
 Technology peripherals
AI
Andrew Ng likes it! Harvard and MIT scholars used chess to prove that large language models indeed 'understand' the world
Technology peripherals
AI
Andrew Ng likes it! Harvard and MIT scholars used chess to prove that large language models indeed 'understand' the world
Andrew Ng likes it! Harvard and MIT scholars used chess to prove that large language models indeed 'understand' the world

In 2021, Emily M. Bender, a linguist at the University of Washington, published a paper arguing that large language models are nothing more than "stochastic parrots". They do not understand the real world, but only count certain statistics. probability of occurrence of a word, and then randomly generates seemingly reasonable words like a parrot.
Due to the uninterpretability of neural networks, the academic community is not sure whether the language model is a random parrot, and the opinions of various parties vary greatly.
Due to the lack of widely recognized tests, whether the model can "understand the world" has become a philosophical question rather than a scientific question.
Recently, researchers from Harvard University and MIT jointly published a new study, Othello-GPT, which verified the effectiveness of internal representation in a simple board game. They believe that the language model does indeed establish a world model internally, and is not just a simple memory or statistics, but the source of its ability is unclear.

Paper link: https://arxiv.org/pdf/2210.13382.pdf
Experiment The process is very simple. Without any prior knowledge of Othello's rules, the researchers found that the model can predict legal movement operations and capture the state of the chessboard with very high accuracy.
Ng Enda highly recognized this research in the "Letter" column. He believed that based on this research, there is reason to believe that large-scale language models have built a sufficiently complex world model, and in a certain way To a certain extent, I do understand the world.
Blog link: https://www.deeplearning.ai/the-batch/does-ai-understand-the-world/
However, Andrew Ng also said that although philosophy is important, such debates may be endless, so it is better to go for programming!
Chessboard World Model
If you imagine the chessboard as a simple "world" and require the model to make continuous decisions during the game, you can initially test the sequence model Whether it is possible to learn world representations.

The researchers chose a simple Othello game, Othello, as the experimental platform. Its rules are in the center of the 8*8 chess board. , first put in four chess pieces, two each for black and white; then both sides take turns to play, in the straight or diagonal direction, all enemy pieces (cannot include spaces) between the two own pieces become your own pieces (called capturing pieces) , every time a piece is placed, there must be a piece to capture; in the end, the board is completely occupied, and the player with the most pieces wins.
Compared to chess, the rules of Othello are much simpler; at the same time, the search space of chess games is large enough, and the model cannot complete sequence generation through memory, so it is very suitable for testing the model world representation learning ability.
Othello Language Model
The researchers first trained a GPT variant language model (Othello-GPT), which combined the game script (a series of chess pieces made by the player) movement operations) are input into the model, but the model has no prior knowledge about the game and related rules.
The model is not explicitly trained to pursue strategy improvement, winning games, etc., but has a relatively high accuracy when generating legal Othello movement operations.
Dataset
The researchers used two sets of training data:
Championship pays more attention to data quality, mainly from the more strategic thinking moves adopted by professional human players in the two Othello tournaments, but only collected 7605 and 132921 game samples respectively. After the data sets were merged, they were randomly divided into a training set (20 million samples) and a validation set (3.796 million samples) in a ratio of 8:2.
Synthetic pays more attention to the scale of the data and consists of random and legal movement operations. The data distribution is different from the championship data set, but evenly drawn from the Othello game tree. Sampling is obtained, of which 20 million samples are used for training and 3.796 million samples are used for verification.
The description of each game consists of a string of tokens, and the vocabulary size is 60 (8*8-4)
Model and training
The architecture of the model is an 8-layer GPT model with 8 heads and a hidden dimension of 512
The weights of the model are completely randomly initialized, including word In the embedding layer, although there is a geometric relationship in the vocabulary representing the chessboard position (such as C4 being lower than B4), this inductive bias is not explicitly expressed and is left to model learning.
Predict legal moves
The main evaluation indicator of the model is whether the movement operation predicted by the model complies with the rules of Othello .
Othello-GPT trained on the synthetic dataset has an error rate of 0.01% and on the championship dataset an error rate of 5.17%, compared to untrained Othello -The error rate of GPT is 93.29%, which means that both data sets allow the model to learn the rules of the game to a certain extent.
One possible explanation is that the model remembers all the movement actions of the Othello game.
To test this conjecture, the researchers synthesized a new data set: at the beginning of each game, Othello has four possible opening positions (C5, D6, E3 and F4), all C5 opening moves were removed and used as the training set, and then the C5 opening data was used as the test, that is, nearly 1/4 of the game tree was removed. The results found that the model error rate was still only 0.02%
So the high performance of Othello-GPT is not due to memory, because the test data is completely unseen during the training process. So what exactly makes the model predict successfully?
Exploring internal representations
A commonly used tool for detecting internal representations of neural networks is probes. Each probe is a classifier or regressor. The input consists of the network's internal activations and is trained to predict features of interest.
In this task, in order to detect whether the internal activation of Othello-GPT contains the representation of the current chessboard state, after inputting the movement sequence, the internal activation vector is used to predict the next movement step.
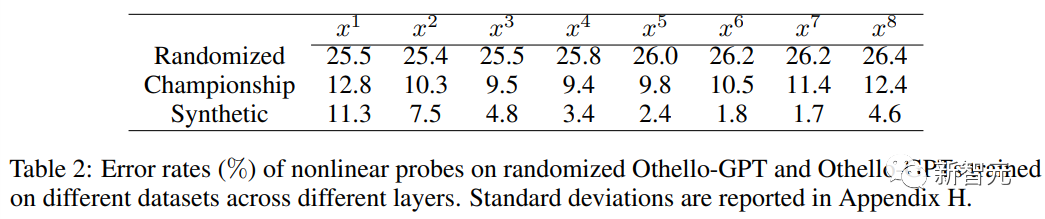
When using linear probes, the trained Othello-GPT internal representation is only slightly more accurate than random guessing.

