

Listen to me, Transformer is a support vector machine

Transformer is a support vector machine (SVM), a new theory that has triggered discussions in the academic community.
Last weekend, a paper from the University of Pennsylvania and the University of California, Riverside attempted to study the principle of the Transformer structure based on large models. Its optimization geometry in the attention layer is related to the optimal Formal equivalence is established between hard-bound SVM problems where input tokens are separated from non-optimal tokens.
The author stated on hackernews that this theory solves the problem of SVM separating "good" tokens from "bad" tokens in each input sequence. As a token selector with excellent performance, this SVM is essentially different from the traditional SVM that assigns 0-1 labels to the input.
This theory also explains how attention induces sparsity through softmax: "bad" tokens that fall on the wrong side of the SVM decision boundary are suppressed by the softmax function, while "good" tokens fall on the wrong side of the SVM decision boundary. are those tokens that eventually have non-zero softmax probability. It is also worth mentioning that this SVM derives from the exponential properties of softmax.
After the paper was uploaded to arXiv, people expressed their opinions one after another. Some people said: The direction of AI research is really spiraling, is it going to go back again?
After going around in a circle, support vector machines are still not outdated.
Since the publication of the classic paper "Attention is All You Need", the Transformer architecture has brought revolutionary progress to the field of natural language processing (NLP). The attention layer in Transformer accepts a series of input tokens X and evaluates the correlation between tokens by calculating 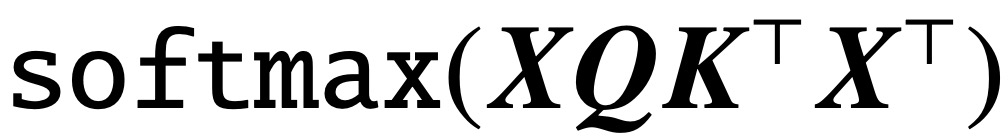 , where (K, Q) is a trainable key-query parameter, which is ultimately effective Capture remote dependencies.
, where (K, Q) is a trainable key-query parameter, which is ultimately effective Capture remote dependencies.
Now, a new paper called "Transformers as Support Vector Machines" establishes a formal equivalence between self-attentional optimization geometry and the hard-margin SVM problem. , using the outer product linear constraint of token pairs to separate optimal input tokens from non-optimal tokens.

Paper link: https://arxiv.org/pdf/2308.16898.pdf
This This formal equivalence is based on the paper "Max-Margin Token Selection in Attention Mechanism" by Davoud Ataee Tarzanagh et al., which can describe the implicit bias of a 1-layer transformer optimized through gradient descent:
(1) Optimize the attention layer parameterized by (K, Q), and converge to an SVM solution through vanishing regularization, which minimizes the combined parameters # The nuclear norm of 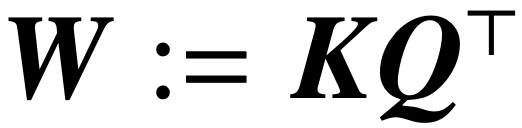 ##. In contrast, parameterizing directly via W minimizes the Frobenius norm SVM objective. The paper describes this convergence and emphasizes that it can occur in the direction of a local optimum rather than a global optimum.
##. In contrast, parameterizing directly via W minimizes the Frobenius norm SVM objective. The paper describes this convergence and emphasizes that it can occur in the direction of a local optimum rather than a global optimum.
(2) The paper also demonstrates the local/global directional convergence of W parameterization gradient descent under appropriate geometric conditions. Importantly, overparameterization catalyzes global convergence by ensuring the feasibility of the SVM problem and ensuring a benign optimization environment without stationary points.
(3) Although the theory of this study mainly applies to linear prediction heads, the research team proposed a more general SVM equivalent that can predict 1 with non-linear heads/MLP Implicit bias of layer transformer.
Overall, the results of this study are applicable to general data sets and can be extended to cross-attention layers, and the practical validity of the study conclusions has been obtained through thorough numerical experiments verify. This study establishes a new research perspective that views multi-layer transformers as SVM hierarchies that separate and select the best tokens.
