
 Technology peripherals
AI
UniOcc: Unifying vision-centric occupancy prediction with geometric and semantic rendering!
Technology peripherals
AI
UniOcc: Unifying vision-centric occupancy prediction with geometric and semantic rendering!
UniOcc: Unifying vision-centric occupancy prediction with geometric and semantic rendering!

Original title: UniOcc: Unifying Vision-Centric 3D Occupancy Prediction with Geometric and Semantic Rendering
Please click the following link to view the paper: https://arxiv.org/pdf/2306.09117.pdf

Paper idea:
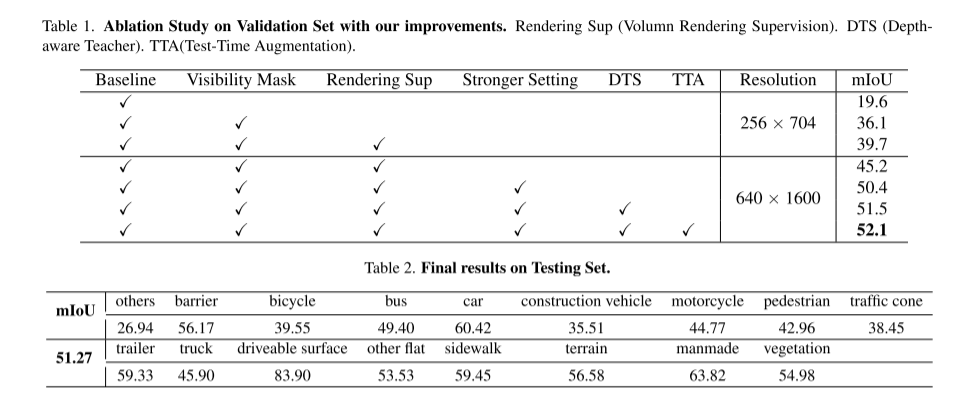
In this technical report, we propose a solution called UniOCC for use in nuScenes at CVPR 2023 Vision-centered 3D occupancy prediction trajectories are performed in the Open Dataset Challenge. Existing occupancy prediction methods mainly focus on using 3D occupancy labels to optimize the projected characteristics of the 3D volumetric space. However, the generation process of these labels is very complex and expensive (relying on 3D semantic annotation), and is limited by voxel resolution and cannot provide fine-grained spatial semantics. To address this limitation, we propose a new unified occupancy (UniOcc) prediction method that explicitly imposes spatial geometric constraints and supplements fine-grained semantic supervision with volume ray rendering. Our method significantly improves model performance and shows good potential in reducing manual annotation costs. Considering the laboriousness of annotating 3D occupancies, we further propose the depth-aware Teacher Student (DTS) framework to improve the prediction accuracy using unlabeled data. Our solution achieved 51.27% mIoU on the official single-model ranking, ranking third in this challenge
Network Design:
Here As part of this challenge, this paper proposes UniOcc, a general solution that leverages volume rendering to unify 2D and 3D representation supervision, improving multi-camera occupancy prediction models. This paper does not design a new model architecture, but focuses on enhancing existing models [3, 18, 20] in a versatile and plug-and-play manner.
Re-written as follows: This paper implements the function of generating 2D semantic and depth maps using volume rendering by upgrading the representation to NeRF-style representation [1,15,21]. This enables fine-grained supervision at the 2D pixel level. By ray sampling three-dimensional voxels, the rendered two-dimensional pixel semantics and depth information can be obtained. By explicitly integrating geometric occlusion relationships and semantic consistency constraints, this paper provides explicit guidance for the model and ensures compliance with these constraints. It is worth mentioning that UniOcc has the potential to reduce the need for expensive 3D semantic annotation. dependence. In the absence of 3D occupancy labels, models trained using only our volume rendering supervision perform even better than models trained using 3D label supervision. This highlights the exciting potential to reduce reliance on expensive 3D semantic annotations, as scene representations can be learned directly from affordable 2D segmentation labels. In addition, using advanced technologies such as SAM [6] and [14,19] can further reduce the cost of 2D segmentation annotation.
