
 Technology peripherals
AI
Several papers were selected for Interspeech 2023, and Huoshan Speech effectively solved many types of practical problems
Technology peripherals
AI
Several papers were selected for Interspeech 2023, and Huoshan Speech effectively solved many types of practical problems
Several papers were selected for Interspeech 2023, and Huoshan Speech effectively solved many types of practical problems

Recently, several papers from the Volcano Voice Team were selected for Interspeech 2023, covering short video speech recognition, cross-language timbre and style, and oral fluency assessment, etc. Innovative breakthroughs in application direction. Interspeech is one of the top conferences in the field of speech research organized by the International Speech Communications Association ISCA. It is also known as the world's largest comprehensive speech signal processing event and has received widespread attention from people in the global language field.

Interspeech2023Event site
Data enhancement based on random sentence concatenation to improve short video speech Recognition (Random Utterance Concatenation Based Data Augmentation for Improving Short-video Speech Recognition)
Generally speaking, end-to-end automatic speech recognition (ASR) One of the limitations of the framework is that its performance may suffer if the lengths of training and test statements do not match. In this paper, the Huoshan Speech team proposes a data enhancement method based on instant random sentence concatenation (RUC) as front-end data enhancement to alleviate the problem of training and test sentence length mismatch in short video ASR tasks.
Specifically, the team found that the following observations played a major role in innovative practice: Typically, the training sentences of short video spontaneous speech are much shorter than the human-transcribed sentences (an average of about 3 seconds), while the test sentences generated from the voice activity detection frontend were much longer (about 10 seconds on average). Therefore, this mismatch may lead to poor performance
The Volcano Speech team stated that for the purpose of empirical work, we used multi-class ASR models from 15 languages. Datasets for these languages range from 1,000 to 30,000 hours. During the model fine-tuning phase, we also added data that was sampled and spliced from multiple pieces of data in real time. Compared with the unenhanced data, this method achieves an average relative word error rate reduction of 5.72% across all languages.
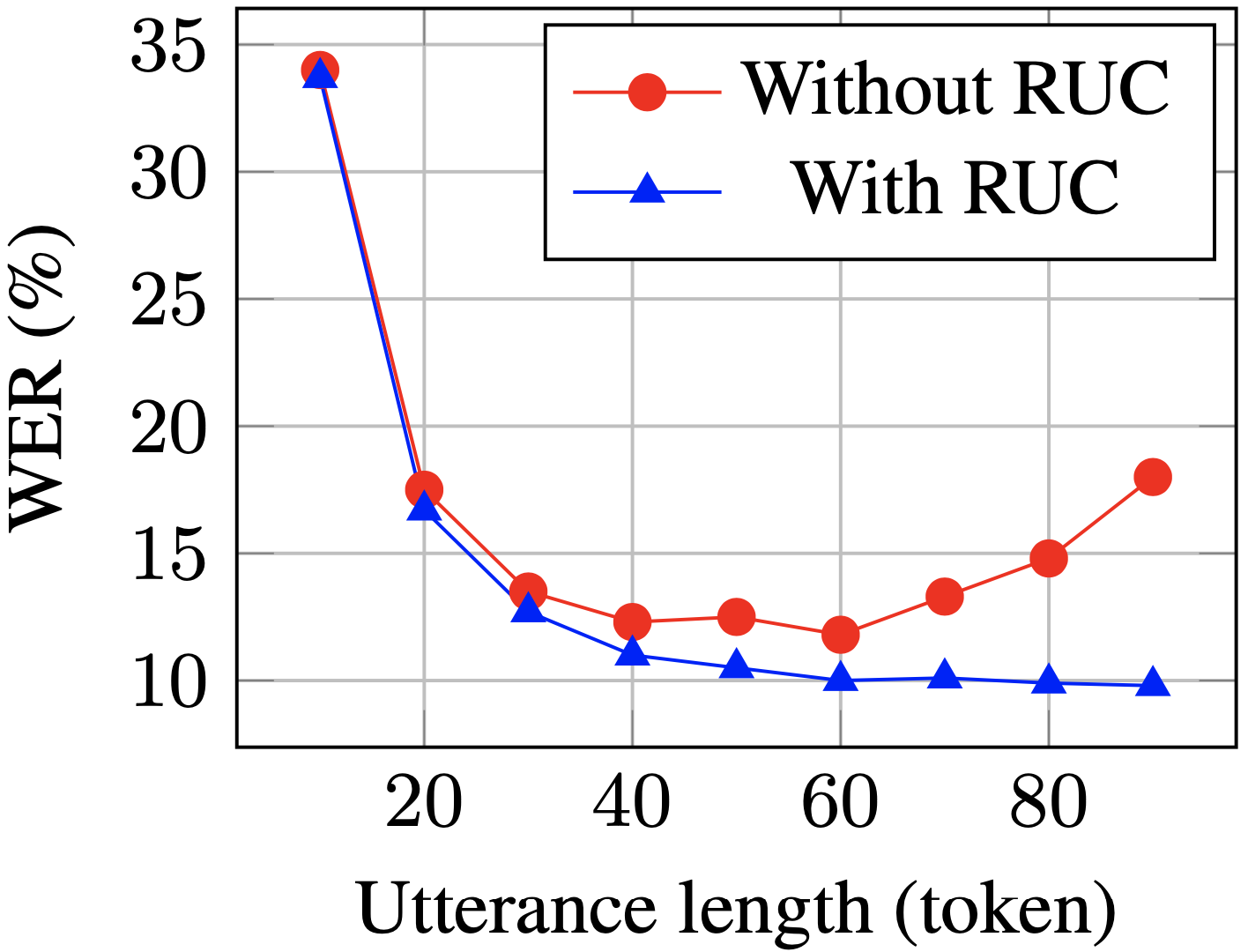
WER for long sentences on the test set passes RUC dropped significantly after training (blue vs. red)
