
 Technology peripherals
AI
Apache IoTDB: an innovative database that solves storage, query and usage problems in industrial IoT scenarios
Technology peripherals
AI
Apache IoTDB: an innovative database that solves storage, query and usage problems in industrial IoT scenarios
Apache IoTDB: an innovative database that solves storage, query and usage problems in industrial IoT scenarios

With the advent of the Industry 4.0 era, the production environment has become more efficient with the introduction of digitization and automation. At the same time, people are beginning to pay attention to the potential value of the massive data brought by smart devices, but how to efficiently store the data generated by smart devices and how to better analyze the massive data has become a problem. Traditional database models and storage methods can no longer meet these needs. Therefore, the time series database emerged as the times require, aiming to achieve efficient data storage and query, and help better explore the potential value of data
Faced with such a situation, Tsinghua University in 2015 Started the development of IoTDB. On September 23, 2020, Apache IoTDB graduated and became an Apache Top-Level Project. It is currently the only Apache Foundation top-level project initiated by Chinese universities and is also the only open source project in the field of IoT data management under the Apache Foundation. In October 2021, the Apache IoTDB core team founded Tianmou Technology and continues to operate IoTDB to help industrial users solve the problems of data "storage, search, and use".
Regarding the core technology developed by Apache IoTDB, several participants collaborated to publish a review paper, which elaborated on the design of IoTDB in detail and completely. The article takes an industrial company that needs to manage tens of thousands of excavators as an example and describes the requirements: "The data is first packaged into the device, and then sent to the server through the 5G mobile network. In the server, the data is written into the time series database, For OLTP queries. Finally, data scientists can load data from the database into the big data platform for complex analysis and prediction, that is, OLAP tasks."

- Paper address: https://dl.acm.org/doi/abs/10.1145/3589775
- ##Project address: https://github.com/ apache/iotdb
The key points of the paper include the following parts:
1. Design of data model: Organization of time series at the logical level and storage in physical schema;
2. TsFile file Format: Self-developed columnar storage file format, which also meets the efficiency of writing, querying, etc.;
3. IoTDB engine : Mainly includes storage engines, query engines, etc.;
Distributed solutions refer to decomposing a task or problem into multiple subtasks , and allocate these subtasks to multiple computers or nodes for processing. This solution improves system reliability, scalability and performance. By distributing tasks to multiple computers, the load on a single computer can be reduced and the concurrent processing capabilities of the system can be improved. At the same time, distributed solutions can also enhance the fault tolerance of the system through redundant backup and failover. Even if a node fails, the system can still continue to run. In today's big data and cloud computing environment, distributed solutions have become a common architectural pattern and are widely used in various fields, such as distributed databases, distributed storage systems, distributed computing platforms, etc.
