model, such as using Multi-Query Attention to improve the scalability of the model. .
For the training process, Falcon 180B is based on Amazon SageMaker, the Amazon cloud machine learning platform, and has completed the training of 3.5 trillion tokens on up to 4096 GPUs. training.
Total GPU calculation time, approximately 7,000,000.
The parameter size of Falcon 180B is 2.5 times that of Llama 2 (70B), and the amount of calculation required for training is 4 times that of Llama 2.
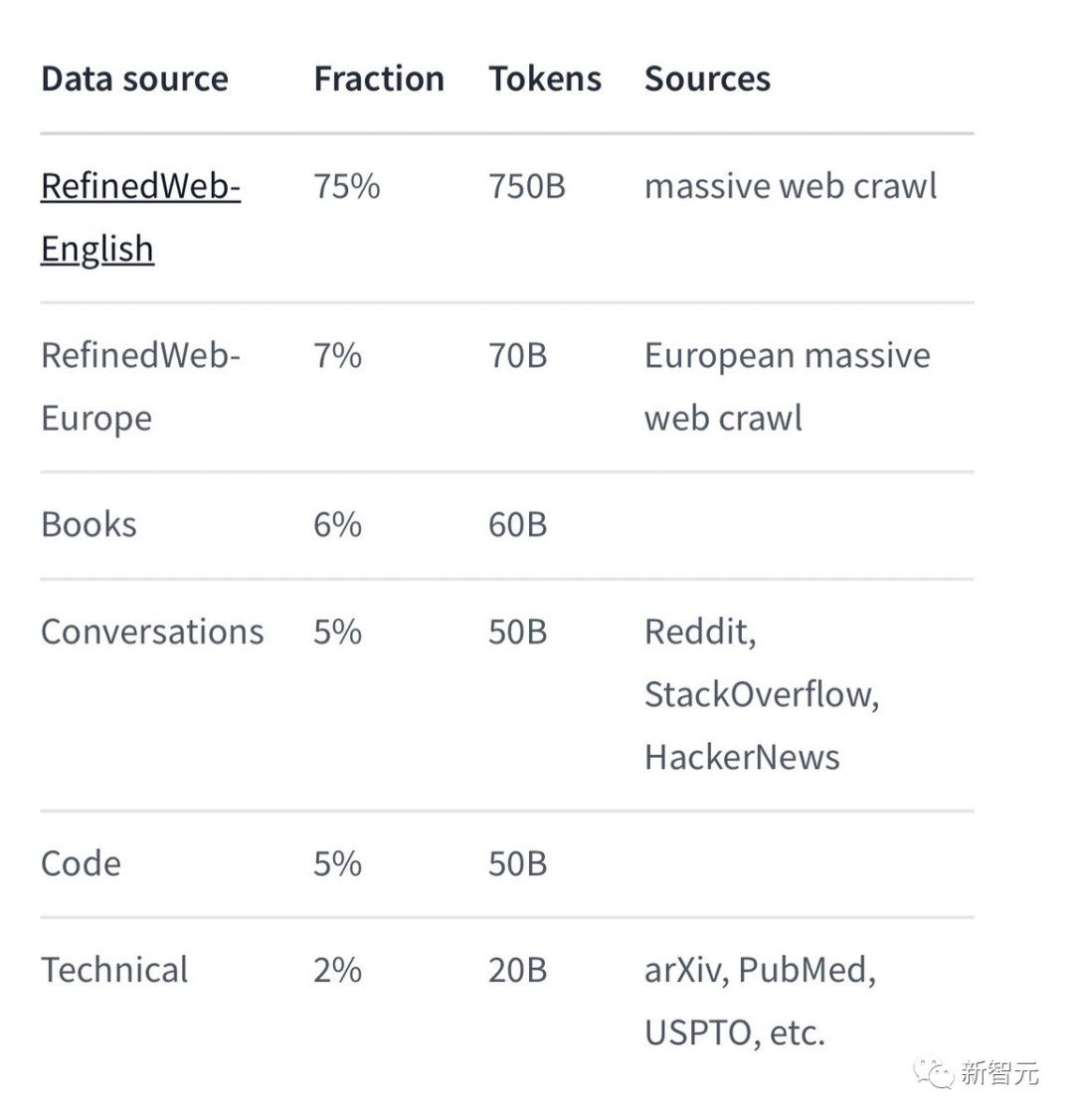
Among the specific training data, Falcon 180B is mainly the RefinedWe data set (accounting for about 85%).
