
 Technology peripherals
AI
Meta plans to release a new open source version of the GPT-4 level large model next year. Its number of parameters will be several times that of Llama 2. Users can use it for free commercially.
Technology peripherals
AI
Meta plans to release a new open source version of the GPT-4 level large model next year. Its number of parameters will be several times that of Llama 2. Users can use it for free commercially.
Meta plans to release a new open source version of the GPT-4 level large model next year. Its number of parameters will be several times that of Llama 2. Users can use it for free commercially.

According to the foreign media "Wall Street Journal", Meta is stepping up the development of a new large language model. Its capabilities will be fully aligned with GPT-4 and is expected to be launched next year.

The news also specifically emphasized that Meta’s new large language model will be several times larger than Llama 2, and there is a high probability that it will be open source and free. Commercial.
Since Meta "accidentally" leaked LlaMA at the beginning of the year, to the open source release of Llama 2 in July, Meta has gradually found its unique position in this AI wave—— The flag of the AI open source community.

The personnel are constantly changing, and the model’s capabilities are flawed. We can only rely on open source software to solve the problem
At the beginning of the year, at OpenAI After detonating the technology industry with GPT-4, Google and Microsoft have also launched their own AI products.
In May, U.S. regulators invited CEOs of leading companies that they considered relevant to the AI industry at the time to hold a roundtable meeting to discuss the development of AI technology.
OpenAI, Google and Microsoft were invited to participate, and even the startup Anthropic, but Meta was a no-show. At that time, the official response to the reason for Meta's absence was: "We only invited the top companies in the AI industry."

Good things did not happen to Meta. But trouble kept coming.
Xiao Zha received a letter of inquiry from Congress in early June, asking him to explain in detail the cause and impact of the LlaMA leak in March. The letter was sternly worded and the requirements were very clear

. In the following months, even after the release of Llama 2, Meta spent The AI team built with a lot of money is still gradually falling apart.
In the acknowledgments of Llama 2, the four team members who first initiated this research were mentioned, three of whom have resigned, and currently only Edouard Grave is still working at Meta Company
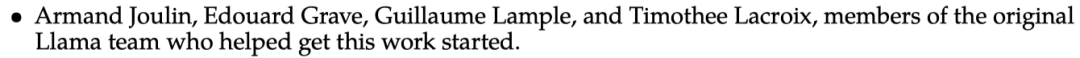
Industry Big BullHe Kaiming will also leave Meta and return to academia.

#According to a recent breaking article by The Information, Meta’s AI team has been experiencing constant friction due to competition for internal computing power, and personnel have been leaving one after another.
In this context, Xiao Zha himself should also know very well that Meta’s own large language model is indeed unable to compete with the industry’s most cutting-edge GPT-4.
Whether it is viewed from all directions of benchmark testing or user feedback, the gap between Llama 2 and GPT-4 is still huge
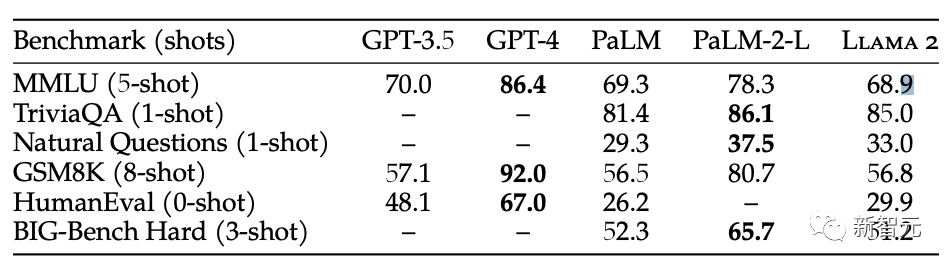
In various benchmark tests, there is a considerable gap between the open source Llama 2 and GPT-4

GPT-4 still shows a clear lead over Llama 2 in the actual experience of netizens
Therefore, Xiao Zha decided to let Meta continue to run wildly on the road of model open source
Perhaps Xiao Zha’s thinking behind it is this: Meta model has average capabilities and cannot There’s no point in continuing to keep things secret in competition with the big guys who are closed source. Therefore, let’s simply open source and let the AI community continue to iterate based on their own models to expand the influence of their products in the industry
Xiao Zha has publicly stated many times that the open source community is very important to them. The model iterations played an inspiring role, allowing their technical team to develop more competitive products in the future

