
 Technology peripherals
AI
ICCV 2023 Oral | How to conduct test segment training in the open world? Self-training method based on dynamic prototype expansion
Technology peripherals
AI
ICCV 2023 Oral | How to conduct test segment training in the open world? Self-training method based on dynamic prototype expansion
ICCV 2023 Oral | How to conduct test segment training in the open world? Self-training method based on dynamic prototype expansion

When promoting the implementation of vision-based perception methods, improving the generalization ability of the model is an important foundation. Test-Time Training/Adaptation (Test-Time Training/Adaptation) enables the model to adapt to the unknown target domain data distribution by adjusting the model parameter weights during the test phase. Existing TTT/TTA methods usually focus on improving the test segment training performance under target domain data in a closed environment. However, in many application scenarios, the target domain is easily affected by strong out-of-domain data (Strong OOD). ), such as semantically irrelevant data categories. In this case, also known as Open World Test Segment Training (OWTTT), existing TTT/TTA usually forcibly classify strong out-of-domain data into known categories, ultimately interfering with weak out-of-domain data (Weak OOD) such as Recognition ability of images disturbed by noise
Recently, South China University of Technology and the A*STAR team proposed the setting of open world test segment training for the first time, and launched corresponding training methods

- Paper: https://arxiv.org/abs/2308.09942
- The content that needs to be rewritten is: Code link: https: //github.com/Yushu-Li/OWTTT
- This article first proposes a strong out-of-domain data sample filtering method with adaptive threshold, which improves the performance of the self-training TTT method in the open world of robustness. The method further proposes a method to characterize strong out-of-domain samples based on dynamically extended prototypes to improve the weak/strong out-of-domain data separation effect. Finally, self-training is constrained by distribution alignment.
The method in this article achieves optimal performance on 5 different OWTTT benchmarks, and provides a new direction for subsequent research on TTT to explore more robust TTT methods. The research has been accepted as an Oral paper in ICCV 2023.
IntroductionTest segment training (TTT) can access target domain data only during the inference phase and perform on-the-fly inference on test data with distribution shifts. The success of TTT has been demonstrated on a number of artificially selected synthetically corrupted target domain data. However, the capability boundaries of existing TTT methods have not been fully explored.
To promote TTT applications in open scenarios, the focus of research has shifted to investigating scenarios where TTT methods may fail. Many efforts have been made to develop stable and robust TTT methods in more realistic open-world environments. In this work, we delve into a common but overlooked open-world scenario, where the target domain may contain test data distributions drawn from significantly different environments, such as different semantic categories than the source domain, or simply random noise.
We call the above test data strong out-of-distribution data (strong OOD). What is called weak OOD data in this work is test data with distribution shifts, such as common synthetic damage. Therefore, the lack of existing work on this real-life environment motivates us to explore improving the robustness of Open World Test Segment Training (OWTTT), where the test data is contaminated by strong OOD samples
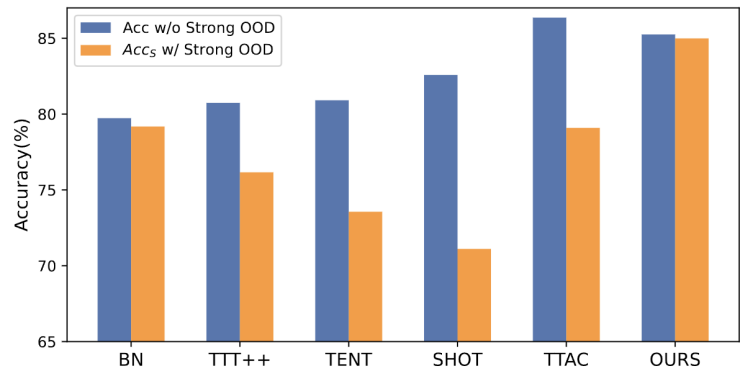
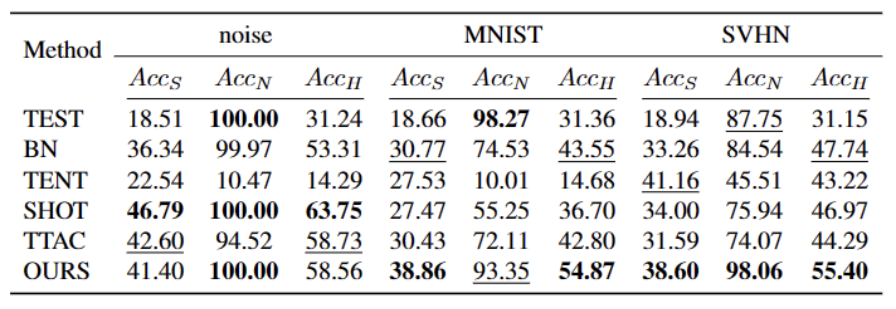
The content that needs to be rewritten is: Figure 1: The results of evaluating the existing TTT method under the OWTTT settingAccording to Figure 1 As shown, we first evaluated the existing TTT methods under the OWTTT setting and found that TTT methods through self-training and distribution alignment will be affected by strong OOD samples. These results indicate that safe test training cannot be achieved by applying existing TTT technology in the open world. We attribute their failure to the following two reasons
- Self-training-based TTT has difficulty handling strong OOD samples because it must assign test samples to known classes. Although some low-confidence samples can be filtered out by applying the threshold employed in semi-supervised learning, there is still no guarantee that all strong OOD samples will be filtered out.