For the following content, we will explain these key parts in more detail
Detailed interpretation
Requires data model design
As shown in the figure below, we use The tree structure is used to meet high-intensity write operations, and can effectively handle the common delayed data arrival problem in IoT scenarios
In the tree structure, each leaf node represents A sensor, each sensor has a corresponding device. As shown in the bottom two levels in the figure, the same applies to the upward levels
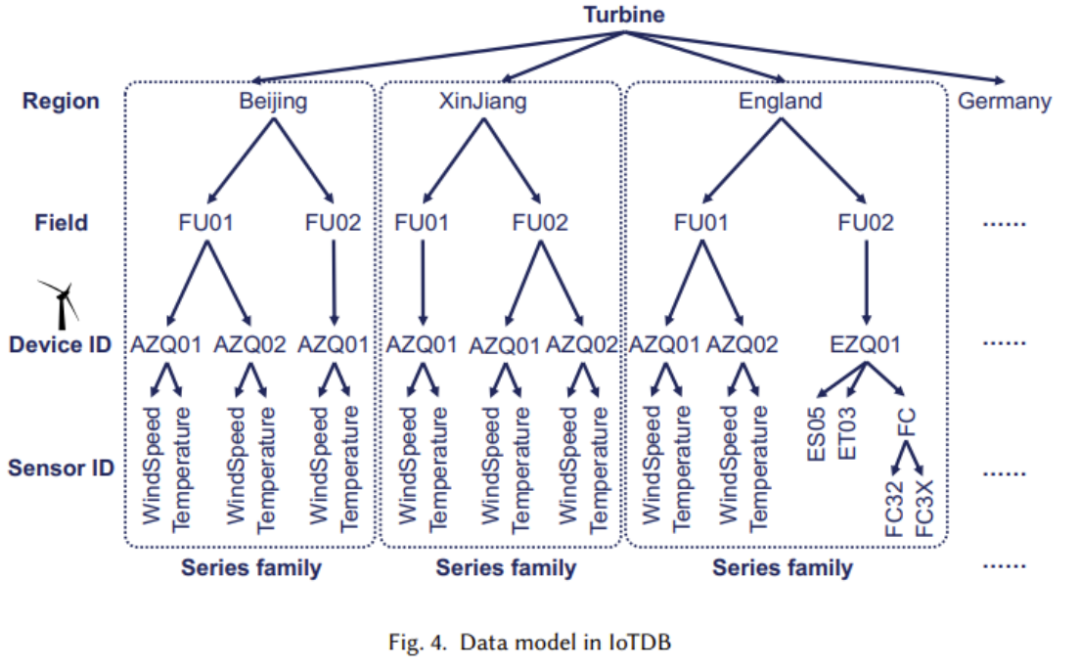
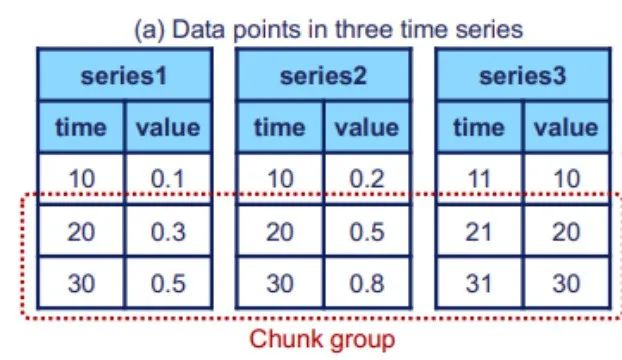
(2) The logical structure has been explained in the previous article, Now we will look at the implementation of the physical structure, which mainly includes two parts: time series (Time series) and sequence family (Series family). The figure below shows that each time series consists of two attributes: time and value. The time series is located through the complete path from the root node to the leaf node. The above figure shows the concept of sequence cluster. A sequence cluster may contain multiple devices, and their data will be stored together in TsFile (a file structure, which will be explained later)
What needs to be rewritten is: 2. TsFile file format design
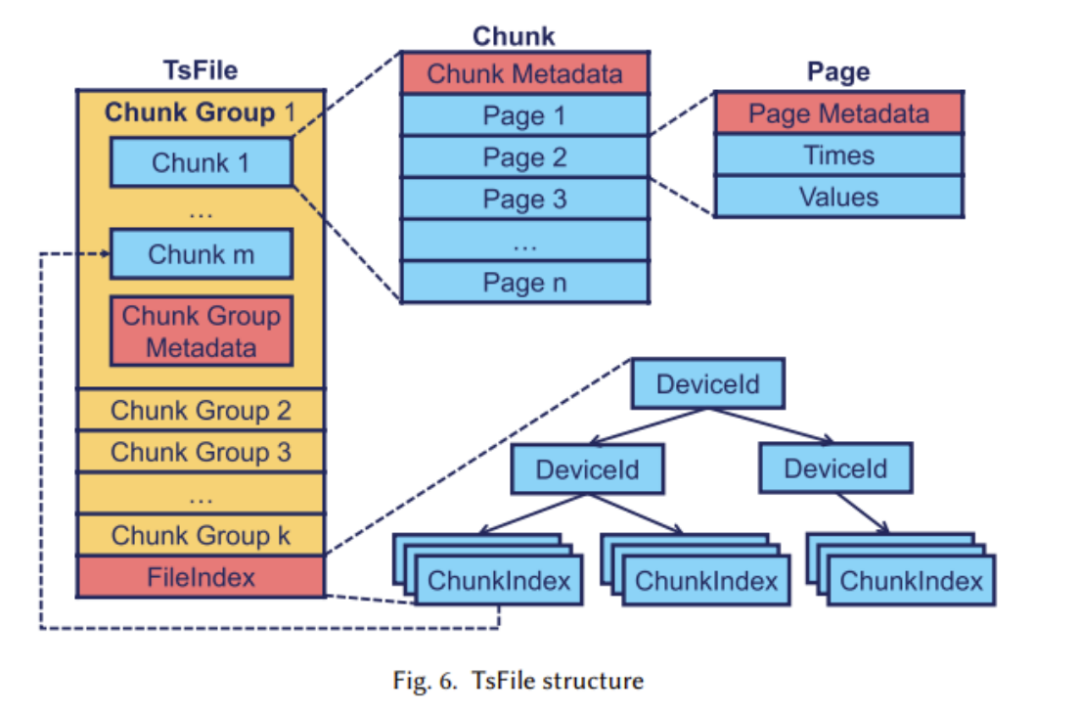
TsFile is Apache IoTDB's self-developed columnar storage file format. Its structure is shown in the figure below:
When designing TsFile, the research team mainly focused on solving the following problems:
- Save space and compress data as much as possible
- Reduce the number of files
- Will query the time series together in the physical location Close to
- Reduce disk fragmentation
- Efficient access
Mainly provided The solution is:
