
 Technology peripherals
AI
New Title: Uncovering Why Large Models Slow: New Directions for Algorithms of the Human Mind
Technology peripherals
AI
New Title: Uncovering Why Large Models Slow: New Directions for Algorithms of the Human Mind
New Title: Uncovering Why Large Models Slow: New Directions for Algorithms of the Human Mind

AI researchers often ignore human intuition, but in fact we ourselves don’t fully understand its subtlety. Recently, a research team from Virginia Tech and Microsoft proposed an Algorithm of Thinking (AoT) that combines intuitive abilities with algorithmic methods to ensure LLM performance and achieve significant cost savings
Large language models have been developing very rapidly recently, demonstrating remarkable capabilities in solving general problems, generating code, and following instructions
Despite early Models rely on direct answer strategies, but current research turns to a linear reasoning path by breaking the problem into subtasks to discover solutions, or by modifying the context to exploit external mechanisms to change token generation.
Similar to human cognition, early LLM strategies seemed to mimic immediate System 1 (rapid reactions), characterized by impulsive decision-making. In contrast, newer methods such as Chain of Thoughts (CoT) and least-to-most prompting (L2M) reflect the introspective nature of System 2 (slow thinking). It is worth noting that the arithmetic reasoning ability of LLM can be improved by integrating intermediate reasoning steps.
#However, if the task requires deeper planning and broader mental exploration, then the limitations of these methods become apparent. Although CoT incorporating self-consistency (CoT-SC) can use multiple LLM outputs to reach consensus results, the lack of detailed evaluation may lead the model in the wrong direction. The Tree of Thinking (ToT) emerging in 2023 is a noteworthy solution. One LLM is used to generate ideas, and another LLM is used to evaluate the merits of those ideas, followed by a "pause-evaluate-continue" cycle. This iterative process based on tree search is clearly effective, especially for tasks with long continuations. The researchers believe this development is the use of external tools to enhance LLM, similar to how humans use tools to circumvent the limitations of their own working memory.
On the other hand, the enhanced LLM method also has some shortcomings. An obvious problem is that the number of queries and computational requirements will increase significantly. Each query to an online LLM API such as GPT-4 incurs significant overhead and results in increased latency, which is particularly important for real-time applications. The accumulated latency of these queries can reduce the overall efficiency of the scenario. On the infrastructure side, constant interaction puts stress on the system, potentially limiting bandwidth and reducing model availability. In addition, the impact on the environment cannot be ignored. Frequent queries will increase the energy consumption of the already energy-intensive data center and further increase the carbon footprint.
The researchers’ optimization goal is to maintain While achieving sufficient performance, it significantly reduces the number of queries used by current multi-query inference methods. Such optimization can enable models to handle tasks that require proficient application of world knowledge, and guide people to use AI resources more responsibly and proficiently
Thinking about LLM from System 1 to System 2 Evolution, we can see a key factor emerging: algorithms. Algorithms are methodical and provide a way for people to explore problem spaces, formulate strategies, and build solutions. Although many mainstream literature regard algorithms as external tools of LLM, considering the inherent generative recurrence ability of LLM, can we guide this iterative logic and internalize the algorithm into LLM?
A team of researchers at Virginia Tech and Microsoft has brought together the sophistication of human reasoning and the methodical precision of algorithmic approaches to enhance LLM by fusing the two. Internal reasoning ability
According to existing research, humans will instinctively draw on past experiences when solving complex problems to ensure that they think comprehensively rather than narrowly focus on one detail. The generation range of LLM is only limited by its token limit, and it seems destined to break through the obstacles of human working memory
Inspired by this observation, researchers began to explore whether LLM can be used to achieve something similar. A hierarchical way of thinking, eliminating unfeasible options by referring to previous intermediate steps - all within the LLM's generation cycle. Humans are good at intuition, while algorithms are good at organized and systematic exploration. Current technologies such as CoT tend to avoid this synergistic potential and focus too much on the on-site accuracy of LLM. By leveraging LLM's recursive capabilities, the researchers constructed a human-algorithm hybrid approach. This approach is achieved through the use of algorithmic examples that capture the essence of exploration - from initial candidates to proven solutions
Based on these observations, researchers proposed the Algorithm of Thoughts (AoT).