According to experimental observations, the RUC method significantly improved the recognition ability of long sentences, while the performance of short sentences did not decrease. Further analysis found that the proposed data augmentation method can reduce the sensitivity of the ASR model to length normalization changes, which may mean that the ASR model is more robust in diverse environments. To sum up, although the RUC data enhancement method is simple to operate, the effect is significant
Fluency scoring based on phonetic and prosody-aware self-supervision methods(Phonetic and Prosody-aware Self- Supervised Learning Approach for Non-native Fluency Scoring)
One of the important dimensions for evaluating second language learners’ language ability is oral fluency. Fluent pronunciation is mainly characterized by the ability to produce speech easily and normally without many abnormal phenomena such as pauses, hesitations or self-corrections when speaking. Most second language learners typically speak slower and pause more frequently than native speakers. In order to evaluate spoken fluency, the Volcano Speech team proposed a self-supervised modeling method based on speech and prosody correlation
Specifically, in the pre-training stage, the model’s input sequence features (acoustic features, acoustic features, Phoneme id, phoneme duration) are masked, and the masked features are sent to the model. The context-related encoder is used to restore the phoneme id and phoneme duration information of the masked part based on the timing information, so that the model has more powerful speech and Prosodic representation ability. This solution masks and reconstructs the three features of original duration, phoneme and acoustic information in the sequence modeling framework, allowing the machine to automatically learn the speech and duration representation of the context, which is better used for fluency scoring.
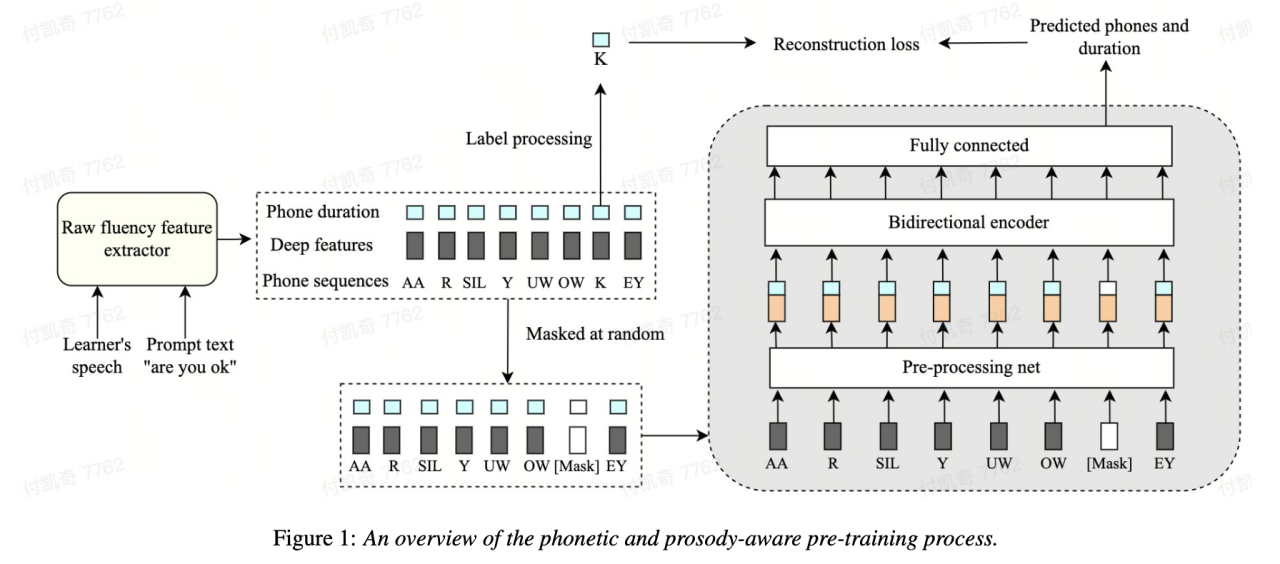
#This self-supervised learning method based on speech and prosody outperforms other methods in the field, predicting machine results and human experts on in-house test sets The correlation between scores reached 0.833, which is the same as the correlation between experts and experts. 0.831. On the open source data set, the correlation between machine prediction results and human expert scores reached 0.835, and the performance exceeded some self-supervised methods proposed in the past on this task. In terms of application scenarios, this method can be applied to scenarios that require automatic fluency assessment, such as oral exams and various online oral exercises.