Additionally, it was trained on a curated mix of conversations, technical papers, and a small portion of code.
This pre-training data set is large enough that even 3.5 trillion tokens only occupy less than one epoch.
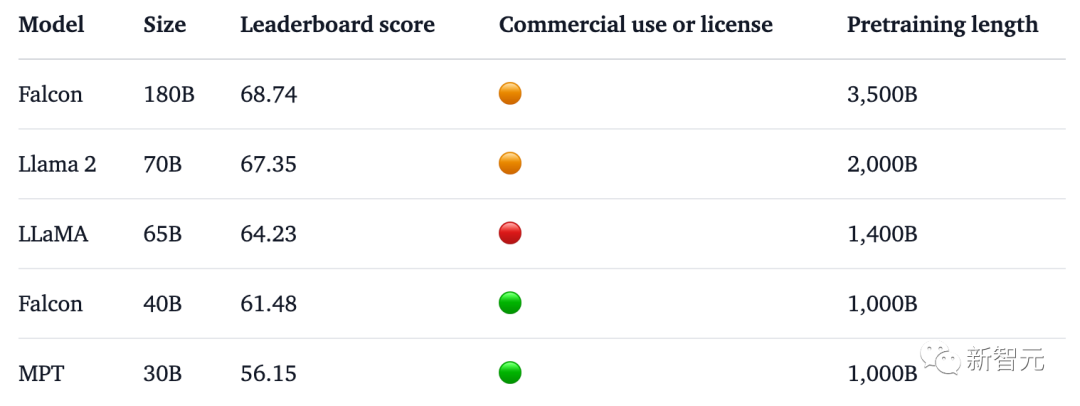
Officially claims that Falcon 180B is currently the "best" open source large model. The specific performance is as follows:
On the MMLU benchmark, Falcon 180B outperforms Llama 2 70B and GPT-3.5.
On par with Google's PaLM 2-Large on HellaSwag, LAMBADA, WebQuestions, Winogrande, PIQA, ARC, BoolQ, CB, COPA, RTE, WiC, WSC and ReCoRD .
In addition, it is currently the open large model with the highest score (68.74 points) on the Hugging Face open source large model list, surpassing LlaMA 2 (67.35).
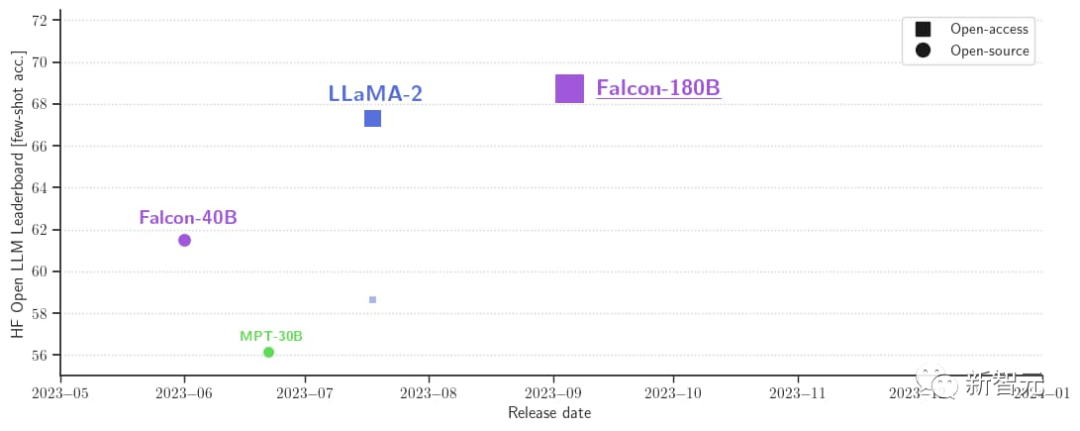
Falcon 180B is available to get started
At the same time, the researchers also released the chat dialogue model Falcon-180B-Chat. The model is fine-tuned on conversation and instruction datasets covering Open-Platypus, UltraChat and Airoboros.

Now, everyone can have a demo experience.
