

A large model development toolset has been created!

The content that needs to be rewritten is: Author Richard MacManus
Planning | Yan Zheng
Web3 failed to subvert Web2, but the emerging large model development stack is allowing developers to start from the "cloud" The "native" era is moving towards a new AI technology stack.
Tip engineers may not be able to touch the nerves of developers to rush to large models, but a sentence from a product manager or leader: Can an "agent" be developed, can a "chain" be implemented, and "Which vector database to use?" , but it has become the difficulty for driving technology students in major mainstream large model application companies to overcome the development of generative AI.
What are the layers of the emerging technology stack? Where is the most difficult part? This article will lead you to find out
1. The technology stack needs to be updated. Developers are ushering in the era of AI engineers
In the past year, some tools have emerged, such as LangChain and LlamaIndex. This has allowed the developer ecosystem for AI applications to begin to mature. There is even a term now used to describe those who focus on the development of artificial intelligence, namely "AI engineer". According to Shawn @swyx Wang, this is the next step for "prompt engineers". He also created a coordinate chart to visualize where AI engineers fit into the broader artificial intelligence ecosystem
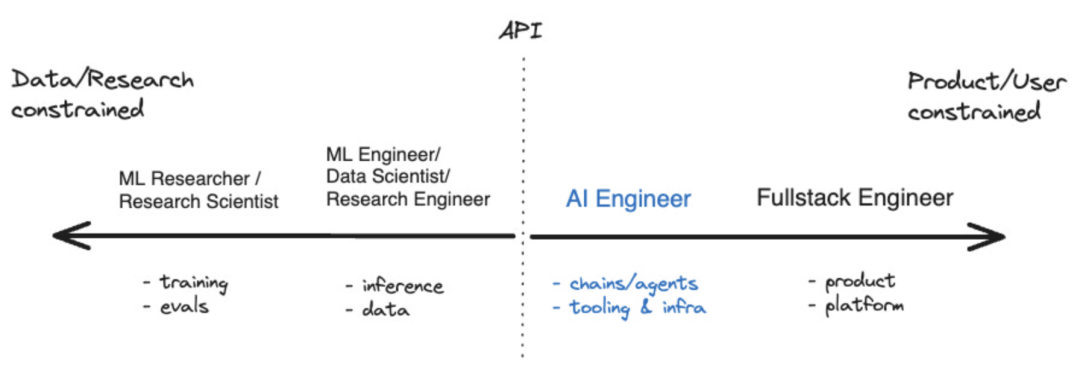 Source: swyx
Source: swyx
Large-scale language model (LLM) is the core technology of AI engineers. It is no coincidence that both LangChain and LlamaIndex are tools that extend and complement LLM. But what other tools are available for this new breed of developer?
So far, the best diagram I’ve seen of the LLM stack comes from venture capital firm Andreessen Horowitz (a16z). The following is its view on the "LLM app stack":
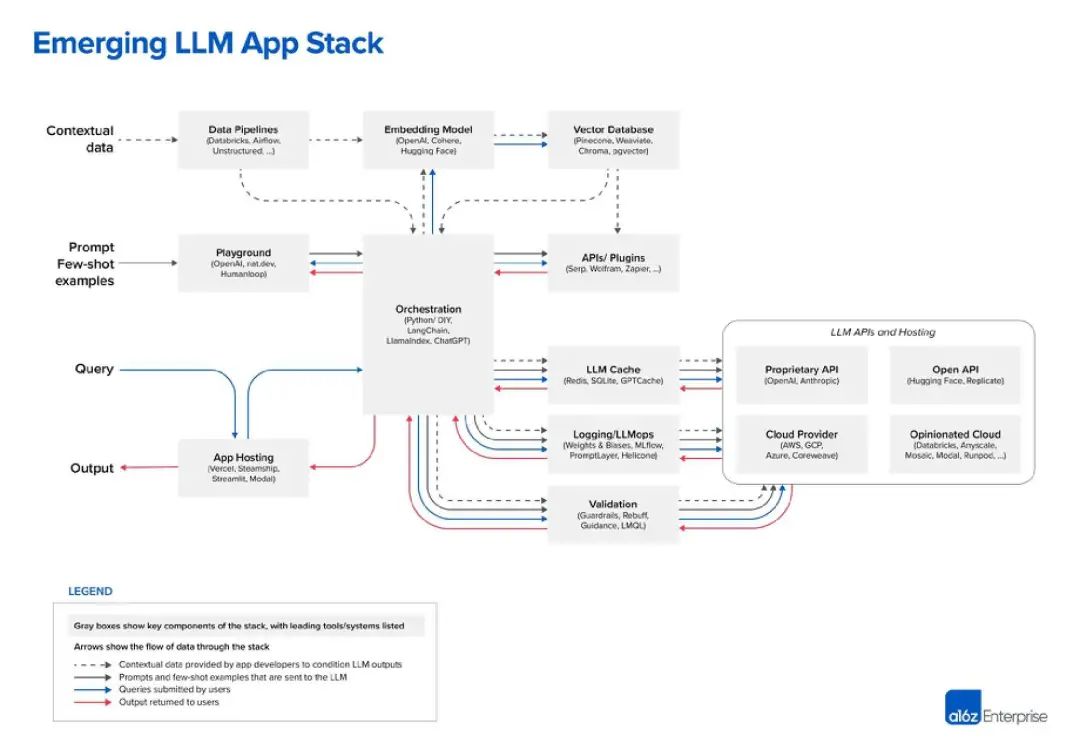 Source: a16z
Source: a16z
2. Yes, the top layer is still data
In the LLM technology stack, data is the most important component, this is very obvious. According to a16z's chart, the data is at the top. In LLM, "embedded model" is a very critical area, and you can choose from OpenAI, Cohere, Hugging Face, or dozens of other LLM options, including the increasingly popular open source LLM
Before using LLM, a "data pipeline" needs to be established. For example, consider Databricks and Airflow as two examples, or the data can be processed "unstructured". This also applies to the periodicity of data and can help companies "clean" or simply organize the data before entering it into a custom LLM. "Data intelligence" companies like Alation offer this type of service, which sounds a bit like tools such as "business intelligence" that are better known in the IT technology stack