- Column storage: eliminates null values, saves disk usage; data access locality
- time Sequence encoding: Taking advantage of the unique characteristics of time series in IoT scenarios
- Frequency domain encoding: Frequency domain analysis of time series is widely performed in signal processing
- Specific structure analysis: Page (Page) is the basic storage unit. Chunk contains multiple Pages. The pages in a chunk belong to the same time series and are variable in size; Chunk Group contains multiple Chunks, multiple pages in a group. Chunk belongs to one or more series of devices written within the same period of time. They are placed in continuous disk space because they are often queried together; Block is in memory, and the written block group is first in memory. Buffering is performed in TsFile, and when the memory reaches the threshold, all block groups are flushed to TsFile; the index (FileIndex) records information at the end of the file for data access.
The content that needs to be rewritten is: 3. IoTDB engine
In this part, researchers mainly focus on delayed arrival, efficient query processing and the design of SQL-like queries in IoT scenarios. The structure of the IoTDB engine is shown in the following figure:
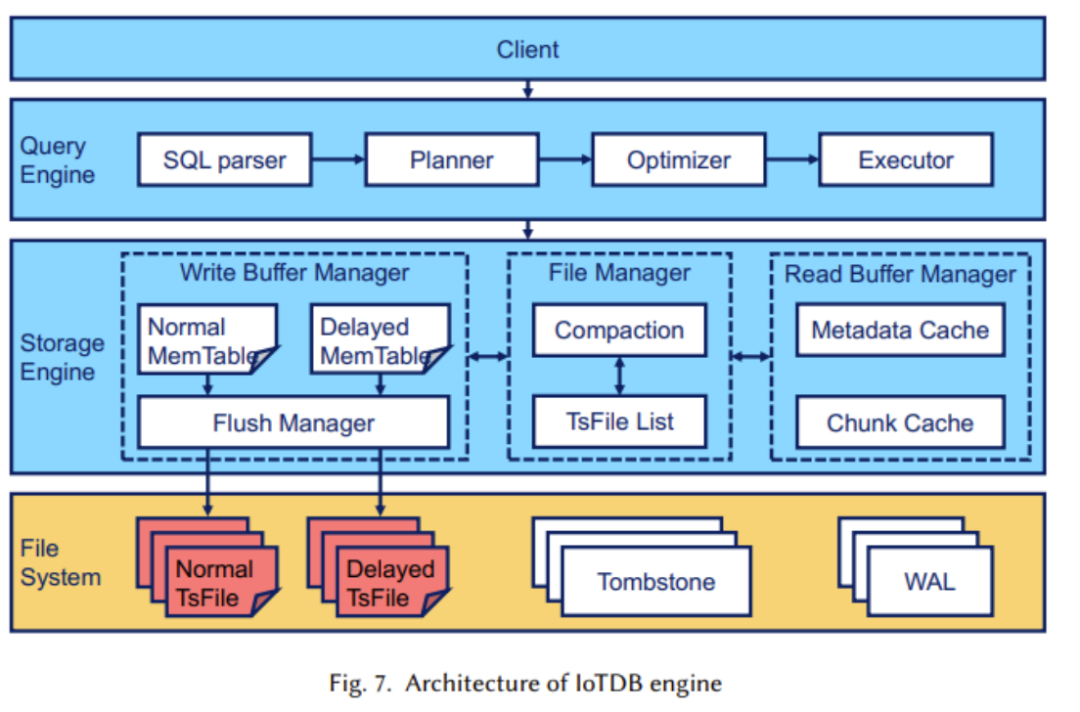
In the figure, we can see that the storage engine part is mainly used to process the writing of TsFile, Read and manage. In this part, automatic delay separation technology is adopted (as shown in the figure below)
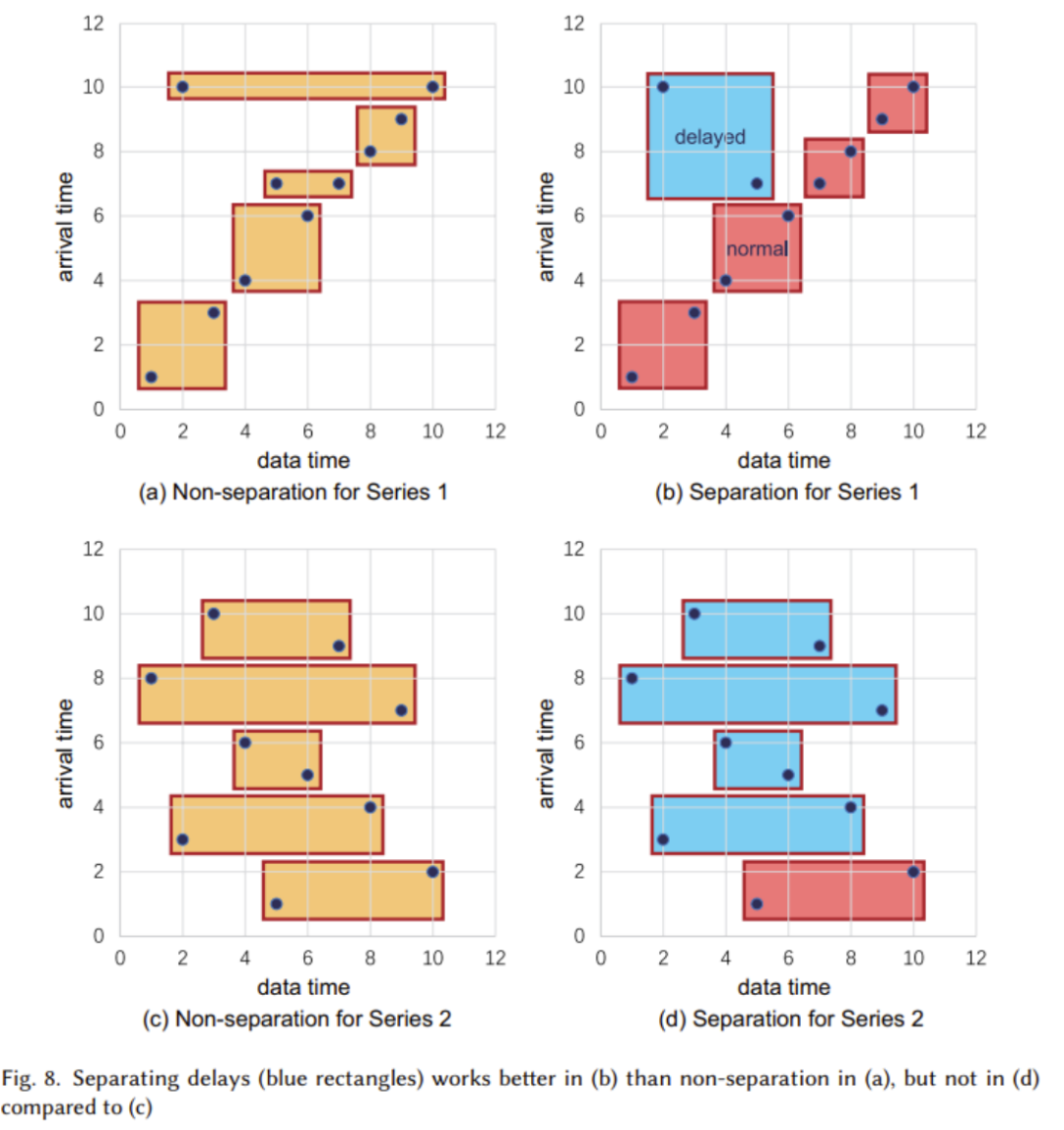
In most cases, when the time range in TsFile Lazy data separation is recommended when there is no overlap. However, for situations where most data is unordered, lazy data separation is not recommended
