
 Technology peripherals
AI
32-card 176% training acceleration, open source large model training framework Megatron-LLaMA is here
Technology peripherals
AI
32-card 176% training acceleration, open source large model training framework Megatron-LLaMA is here
32-card 176% training acceleration, open source large model training framework Megatron-LLaMA is here

Taotian Group and Aicheng Technology officially released the open source large model training framework-Megatron-LLaMA on September 12. The goal of this framework is to make it easier for technology developers to improve the training performance of large language models, reduce training costs, and maintain compatibility with the LLaMA community. The test results show that on 32-card training, Megatron-LLaMA can achieve 176% acceleration compared with the code version obtained directly on HuggingFace; on large-scale training, Megatron-LLaMA expands almost linearly and is unstable to the network. Show a high level of tolerance. Currently, Megatron-LLaMA has been launched in the open source community
Open source address: https://github.com/alibaba/Megatron-LLaMA
The superior performance of large language models has exceeded people's imagination time and time again. Over the past few months, LLaMA and LLaMA2 have been made generally available to the open source community, providing a great option for those who want to train their own large language models. In the open source community, there are already many models developed based on LLaMA, including continued training/SFT (such as Alpaca, Vicuna, WizardLM, Platypus, StableBegula, Orca, OpenBuddy, Linly, Ziya, etc.) and training from scratch (such as Baichuan, QWen , InternLM, OpenLLaMA) work. These works not only performed well on various objective evaluation lists of large model capabilities, but also demonstrated excellent performance in practical application scenarios such as long text understanding, long text generation, code writing, and mathematical solving. In addition, many interesting products have appeared in the industry, such as LLaMA combined with Whisper's voice chat robot, LLaMA combined with Stable Diffusion's painting software, and auxiliary consultation robots in the medical/legal field, etc.
Although the LLaMA model code can be obtained from HuggingFace, training an LLaMA model with your own data is not a low-cost and simple task for individual users or small and medium-sized organizations. The volume of large models and the scale of data make it impossible to complete effective training on ordinary computing resources, and computing power and cost have become serious bottlenecks. The users of the Megatron-LM community have very urgent demands in this regard.
Taotian Group and Aicheng Technology have very broad application scenarios for large model applications, and have done a lot of work on efficient training of large models. investment. The advent of LLaMA has given many companies, including Taotian Group and Aicheng Technology, a lot of inspiration in terms of data processing, model design, fine-tuning and reinforcement learning feedback adjustment, and has also helped achieve new breakthroughs in business application scenarios. . Therefore, in order to give back to the entire LLaMA open source community and promote the development of the Chinese pre-trained large model open source community, so that developers can more easily improve the training performance of large language models and reduce training costs, Taotian Group and Aicheng Technology will combine some internal Optimize the technology and open source it, release Megatron-LLaMA, and look forward to building the Megatron and LLaMA ecosystem with every partner.
Megatron-LLaMA provides a set of standard Megatron-LM implementations of LLaMA, and provides and HuggingFace free formats The switching tool is convenient for compatibility with community ecological tools. Megatron-LLaMA has redesigned the reverse process of Megatron-LM, so that it can be achieved no matter where the number of nodes is small and large gradient aggregation (GA) needs to be turned on, or when the number of nodes is large and small GA must be used. Excellent training performance.
- In 32-card training, compared to the code version obtained directly from HuggingFace, Megatron-LLaMA can achieve 176% acceleration; even if it is optimized with DeepSpeed and FlashAttention version, Megatron-LLaMA can still reduce training time by at least 19%.
- In large-scale training, Megatron-LLaMA has almost linear scalability compared to 32 cards. For example, using 512 A100 to reproduce the training of LLaMA-13B, the reverse mechanism of Megatron-LLaMA can save at least two days compared to the DistributedOptimizer of the native Megatron-LM without any loss of accuracy.
- Megatron-LLaMA exhibits a high tolerance for network instability. Even on the current cost-effective 8xA100-80GB training cluster with 4x200Gbps communication bandwidth (this environment is usually a mixed-deployment environment, the network can only use half of the bandwidth, network bandwidth is a serious bottleneck, but the rental price is relatively low), Megatron-LLaMA can still achieve a linear expansion capability of 0.85, but Megatron-LM can only achieve less than 0.7 on this indicator.