The last part of the data layer is very popular these days A vector database for storing and processing LLM data. According to Microsoft's definition, this is a database that stores data as high-dimensional vectors, which are mathematical representations of features or attributes. Data is stored as vectors using embedding technology. In a media chat, leading vector database vendor Pinecone noted that their tools are often used with data pipeline tools such as Databricks. In this case, the data is typically stored elsewhere (such as a data lake) and then transformed into embedded data via a machine learning model. After processing and chunking, the resulting vectors are sent to Pinecone
3, Hints and Queries
The next two levels can be summarized as hints and queries - this is an artificial intelligence application The point of interaction where the program interfaces with LLM and (optionally) other data tools. A16z positions LangChain and LlamaIndex as "orchestration frameworks," meaning that once developers understand which LLM they are using, they can leverage these tools
According to a16z, orchestration like LangChain and LlamaIndex The framework "abstracts away many of the details of prompt linking," which means querying and managing data between the application and the LLM. This orchestration process includes interacting with external API interfaces, retrieving context data from the vector database, and maintaining memory across multiple LLM calls. The most interesting box in a16z’s diagram is “Playground,” which includes OpenAI, nat.dev, and Humanloop
A16z isn’t exactly defined in the blog post, but we can infer that the “Playground” tool can help The developers perform what A16z calls "cue jiu-jitsu." In these places, developers can experiment with various prompting techniques.
Humanloop is a British company whose platform features a “collaborative prompt workspace.” It further describes itself as a "complete development toolkit for production LLM functionality." So basically it allows you to try LLM stuff and then deploy it into your application if it works
4. Assembly line operations: LLMOps
At present, the layout of large-scale production lines is gradually becoming clear. On the right side of the orchestration box, there are many operation boxes, including LLM caching and verification. In addition, there are a series of LLM-related cloud services and API services, including open API repositories such as Hugging Face, and proprietary API providers such as OpenAI
This may be our first step in "cloud native" It’s no coincidence that many DevOps companies have added artificial intelligence to their product lists in the most similar place in the tech stack that developers are used to. In May, I spoke with Harness CEO Jyoti Bansal. Harness runs a "software delivery platform" that focuses on the "CD" part of the CI/CD process.