This article also introduces the Deep Sensing Teacher-Student (DTS) framework, a self-supervised training method. Unlike the classic Mean Teacher, DTS enhances the deep prediction of the teacher model, achieving stable and effective training while utilizing unlabeled data. Furthermore, this paper applies some simple yet effective techniques to improve the performance of the model. This includes using visible masks in training, using a stronger pre-trained backbone network, increasing voxel resolution, and implementing test-time data augmentation (TTA)
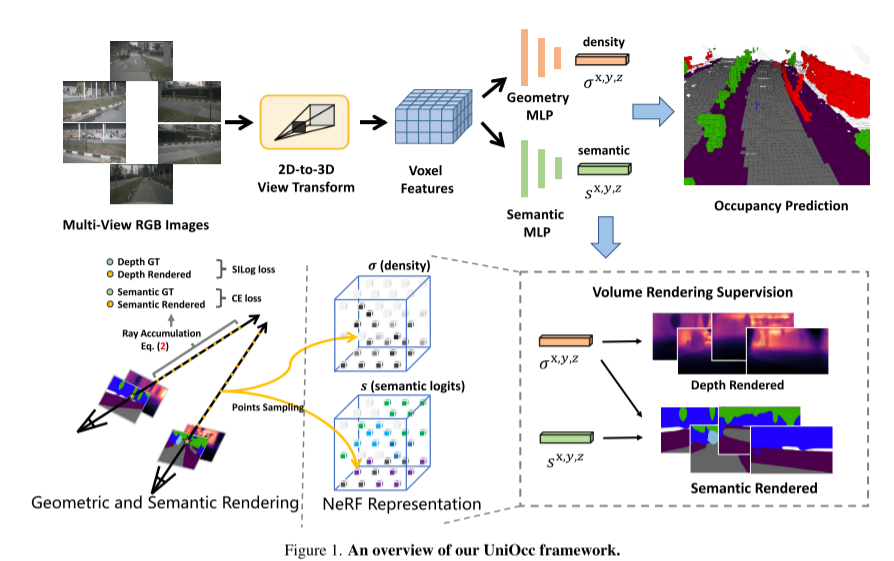 following Here is an overview of the UniOcc framework:
Figure 1
following Here is an overview of the UniOcc framework:
Figure 1
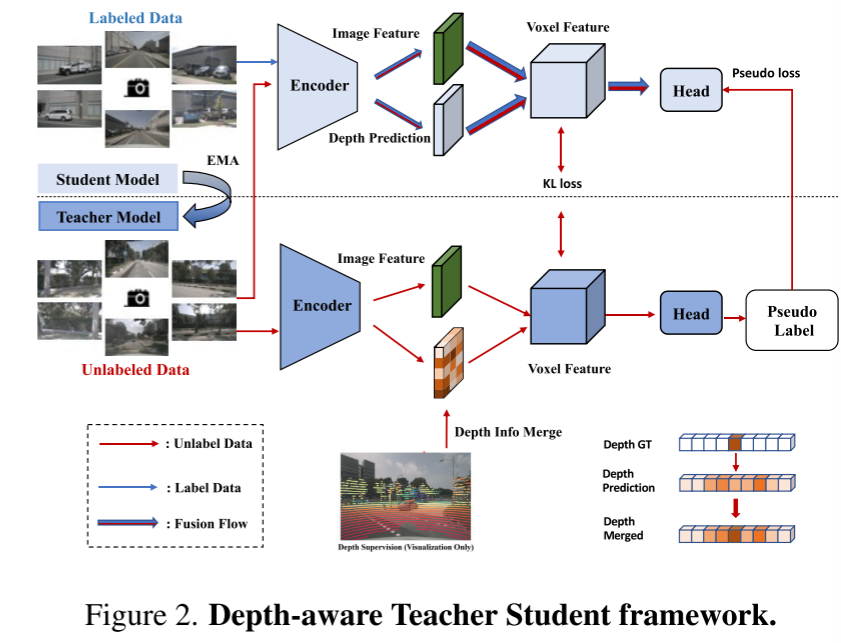 Figure 2. Depth-aware Teacher-Student framework.