- Methods based on distribution alignment will be affected when strong OOD samples are calculated to estimate the target domain distribution. Both global distribution alignment [1] and class distribution alignment [2] can be affected and lead to inaccurate feature distribution alignment.
- In order to improve the robustness of open-world TTT under the self-training framework, we considered the potential reasons for the failure of existing TTT methods and proposed a solution combining the two technologies
First, we will establish the baseline of TTT on the self-trained variant, that is, clustering in the target domain using the source domain prototype as the cluster center. In order to mitigate the impact of strong OOD on self-training by false pseudo-labels, we propose a hyperparameter-free method to reject strong OOD samples
To further separate the characteristics of weak OOD samples and strong OOD samples, we allow prototypes The pool is expanded by selecting isolated strong OOD samples. Therefore, self-training will allow strong OOD samples to form tight clusters around the newly expanded strong OOD prototype. This will facilitate distribution alignment between source and target domains. We further propose to regularize self-training through global distribution alignment to reduce the risk of confirmation bias
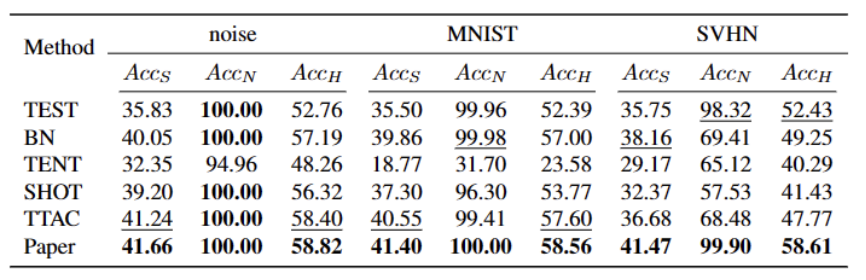
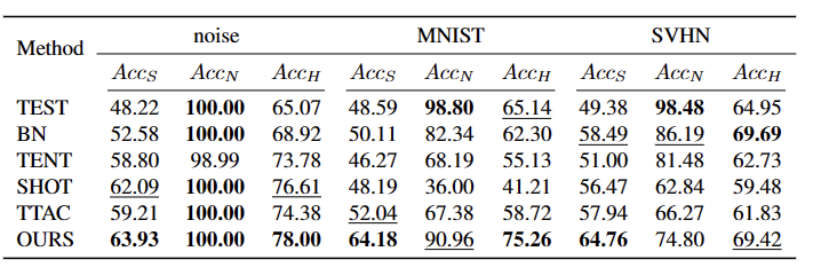
Finally, in order to synthesize the open-world TTT scenario, we use CIFAR10-C, CIFAR100-C, ImageNet-C, VisDA-C, ImageNet-R, Tiny-ImageNet, MNIST and SVHN data sets, and use a data The set is weak OOD, and the others are strong OOD to establish a benchmark data set. We refer to this benchmark as the Open World Test Segment Training Benchmark and hope that this encourages more future work to focus on the robustness of test segment training in more realistic scenarios.
Method
The paper is divided into four parts to introduce the proposed method.
1) Overview of the settings of the training tasks in the test section under the open world.
2) Introduces how to usePrototype clustering is an unsupervised learning algorithm used to cluster samples in a data set into different categories. In prototype clustering, each category is represented by one or more prototypes, which can be samples in the data set or generated according to some rules. The goal of prototype clustering is to achieve clustering by minimizing the distance between samples and the prototypes of the categories to which they belong. Common prototype clustering algorithms include K-means clustering and Gaussian mixture models. These algorithms are widely used in fields such as data mining, pattern recognition, and image processing Implementing TTT and how to extend the prototype for open-world test-time training.