After rewriting: Another important component is the query engine, which is responsible for converting SQL Queries are converted into operators that can be executed in the database. At the same time, in order to adapt to industrial IoT scenarios, Apache IoTDB has also designed a rich time series data query function
The content that needs to be rewritten is: 4. Decentralized solution
TsFile can be distributed on HDFS and operated by Spark. In addition, it also provides native solutions for better handling of data distribution and query processing, including partition replication, NB-Raft replication and dynamic read consistency
Comparison results
In the paper, we compare TsFile and IoTDB, which are state-of-the-art file formats and timing databases widely used in industry. Through the following figure, we demonstrate the advantages of Apache IoTDB in many aspects
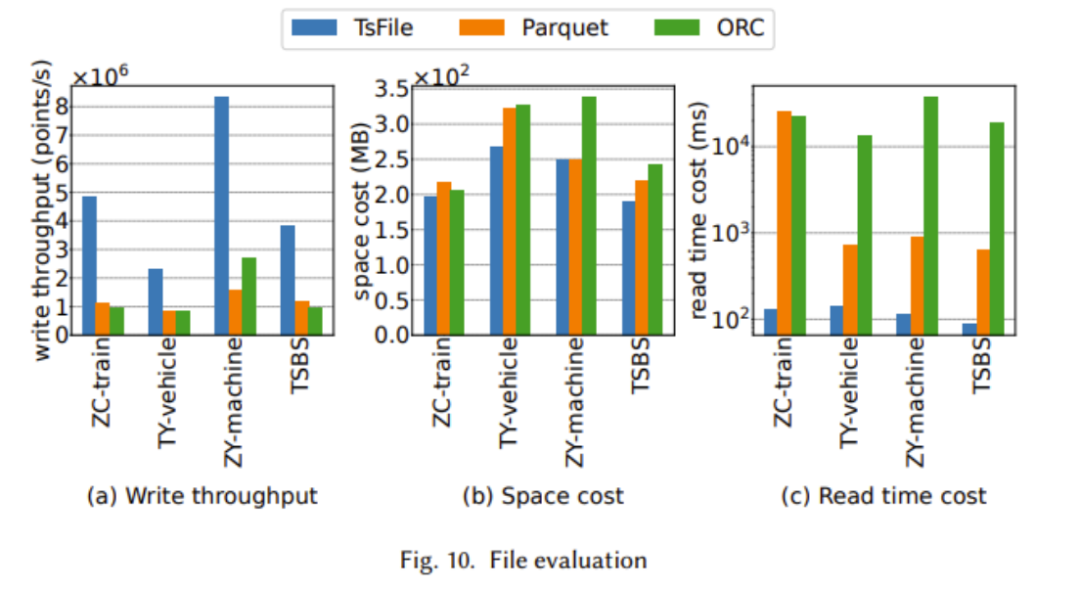
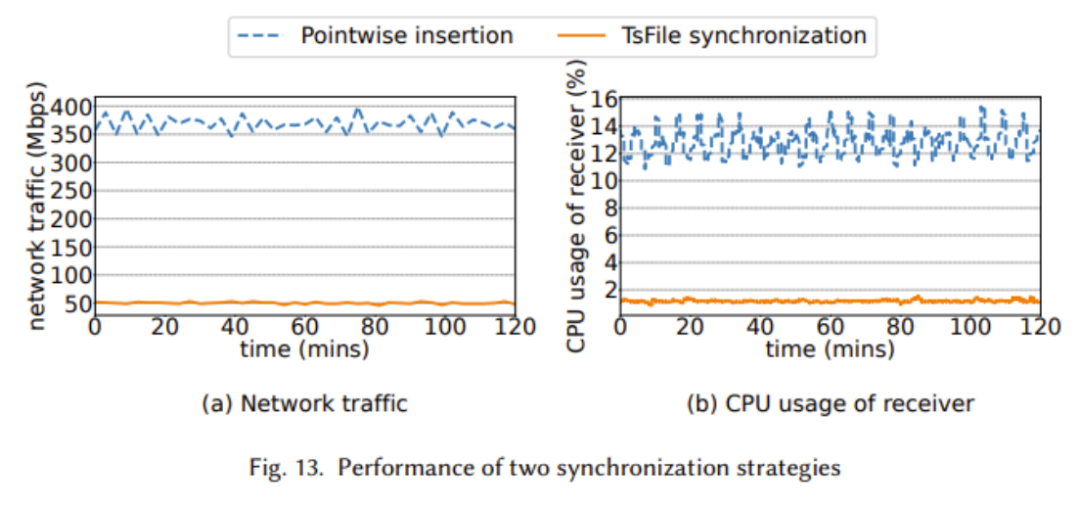
The above two figures show TsFile’s advantages in write throughput, read time cost and synchronization performance. This is mainly due to TsFile’s IoT-aware structure design, which avoids storing redundant information such as deviceId. Although there is no obvious advantage in disk usage of TsFile, this is because a more granular index is built, resulting in more space taken up. However, this sacrifice can lead to extraordinary query time improvements, as we can see a clear advantage in read time cost
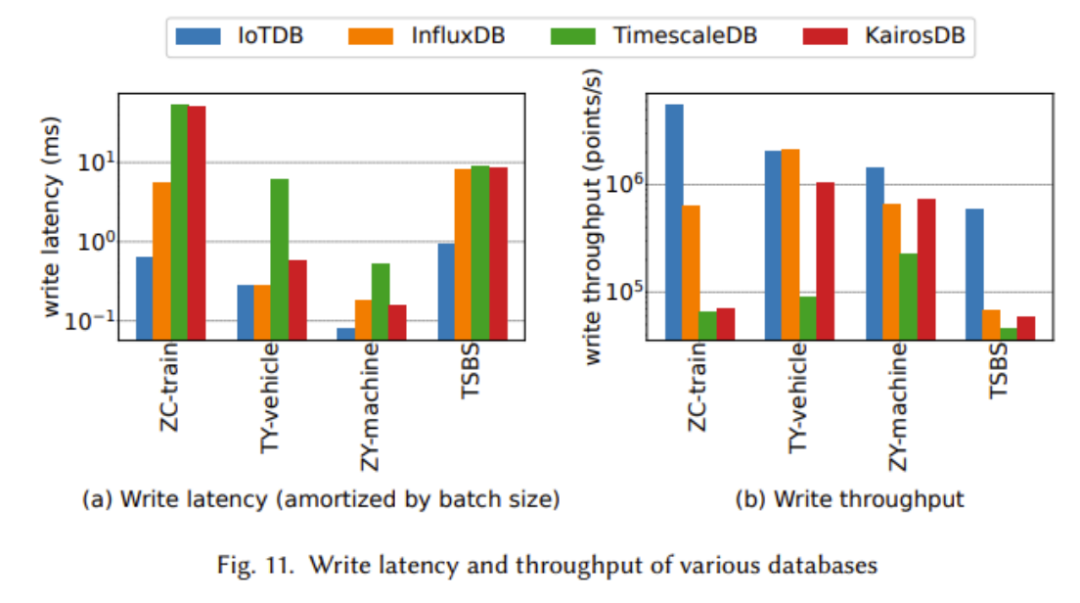
in the above chart It can be clearly seen that IoTDB exhibits better performance in almost all tests, including higher write throughput and lower write latency
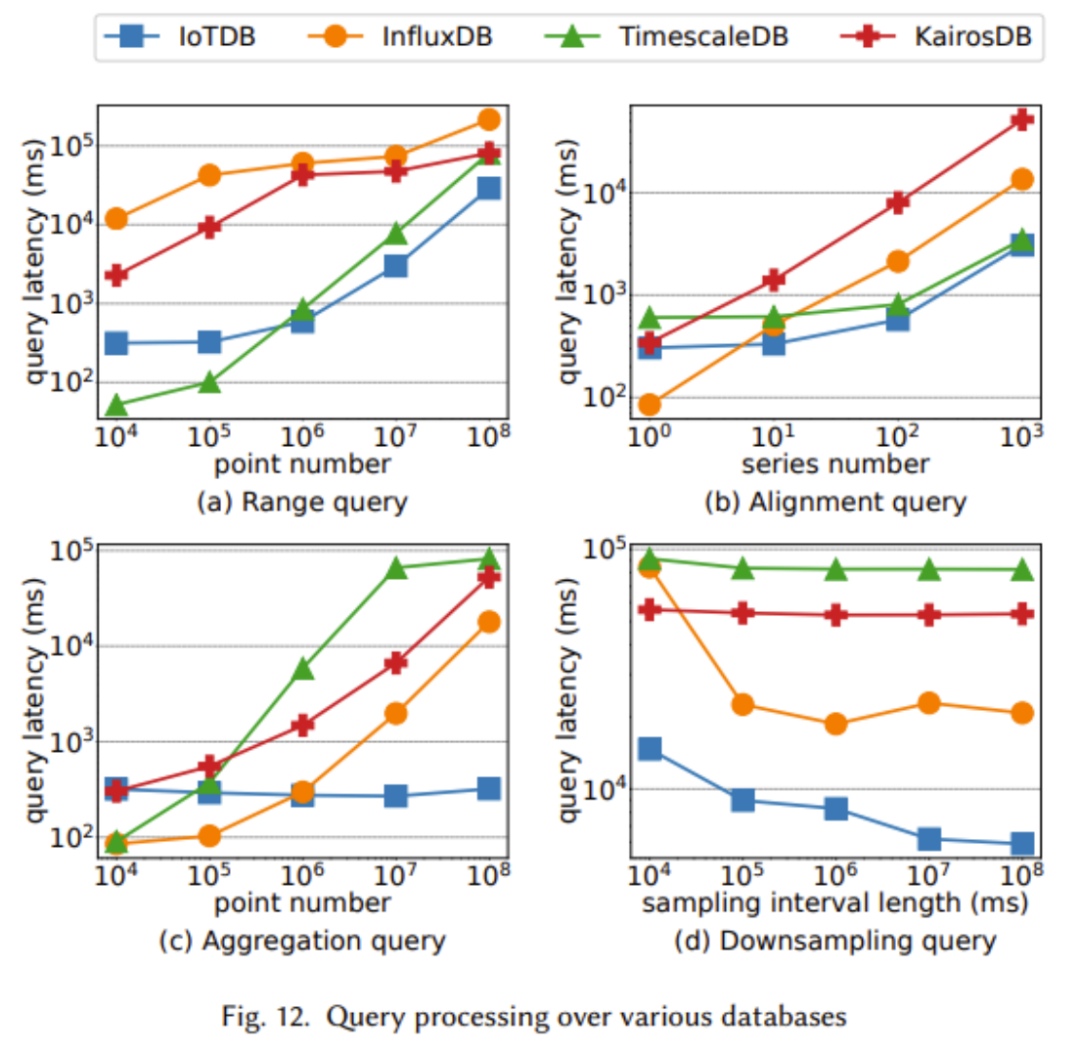