When using nonlinear probes (two-layer MLP), the error rate drops significantly, proving that the chessboard state is not represented by a simple The method is stored in network activation.
Intervention experiment
To determine the causal relationship between model predictions and emergent world representations, i.e. whether the chessboard state indeed affects To predict the network's results, the researchers conducted a set of intervention trials and measured the resulting impact.
Given a set of activations from Othello-GPT, use probes to predict the board state, record the associated move predictions, and then modify the activations to let the probes predict the updated board state.
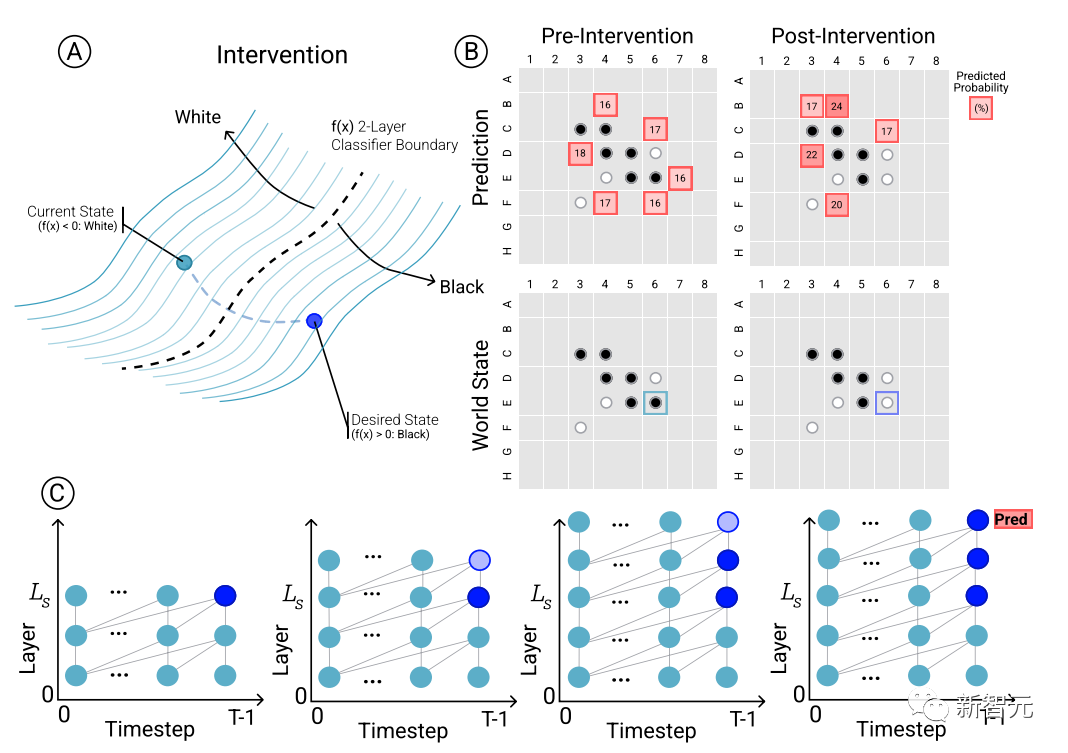
Intervention operations include changing the chess piece in a certain position from white to black, etc. A small modification will lead to the model finding that the internal representation can Predictions are done reliably, i.e. there is a causal influence between internal representations and model predictions.
Visualization
In addition to the intervention experiments to verify the effectiveness of the internal representation, the researchers also visualized the prediction results. For example, for each chess piece on the chessboard, you can ask If the model uses intervention technology to change the chess piece, how the model's prediction results will change corresponds to the significance of the prediction results.
Then the cards are colored and visualized based on the saliency predicted by top1 of the current chessboard state. Because the drawn picture is input based on the latent space of the network, it can also be called potential saliency. Figure (latent saliency map).