3) Introduces how to use target domain data toThe content that needs to be rewritten is: dynamic prototype extension.
4) IntroducingDistribution Alignment and Prototype Clustering is an unsupervised learning algorithm used to cluster samples in a data set into different categories. In prototype clustering, each category is represented by one or more prototypes, which can be samples in the data set or generated according to some rules. The goal of prototype clustering is to achieve clustering by minimizing the distance between samples and the prototypes of the categories to which they belong. Common prototype clustering algorithms include K-means clustering and Gaussian mixture models. These algorithms, widely used in fields such as data mining, pattern recognition, and image processing, are combined to enable powerful open-world test-time training.
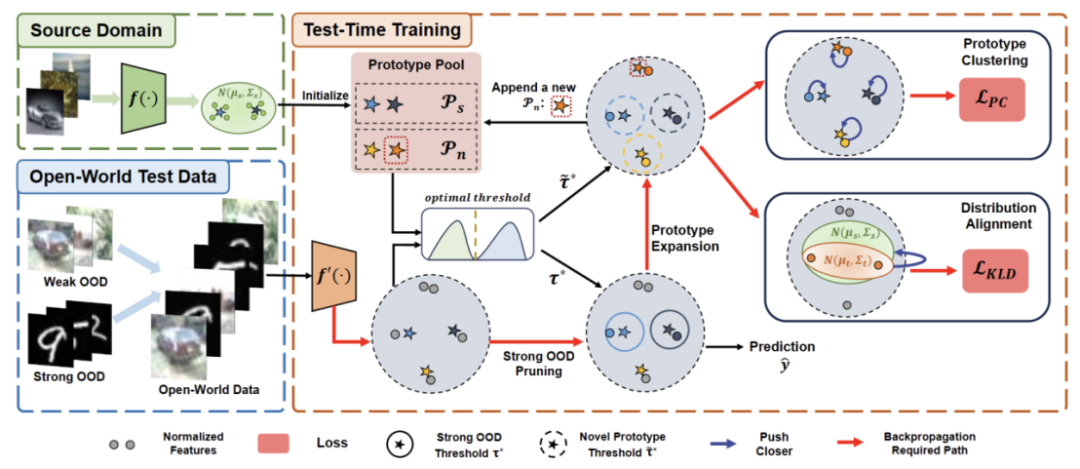
The content that needs to be rewritten is: Figure 2: Method Overview Diagram
Task The goal of setting
TTT is to adapt the source domain pre-trained model to the target domain, where there may be a distribution shift in the target domain relative to the source domain. In standard closed-world TTT, the label spaces of the source and target domains are the same. However, in open-world TTT, the label space of the target domain contains the target space of the source domain, which means that the target domain has unseen new semantic categoriesIn order to avoid confusion between TTT definitions, we adopt The sequential test time training (sTTT) protocol proposed in TTAC [2] is evaluated. Under the sTTT protocol, test samples are tested sequentially, and model updates are performed after observing small batches of test samples. The prediction for any test sample arriving at timestamp t is not affected by any test sample arriving at t k (whose k is greater than 0).Prototype clustering is an unsupervised learning algorithm used to cluster samples in a data set into different categories. In prototype clustering, each category is represented by one or more prototypes, which can be samples in the data set or generated according to some rules. The goal of prototype clustering is to achieve clustering by minimizing the distance between samples and the prototypes of the categories to which they belong. Common prototype clustering algorithms include K-means clustering and Gaussian mixture models. These algorithms are widely used in fields such as data mining, pattern recognition, and image processing
Inspired by the work using clustering in domain adaptation tasks [3,4], we treat test segment training as discovery Cluster structure in target domain data. By identifying representative prototypes as cluster centers, cluster structures are identified in the target domain and test samples are encouraged to embed near one of the prototypes. Prototype clustering is an unsupervised learning algorithm used to cluster samples in a data set into different categories. In prototype clustering, each category is represented by one or more prototypes, which can be samples in the data set or generated according to some rules. The goal of prototype clustering is to achieve clustering by minimizing the distance between samples and the prototypes of the categories to which they belong. Common prototype clustering algorithms include K-means clustering and Gaussian mixture models. The goal of these algorithms, which are widely used in fields such as data mining, pattern recognition, and image processing, is defined as minimizing the negative log-likelihood loss of the cosine similarity between a sample and the cluster center, as shown in the following equation.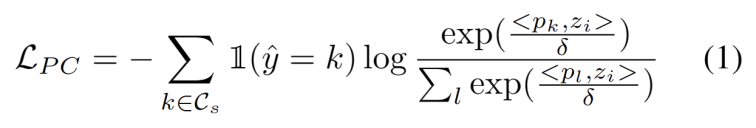