In the above experiments, we observed that IoTDB showed better performance when the query data size was larger. Especially in large-scale data aggregation, the advantages of IoTDB are particularly obvious
Summary
This paper introduces a new method called Apache IoTDB A new time series data management system that adopts an open architecture and is specifically designed to support real-time query and big data analysis for IoT applications. The system includes a new time series file format called TsFile, which uses column storage to store times and values to avoid null values and achieve effective compression. Based on TsFile, the IoTDB engine uses an LSM tree-like strategy to handle high-intensity writes and can handle the common delayed data arrival problem in IoT scenarios. Rich scalable query functions and pre-computed statistical information in TsFile enable IoTDB to efficiently handle OLTP and OLAP tasks
IoTDB has become better able to cope with industrial IoT scenarios A new type of database, which is the result of the above technology
The above is the detailed content of Apache IoTDB: an innovative database that solves storage, query and usage problems in industrial IoT scenarios. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Configuring a Debian mail server's firewall is an important step in ensuring server security. The following are several commonly used firewall configuration methods, including the use of iptables and firewalld. Use iptables to configure firewall to install iptables (if not already installed): sudoapt-getupdatesudoapt-getinstalliptablesView current iptables rules: sudoiptables-L configuration
 How to set the Debian Apache log level
Apr 13, 2025 am 08:33 AM
How to set the Debian Apache log level
Apr 13, 2025 am 08:33 AM