As can be seen, clear patterns are shown in the latent saliency maps of the top1 predictions of Othello-GPTs trained on both the synthetic and tournament datasets.
The synthetic version of Othello-GPT shows a higher significance value in legal operation positions, and the significance value of illegal operations is significantly lower, for players with a little experience The intention of the model can be seen;
The saliency map of the tournament version is more complex. Although the saliency value of the legal operation position is relatively high, other positions also show higher saliency values. Salience, may be because Othello masters consider more global features.
The above is the detailed content of Andrew Ng likes it! Harvard and MIT scholars used chess to prove that large language models indeed 'understand' the world. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 What is the syntax for adding columns in SQL
Apr 09, 2025 pm 02:51 PM
What is the syntax for adding columns in SQL
Apr 09, 2025 pm 02:51 PM
The syntax for adding columns in SQL is ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value]; where table_name is the table name, column_name is the new column name, data_type is the data type, NOT NULL specifies whether null values are allowed, and DEFAULT default_value specifies the default value.
 SQL Clear Table: Performance Optimization Tips
Apr 09, 2025 pm 02:54 PM
SQL Clear Table: Performance Optimization Tips
Apr 09, 2025 pm 02:54 PM
Tips to improve SQL table clearing performance: Use TRUNCATE TABLE instead of DELETE, free up space and reset the identity column. Disable foreign key constraints to prevent cascading deletion. Use transaction encapsulation operations to ensure data consistency. Batch delete big data and limit the number of rows through LIMIT. Rebuild the index after clearing to improve query efficiency.
 Use DELETE statement to clear SQL tables
Apr 09, 2025 pm 03:00 PM
Use DELETE statement to clear SQL tables
Apr 09, 2025 pm 03:00 PM
Yes, the DELETE statement can be used to clear a SQL table, the steps are as follows: Use the DELETE statement: DELETE FROM table_name; Replace table_name with the name of the table to be cleared.
 phpmyadmin creates data table
Apr 10, 2025 pm 11:00 PM
phpmyadmin creates data table
Apr 10, 2025 pm 11:00 PM
To create a data table using phpMyAdmin, the following steps are essential: Connect to the database and click the New tab. Name the table and select the storage engine (InnoDB recommended). Add column details by clicking the Add Column button, including column name, data type, whether to allow null values, and other properties. Select one or more columns as primary keys. Click the Save button to create tables and columns.
 How to deal with Redis memory fragmentation?
Apr 10, 2025 pm 02:24 PM
How to deal with Redis memory fragmentation?
Apr 10, 2025 pm 02:24 PM
Redis memory fragmentation refers to the existence of small free areas in the allocated memory that cannot be reassigned. Coping strategies include: Restart Redis: completely clear the memory, but interrupt service. Optimize data structures: Use a structure that is more suitable for Redis to reduce the number of memory allocations and releases. Adjust configuration parameters: Use the policy to eliminate the least recently used key-value pairs. Use persistence mechanism: Back up data regularly and restart Redis to clean up fragments. Monitor memory usage: Discover problems in a timely manner and take measures.
 How to create an oracle database How to create an oracle database
Apr 11, 2025 pm 02:33 PM
How to create an oracle database How to create an oracle database
Apr 11, 2025 pm 02:33 PM
Creating an Oracle database is not easy, you need to understand the underlying mechanism. 1. You need to understand the concepts of database and Oracle DBMS; 2. Master the core concepts such as SID, CDB (container database), PDB (pluggable database); 3. Use SQL*Plus to create CDB, and then create PDB, you need to specify parameters such as size, number of data files, and paths; 4. Advanced applications need to adjust the character set, memory and other parameters, and perform performance tuning; 5. Pay attention to disk space, permissions and parameter settings, and continuously monitor and optimize database performance. Only by mastering it skillfully requires continuous practice can you truly understand the creation and management of Oracle databases.
 How to create oracle database How to create oracle database
Apr 11, 2025 pm 02:36 PM
How to create oracle database How to create oracle database
Apr 11, 2025 pm 02:36 PM
To create an Oracle database, the common method is to use the dbca graphical tool. The steps are as follows: 1. Use the dbca tool to set the dbName to specify the database name; 2. Set sysPassword and systemPassword to strong passwords; 3. Set characterSet and nationalCharacterSet to AL32UTF8; 4. Set memorySize and tablespaceSize to adjust according to actual needs; 5. Specify the logFile path. Advanced methods are created manually using SQL commands, but are more complex and prone to errors. Pay attention to password strength, character set selection, tablespace size and memory
 Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Effective monitoring of Redis databases is critical to maintaining optimal performance, identifying potential bottlenecks, and ensuring overall system reliability. Redis Exporter Service is a powerful utility designed to monitor Redis databases using Prometheus. This tutorial will guide you through the complete setup and configuration of Redis Exporter Service, ensuring you seamlessly build monitoring solutions. By studying this tutorial, you will achieve fully operational monitoring settings