Bansai told me that AI can alleviate the tedious and repetitive tasks involved in the software delivery life cycle, from generating specifications based on existing functionality to writing code. Additionally, he said AI can automate code reviews, vulnerability testing, bug fixes, and even create CI/CD pipelines for builds and deployments. According to another conversation I had in May, AI is also changing developer productivity. Trisha Gee from the build automation tool Gradle told me that AI can speed up development by reducing time on repetitive tasks, like writing boilerplate code, and allowing developers to focus on the big picture, like making sure the code meets business needs.
5. Web3 is out, and the large model development stack is coming
In the emerging LLM development technology stack, we can observe a series of new product types, such as orchestration frameworks (such as LangChain and LlamaIndex), vector databases and "playground" platforms such as Humanloop. All of these products are extending and/or supplementing the core technologies of the current era: large language models, just like the rise of cloud-native era tools such as Spring Cloud and Kubernetes in previous years. However, at present, almost all large, small, and top companies in the cloud native era are trying their best to adapt their tools to AI engineering, which will be very beneficial to the future development of the LLM technology stack.
Yes, this time the big model seems to be "standing on the shoulders of giants." The best innovations in computer technology are always based on the past. Maybe that's why the "Web3" revolution failed - it wasn't so much building on the previous generation as trying to usurp it.
The LLM technology stack seems to have done it, and it has become a bridge from the cloud development era to a newer, artificial intelligence-based developer ecosystem
Reference link:
https:/ /www.php.cn/link/c589c3a8f99401b24b9380e86d939842The above is the detailed content of A large model development toolset has been created!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Big model app Tencent Yuanbao is online! Hunyuan is upgraded to create an all-round AI assistant that can be carried anywhere
Jun 09, 2024 pm 10:38 PM
Big model app Tencent Yuanbao is online! Hunyuan is upgraded to create an all-round AI assistant that can be carried anywhere
Jun 09, 2024 pm 10:38 PM
On May 30, Tencent announced a comprehensive upgrade of its Hunyuan model. The App "Tencent Yuanbao" based on the Hunyuan model was officially launched and can be downloaded from Apple and Android app stores. Compared with the Hunyuan applet version in the previous testing stage, Tencent Yuanbao provides core capabilities such as AI search, AI summary, and AI writing for work efficiency scenarios; for daily life scenarios, Yuanbao's gameplay is also richer and provides multiple features. AI application, and new gameplay methods such as creating personal agents are added. "Tencent does not strive to be the first to make large models." Liu Yuhong, vice president of Tencent Cloud and head of Tencent Hunyuan large model, said: "In the past year, we continued to promote the capabilities of Tencent Hunyuan large model. In the rich and massive Polish technology in business scenarios while gaining insights into users’ real needs
 Bytedance Beanbao large model released, Volcano Engine full-stack AI service helps enterprises intelligently transform
Jun 05, 2024 pm 07:59 PM
Bytedance Beanbao large model released, Volcano Engine full-stack AI service helps enterprises intelligently transform
Jun 05, 2024 pm 07:59 PM
Tan Dai, President of Volcano Engine, said that companies that want to implement large models well face three key challenges: model effectiveness, inference costs, and implementation difficulty: they must have good basic large models as support to solve complex problems, and they must also have low-cost inference. Services allow large models to be widely used, and more tools, platforms and applications are needed to help companies implement scenarios. ——Tan Dai, President of Huoshan Engine 01. The large bean bag model makes its debut and is heavily used. Polishing the model effect is the most critical challenge for the implementation of AI. Tan Dai pointed out that only through extensive use can a good model be polished. Currently, the Doubao model processes 120 billion tokens of text and generates 30 million images every day. In order to help enterprises implement large-scale model scenarios, the beanbao large-scale model independently developed by ByteDance will be launched through the volcano
 Advanced practice of industrial knowledge graph
Jun 13, 2024 am 11:59 AM
Advanced practice of industrial knowledge graph
Jun 13, 2024 am 11:59 AM
1. Background Introduction First, let’s introduce the development history of Yunwen Technology. Yunwen Technology Company...2023 is the period when large models are prevalent. Many companies believe that the importance of graphs has been greatly reduced after large models, and the preset information systems studied previously are no longer important. However, with the promotion of RAG and the prevalence of data governance, we have found that more efficient data governance and high-quality data are important prerequisites for improving the effectiveness of privatized large models. Therefore, more and more companies are beginning to pay attention to knowledge construction related content. This also promotes the construction and processing of knowledge to a higher level, where there are many techniques and methods that can be explored. It can be seen that the emergence of a new technology does not necessarily defeat all old technologies. It is also possible that the new technology and the old technology will be integrated with each other.