The content that needs to be rewritten is: Paper: https://arxiv.org/pdf/2308.10379.pdf
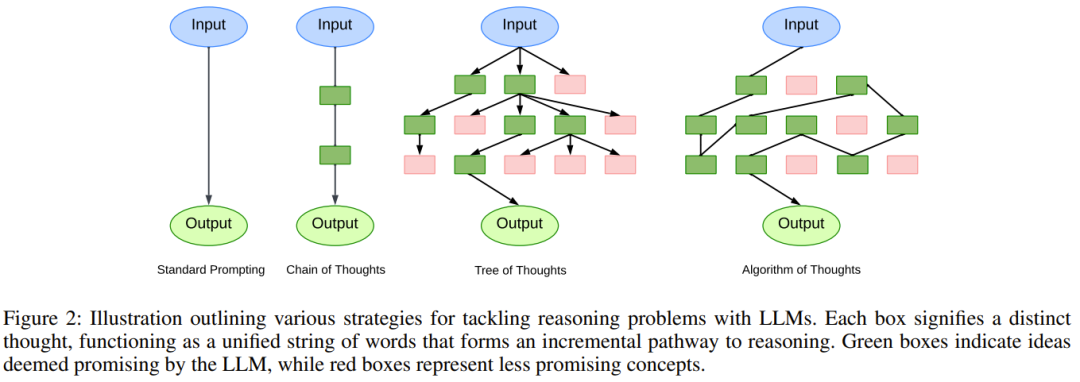
From a broader scope, this new method is expected to give birth to a new paradigm of contextual learning. Instead of using the traditional supervised learning model of [question, answer] or [question, subsequent steps to obtain the answer], this new approach adopts a new model [question, search process, answer]. Naturally, when an LLM is instructed to use an algorithm, we usually expect the LLM to simply imitate the iterative thinking of that algorithm. However, what is interesting is that LLM has the ability to inject its own "intuition", even making its search more efficient than the algorithm itself.
Thinking Algorithms
The researchers say that at the heart of their research strategy is recognition of the major shortcomings of the current contextual learning paradigm. Although CoT can improve the consistency of thought connections, problems occasionally occur, leading to wrong intermediate steps
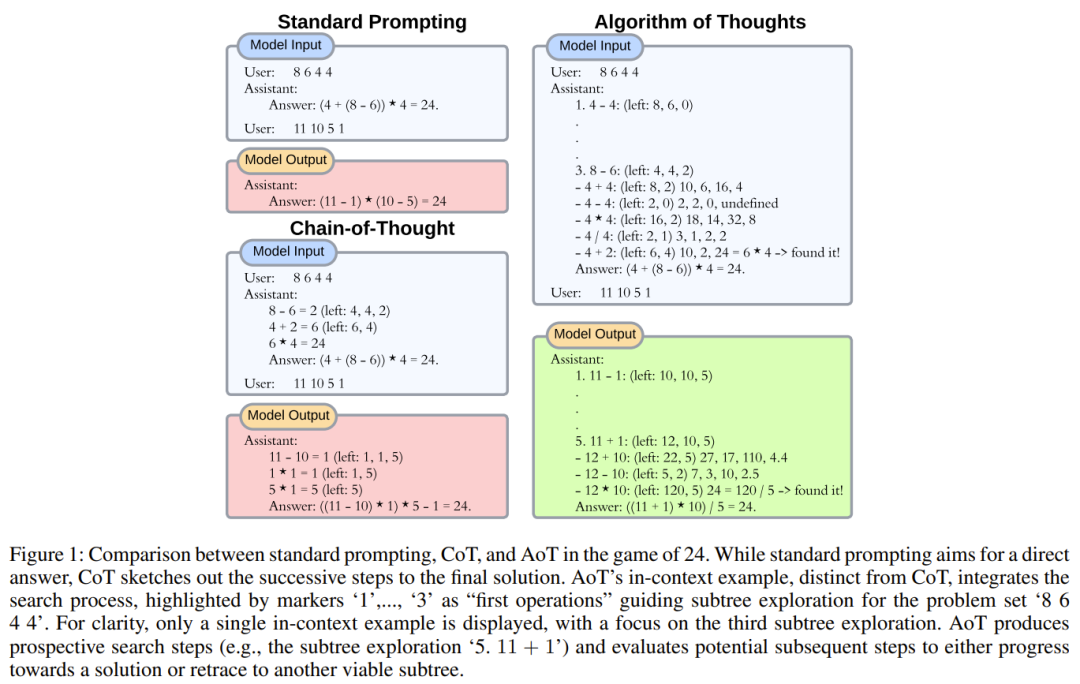
To illustrate this phenomenon, the researchers designed an experiment. When querying text-davinci-003 with an arithmetic task (such as 11 − 2 =), the researchers will prepend multiple contextual equations that will produce equivalent outputs (such as 15 − 5 = 10, 8 2 = 10).