Figure 2. Depth-aware Teacher-Student framework.
 #Quote:
#Quote:
Pan, M., Liu, L., Liu, J., Huang, P., Wang, L., Zhang, S., Xu, S., Lai, Z., Yang, K. (2023) . UniOcc: Unifying geometric and semantic rendering with vision-centric 3D occupancy prediction. ArXiv. / abs / 2306.09117
Original link: https://mp.weixin.qq.com/s/iLPHMtLzc5z0f4bg_W1vIg
The above is the detailed content of UniOcc: Unifying vision-centric occupancy prediction with geometric and semantic rendering!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1317
25
1268
29
1246
24
14
1423
52
1317
25
1268
29
1246
24

 Smart App Control on Windows 11: How to turn it on or off
Jun 06, 2023 pm 11:10 PM
Smart App Control on Windows 11: How to turn it on or off
Jun 06, 2023 pm 11:10 PM
Intelligent App Control is a very useful tool in Windows 11 that helps protect your PC from unauthorized apps that can damage your data, such as ransomware or spyware. This article explains what Smart App Control is, how it works, and how to turn it on or off in Windows 11. What is Smart App Control in Windows 11? Smart App Control (SAC) is a new security feature introduced in the Windows 1122H2 update. It works with Microsoft Defender or third-party antivirus software to block potentially unnecessary apps that can slow down your device, display unexpected ads, or perform other unexpected actions. Smart application
 Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Written previously, today we discuss how deep learning technology can improve the performance of vision-based SLAM (simultaneous localization and mapping) in complex environments. By combining deep feature extraction and depth matching methods, here we introduce a versatile hybrid visual SLAM system designed to improve adaptation in challenging scenarios such as low-light conditions, dynamic lighting, weakly textured areas, and severe jitter. sex. Our system supports multiple modes, including extended monocular, stereo, monocular-inertial, and stereo-inertial configurations. In addition, it also analyzes how to combine visual SLAM with deep learning methods to inspire other research. Through extensive experiments on public datasets and self-sampled data, we demonstrate the superiority of SL-SLAM in terms of positioning accuracy and tracking robustness.
 The facial features are flying around, opening the mouth, staring, and raising eyebrows, AI can imitate them perfectly, making it impossible to prevent video scams
Dec 14, 2023 pm 11:30 PM
The facial features are flying around, opening the mouth, staring, and raising eyebrows, AI can imitate them perfectly, making it impossible to prevent video scams
Dec 14, 2023 pm 11:30 PM
With such a powerful AI imitation ability, it is really impossible to prevent it. It is completely impossible to prevent it. Has the development of AI reached this level now? Your front foot makes your facial features fly, and on your back foot, the exact same expression is reproduced. Staring, raising eyebrows, pouting, no matter how exaggerated the expression is, it is all imitated perfectly. Increase the difficulty, raise the eyebrows higher, open the eyes wider, and even the mouth shape is crooked, and the virtual character avatar can perfectly reproduce the expression. When you adjust the parameters on the left, the virtual avatar on the right will also change its movements accordingly to give a close-up of the mouth and eyes. The imitation cannot be said to be exactly the same, but the expression is exactly the same (far right). The research comes from institutions such as the Technical University of Munich, which proposes GaussianAvatars, which
 What is NeRF? Is NeRF-based 3D reconstruction voxel-based?
Oct 16, 2023 am 11:33 AM
What is NeRF? Is NeRF-based 3D reconstruction voxel-based?