Specifically, given an input sequence of length T and embedding dimension d 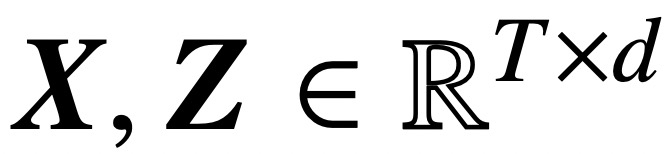 , this study analyzes core cross-attention and self-attention Model:
, this study analyzes core cross-attention and self-attention Model:

Among them, K, Q, and V are trainable key, query, and value matrices respectively, 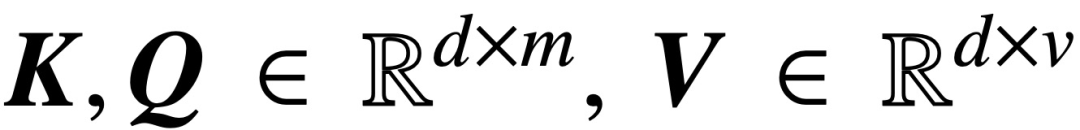 ; S (・) represents softmax nonlinearity, which is applied row by row. The study assumes that the first token of Z (denoted by z) is used for prediction. Specifically, given a training data set
; S (・) represents softmax nonlinearity, which is applied row by row. The study assumes that the first token of Z (denoted by z) is used for prediction. Specifically, given a training data set 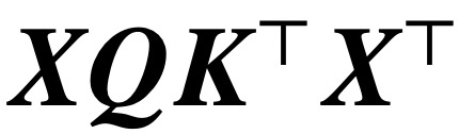 ,
, 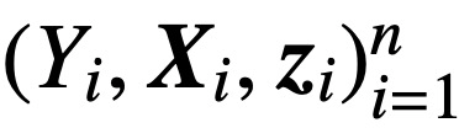 ,
, 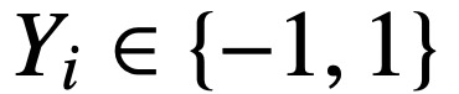 , the study uses a decreasing loss function
, the study uses a decreasing loss function 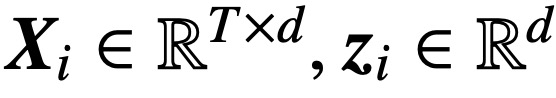 Minimize:
Minimize: 
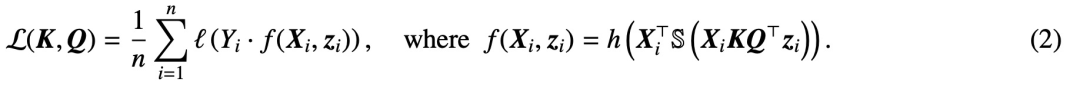 Here, h (・):
Here, h (・):
is the included value weight Predictive header for V. In this formulation, the model f (・) accurately represents a single-layer transformer where the attention layer is followed by an MLP. The author restores the self-attention in (2) by setting  , where x_i represents the first token of the sequence X_i. Due to the nonlinear nature of the softmax operation, it poses a huge challenge to optimization. Even if the prediction head is fixed and linear, the problem is non-convex and non-linear. In this study, the authors focus on optimizing attention weights (K, Q, or W) and overcoming these challenges to establish the basic equivalence of SVMs.
, where x_i represents the first token of the sequence X_i. Due to the nonlinear nature of the softmax operation, it poses a huge challenge to optimization. Even if the prediction head is fixed and linear, the problem is non-convex and non-linear. In this study, the authors focus on optimizing attention weights (K, Q, or W) and overcoming these challenges to establish the basic equivalence of SVMs. 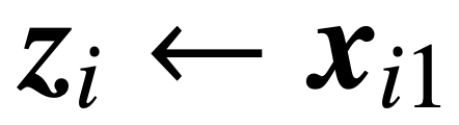 The structure of the paper is as follows: Chapter 2 introduces the preliminary knowledge of self-attention and optimization; Chapter 3 analyzes the optimization geometry of self-attention, showing that the attention parameter RP converges to the maximum Marginal solution; Chapters 4 and 5 introduce the global and local gradient descent analysis respectively, showing that the key-query variable W converges to the solution of (Att-SVM); Chapter 6 provides the solution on the nonlinear prediction head and generalized SVM Results in terms of equivalence; Chapter 7 extends the theory to sequential and causal predictions; Chapter 8 discusses related literature. Finally, Chapter 9 concludes by proposing open questions and future research directions.
