

Used for lidar point cloud self-supervised pre-training SOTA!


Thesis idea:
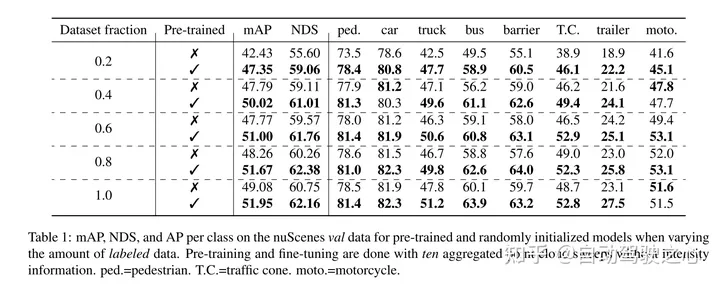
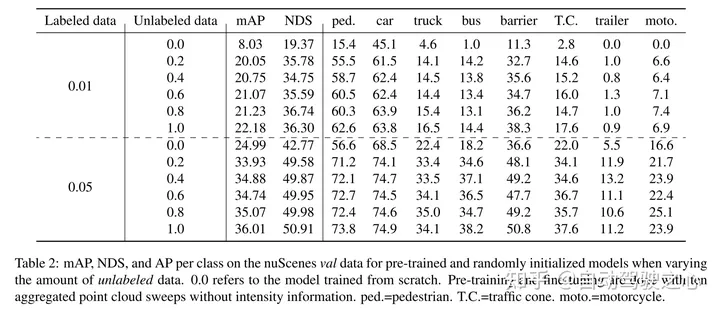
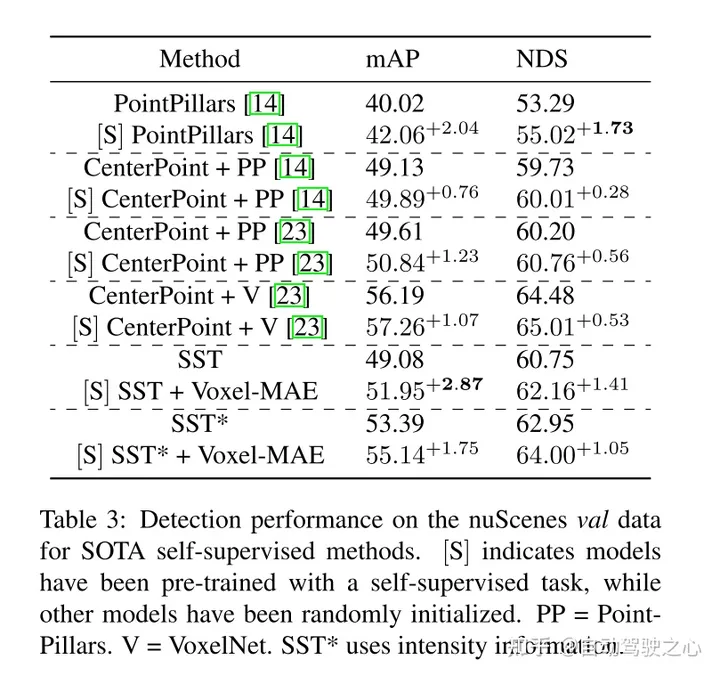
masked autoencoding has become a successful pre-training paradigm for Transformer models of text, images, and most recently point clouds. Raw car datasets are suitable for self-supervised pre-training because they are generally less expensive to collect than annotation for tasks such as 3D object detection (OD). However, the development of masked autoencoders for point clouds has only focused on synthetic and indoor data. Therefore, existing methods have tailored their representations and models into small and dense point clouds with uniform point density. In this work, we investigate masked autoencoding of point clouds in automotive settings, which are sparse and whose density can vary significantly between different objects in the same scene. . To this end, this paper proposes Voxel-MAE, a simple masked autoencoding pre-training scheme designed for voxel representation. This paper pre-trains a Transformer-based 3D object detector backbone to reconstruct masked voxels and distinguish empty voxels from non-empty voxels. Our method improves 3D OD performance of 1.75 mAP and 1.05 NDS on the challenging nuScenes dataset. Furthermore, we show that by using Voxel-MAE for pre-training, we require only 40% annotated data to outperform the equivalent data with random initialization.
Main contributions:
This paper proposes Voxel-MAE (a method of deploying MAE-style self-supervised pre-training on voxelized point clouds) , and evaluated it on the large automotive point cloud dataset nuScenes. The method in this article is the first self-supervised pre-training scheme using the automotive point cloud Transformer backbone.