Oct 16, 2023 am 11:33 AM
1 Introduction Neural Radiation Fields (NeRF) are a fairly new paradigm in the field of deep learning and computer vision. This technology was introduced in the ECCV2020 paper "NeRF: Representing Scenes as Neural Radiation Fields for View Synthesis" (which won the Best Paper Award) and has since become extremely popular, with nearly 800 citations to date [1 ]. The approach marks a sea change in the traditional way machine learning processes 3D data. Neural radiation field scene representation and differentiable rendering process: composite images by sampling 5D coordinates (position and viewing direction) along camera rays; feed these positions into an MLP to produce color and volumetric densities; and composite these values using volumetric rendering techniques image; the rendering function is differentiable, so it can be passed
 MotionLM: Language modeling technology for multi-agent motion prediction
Oct 13, 2023 pm 12:09 PM
MotionLM: Language modeling technology for multi-agent motion prediction
Oct 13, 2023 pm 12:09 PM
This article is reprinted with permission from the Autonomous Driving Heart public account. Please contact the source for reprinting. Original title: MotionLM: Multi-Agent Motion Forecasting as Language Modeling Paper link: https://arxiv.org/pdf/2309.16534.pdf Author affiliation: Waymo Conference: ICCV2023 Paper idea: For autonomous vehicle safety planning, reliably predict the future behavior of road agents is crucial. This study represents continuous trajectories as sequences of discrete motion tokens and treats multi-agent motion prediction as a language modeling task. The model we propose, MotionLM, has the following advantages: First
 The first pure visual static reconstruction of autonomous driving
Jun 02, 2024 pm 03:24 PM
The first pure visual static reconstruction of autonomous driving
Jun 02, 2024 pm 03:24 PM
A purely visual annotation solution mainly uses vision plus some data from GPS, IMU and wheel speed sensors for dynamic annotation. Of course, for mass production scenarios, it doesn’t have to be pure vision. Some mass-produced vehicles will have sensors like solid-state radar (AT128). If we create a data closed loop from the perspective of mass production and use all these sensors, we can effectively solve the problem of labeling dynamic objects. But there is no solid-state radar in our plan. Therefore, we will introduce this most common mass production labeling solution. The core of a purely visual annotation solution lies in high-precision pose reconstruction. We use the pose reconstruction scheme of Structure from Motion (SFM) to ensure reconstruction accuracy. But pass
 What are the effective methods and common Base methods for pedestrian trajectory prediction? Top conference papers sharing!
Oct 17, 2023 am 11:13 AM
What are the effective methods and common Base methods for pedestrian trajectory prediction? Top conference papers sharing!
Oct 17, 2023 am 11:13 AM
Trajectory prediction has been gaining momentum in the past two years, but most of it focuses on the direction of vehicle trajectory prediction. Today, Autonomous Driving Heart will share with you the algorithm for pedestrian trajectory prediction on NeurIPS - SHENet. In restricted scenes, human movement patterns are usually To a certain extent, it conforms to limited rules. Based on this assumption, SHENet predicts a person's future trajectory by learning implicit scene rules. The article has been authorized to be original by Autonomous Driving Heart! The author's personal understanding is that currently predicting a person's future trajectory is still a challenging problem due to the randomness and subjectivity of human movement. However, human movement patterns in constrained scenes often vary due to scene constraints (such as floor plans, roads, and obstacles) and human-to-human or human-to-object interactivity.
 Point cloud registration is inescapable for 3D vision! Understand all mainstream solutions and challenges in one article
Apr 02, 2024 am 11:31 AM
Point cloud registration is inescapable for 3D vision! Understand all mainstream solutions and challenges in one article
Apr 02, 2024 am 11:31 AM
Point cloud, as a collection of points, is expected to bring about a change in acquiring and generating three-dimensional (3D) surface information of objects through 3D reconstruction, industrial inspection and robot operation. The most challenging but essential process is point cloud registration, i.e. obtaining a spatial transformation that aligns and matches two point clouds obtained in two different coordinates. This review introduces the overview and basic principles of point cloud registration, systematically classifies and compares various methods, and solves the technical problems existing in point cloud registration, trying to provide academic researchers outside the field and Engineers provide guidance and facilitate discussions on a unified vision for point cloud registration. The general method of point cloud acquisition is divided into active and passive methods. The point cloud actively acquired by the sensor is the active method, and the point cloud is reconstructed later.