The structure of the paper is as follows: Chapter 2 introduces the preliminary knowledge of self-attention and optimization; Chapter 3 analyzes the optimization geometry of self-attention, showing that the attention parameter RP converges to the maximum Marginal solution; Chapters 4 and 5 introduce the global and local gradient descent analysis respectively, showing that the key-query variable W converges to the solution of (Att-SVM); Chapter 6 provides the solution on the nonlinear prediction head and generalized SVM Results in terms of equivalence; Chapter 7 extends the theory to sequential and causal predictions; Chapter 8 discusses related literature. Finally, Chapter 9 concludes by proposing open questions and future research directions.
The main contents of the paper are as follows:
Implicit bias in the attention layer (Chapter 2-3)
Optimizing the attention parameters (K, Q) when regularization disappears will converge in the direction to the maximum marginal solution of
, whose kernel The norm target is the combined parameter  . In the case where the cross-attention is directly parameterized with the combined parameter W, the regularization path (RP) directionally converges to the (Att-SVM) solution targeting the Frobenius norm.
. In the case where the cross-attention is directly parameterized with the combined parameter W, the regularization path (RP) directionally converges to the (Att-SVM) solution targeting the Frobenius norm. 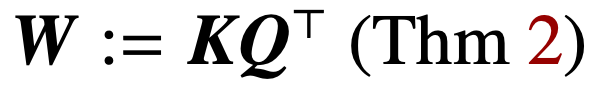 This is the first result to formally distinguish between W and (K, Q) parametric optimization dynamics, revealing low-order biases in the latter. The theory of this study clearly describes the optimality of selected tokens and naturally extends to sequence-to-sequence or causal classification settings.
This is the first result to formally distinguish between W and (K, Q) parametric optimization dynamics, revealing low-order biases in the latter. The theory of this study clearly describes the optimality of selected tokens and naturally extends to sequence-to-sequence or causal classification settings.
Convergence of Gradient Descent (Chapter 4-5)
With proper initialization and linear head h (・), the gradient descent (GD) iteration of the combined key-query variable W converges in the direction to the local optimal solution of (Att-SVM) (Section 5). To achieve a local optimum, the selected token must have a higher score than adjacent tokens.
The local optimal direction is not necessarily unique and can be determined based on the geometric characteristics of the problem [TLZO23]. As an important contribution, the authors identify geometric conditions that guarantee convergence toward the global optimum (Chapter 4). These conditions include:
- The best token has a significant difference in score;
- The initial gradient direction is consistent with the best token.