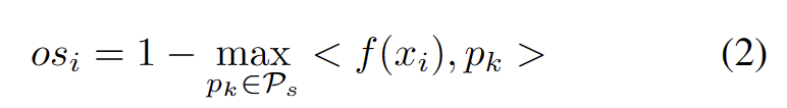
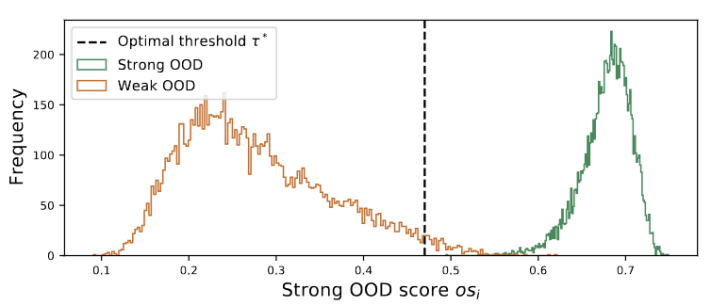
# The outliers obey a bimodal distribution, as shown in Figure 3. Therefore, instead of specifying a fixed threshold, we define the optimal threshold as the best value that separates the two distributions. Specifically, the problem can be formulated as dividing the outliers into two clusters, and the optimal threshold will minimize the within-cluster variance in . Optimizing the following equation can be efficiently achieved by exhaustively searching all possible thresholds from 0 to 1 in steps of 0.01.
The content that needs to be rewritten is: dynamic prototype extension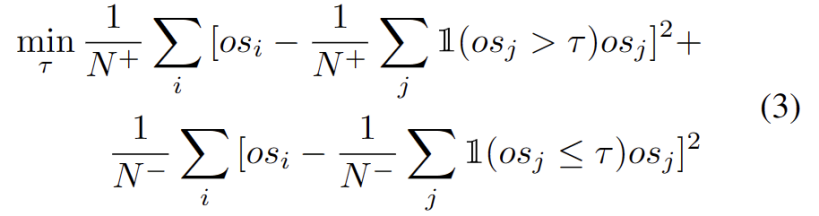
To alleviate the difficulty of estimating additional hyperparameters, we first define a test sample with an extended strong OOD score as the closest distance to the existing source domain prototype and the strong OOD prototype, as follows. Therefore, testing samples above this threshold will build a new prototype. To avoid adding nearby test samples, we incrementally repeat this prototype expansion process.
With other strong OOD prototypes identified, we define prototypes for test samples. Clustering is an unsupervised learning algorithm for classifying samples in a dataset. clustered into different categories. In prototype clustering, each category is represented by one or more prototypes, which can be samples in the data set or generated according to some rules. The goal of prototype clustering is to achieve clustering by minimizing the distance between samples and the prototypes of the categories to which they belong. Common prototype clustering algorithms include K-means clustering and Gaussian mixture models. These algorithms are widely used in fields such as data mining, pattern recognition, and image processing. Loss takes two factors into consideration. First, test samples classified into known classes should be embedded closer to prototypes and farther away from other prototypes, which defines the K-class classification task. Second, test samples classified as strong OOD prototypes should be far away from any source domain prototypes, which defines the K 1 class classification task. With these goals in mind, we prototype clustering, an unsupervised learning algorithm used to cluster samples in a dataset into distinct categories. In prototype clustering, each category is represented by one or more prototypes, which can be samples in the data set or generated according to some rules. The goal of prototype clustering is to achieve clustering by minimizing the distance between samples and the prototypes of the categories to which they belong. Common prototype clustering algorithms include K-means clustering and Gaussian mixture models. These algorithms are widely used in fields such as data mining, pattern recognition, and image processing. The loss is defined as the following formula.