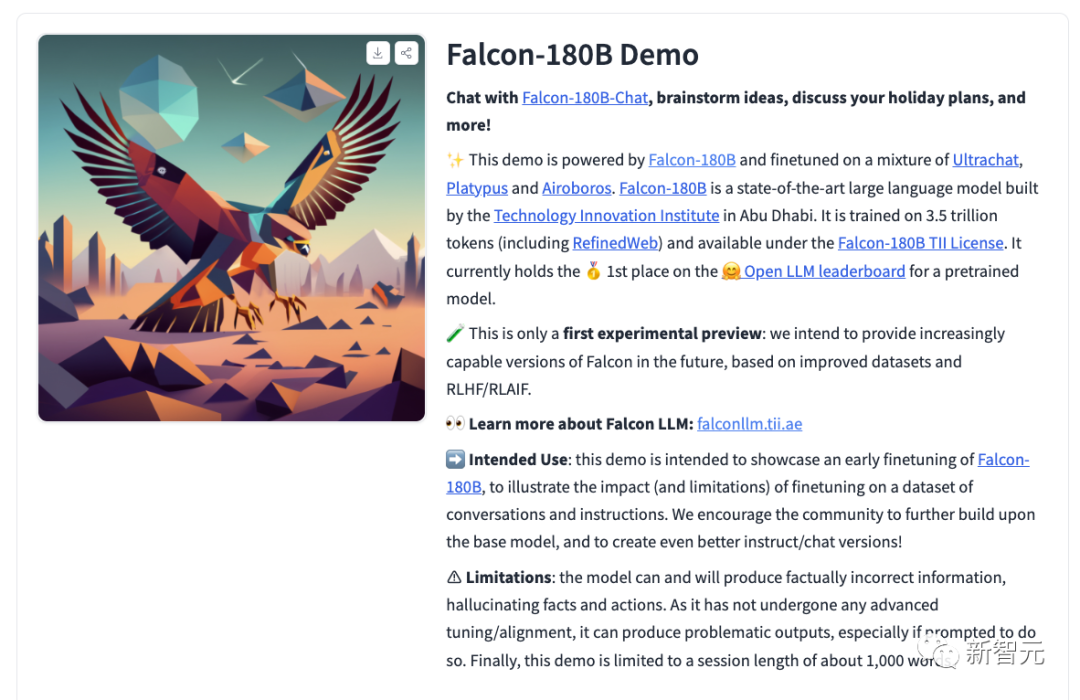
Address: https://huggingface.co/tiiuae/falcon-180B-chat
Prompt format
The basic model does not have a prompt format because it is not a large conversational model, nor is it trained through instructions, so it does not respond in a conversational manner.
Pre-trained models are a great platform for fine-tuning, but perhaps you shouldn’t use them directly. Its dialogue model has a simple dialogue mode.
System: Add an optional system prompt hereUser: This is the user inputFalcon: This is what the model generatesUser: This might be a second turn inputFalcon: and so on
Transformers
Starting from Transformers 4.33, Falcon 180B can be used and downloaded in the Hugging Face ecosystem.
Make sure you are logged in to your Hugging Face account and have the latest version of transformers installed:
pip install --upgrade transformershuggingface-cli login
bfloat16
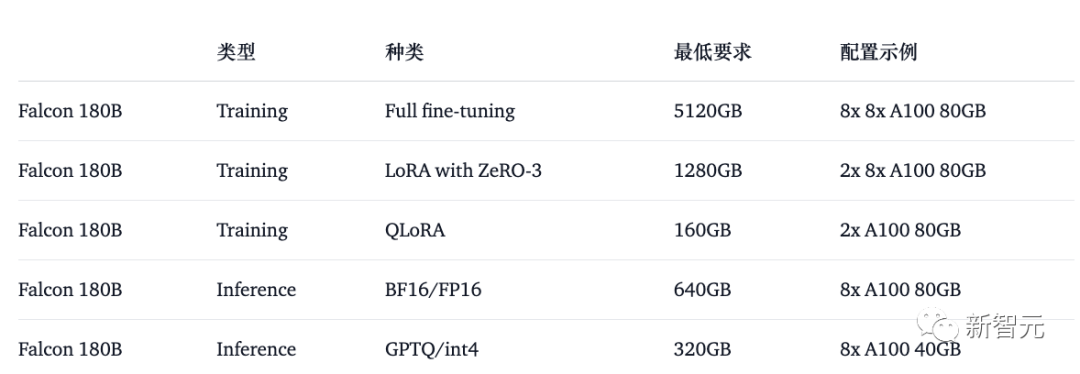
Here's how to use the base model in bfloat16. The Falcon 180B is a large model, so please be aware of its hardware requirements.