Megatron-LM technology brings high-performance LLaMA training opportunities
LLaMA is currently a large language model open source community Important work. LLaMA introduces optimization technologies such as BPE character encoding, RoPE position encoding, SwiGLU activation function, RMSNorm regularization and Untied Embedding into the structure of LLM, and has achieved excellent results in many objective and subjective evaluations. LLaMA provides 7B, 13B, 30B, 65B/70B versions, which are suitable for various large model demand scenarios and are also favored by the majority of developers. Like many other open source large models, since the official only provides the inference version of the code, there is no standard paradigm for how to carry out efficient training at the lowest cost
Megatron-LM is a Elegant high-performance training solution. Megatron-LM provides tensor parallelism (Tensor Parallel, TP, which allocates large multiplications to multiple cards for parallel computing), pipeline parallelism (Pipeline Parallel, PP, which allocates different layers of the model to different cards for processing), and sequence parallelism (Sequence Parallel, SP, different parts of the sequence are processed by different cards, saving video memory), DistributedOptimizer optimization (similar to DeepSpeed Zero Stage-2, splitting gradients and optimizer parameters to all computing nodes) and other technologies can significantly reduce video memory usage and improve GPU Utilization. Megatron-LM operates an active open source community, and new optimization technologies and functional designs continue to be incorporated into the framework.
However, developing based on Megatron-LM is not simple, especially debugging and functional verification on expensive multi-card machines is very expensive. Megatron-LLaMA first provides a set of LLaMA training code based on the Megatron-LM framework, which supports model versions of various sizes and can be easily adapted to support various variants of LLaMA, including Tokenizer that directly supports the HuggingFace format. Therefore, Megatron-LLaMA can be easily applied to existing offline training links without excessive adaptation. In small and medium-scale training/fine-tuning scenarios of LLaMA-7b and LLaMA-13b, Megatron-LLaMA can easily achieve an industry-leading hardware utilization (MFU) of more than 54%
Megatron- LLaMA’s reverse process optimization
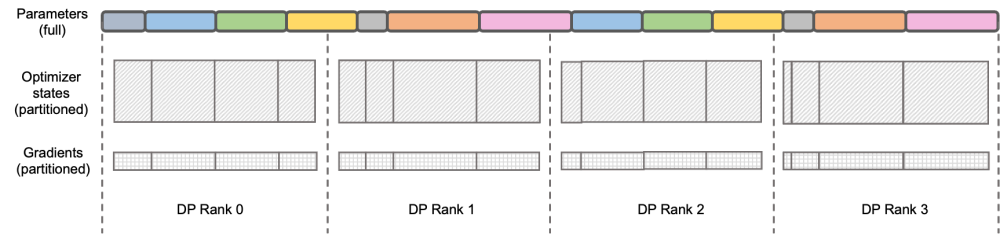
The content that needs to be rewritten is: Illustration: DeepSpeed ZeRO Stage-2
DeepSpeed ZeRO is a set of distributed training frameworks launched by Microsoft. The technology proposed in it has had a profound impact on many subsequent frameworks. DeepSpeed ZeRO Stage-2 (hereinafter referred to as ZeRO-2) is a technology in the framework that saves memory usage without adding additional calculation and communication workload. As shown in the figure above, due to calculation requirements, each Rank needs to have all parameters. But for the optimizer state, each Rank is only responsible for a part of it, and it is not necessary for all Ranks to perform completely repeated operations at the same time. Therefore, ZeRO-2 proposes to evenly divide the optimizer state into each Rank (note that there is no need to ensure that each variable is evenly divided or completely retained in a certain Rank). Each Rank only needs to be used during the training process. Responsible for updating the optimizer status and model parameters of the corresponding part. In this setting, gradients can also be split in this way. By default, ZeRO-2 uses the Reduce method to aggregate gradients among all Ranks in reverse, and then each Rank only needs to retain the part of the parameters it is responsible for, which not only eliminates redundant repeated calculations, but also reduces the memory usage. .