Xiao Zha in Fridman’s The podcast emphasized that open source allows Meta to draw inspiration from the community, and that Meta may launch a closed-source model in the future.
See: https://lexfridman.com/mark-zuckerberg-2/
And facts have proven that Meta’s choice is indeed is correct.
Although it is not as good as Google and OpenAI in terms of computing resources and technical strength, open source models such as Meta’s Llama 2 are still second to none in their appeal to the open source community. As Llama 2 slowly becomes the "technical base" of the AI open source community, Meta has also found its own ecological niche in the industry.
The most obvious sign is that in the closed-door meeting of Congress on AI that will be held in September, Xiao Zha finally became a guest of the regulators, working with Google, OpenAI and other industries CEOs of the most cutting-edge companies will act as representatives to express their voices on the regulation of the AI industry.
If the new model launched by Meta next year can continue to make progress and gain the same capabilities as GPT-4, on the one hand, it will enable the open source community Continuing to close the gap with closed source giants has confirmed the statement that "the gap between the open source community and the most advanced level in the industry is about one year."
On the other hand, Xiao Zha also revealed in the interview that if the capabilities of large models are further improved in the future, Meta may launch its own closed-source model. If the new model can further approach the industry SOTA, it may not be far from Meta launching its own closed-source model.
Although Meta seems to be temporarily lagging behind in this AI wave, Xiao Zha is not satisfied with being just a follower
In Yann Under the guidance of Lecun, Meta is also preparing to subvert the entire industry
Meta’s future
So, after this mysterious large model that is legendary to be comparable to GPT-4, Meta What will the future of AI look like?
Because there is no specific information yet, we can only make some guesses, such as starting from the attitude of Meta AI chief scientist LeCun.
The popular GPT has always been the artificial intelligence development route that LeCun criticized and despised.
On February 4 of this year, LeCun bluntly expressed his opinion that large language models are the wrong path on the road to human-level AI

He believes that this large model that generates autoregression based on probability will not survive for at most 5 years, because these artificial intelligences are only trained on a large amount of text, and they cannot Understand the real world.
These models can neither plan nor reason. They only have the ability to learn context.
Seriously speaking, these models are The artificial intelligence trained on LLM has almost no "intelligence" at all.
What LeCun is looking forward to is a "world model" that can lead to AGI.
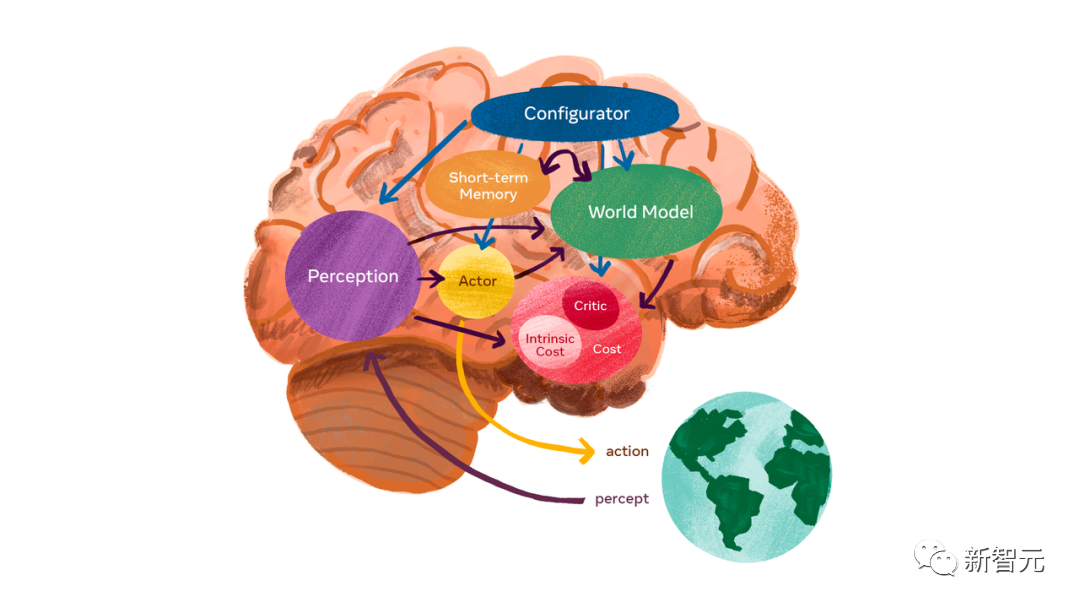
World model can learn how the world works, learn more quickly, plan for completing complex tasks, and respond to unfamiliar new situations at any time Condition.
This is different from LLM that requires a lot of pre-training. The world model can find patterns from observation, adapt to new environments, and master new skills like humans.
Meta strives for diversified model development, compared with OpenAI’s strategy of continuous improvement and deepening in the LLM field
On June 14 this year, Meta has released I-JEPA, a "human-like" artificial intelligence model, which is also the first AI model in history based on key parts of LeCun's world model vision.