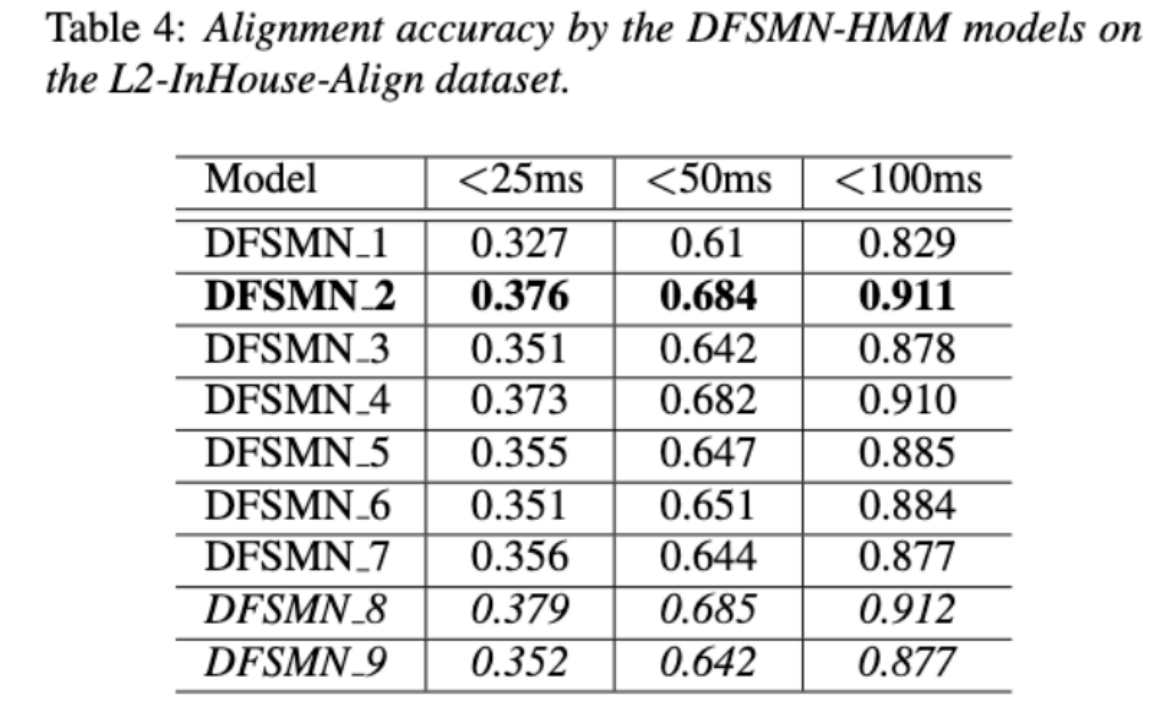
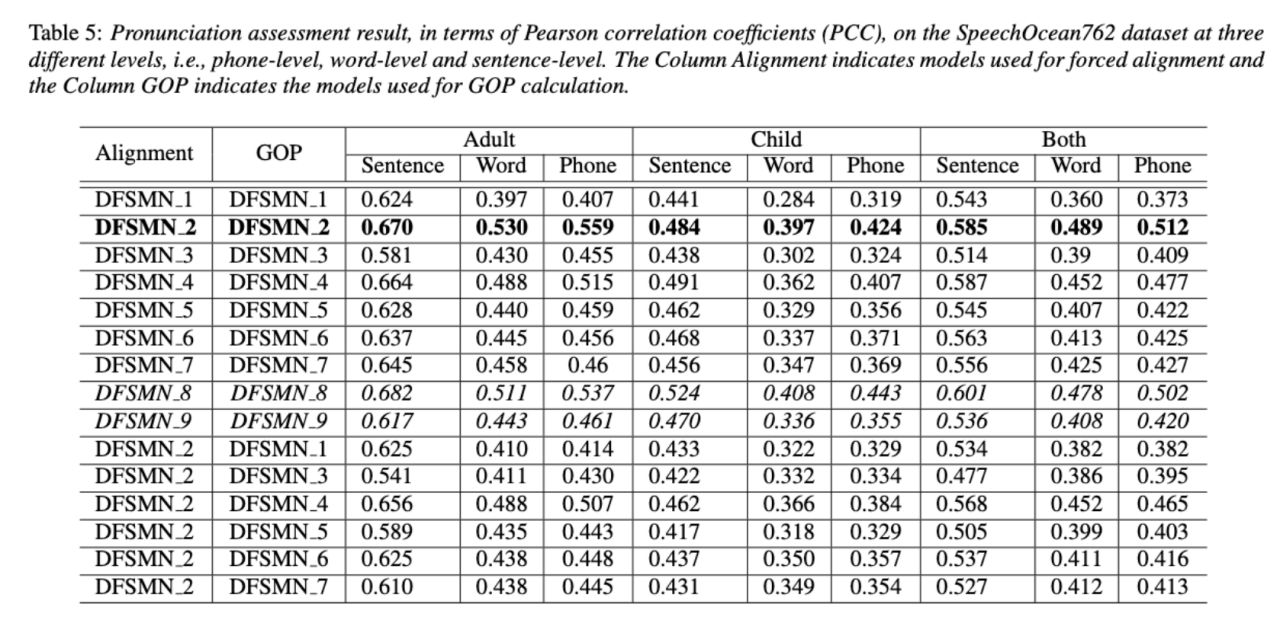
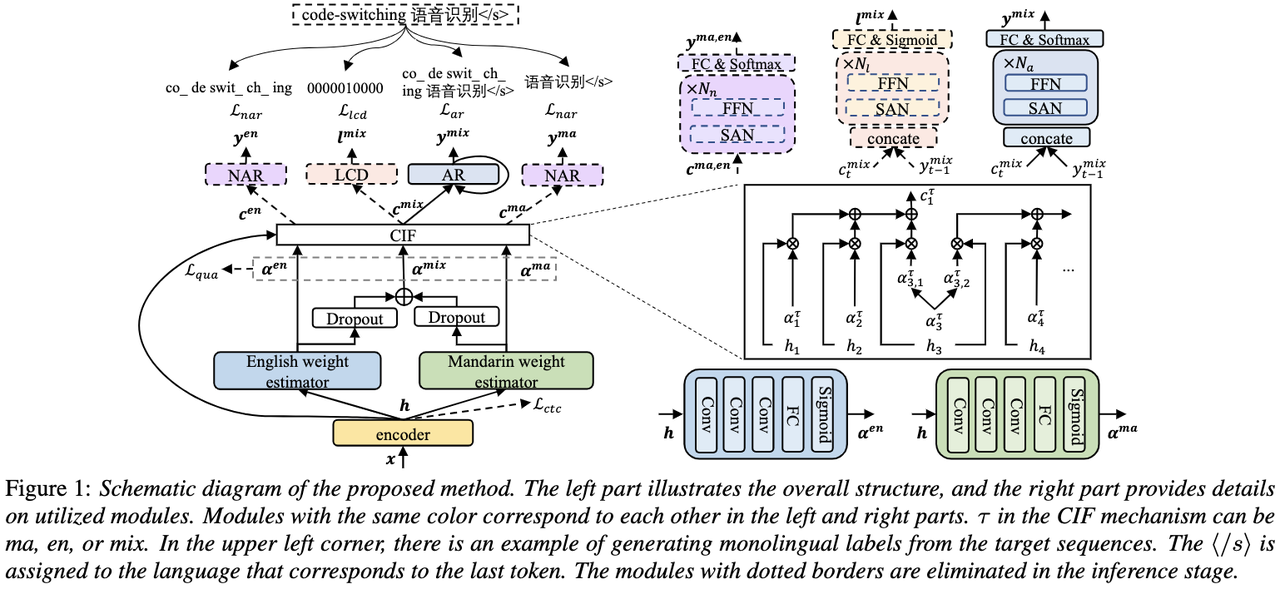
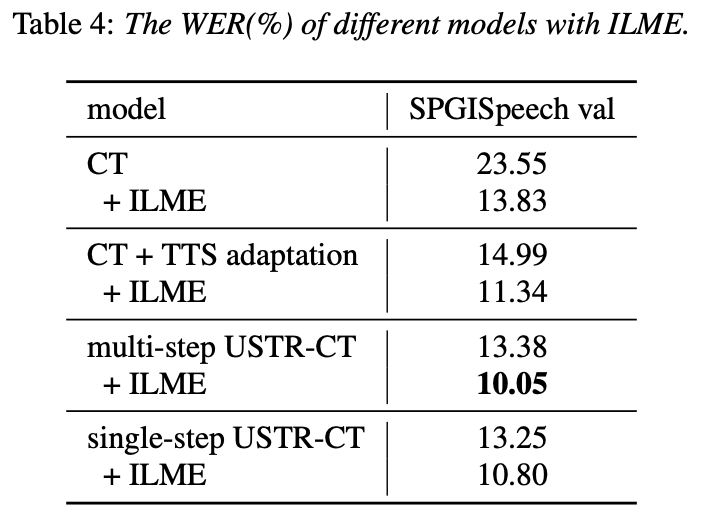
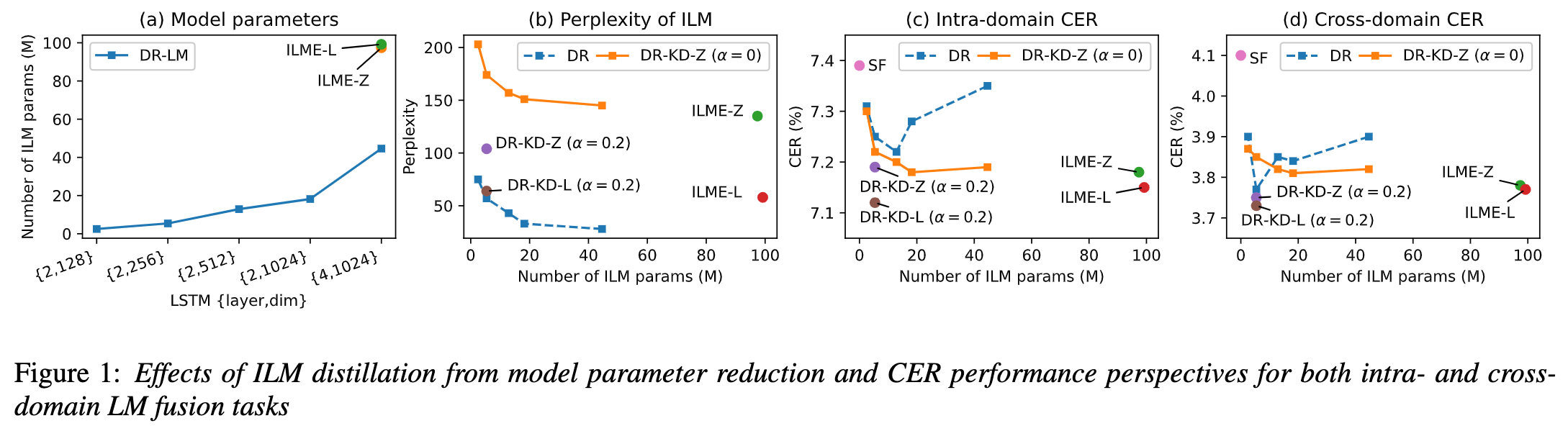
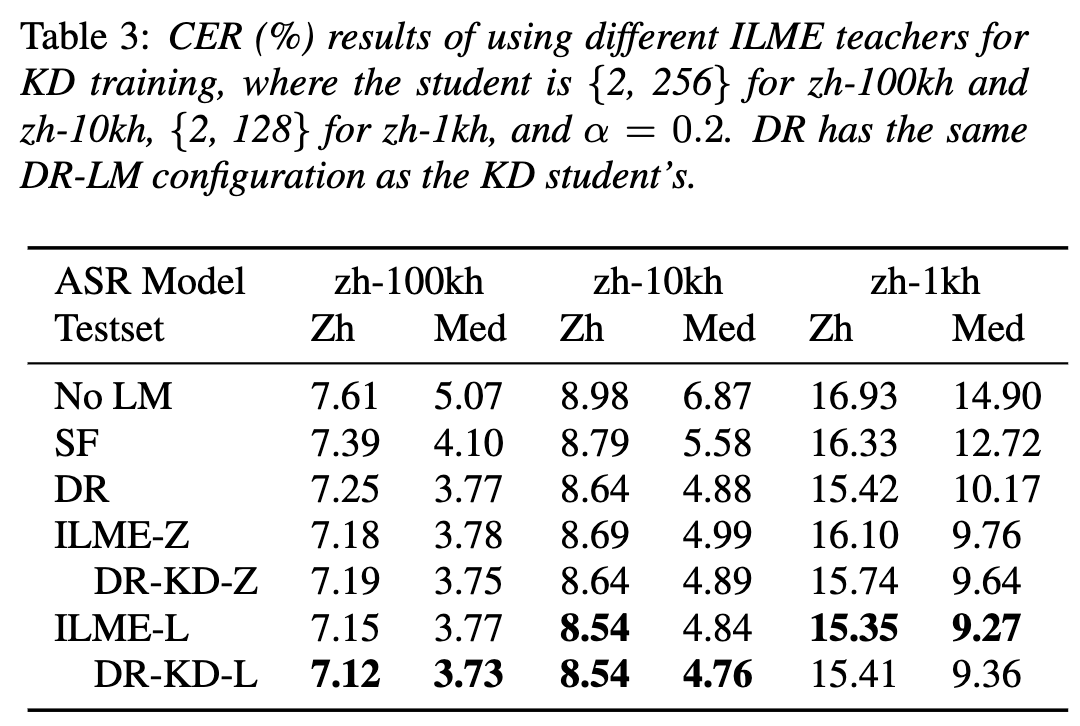
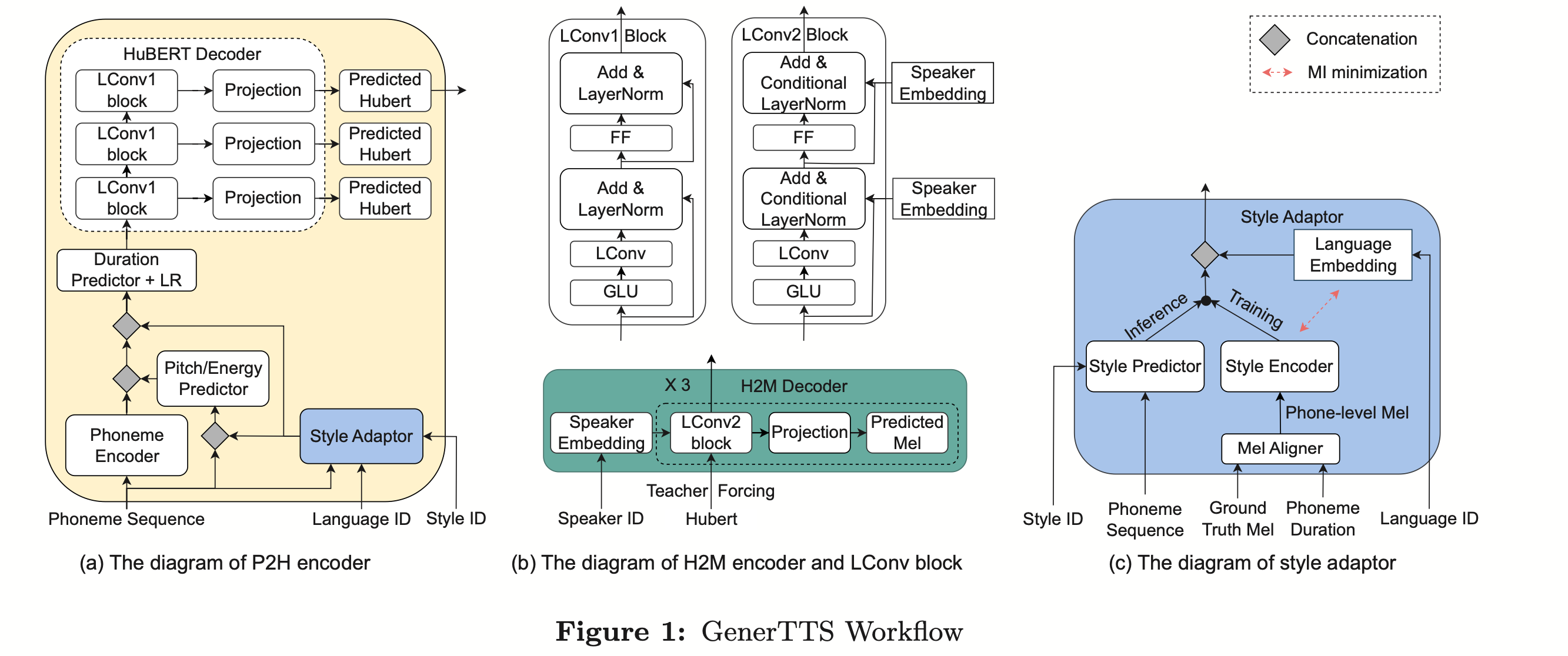
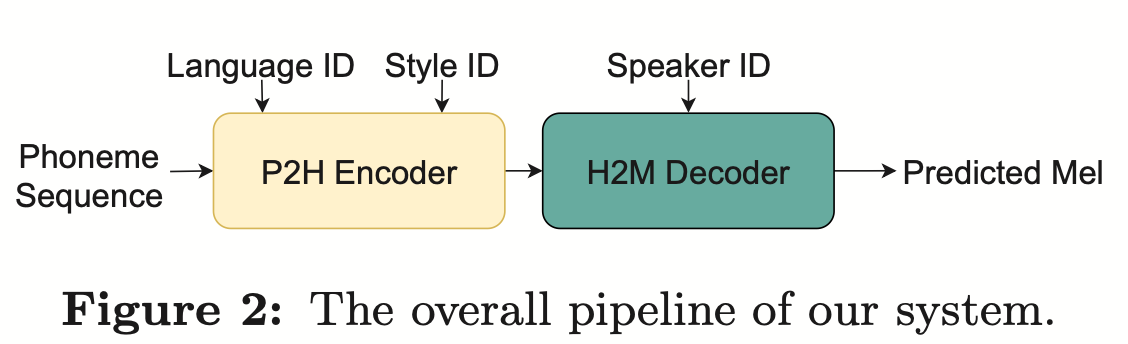
Disentangling the Contribution of Non-native Speech in Automated Pronunciation Assessment A basic idea of non-native speaker pronunciation assessment is to quantify the deviation between learner pronunciation and native speaker pronunciation. Therefore, early acoustic models used for pronunciation evaluation usually only use target language data for training, but some recent studies have begun to use non-native language pronunciation data for training. Native language speech data is incorporated into model training. There is a fundamental difference between the purpose of incorporating non-native speech into L2 ASR and non-native assessment or pronunciation error detection: the goal of the former is to adapt the model to non-native data as much as possible to achieve optimal ASR performance; the latter requires balancing the two perspectives. There are seemingly contradictory requirements, that is, higher recognition accuracy of non-native speech and objective assessment of the pronunciation level of non-native pronunciation. The Volcano Speech team aims to study the contribution of non-native speech in pronunciation assessment from two different perspectives, namely alignment accuracy and assessment performance. To this end, they designed different data combinations and text