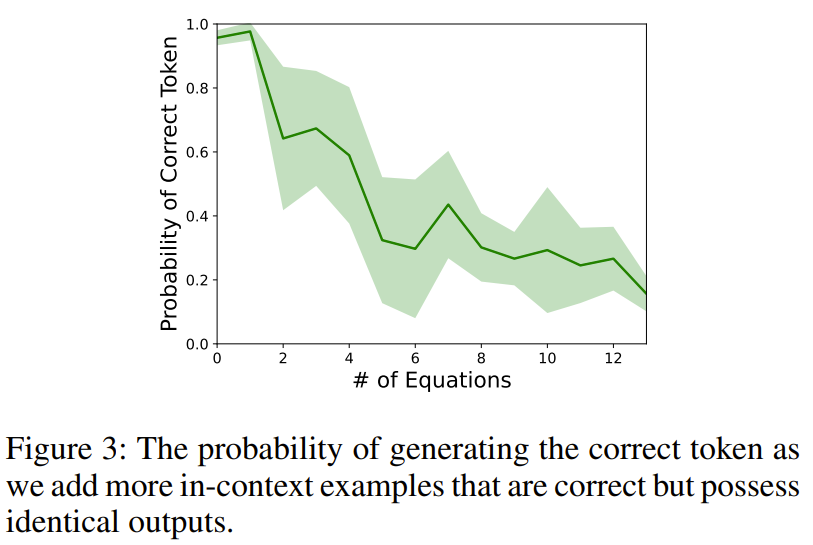
#After investigation, it was found that the accuracy of the results plummeted, indicating that simply providing correct reasoning in context may inadvertently undermine the foundation of LLM. Arithmetic ability
To reduce this bias, making the examples more diverse may be a viable solution, but this may slightly change the distribution of the output. Simply adding a few unsuccessful attempts (like a random search) may inadvertently encourage the model to try again without actually solving the problem. Understanding the true nature of algorithmic behavior (where failed searches and subsequent recoveries are important, as well as learning from these attempts), the way researchers incorporate contextual examples is by following the pattern of search algorithms, especially depth-first search (DFS) and Breadth First Search (BFS). Figure 1 gives an example.
The main focus of this paper is a class of tasks similar to the tree search problem
For this type of task, the main problem needs to be Break it down and build a workable solution for each part. We then need to decide whether to adopt or abandon certain paths, and potentially choose to re-evaluate those that have greater potential. The researcher's approach is to leverage the iterative capabilities of LLM, in Solve each subset's query problem in a unified generative scan. By limiting to just one or two LLM interactions, the approach can naturally integrate insights from previous contextual candidates and solve complex problems that require deep exploration of the solution domain. The researchers also provide insights into mind size and what type of contextual examples to provide LLM with to improve token efficiency. The key components of the tree search algorithm and their representation in the new framework will be introduced below
#1. Decompose into sub-problems.
Given a problem, constructing a search tree that describes feasible reasoning paths is already a daunting task, even without looking at the actual problem-solving aspect. Any decomposition must consider not only the interrelationships between subtasks, but also the ease of solving each problem. Take simple multi-digit addition as an example: Although it is efficient for computers to convert numerical values into binary numbers, humans often find decimal numbers more intuitive. Furthermore, even if the subproblems are the same, the execution methods may be different. Intuition can find shortcuts between steps to a solution, and without intuition, more detailed steps may be necessary.
In order to create the correct prompt (i.e. contextual algorithm example), these subtleties are very important, and they determine the minimum number of tokens required by LLM for reliable performance. This not only satisfies LLM's constraints on context, but is also important for LLM's ability to solve problems that resonate with its context using a similar amount of tokens.
#2. Propose a solution to the sub-question. One of the current mainstream methods involves directly sampling the LLM token output probability. Although this method is effective for one-time answers (with certain limitations), it is also unable to cope with some scenarios, such as when the sample sequence needs to be integrated into a subsequent prompt or evaluated in a subsequent prompt. To minimize model queries, the researchers used a non-stop solution creation process. That is, directly and continuously generate solutions to the main subproblems without any generation pauses.
Rewritten content: This approach has many advantages. First, all generated answers are in the same shared context, eliminating the need to generate separate model queries for each answer for evaluation. Second, although it may seem counterintuitive at first, isolated marker or marker group probabilities may not always lead to meaningful selections. Figure 4 shows a simple schematic

3. Measure the prospects of sub-problems. As mentioned above, existing techniques rely on additional hints to identify the potential of tree nodes to help make decisions about exploration directions. Our observations indicate that LLM inherently tends to prioritize promising candidates if they can be encapsulated in contextual examples. This reduces the need for complex prompt engineering and allows the integration of sophisticated heuristics, whether they are intuitive or knowledge-driven. Likewise, the new method does not include disjointed prompts, which enables an instant assessment of candidate feasibility within the same generated result.