Megatron-LM DistributedOptimizer
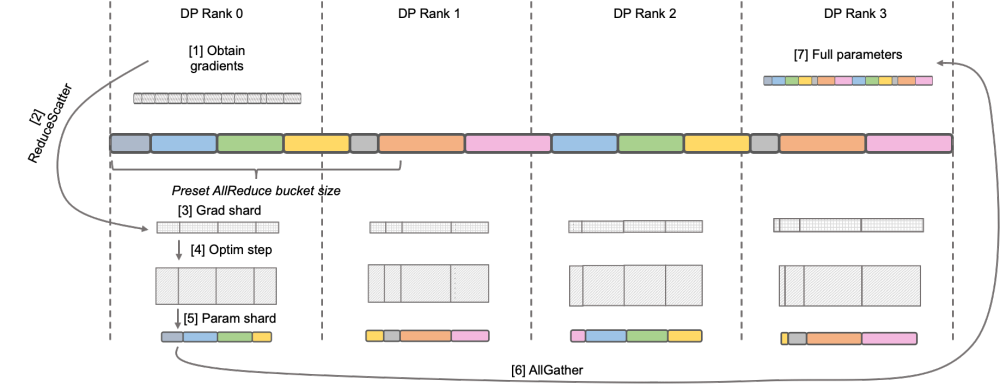
Native Megatron-LM implements ZeRO-2-like gradient and optimizer state segmentation through DistributedOptimizer to reduce video memory usage during training. As shown in the figure above, DistributedOptimizer uses the ReduceScatter operator to distribute all the previously accumulated gradients to different Ranks after obtaining all the gradients aggregated by the preset gradient. Each Rank only obtains part of the gradient that it needs to process, and then updates the optimizer state and the corresponding parameters. Finally, each Rank obtains updated parameters from other nodes through AllGather, and finally obtains all parameters. The actual training results show that the gradient and parameter communication of Megatron-LM are performed in series with other calculations. For large-scale pre-training tasks, in order to ensure that the total batch data size remains unchanged, it is usually impossible to open a larger GA. Therefore, the proportion of communication will increase with the increase of machines. At this time, the characteristics of serial communication lead to very weak scalability. Within the community, this need is also urgent
##Megatron-LLaMA OverlappedDistributedOptimizer
In order to solve For this problem, Megatron-LLaMA has improved the DistributedOptimizer of the native Megatron-LM so that its gradient communication operator can be parallelized with the calculation. In particular, compared to ZeRO's implementation, Megatron-LLaMA uses a more scalable collective communication method to improve scalability through clever optimization of the optimizer partitioning strategy under the premise of parallelism. The main design of OverlappedDistributedOptimizer ensures the following points: a) The data volume of a single set communication operator is large enough to fully utilize the communication bandwidth; b) The amount of communication data required by the new segmentation method should be equal to the minimum communication data volume required for data parallelism; c) During the conversion process of complete parameters or gradients and segmented parameters or gradients, too many video memory copies cannot be introduced.
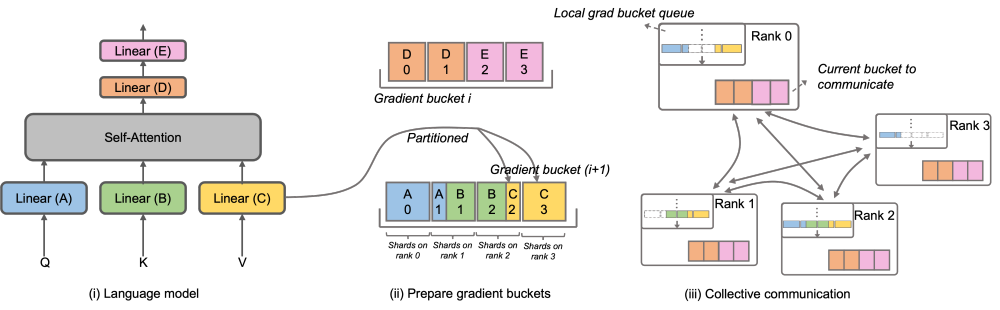
Specifically, Megatron-LLaMA has improved DistributedOptimizer and proposed OverlappedDistributedOptimizer, which is used to combine new ones in the reverse process of training. Optimize the segmentation method. As shown in the figure, when initializing OverlappedDistributedOptimizer, all parameters will be pre-allocated to the Bucket to which they belong. The parameters in each Bucket are complete. A parameter only belongs to one Bucket. There may be multiple parameters in a Bucket. Logically, each Bucket will be continuously divided into P parts (P is the number of data parallel groups), and each Rank in the data parallel group will be responsible for one of them
Buckets are placed in the local gradient bucket queue to ensure communication order. While training calculations are being performed, the data parallel groups exchange their required gradients in bucket units through collective communication. In Megatron-LLaMA, the Bucket implementation uses address indexing as much as possible, and new space is allocated only when the value needs to be changed to avoid wasting video memory
By combining a large number of Engineering optimization, the above design enables Megatron-LLaMA to make full use of hardware during large-scale training and achieve better acceleration than the native Megatron-LM. In a commonly used network environment, by expanding the training scale from 32 A100 cards to 512 A100 cards, Megatron-LLaMA can still achieve an expansion ratio of 0.85
Future plans for Megatron-LLaMA