We tailor our method for voxel representation and use a unique set of reconstruction tasks to capture the characteristics of voxelized point clouds.
This article proves that our method is data efficient and reduces the need for annotated data. With pre-training, this paper outperforms fully supervised data when using only 40% of the annotated data.
Additionally, this paper finds that Voxel-MAE improves the performance of Transformer-based detectors by 1.75 percentage points in mAP and 1.05 percentage points in NDS, compared with existing self-supervised methods. , its performance is improved by 2 times.
Network Design:
The purpose of this work is to extend MAE-style pre-training to voxelized point clouds. The core idea is still to use an encoder to create a rich latent representation from partial observations of the input, and then use a decoder to reconstruct the original input, as shown in Figure 2. After pre-training, the encoder is used as the backbone of the 3D object detector. However, due to fundamental differences between images and point clouds, some modifications are required for efficient training of Voxel-MAE.
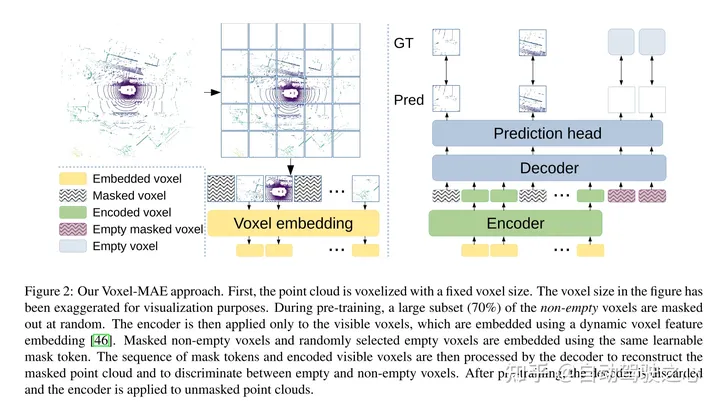
Figure 2: Voxel-MAE method of this article. First, the point cloud is voxelized with a fixed voxel size. Voxel sizes in the figures have been exaggerated for visualization purposes. Before training, a large portion (70%) of non-empty voxels are randomly masked. The encoder is then applied only to visible voxels, embedding these voxels using dynamic voxel features embedding [46]. Masked non-empty voxels and randomly selected empty voxels are embedded using the same learnable mask tokens. The decoder then processes the sequence of mask tokens and the encoded sequence of visible voxels to reconstruct the masked point cloud and distinguish empty voxels from non-empty voxels. After pre-training, the decoder is discarded and the encoder is applied to the unmasked point cloud.

Figure 1: MAE (left) divides the image into fixed-size non-overlapping patches. Existing masked point modeling methods (middle) create a fixed number of point cloud patches by using farthest point sampling and k-nearest neighbors. Our method (right) uses non-overlapping voxels and a dynamic number of points.
Experimental results:
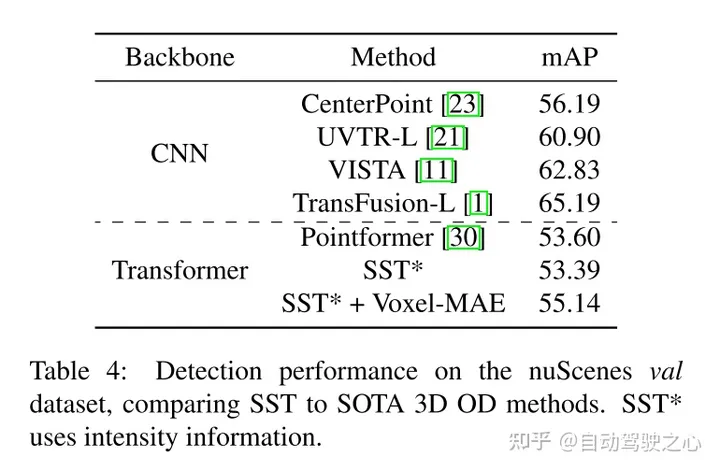
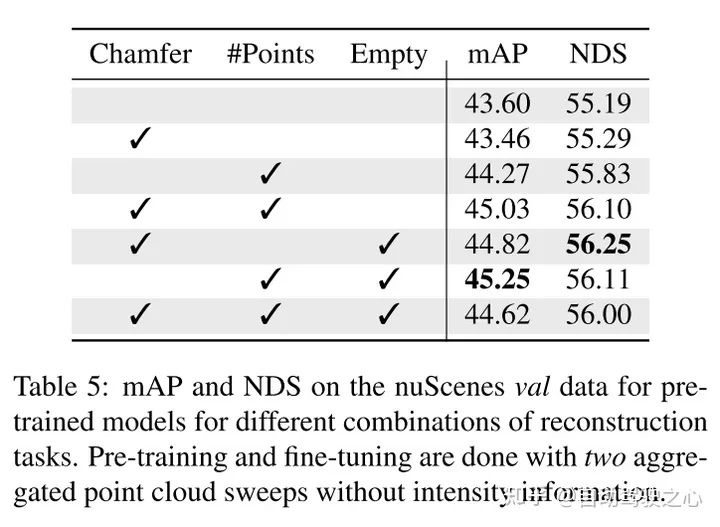
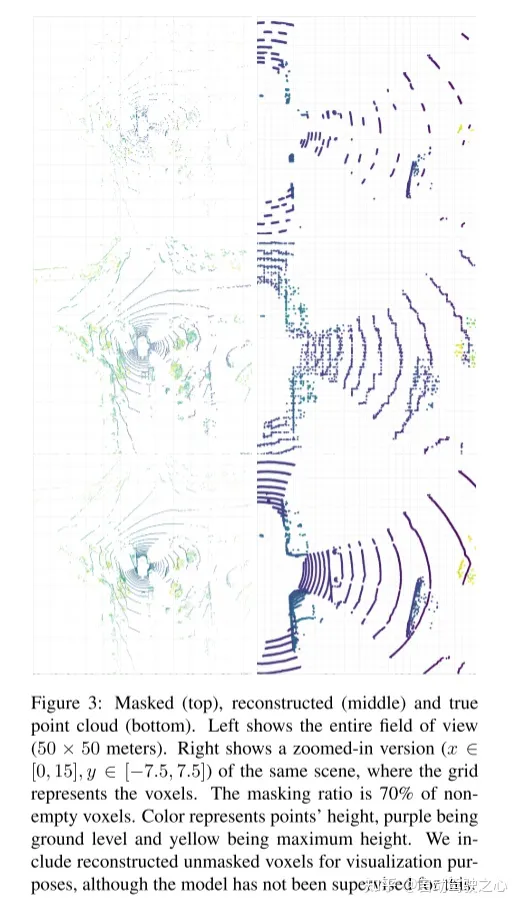 ##
##
引用:
Hess G, Jaxing J, Svensson E, et al. Masked autoencoder for self-supervised pre-training on lidar point clouds[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2023: 350-359.