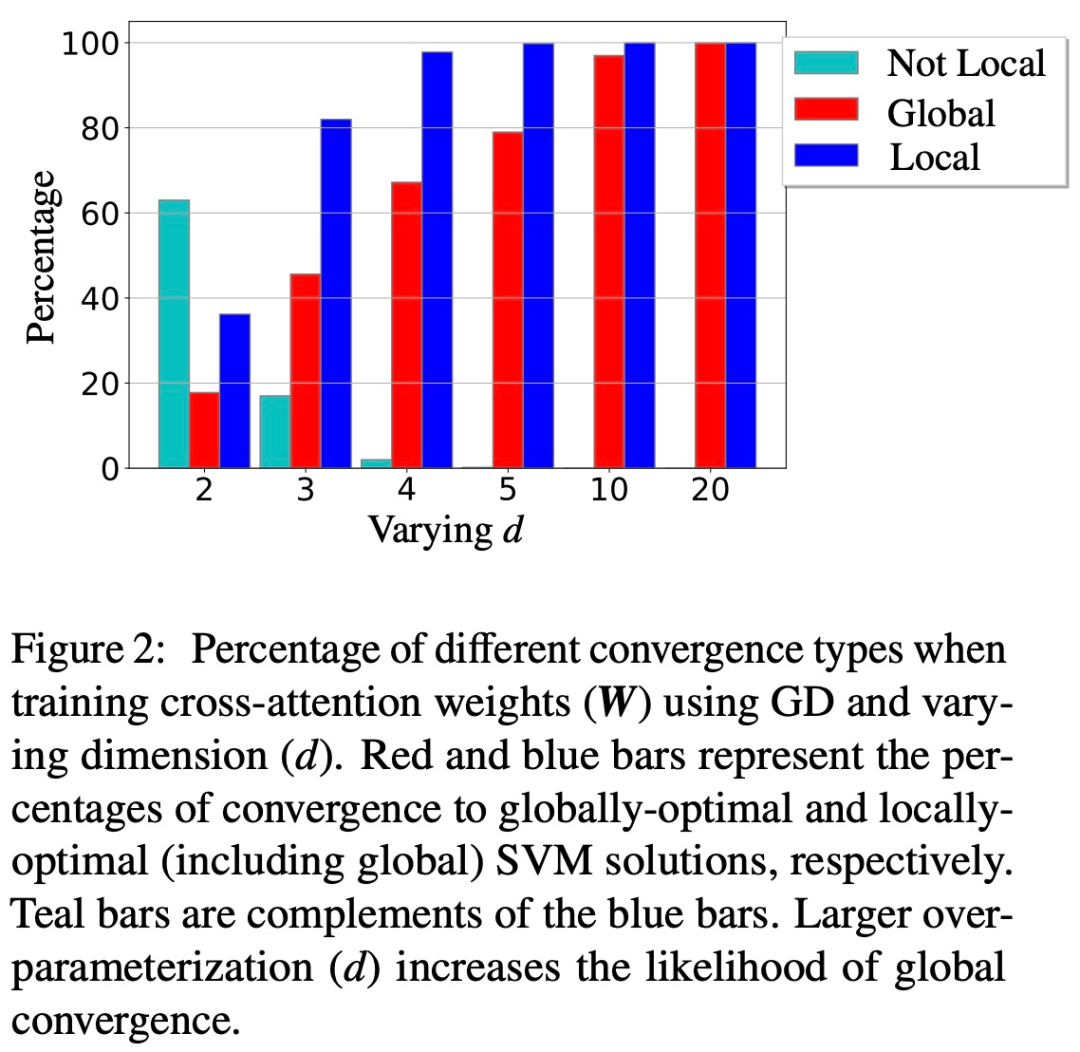
In addition, the paper also shows the feasibility of over-parameterization (ie, the dimension d is large, and the same conditions) by ensuring (1) (Att-SVM) , and (2) a benign optimization landscape (that is, there are no stationary points and false local optimal directions) to catalyze global convergence (see Section 5.2).