4. Backtrack to a better node. Deciding which node to explore next (including backtracking to previous nodes) essentially depends on the chosen tree search algorithm. Although previous research has employed external methods such as coding mechanisms for the search process, this would limit its broader appeal and require additional customization. The new design proposed in this paper mainly adopts the DFS method supplemented by pruning. The goal is to maintain proximity between child nodes with the same parent node, thereby encouraging LLM to prioritize local features over remote features. In addition, the researchers also proposed performance indicators of the BFS-based AoT method. The researchers say that the need for additional customization mechanisms can be eliminated by leveraging the model's inherent ability to glean insights from contextual examples.
Experiment
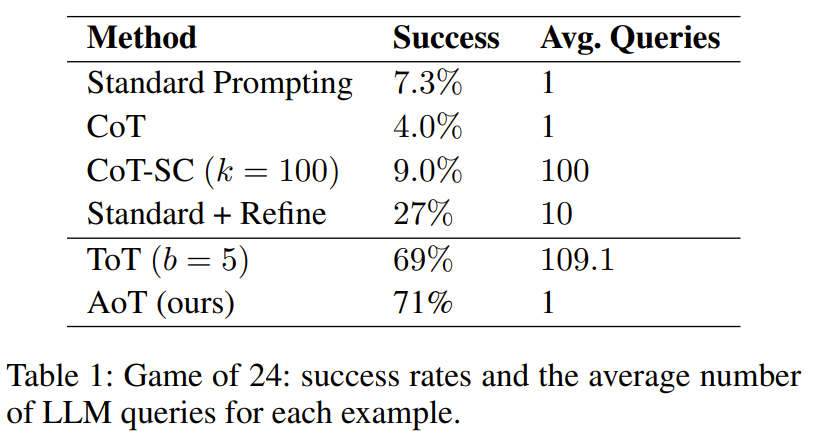
The researchers conducted an experiment on 24-point and 5x5 mini word puzzles. The results show that the AoT method outperforms single prompt methods (such as standard methods, CoT, CoT-SC) in performance, and is also comparable to methods that use external mechanisms (such as ToT)
It can be clearly seen from Table 1 that the method of using LLM for tree search is significantly better than the standard prompt design method combined with CoT/CoT-SC
In the mini word-filling task, Table 3 shows the effectiveness of AoT, and its word-filling success rate exceeds previous methods using various prompting techniques

However, it is worse than ToT. An important observation is that the query volume used by ToT is huge, exceeding that of AoT by more than a hundred times. Another factor that makes AoT inferior to ToT is that the backtracking capabilities inherent in algorithmic examples are not fully activated. If this ability could be fully unlocked, it would result in a significantly longer generation phase. In contrast, ToT has the advantage of using external memory for backtracking.
Discussion
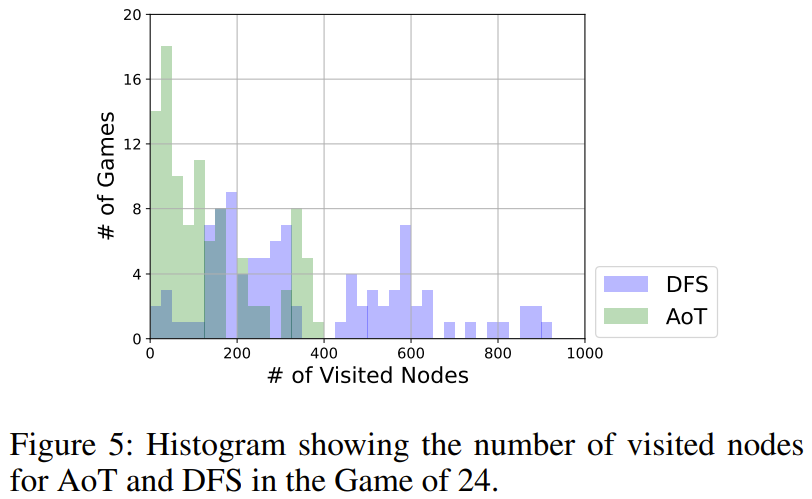
Can AoT achieve a breakthrough based on imitating DFS?