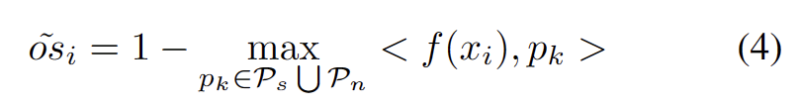
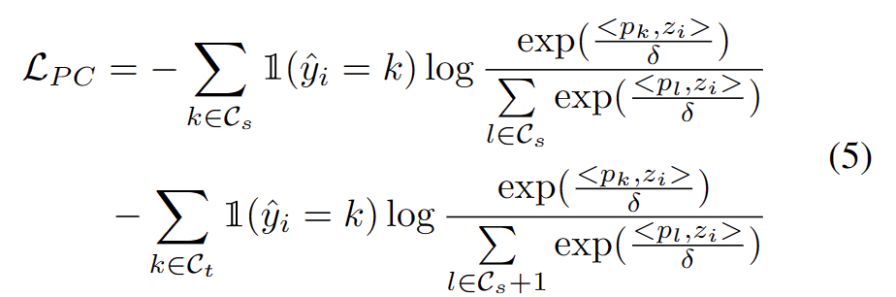
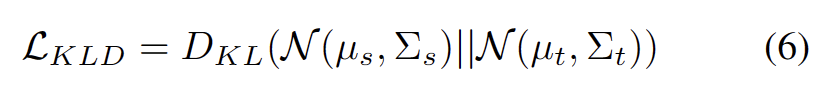


References:
[1] Yuejiang Liu, Parth Kothari, Bastien van Delft, Baptiste Bellot-Gurlet, Taylor Mordan, and Alexandre Alahi. Ttt : When does self-supervised test-time training fail or thrive? In Advances in Neural Information Processing Systems, 2021.
[2] Yongyi Su, Xun Xu, and Kui Jia. Revisiting realistic test-time training: Sequential inference and adaptation by anchored clustering. In Advances in Neural Information Processing Systems, 2022.
[3] Tang Hui and Jia Kui. Discriminative adversarial domain adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 5940-5947, 2020
[4] Kuniaki Saito, Shohei Yamamoto, Yoshitaka Ushiku, and Tatsuya Harada. Open set domain adaptation by backpropagation. In European Conference on Computer Vision, 2018.
[5] Brian Kulis and Michael I Jordan. k-means revisited: a new algorithm via Bayesian nonparametric methods. In International Conference on Machine Learning, 2012
The above is the detailed content of ICCV 2023 Oral | How to conduct test segment training in the open world? Self-training method based on dynamic prototype expansion. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1382
1382
 52
52

 A Diffusion Model Tutorial Worth Your Time, from Purdue University
Apr 07, 2024 am 09:01 AM
A Diffusion Model Tutorial Worth Your Time, from Purdue University
Apr 07, 2024 am 09:01 AM
Diffusion can not only imitate better, but also "create". The diffusion model (DiffusionModel) is an image generation model. Compared with the well-known algorithms such as GAN and VAE in the field of AI, the diffusion model takes a different approach. Its main idea is a process of first adding noise to the image and then gradually denoising it. How to denoise and restore the original image is the core part of the algorithm. The final algorithm is able to generate an image from a random noisy image. In recent years, the phenomenal growth of generative AI has enabled many exciting applications in text-to-image generation, video generation, and more. The basic principle behind these generative tools is the concept of diffusion, a special sampling mechanism that overcomes the limitations of previous methods.