This article describes how to adjust the logging level of the ApacheWeb server in the Debian system. By modifying the configuration file, you can control the verbose level of log information recorded by Apache. Method 1: Modify the main configuration file to locate the configuration file: The configuration file of Apache2.x is usually located in the /etc/apache2/ directory. The file name may be apache2.conf or httpd.conf, depending on your installation method. Edit configuration file: Open configuration file with root permissions using a text editor (such as nano): sudonano/etc/apache2/apache2.conf
 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
 How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
The readdir function in the Debian system is a system call used to read directory contents and is often used in C programming. This article will explain how to integrate readdir with other tools to enhance its functionality. Method 1: Combining C language program and pipeline First, write a C program to call the readdir function and output the result: #include#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 Debian mail server SSL certificate installation method
Apr 13, 2025 am 11:39 AM
Debian mail server SSL certificate installation method
Apr 13, 2025 am 11:39 AM
The steps to install an SSL certificate on the Debian mail server are as follows: 1. Install the OpenSSL toolkit First, make sure that the OpenSSL toolkit is already installed on your system. If not installed, you can use the following command to install: sudoapt-getupdatesudoapt-getinstallopenssl2. Generate private key and certificate request Next, use OpenSSL to generate a 2048-bit RSA private key and a certificate request (CSR): openss
 How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