The above is the detailed content of Used for lidar point cloud self-supervised pre-training SOTA!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3’s paper is finally here! This model was released two weeks ago and uses the same DiT (DiffusionTransformer) architecture as Sora. It caused quite a stir once it was released. Compared with the previous version, the quality of the images generated by StableDiffusion3 has been significantly improved. It now supports multi-theme prompts, and the text writing effect has also been improved, and garbled characters no longer appear. StabilityAI pointed out that StableDiffusion3 is a series of models with parameter sizes ranging from 800M to 8B. This parameter range means that the model can be run directly on many portable devices, significantly reducing the use of AI
 Have you really mastered coordinate system conversion? Multi-sensor issues that are inseparable from autonomous driving
Oct 12, 2023 am 11:21 AM
Have you really mastered coordinate system conversion? Multi-sensor issues that are inseparable from autonomous driving
Oct 12, 2023 am 11:21 AM
The first pilot and key article mainly introduces several commonly used coordinate systems in autonomous driving technology, and how to complete the correlation and conversion between them, and finally build a unified environment model. The focus here is to understand the conversion from vehicle to camera rigid body (external parameters), camera to image conversion (internal parameters), and image to pixel unit conversion. The conversion from 3D to 2D will have corresponding distortion, translation, etc. Key points: The vehicle coordinate system and the camera body coordinate system need to be rewritten: the plane coordinate system and the pixel coordinate system. Difficulty: image distortion must be considered. Both de-distortion and distortion addition are compensated on the image plane. 2. Introduction There are four vision systems in total. Coordinate system: pixel plane coordinate system (u, v), image coordinate system (x, y), camera coordinate system () and world coordinate system (). There is a relationship between each coordinate system,
 This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
Trajectory prediction plays an important role in autonomous driving. Autonomous driving trajectory prediction refers to predicting the future driving trajectory of the vehicle by analyzing various data during the vehicle's driving process. As the core module of autonomous driving, the quality of trajectory prediction is crucial to downstream planning control. The trajectory prediction task has a rich technology stack and requires familiarity with autonomous driving dynamic/static perception, high-precision maps, lane lines, neural network architecture (CNN&GNN&Transformer) skills, etc. It is very difficult to get started! Many fans hope to get started with trajectory prediction as soon as possible and avoid pitfalls. Today I will take stock of some common problems and introductory learning methods for trajectory prediction! Introductory related knowledge 1. Are the preview papers in order? A: Look at the survey first, p
 DualBEV: significantly surpassing BEVFormer and BEVDet4D, open the book!