As shown in Figure 5, AoT uses fewer nodes overall than the DFS version. DFS adopts a unified strategy in selecting subtrees to explore, while AoT's LLM integrates its inherent heuristics. This amplification of the basic algorithm reflects the advantages of LLM's recursive reasoning capabilities
How does the choice of algorithm affect the performance of AoT?
It was found in the experiment that Table 5 shows that all three AoT variants are superior to the CoT of a single query
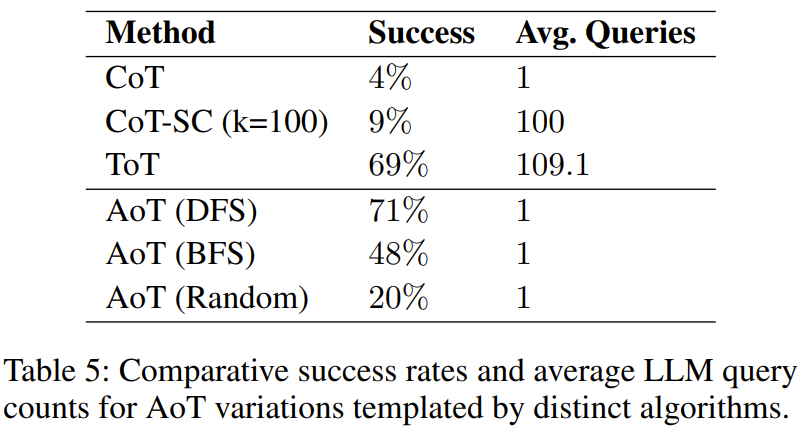
This result is as expected because whatever the algorithm is, it searches and revisits potential errors - either through random attempts in the random search variant or through depth-first search (DFS). ) or backtracking in a breadth-first search (BFS) configuration. It is worth noting that the efficiency of structured searches, the DFS version of AoT and the BFS version of AoT, are both better than the random version of AoT, which highlights the advantage of algorithmic insights in solution discovery. However, the BFS version of AoT lags behind the DFS version of AoT. By further analyzing the errors of the BFS version of AoT, the researchers found that compared to the DFS version of AoT, the BFS version of AoT is more difficult to identify the best operations
in regulating the behavior of AoT When, we need to pay attention to the number of search steps in the algorithm example
The impact of the total number of search steps is shown in Figure 6. Among them, AoT (long) and AoT (short) respectively represent longer and shorter versions relative to the original AoT generated results
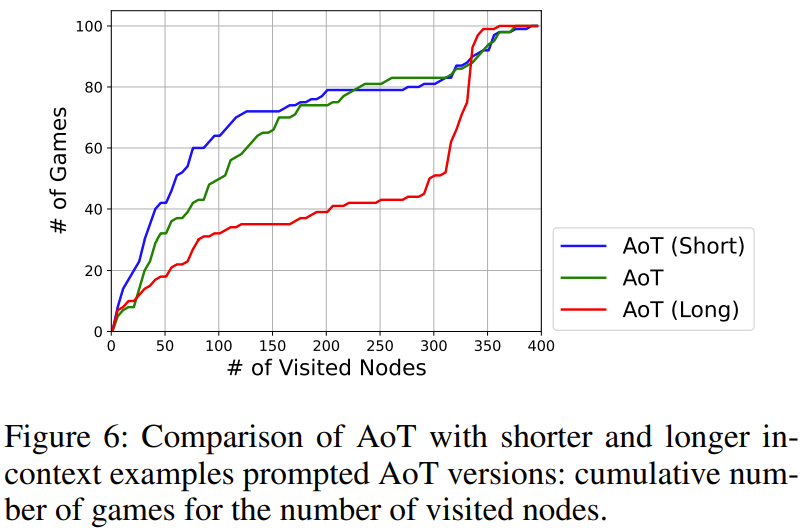
Research results show , the search step will produce an implicit bias in the search speed of LLM. It is important to note that even when wrong steps are taken, it is still important to emphasize exploring promising directions
The above is the detailed content of New Title: Uncovering Why Large Models Slow: New Directions for Algorithms of the Human Mind. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
DDREASE is a tool for recovering data from file or block devices such as hard drives, SSDs, RAM disks, CDs, DVDs and USB storage devices. It copies data from one block device to another, leaving corrupted data blocks behind and moving only good data blocks. ddreasue is a powerful recovery tool that is fully automated as it does not require any interference during recovery operations. Additionally, thanks to the ddasue map file, it can be stopped and resumed at any time. Other key features of DDREASE are as follows: It does not overwrite recovered data but fills the gaps in case of iterative recovery. However, it can be truncated if the tool is instructed to do so explicitly. Recover data from multiple files or blocks to a single
 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