In Debian systems, the readdir function is used to read directory contents, but the order in which it returns is not predefined. To sort files in a directory, you need to read all files first, and then sort them using the qsort function. The following code demonstrates how to sort directory files using readdir and qsort in Debian system: #include#include#include#include#include//Custom comparison function, used for qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 How to perform digital signature verification with Debian OpenSSL
Apr 13, 2025 am 11:09 AM
How to perform digital signature verification with Debian OpenSSL
Apr 13, 2025 am 11:09 AM
Using OpenSSL for digital signature verification on Debian systems, you can follow these steps: Preparation to install OpenSSL: Make sure your Debian system has OpenSSL installed. If not installed, you can use the following command to install it: sudoaptupdatesudoaptininstallopenssl to obtain the public key: digital signature verification requires the signer's public key. Typically, the public key will be provided in the form of a file, such as public_key.pe
 How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
In Debian systems, OpenSSL is an important library for encryption, decryption and certificate management. To prevent a man-in-the-middle attack (MITM), the following measures can be taken: Use HTTPS: Ensure that all network requests use the HTTPS protocol instead of HTTP. HTTPS uses TLS (Transport Layer Security Protocol) to encrypt communication data to ensure that the data is not stolen or tampered during transmission. Verify server certificate: Manually verify the server certificate on the client to ensure it is trustworthy. The server can be manually verified through the delegate method of URLSession