Please click the following link to view the paper: https://arxiv.org/abs/2301.08243
I-JEPA is able to understand abstract representations in images and acquire common sense through self-supervised learning
I-JEPA does not require additional artificial knowledge as an aid
Subsequently, Meta launched Voicebox, a new and innovative speech generation system based on a new method proposed by Meta AI - flow matching

It can synthesize speech in six languages, perform operations such as denoising, editing content, and converting audio styles.
Meta also released a universal embodied AI agent
With Language Guided Skills Coordination (LSC), the robot can operate on pre-mapped Free movement and picking up of items in certain environments
In the development of multi-modal models, Meta is unique
ImageBind, first An artificial intelligence model capable of binding information from six different modalities.
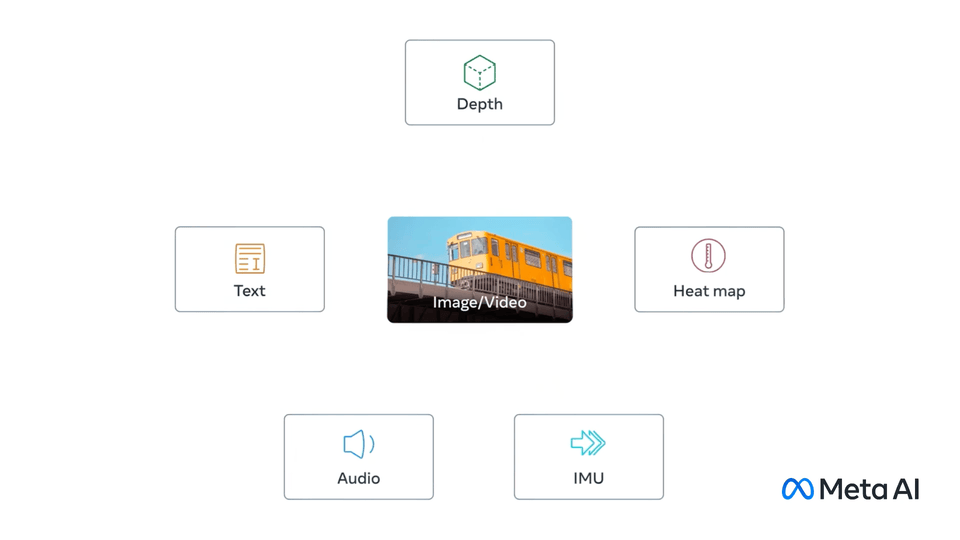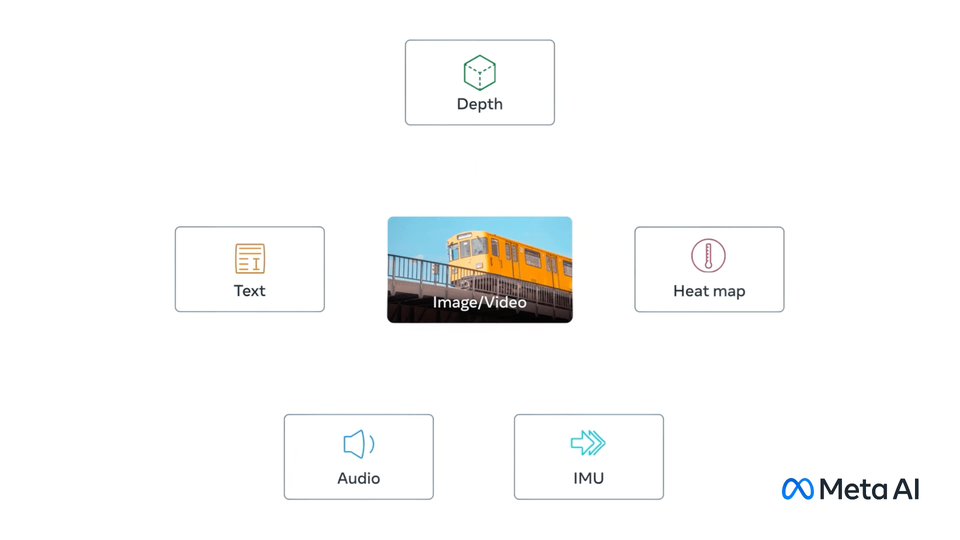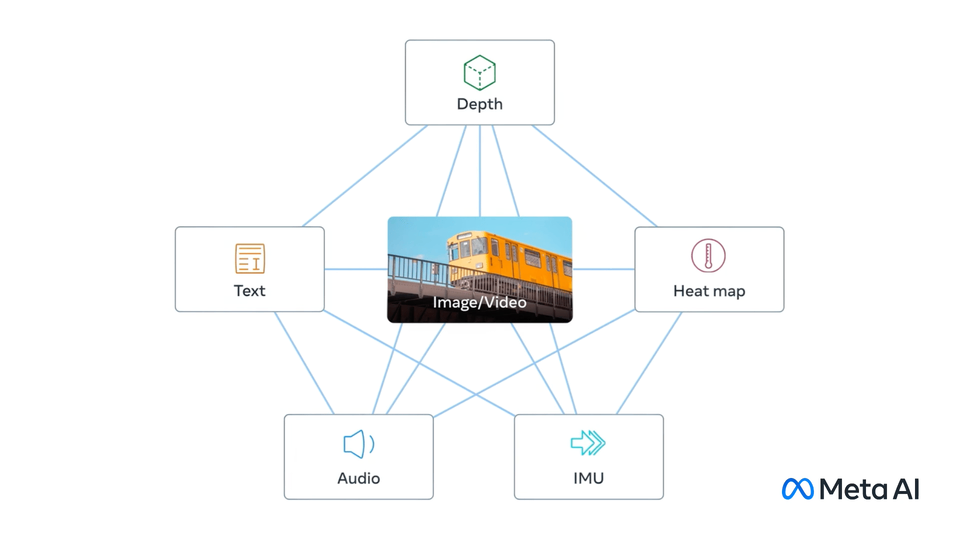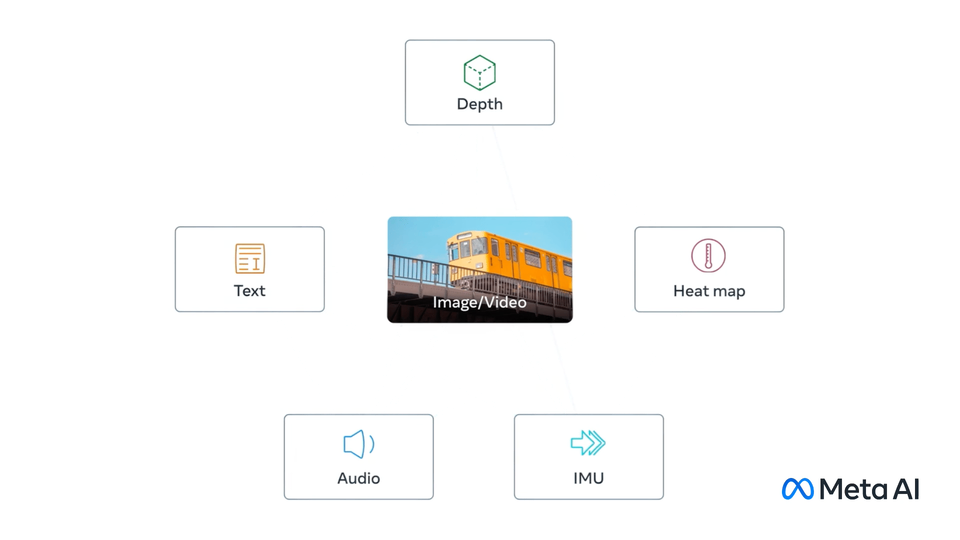
It has comprehensive machine understanding capabilities and can connect the objects in the photo to their sounds, three-dimensional shapes, temperatures and movement patterns
The RoboAgent jointly developed by Meta AI and CMU_Robotics allows robots to acquire a variety of non-trivial skills and promote them to hundreds of life scenarios.
The data for all these scenarios is an order of magnitude smaller than previous work in the field

Regarding the model that was revealed this time, some netizens expressed the hope that they will continue to open source code.
However, some netizens said that Meta will not start training until early 2024