Megatron-LLaMA is a training framework jointly open sourced by Taotian Group and Aicheng Technology and provided with follow-up maintenance support. It has been widely used internally. As more and more developers join LLaMA's open source community and contribute experiences that can be learned from each other, I believe there will be more challenges and opportunities at the training framework level in the future. Megatron-LLaMA will pay close attention to the development of the community and work with developers to promote the development in the following directions:
- Adaptive optimal configuration selection
- More support for model structure or local design changes
- Extreme performance training solutions in more different types of hardware environments
Project address: https://github.com/alibaba/Megatron-LLaMA
The above is the detailed content of 32-card 176% training acceleration, open source large model training framework Megatron-LLaMA is here. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 The facial features are flying around, opening the mouth, staring, and raising eyebrows, AI can imitate them perfectly, making it impossible to prevent video scams
Dec 14, 2023 pm 11:30 PM
The facial features are flying around, opening the mouth, staring, and raising eyebrows, AI can imitate them perfectly, making it impossible to prevent video scams
Dec 14, 2023 pm 11:30 PM
With such a powerful AI imitation ability, it is really impossible to prevent it. It is completely impossible to prevent it. Has the development of AI reached this level now? Your front foot makes your facial features fly, and on your back foot, the exact same expression is reproduced. Staring, raising eyebrows, pouting, no matter how exaggerated the expression is, it is all imitated perfectly. Increase the difficulty, raise the eyebrows higher, open the eyes wider, and even the mouth shape is crooked, and the virtual character avatar can perfectly reproduce the expression. When you adjust the parameters on the left, the virtual avatar on the right will also change its movements accordingly to give a close-up of the mouth and eyes. The imitation cannot be said to be exactly the same, but the expression is exactly the same (far right). The research comes from institutions such as the Technical University of Munich, which proposes GaussianAvatars, which
 The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3’s paper is finally here! This model was released two weeks ago and uses the same DiT (DiffusionTransformer) architecture as Sora. It caused quite a stir once it was released. Compared with the previous version, the quality of the images generated by StableDiffusion3 has been significantly improved. It now supports multi-theme prompts, and the text writing effect has also been improved, and garbled characters no longer appear. StabilityAI pointed out that StableDiffusion3 is a series of models with parameter sizes ranging from 800M to 8B. This parameter range means that the model can be run directly on many portable devices, significantly reducing the use of AI
 This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
Trajectory prediction plays an important role in autonomous driving. Autonomous driving trajectory prediction refers to predicting the future driving trajectory of the vehicle by analyzing various data during the vehicle's driving process. As the core module of autonomous driving, the quality of trajectory prediction is crucial to downstream planning control. The trajectory prediction task has a rich technology stack and requires familiarity with autonomous driving dynamic/static perception, high-precision maps, lane lines, neural network architecture (CNN&GNN&Transformer) skills, etc. It is very difficult to get started! Many fans hope to get started with trajectory prediction as soon as possible and avoid pitfalls. Today I will take stock of some common problems and introductory learning methods for trajectory prediction! Introductory related knowledge 1. Are the preview papers in order? A: Look at the survey first, p
 DualBEV: significantly surpassing BEVFormer and BEVDet4D, open the book!
Mar 21, 2024 pm 05:21 PM
DualBEV: significantly surpassing BEVFormer and BEVDet4D, open the book!