In this regard, the hardware requirements are as follows:
It can be seen that if you want to fully fine-tune Falcon 180B, you need at least 8X8X A100 80G, If it is just for inference, you will also need an 8XA100 80G GPU.
from transformers import AutoTokenizer, AutoModelForCausalLMimport transformersimport torchmodel_id = "tiiuae/falcon-180B"tokenizer = AutoTokenizer.from_pretrained(model_id)model = AutoModelForCausalLM.from_pretrained(model_id,torch_dtype=torch.bfloat16,device_map="auto",)prompt = "My name is Pedro, I live in"inputs = tokenizer(prompt, return_tensors="pt").to("cuda")output = model.generate(input_ids=inputs["input_ids"],attention_mask=inputs["attention_mask"],do_sample=True,temperature=0.6,top_p=0.9,max_new_tokens=50,)output = output[0].to("cpu")print(tokenizer.decode(output)may produce the following output:
My name is Pedro, I live in Portugal and I am 25 years old. I am a graphic designer, but I am also passionate about photography and video.I love to travel and I am always looking for new adventures. I love to meet new people and explore new places.
Use 8 bits and 4 bitsandbytes
# Additionally, the 8-bit and 4-bit quantized versions of Falcon 180B are virtually indistinguishable from bfloat16 in terms of evaluation!
This is good news for inference, as users can confidently use the quantized version to reduce hardware requirements.
Note that inference is much faster in the 8-bit version than in the 4-bit version. To use quantization, you need to install the "bitsandbytes" library and enable the corresponding flag when loading the model:
model = AutoModelForCausalLM.from_pretrained(model_id,torch_dtype=torch.bfloat16,**load_in_8bit=True,**device_map="auto",)
Dialog Model
As mentioned above, the version of the model fine-tuned for tracking conversations uses a very straightforward training template. We have to follow the same pattern to run chat-style reasoning.
For reference, you can take a look at the [format_prompt] function in the chat demo:
def format_prompt(message, history, system_prompt):prompt = ""if system_prompt:prompt += f"System: {system_prompt}\n"for user_prompt, bot_response in history:prompt += f"User: {user_prompt}\n"prompt += f"Falcon: {bot_response}\n"prompt += f"User: {message}\nFalcon:"return promptAs you can see from the above, the user's interaction and model The responses are preceded by User: and Falcon: delimiters. We connect them together to form a prompt that contains the entire conversation history. This way, a system prompt can be provided to adjust the build style.
Hot comments from netizens
Many netizens have heated discussions about the true strength of Falcon 180B.
Absolutely unbelievable. It beats GPT-3.5 and is on par with Google's PaLM-2 Large. This is a game changer!

A startup CEO said that I tested the Falcon-180B conversation robot and it was no better than the Llama2-70B chat system. The HF OpenLLM rankings also show mixed results. This is surprising considering its larger size and larger training set.
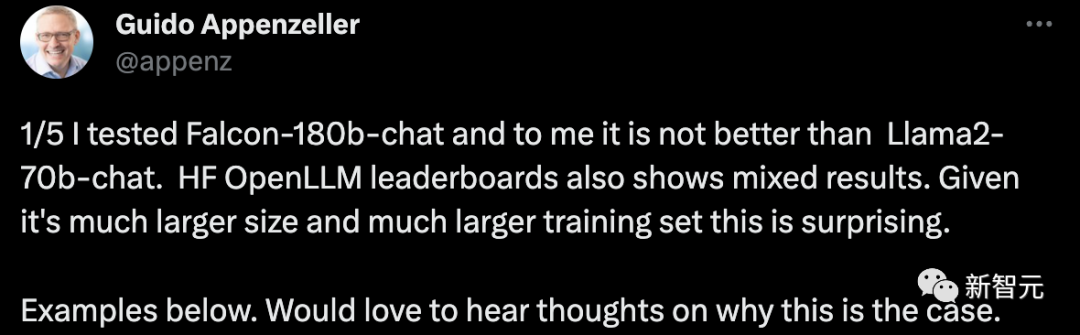
Give a chestnut:
Give some entries, let Falcon-180B and Llama2-70B Answer them separately and see what the effect is?
Falcon-180B mistakenly counts a saddle as an animal. Llama2-70B answered concisely and gave the correct answer.