Mar 21, 2024 pm 05:21 PM
DualBEV: significantly surpassing BEVFormer and BEVDet4D, open the book!
Mar 21, 2024 pm 05:21 PM
This paper explores the problem of accurately detecting objects from different viewing angles (such as perspective and bird's-eye view) in autonomous driving, especially how to effectively transform features from perspective (PV) to bird's-eye view (BEV) space. Transformation is implemented via the Visual Transformation (VT) module. Existing methods are broadly divided into two strategies: 2D to 3D and 3D to 2D conversion. 2D-to-3D methods improve dense 2D features by predicting depth probabilities, but the inherent uncertainty of depth predictions, especially in distant regions, may introduce inaccuracies. While 3D to 2D methods usually use 3D queries to sample 2D features and learn the attention weights of the correspondence between 3D and 2D features through a Transformer, which increases the computational and deployment time.
 Easily understand 4K HD images! This large multi-modal model automatically analyzes the content of web posters, making it very convenient for workers.
Apr 23, 2024 am 08:04 AM
Easily understand 4K HD images! This large multi-modal model automatically analyzes the content of web posters, making it very convenient for workers.
Apr 23, 2024 am 08:04 AM
A large model that can automatically analyze the content of PDFs, web pages, posters, and Excel charts is not too convenient for workers. The InternLM-XComposer2-4KHD (abbreviated as IXC2-4KHD) model proposed by Shanghai AILab, the Chinese University of Hong Kong and other research institutions makes this a reality. Compared with other multi-modal large models that have a resolution limit of no more than 1500x1500, this work increases the maximum input image of multi-modal large models to more than 4K (3840x1600) resolution, and supports any aspect ratio and 336 pixels to 4K Dynamic resolution changes. Three days after its release, the model topped the HuggingFace visual question answering model popularity list. Easy to handle
 The first multi-view autonomous driving scene video generation world model | DrivingDiffusion: New ideas for BEV data and simulation
Oct 23, 2023 am 11:13 AM
The first multi-view autonomous driving scene video generation world model | DrivingDiffusion: New ideas for BEV data and simulation
Oct 23, 2023 am 11:13 AM
Some of the author’s personal thoughts In the field of autonomous driving, with the development of BEV-based sub-tasks/end-to-end solutions, high-quality multi-view training data and corresponding simulation scene construction have become increasingly important. In response to the pain points of current tasks, "high quality" can be decoupled into three aspects: long-tail scenarios in different dimensions: such as close-range vehicles in obstacle data and precise heading angles during car cutting, as well as lane line data. Scenes such as curves with different curvatures or ramps/mergings/mergings that are difficult to capture. These often rely on large amounts of data collection and complex data mining strategies, which are costly. 3D true value - highly consistent image: Current BEV data acquisition is often affected by errors in sensor installation/calibration, high-precision maps and the reconstruction algorithm itself. this led me to
 GSLAM | A general SLAM architecture and benchmark
Oct 20, 2023 am 11:37 AM
GSLAM | A general SLAM architecture and benchmark
Oct 20, 2023 am 11:37 AM
Suddenly discovered a 19-year-old paper GSLAM: A General SLAM Framework and Benchmark open source code: https://github.com/zdzhaoyong/GSLAM Go directly to the full text and feel the quality of this work ~ 1 Abstract SLAM technology has achieved many successes recently and attracted many attracted the attention of high-tech companies. However, how to effectively perform benchmarks on speed, robustness, and portability with interfaces to existing or emerging algorithms remains a problem. In this paper, a new SLAM platform called GSLAM is proposed, which not only provides evaluation capabilities but also provides researchers with a useful way to quickly develop their own SLAM systems.
 CVPR 2024 | LiDAR diffusion model for photorealistic scene generation
Apr 24, 2024 pm 04:28 PM
CVPR 2024 | LiDAR diffusion model for photorealistic scene generation
Apr 24, 2024 pm 04:28 PM
Original title: TowardsRealisticSceneGenerationwithLiDARDiffusionModels Paper link: https://hancyran.github.io/assets/paper/lidar_diffusion.pdf Code link: https://lidar-diffusion.github.io Author affiliation: CMU Toyota Research Institute University of Southern California Paper ideas : Diffusion models (DMs) excel at photorealistic image synthesis, but adapting them to lidar scene generation presents significant challenges. This is mainly because DMs operating in point space have difficulty