Mar 21, 2024 pm 05:21 PM
This paper explores the problem of accurately detecting objects from different viewing angles (such as perspective and bird's-eye view) in autonomous driving, especially how to effectively transform features from perspective (PV) to bird's-eye view (BEV) space. Transformation is implemented via the Visual Transformation (VT) module. Existing methods are broadly divided into two strategies: 2D to 3D and 3D to 2D conversion. 2D-to-3D methods improve dense 2D features by predicting depth probabilities, but the inherent uncertainty of depth predictions, especially in distant regions, may introduce inaccuracies. While 3D to 2D methods usually use 3D queries to sample 2D features and learn the attention weights of the correspondence between 3D and 2D features through a Transformer, which increases the computational and deployment time.
 'Minecraft' turns into an AI town, and NPC residents role-play like real people
Jan 02, 2024 pm 06:25 PM
'Minecraft' turns into an AI town, and NPC residents role-play like real people
Jan 02, 2024 pm 06:25 PM
Please note that this square man is frowning, thinking about the identities of the "uninvited guests" in front of him. It turned out that she was in a dangerous situation, and once she realized this, she quickly began a mental search to find a strategy to solve the problem. Ultimately, she decided to flee the scene and then seek help as quickly as possible and take immediate action. At the same time, the person on the opposite side was thinking the same thing as her... There was such a scene in "Minecraft" where all the characters were controlled by artificial intelligence. Each of them has a unique identity setting. For example, the girl mentioned before is a 17-year-old but smart and brave courier. They have the ability to remember and think, and live like humans in this small town set in Minecraft. What drives them is a brand new,
 Review! Deep model fusion (LLM/basic model/federated learning/fine-tuning, etc.)
Apr 18, 2024 pm 09:43 PM
Review! Deep model fusion (LLM/basic model/federated learning/fine-tuning, etc.)
Apr 18, 2024 pm 09:43 PM
In September 23, the paper "DeepModelFusion:ASurvey" was published by the National University of Defense Technology, JD.com and Beijing Institute of Technology. Deep model fusion/merging is an emerging technology that combines the parameters or predictions of multiple deep learning models into a single model. It combines the capabilities of different models to compensate for the biases and errors of individual models for better performance. Deep model fusion on large-scale deep learning models (such as LLM and basic models) faces some challenges, including high computational cost, high-dimensional parameter space, interference between different heterogeneous models, etc. This article divides existing deep model fusion methods into four categories: (1) "Pattern connection", which connects solutions in the weight space through a loss-reducing path to obtain a better initial model fusion
 Huawei will launch the Xuanji sensing system in the field of smart wearables, which can assess the user's emotional state based on heart rate
Aug 29, 2024 pm 03:30 PM
Huawei will launch the Xuanji sensing system in the field of smart wearables, which can assess the user's emotional state based on heart rate
Aug 29, 2024 pm 03:30 PM
Recently, Huawei announced that it will launch a new smart wearable product equipped with Xuanji sensing system in September, which is expected to be Huawei's latest smart watch. This new product will integrate advanced emotional health monitoring functions. The Xuanji Perception System provides users with a comprehensive health assessment with its six characteristics - accuracy, comprehensiveness, speed, flexibility, openness and scalability. The system uses a super-sensing module and optimizes the multi-channel optical path architecture technology, which greatly improves the monitoring accuracy of basic indicators such as heart rate, blood oxygen and respiration rate. In addition, the Xuanji Sensing System has also expanded the research on emotional states based on heart rate data. It is not limited to physiological indicators, but can also evaluate the user's emotional state and stress level. It supports the monitoring of more than 60 sports health indicators, covering cardiovascular, respiratory, neurological, endocrine,
 More than just 3D Gaussian! Latest overview of state-of-the-art 3D reconstruction techniques
Jun 02, 2024 pm 06:57 PM
More than just 3D Gaussian! Latest overview of state-of-the-art 3D reconstruction techniques
Jun 02, 2024 pm 06:57 PM
Written above & The author’s personal understanding is that image-based 3D reconstruction is a challenging task that involves inferring the 3D shape of an object or scene from a set of input images. Learning-based methods have attracted attention for their ability to directly estimate 3D shapes. This review paper focuses on state-of-the-art 3D reconstruction techniques, including generating novel, unseen views. An overview of recent developments in Gaussian splash methods is provided, including input types, model structures, output representations, and training strategies. Unresolved challenges and future directions are also discussed. Given the rapid progress in this field and the numerous opportunities to enhance 3D reconstruction methods, a thorough examination of the algorithm seems crucial. Therefore, this study provides a comprehensive overview of recent advances in Gaussian scattering. (Swipe your thumb up