The above is the detailed content of 180 billion parameters, the world's top open source large model Falcon is officially announced! Crush LLaMA 2, performance is close to GPT-4. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to use char array in C language
Apr 03, 2025 pm 03:24 PM
How to use char array in C language
Apr 03, 2025 pm 03:24 PM
The char array stores character sequences in C language and is declared as char array_name[size]. The access element is passed through the subscript operator, and the element ends with the null terminator '\0', which represents the end point of the string. The C language provides a variety of string manipulation functions, such as strlen(), strcpy(), strcat() and strcmp().
 Avoid errors caused by default in C switch statements
Apr 03, 2025 pm 03:45 PM
Avoid errors caused by default in C switch statements
Apr 03, 2025 pm 03:45 PM
A strategy to avoid errors caused by default in C switch statements: use enums instead of constants, limiting the value of the case statement to a valid member of the enum. Use fallthrough in the last case statement to let the program continue to execute the following code. For switch statements without fallthrough, always add a default statement for error handling or provide default behavior.
 The importance of default in switch case statement (C language)
Apr 03, 2025 pm 03:57 PM
The importance of default in switch case statement (C language)
Apr 03, 2025 pm 03:57 PM
The default statement is crucial in the switch case statement because it provides a default processing path that ensures that a block of code is executed when the variable value does not match any case statement. This prevents unexpected behavior or errors and enhances the robustness of the code.
 What are the types of return values of c language function? Summary of types of return values of c language function?
Apr 03, 2025 pm 11:18 PM
What are the types of return values of c language function? Summary of types of return values of c language function?
Apr 03, 2025 pm 11:18 PM
The return value types of C language function include int, float, double, char, void and pointer types. int is used to return integers, float and double are used to return floats, and char returns characters. void means that the function does not return any value. The pointer type returns the memory address, be careful to avoid memory leakage.结构体或联合体可返回多个相关数据。
 What is the value range of char in C language
Apr 03, 2025 pm 03:39 PM
What is the value range of char in C language
Apr 03, 2025 pm 03:39 PM
The value range of char in C language depends on the implementation method: signed char: -128 to 127 Unsigned char: 0 to 255 The specific range is affected by computer architecture and compiler options. By default, char is set to a signed type.
 Concept of c language function
Apr 03, 2025 pm 10:09 PM
Concept of c language function
Apr 03, 2025 pm 10:09 PM
C language functions are reusable code blocks. They receive input, perform operations, and return results, which modularly improves reusability and reduces complexity. The internal mechanism of the function includes parameter passing, function execution, and return values. The entire process involves optimization such as function inline. A good function is written following the principle of single responsibility, small number of parameters, naming specifications, and error handling. Pointers combined with functions can achieve more powerful functions, such as modifying external variable values. Function pointers pass functions as parameters or store addresses, and are used to implement dynamic calls to functions. Understanding function features and techniques is the key to writing efficient, maintainable, and easy to understand C programs.
 C# multi-threaded method to prevent jamming
Apr 03, 2025 pm 02:54 PM
C# multi-threaded method to prevent jamming
Apr 03, 2025 pm 02:54 PM
The following ways to avoid "stuck" multithreading in C#: avoid time-consuming operations on UI threads. Use Task and async/await to perform time-consuming operations asynchronously. Update the UI on the UI thread via Application.Current.Dispatcher.Invoke. Use the CancellationToken to control task cancellation. Make rational use of thread pools to avoid excessive creation of threads. Pay attention to code readability and maintainability, making it easy to debug. Logs are recorded in each thread for easy debugging.
 C Programmer &#s Undefined Behavior Guide
Apr 03, 2025 pm 07:57 PM
C Programmer &#s Undefined Behavior Guide
Apr 03, 2025 pm 07:57 PM
Exploring Undefined Behaviors in C Programming: A Detailed Guide This article introduces an e-book on Undefined Behaviors in C Programming, a total of 12 chapters covering some of the most difficult and lesser-known aspects of C Programming. This book is not an introductory textbook for C language, but is aimed at readers familiar with C language programming, and explores in-depth various situations and potential consequences of undefined behaviors. Author DmitrySviridkin, editor Andrey Karpov. After six months of careful preparation, this e-book finally met with readers. Printed versions will also be launched in the future. This book was originally planned to include 11 chapters, but during the creation process, the content was continuously enriched and finally expanded to 12 chapters - this itself is a classic array out-of-bounds case, and it can be said to be every C programmer