But what is gratifying is that Meta still released a signal that it will continue to adhere to its original strategy.
The above is the detailed content of Meta plans to release a new open source version of the GPT-4 level large model next year. Its number of parameters will be several times that of Llama 2. Users can use it for free commercially.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to solve the complexity of WordPress installation and update using Composer
Apr 17, 2025 pm 10:54 PM
How to solve the complexity of WordPress installation and update using Composer
Apr 17, 2025 pm 10:54 PM
When managing WordPress websites, you often encounter complex operations such as installation, update, and multi-site conversion. These operations are not only time-consuming, but also prone to errors, causing the website to be paralyzed. Combining the WP-CLI core command with Composer can greatly simplify these tasks, improve efficiency and reliability. This article will introduce how to use Composer to solve these problems and improve the convenience of WordPress management.
 How to solve SQL parsing problem? Use greenlion/php-sql-parser!
Apr 17, 2025 pm 09:15 PM
How to solve SQL parsing problem? Use greenlion/php-sql-parser!
Apr 17, 2025 pm 09:15 PM
When developing a project that requires parsing SQL statements, I encountered a tricky problem: how to efficiently parse MySQL's SQL statements and extract the key information. After trying many methods, I found that the greenlion/php-sql-parser library can perfectly solve my needs.
 How to solve complex BelongsToThrough relationship problem in Laravel? Use Composer!
Apr 17, 2025 pm 09:54 PM
How to solve complex BelongsToThrough relationship problem in Laravel? Use Composer!
Apr 17, 2025 pm 09:54 PM
In Laravel development, dealing with complex model relationships has always been a challenge, especially when it comes to multi-level BelongsToThrough relationships. Recently, I encountered this problem in a project dealing with a multi-level model relationship, where traditional HasManyThrough relationships fail to meet the needs, resulting in data queries becoming complex and inefficient. After some exploration, I found the library staudenmeir/belongs-to-through, which easily installed and solved my troubles through Composer.
 Solve CSS prefix problem using Composer: Practice of padaliyajay/php-autoprefixer library
Apr 17, 2025 pm 11:27 PM
Solve CSS prefix problem using Composer: Practice of padaliyajay/php-autoprefixer library
Apr 17, 2025 pm 11:27 PM
I'm having a tricky problem when developing a front-end project: I need to manually add a browser prefix to the CSS properties to ensure compatibility. This is not only time consuming, but also error-prone. After some exploration, I discovered the padaliyajay/php-autoprefixer library, which easily solved my troubles with Composer.
 How to solve the problem of PHP project code coverage reporting? Using php-coveralls is OK!
Apr 17, 2025 pm 08:03 PM
How to solve the problem of PHP project code coverage reporting? Using php-coveralls is OK!
Apr 17, 2025 pm 08:03 PM
When developing PHP projects, ensuring code coverage is an important part of ensuring code quality. However, when I was using TravisCI for continuous integration, I encountered a problem: the test coverage report was not uploaded to the Coveralls platform, resulting in the inability to monitor and improve code coverage. After some exploration, I found the tool php-coveralls, which not only solved my problem, but also greatly simplified the configuration process.
 How to solve the complex problem of PHP geodata processing? Use Composer and GeoPHP!
Apr 17, 2025 pm 08:30 PM
How to solve the complex problem of PHP geodata processing? Use Composer and GeoPHP!
Apr 17, 2025 pm 08:30 PM
When developing a Geographic Information System (GIS), I encountered a difficult problem: how to efficiently handle various geographic data formats such as WKT, WKB, GeoJSON, etc. in PHP. I've tried multiple methods, but none of them can effectively solve the conversion and operational issues between these formats. Finally, I found the GeoPHP library, which easily integrates through Composer, and it completely solved my troubles.
 git software installation tutorial
Apr 17, 2025 pm 12:06 PM
git software installation tutorial
Apr 17, 2025 pm 12:06 PM
Git Software Installation Guide: Visit the official Git website to download the installer for Windows, MacOS, or Linux. Run the installer and follow the prompts. Configure Git: Set username, email, and select a text editor. For Windows users, configure the Git Bash environment.
 The latest tutorial on how to read the key of git software
Apr 17, 2025 pm 12:12 PM
The latest tutorial on how to read the key of git software
Apr 17, 2025 pm 12:12 PM
This article will explain in detail how to view keys in Git software. It is crucial to master this because Git keys are secure credentials for authentication and secure transfer of code. The article will guide readers step by step how to display and manage their Git keys, including SSH and GPG keys, using different commands and options. By following the steps in this guide, users can easily ensure their Git repository is secure and collaboratively smoothly with others.