 Xiaomi Byte joins forces! A large model of Xiao Ai's access to Doubao: already installed on mobile phones and SU7
Jun 13, 2024 pm 05:11 PM
Xiaomi Byte joins forces! A large model of Xiao Ai's access to Doubao: already installed on mobile phones and SU7
Jun 13, 2024 pm 05:11 PM
According to news on June 13, according to Byte's "Volcano Engine" public account, Xiaomi's artificial intelligence assistant "Xiao Ai" has reached a cooperation with Volcano Engine. The two parties will achieve a more intelligent AI interactive experience based on the beanbao large model. It is reported that the large-scale beanbao model created by ByteDance can efficiently process up to 120 billion text tokens and generate 30 million pieces of content every day. Xiaomi used the beanbao large model to improve the learning and reasoning capabilities of its own model and create a new "Xiao Ai Classmate", which not only more accurately grasps user needs, but also provides faster response speed and more comprehensive content services. For example, when a user asks about a complex scientific concept, &ldq
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 AI hardware adds another member! Rather than replacing mobile phones, can NotePin last longer?
Sep 02, 2024 pm 01:40 PM
AI hardware adds another member! Rather than replacing mobile phones, can NotePin last longer?
Sep 02, 2024 pm 01:40 PM
So far, no product in the AI wearable device track has achieved particularly good results. AIPin, which was launched at MWC24 at the beginning of this year, once the evaluation prototype was shipped, the "AI myth" that was hyped at the time of its release began to be shattered, and it experienced large-scale returns in just a few months; RabbitR1, which also sold well at the beginning, was relatively It's better, but it also received negative reviews similar to "Android cases" when it was delivered in large quantities. Now, another company has entered the AI wearable device track. Technology media TheVerge published a blog post yesterday saying that AI startup Plaud has launched a product called NotePin. Unlike AIFriend, which is still in the "painting" stage, NotePin has now started
 How to evaluate the cost-effectiveness of commercial support for Java frameworks
Jun 05, 2024 pm 05:25 PM
How to evaluate the cost-effectiveness of commercial support for Java frameworks
Jun 05, 2024 pm 05:25 PM
Evaluating the cost/performance of commercial support for a Java framework involves the following steps: Determine the required level of assurance and service level agreement (SLA) guarantees. The experience and expertise of the research support team. Consider additional services such as upgrades, troubleshooting, and performance optimization. Weigh business support costs against risk mitigation and increased efficiency.
 How does the learning curve of PHP frameworks compare to other language frameworks?
Jun 06, 2024 pm 12:41 PM
How does the learning curve of PHP frameworks compare to other language frameworks?
Jun 06, 2024 pm 12:41 PM
The learning curve of a PHP framework depends on language proficiency, framework complexity, documentation quality, and community support. The learning curve of PHP frameworks is higher when compared to Python frameworks and lower when compared to Ruby frameworks. Compared to Java frameworks, PHP frameworks have a moderate learning curve but a shorter time to get started.