transcription forms when training the acoustic model, as shown in the figure above The above two The two tables respectively show the performance of different combinations of acoustic models in alignment accuracy and evaluation. Experimental results show that using only non-native language data with manually annotated phoneme sequences during acoustic model training enables alignment of non-native speech and the highest accuracy in pronunciation assessment. Specifically, mixing half native language data and half non-native data (human-annotated phoneme sequences) in training may be slightly worse, but comparable to using only non-native data with human-annotated phoneme sequences. Furthermore, the above mixed case performs better when evaluating pronunciation on native language data. With limited resources, adding 10 hours of non-native language data significantly improved alignment accuracy and evaluation performance regardless of the text transcription type used compared to acoustic model training using only native language data. This research has important guiding significance for data applications in the field of speech evaluation Optimizing frame classification through non-spiking CTC The processor solves the timestamp problem (Improving Frame-level Classifier for Word Timings with Non-peaky CTC in End-to-End Automatic Speech Recognition) Automatic Speech Recognition (ASR) End-to-end systems in the domain have demonstrated performance comparable to hybrid systems. As a by-product of ASR, timestamps are crucial in many applications, especially in scenarios such as subtitle generation and computationally assisted pronunciation training. This paper aims to optimize the frame-level classifier in an end-to-end system to obtain timestamps. . In this regard, the team introduced the use of CTC (connectionist temporal classification) loss to train the frame-level classifier, and introduced label prior information to alleviate the spike phenomenon of CTC. It also combined the output of the Mel filter with the ASR encoder. as input features. In internal Chinese experiments, this method achieved 95.68%/94.18% accuracy in word timestamp 200ms, while the traditional hybrid system was only 93.0%/90.22%. In addition, compared to the previous end-to-end approach, the team achieved an absolute performance improvement of 4.80%/8.02% on the 7 internal languages. The accuracy of word timing is also further improved through a frame-by-frame knowledge distillation approach, although this experiment was only conducted for LibriSpeech. The results of this study demonstrate that timestamp performance in end-to-end speech recognition systems can be effectively optimized by introducing label priors and fusing different levels of features. In internal Chinese experiments, this method has achieved significant improvements compared to hybrid systems and previous end-to-end methods; in addition, the method also shows obvious advantages for multiple languages; through the application of knowledge distillation methods, it has further Improved word timing accuracy. These results are not only of great significance for applications such as subtitle generation and pronunciation training, but also provide useful exploration directions for