 Generate PPT with one click! Kimi: Let the 'PPT migrant workers' become popular first
Aug 01, 2024 pm 03:28 PM
Generate PPT with one click! Kimi: Let the 'PPT migrant workers' become popular first
Aug 01, 2024 pm 03:28 PM
Kimi: In just one sentence, in just ten seconds, a PPT will be ready. PPT is so annoying! To hold a meeting, you need to have a PPT; to write a weekly report, you need to have a PPT; to make an investment, you need to show a PPT; even when you accuse someone of cheating, you have to send a PPT. College is more like studying a PPT major. You watch PPT in class and do PPT after class. Perhaps, when Dennis Austin invented PPT 37 years ago, he did not expect that one day PPT would become so widespread. Talking about our hard experience of making PPT brings tears to our eyes. "It took three months to make a PPT of more than 20 pages, and I revised it dozens of times. I felt like vomiting when I saw the PPT." "At my peak, I did five PPTs a day, and even my breathing was PPT." If you have an impromptu meeting, you should do it
 All CVPR 2024 awards announced! Nearly 10,000 people attended the conference offline, and a Chinese researcher from Google won the best paper award
Jun 20, 2024 pm 05:43 PM
All CVPR 2024 awards announced! Nearly 10,000 people attended the conference offline, and a Chinese researcher from Google won the best paper award
Jun 20, 2024 pm 05:43 PM
In the early morning of June 20th, Beijing time, CVPR2024, the top international computer vision conference held in Seattle, officially announced the best paper and other awards. This year, a total of 10 papers won awards, including 2 best papers and 2 best student papers. In addition, there were 2 best paper nominations and 4 best student paper nominations. The top conference in the field of computer vision (CV) is CVPR, which attracts a large number of research institutions and universities every year. According to statistics, a total of 11,532 papers were submitted this year, and 2,719 were accepted, with an acceptance rate of 23.6%. According to Georgia Institute of Technology’s statistical analysis of CVPR2024 data, from the perspective of research topics, the largest number of papers is image and video synthesis and generation (Imageandvideosyn
 From bare metal to a large model with 70 billion parameters, here is a tutorial and ready-to-use scripts
Jul 24, 2024 pm 08:13 PM
From bare metal to a large model with 70 billion parameters, here is a tutorial and ready-to-use scripts
Jul 24, 2024 pm 08:13 PM
We know that LLM is trained on large-scale computer clusters using massive data. This site has introduced many methods and technologies used to assist and improve the LLM training process. Today, what we want to share is an article that goes deep into the underlying technology and introduces how to turn a bunch of "bare metals" without even an operating system into a computer cluster for training LLM. This article comes from Imbue, an AI startup that strives to achieve general intelligence by understanding how machines think. Of course, turning a bunch of "bare metal" without an operating system into a computer cluster for training LLM is not an easy process, full of exploration and trial and error, but Imbue finally successfully trained an LLM with 70 billion parameters. and in the process accumulate
 Five programming software for getting started with learning C language
Feb 19, 2024 pm 04:51 PM
Five programming software for getting started with learning C language
Feb 19, 2024 pm 04:51 PM
As a widely used programming language, C language is one of the basic languages that must be learned for those who want to engage in computer programming. However, for beginners, learning a new programming language can be difficult, especially due to the lack of relevant learning tools and teaching materials. In this article, I will introduce five programming software to help beginners get started with C language and help you get started quickly. The first programming software was Code::Blocks. Code::Blocks is a free, open source integrated development environment (IDE) for
 PyCharm Community Edition Installation Guide: Quickly master all the steps
Jan 27, 2024 am 09:10 AM
PyCharm Community Edition Installation Guide: Quickly master all the steps
Jan 27, 2024 am 09:10 AM
Quick Start with PyCharm Community Edition: Detailed Installation Tutorial Full Analysis Introduction: PyCharm is a powerful Python integrated development environment (IDE) that provides a comprehensive set of tools to help developers write Python code more efficiently. This article will introduce in detail how to install PyCharm Community Edition and provide specific code examples to help beginners get started quickly. Step 1: Download and install PyCharm Community Edition To use PyCharm, you first need to download it from its official website
 AI in use | AI created a life vlog of a girl living alone, which received tens of thousands of likes in 3 days
Aug 07, 2024 pm 10:53 PM
AI in use | AI created a life vlog of a girl living alone, which received tens of thousands of likes in 3 days
Aug 07, 2024 pm 10:53 PM
Editor of the Machine Power Report: Yang Wen The wave of artificial intelligence represented by large models and AIGC has been quietly changing the way we live and work, but most people still don’t know how to use it. Therefore, we have launched the "AI in Use" column to introduce in detail how to use AI through intuitive, interesting and concise artificial intelligence use cases and stimulate everyone's thinking. We also welcome readers to submit innovative, hands-on use cases. Video link: https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ Recently, the life vlog of a girl living alone became popular on Xiaohongshu. An illustration-style animation, coupled with a few healing words, can be easily picked up in just a few days.
 A must-read for technical beginners: Analysis of the difficulty levels of C language and Python
Mar 22, 2024 am 10:21 AM
A must-read for technical beginners: Analysis of the difficulty levels of C language and Python
Mar 22, 2024 am 10:21 AM
Title: A must-read for technical beginners: Difficulty analysis of C language and Python, requiring specific code examples In today's digital age, programming technology has become an increasingly important ability. Whether you want to work in fields such as software development, data analysis, artificial intelligence, or just learn programming out of interest, choosing a suitable programming language is the first step. Among many programming languages, C language and Python are two widely used programming languages, each with its own characteristics. This article will analyze the difficulty levels of C language and Python