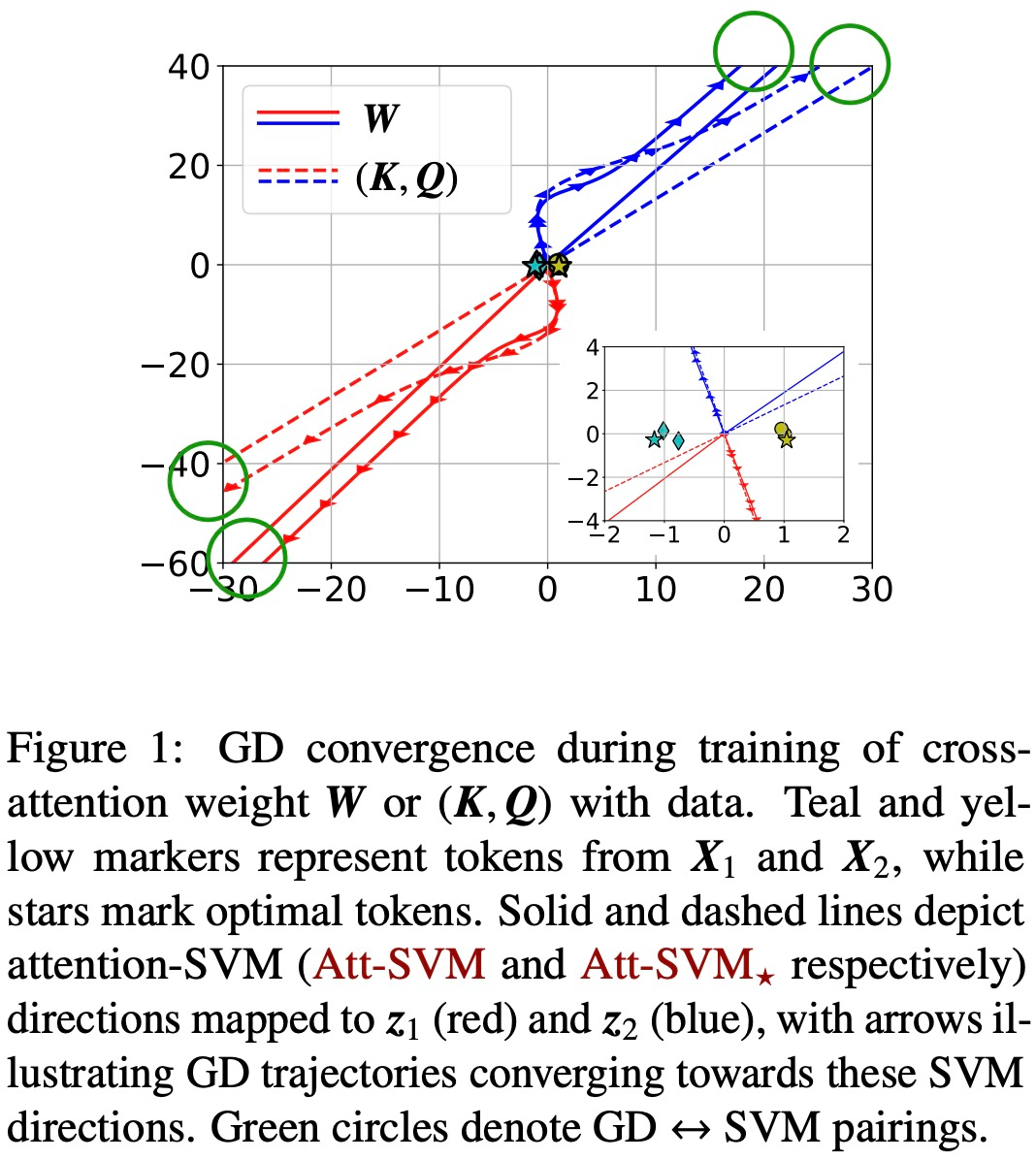
Figures 1 and 2 illustrate this.
#Generality of SVM equivalence (Chapter 6)
When optimizing with linear h (・), the attention layer is inherently biased from Select a token in each sequence (also known as hard attention). This is reflected in (Att-SVM), where the output token is a convex combination of the input tokens. In contrast, the authors show that nonlinear heads must be composed of multiple tokens, thus highlighting their importance in transformer dynamics (Section 6.1). Using insights gained from theory, the authors propose a more general SVM equivalent approach.
It is worth noting that they prove that in general cases not covered by the theory (for example, h (・) is an MLP), the method in this paper can accurately predict the gradient descent training Implicit biases in attention. Specifically, our general formula decouples the attention weight into two parts: a directional part controlled by SVM, which selects markers by applying a 0-1 mask; and a finite part, which adjusts the softmax Probability determines the precise composition of the selected token.
An important feature of these findings is that they apply to arbitrary data sets (as long as SVM is feasible) and can be verified numerically. The authors extensively experimentally verified the maximum marginal equivalence and implicit bias of the transformer. The authors believe that these findings contribute to the understanding of transformers as a hierarchical maximum-margin token selection mechanism and can lay the foundation for upcoming research on their optimization and generalization dynamics.
The above is the detailed content of Listen to me, Transformer is a support vector machine. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