the development of automatic speech recognition technology. Language-specific Acoustic Boundary Learning for Mandarin-English Code-switching Speech Recognition Rewritten content: As we all know, the main goal of Code Switching (CS) is to promote effective communication between different languages or technology areas. CS requires the use of two or more languages alternately in a sentence. However, merging words or phrases from multiple languages may lead to errors and confusion in speech recognition, which makes code-switched speech recognition (CSSR) a more Challenging mission The usual end-to-end ASR model consists of an encoder, a decoder and an alignment mechanism. Most of the existing end-to-end CSASR models only focus on optimizing the encoder and decoder structures, and rarely discuss whether language-related design of the alignment mechanism is needed. Most of the existing work uses a mixture of Mandarin characters and English subwords as modeling units for mixed Chinese and English scenarios. Mandarin characters usually represent single syllables in Mandarin and have clear acoustic boundaries; while English subwords are obtained without reference to any acoustic knowledge, so their acoustic boundaries may be fuzzy. In order to obtain good acoustic boundaries (alignment) between Mandarin and English in the CSASR system, language-related acoustic boundary learning is very necessary. Therefore, we improved on the CIF model and proposed a language-differentiated acoustic boundary learning method for the CSASR task. For detailed information about the model architecture, please see the figure below The model consists of six components, namely the encoder, the language-differentiated weight estimator (LSWE), the CIF module, Autoregressive (AR) decoder, non-autoregressive (NAR) decoder and language change detection (LCD) module. The calculation process of the encoder, autoregressive decoder and CIF is the same as the original CIF-based ASR method. The language-specific weight estimator is responsible for completing the modeling of language-independent acoustic boundaries. The non-autoregressive (NAR) decoder and The Language Change Detection (LCD) module is designed to assist model training and is no longer retained in the decoding stage. The experimental results show that this method is effective in two test sets of the open source Chinese-English mixed data set SEAME USTR: Based on unified representation and plain text ASR Domain adaptation (Text-only Domain Adaptation using Unified Speech-Text Representation in Transducer) As we all know, domain migration has always been a very important task in ASR, but obtaining paired speech data in the target domain is very It is time-consuming and costly, so many of them use text data related to the target domain to improve the recognition effect. Among traditional methods, TTS will increase the training cycle and the storage cost of related data, while methods such as ILME and Shallow fusion will increase the complexity of inference. Based on this task, the team split the Encoder into Audio Encoder and Shared Encoder based on RNN-T, and introduced Text Encoder to learn representations similar to speech signals; speech and text representations are Through Shared Encoder, RNN-T loss is used for training, which is called USTR (Unified Speech-Text Representation). "For the Text Encoder part, we explored different types of representations, including Character sequence, Phone sequence and Sub-word sequence. The final results showed that the Phone sequence has the best effect. As for the training method, this article explores the method based on the given RNN- Multi-step training method of T model and Single-step training method with completely random initialization." Specifically, the team used the LibriSpeech data set as the Source domain and utilized The annotated text of SPGISpeech is used as plain text for domain migration experiments. Experimental results show that the effect of this method in the target field can be basically the same as that of TTS; the Single-step training effect is higher, and the effect is basically the same as Multi-step; it is also found that the USTR method can further improve the performance of plug-in language models such as ILME. Combined, even if LM uses the same text training corpus. Finally, on the target domain test set, without combining external language models, this method achieved a relative decrease of 43.7% compared to the baseline WER of 23.55% -> 13.25%. Efficient Internal Language Model Estimation Method Based on Knowledge Distillation (Knowledge Distillation Approach for Efficient Internal Language Model Estimation) Although Internal Language Model Estimation (ILME) has proven its effectiveness in end-to-end ASR language model fusion, compared with traditional Shallow fusion, ILME additionally introduces the calculation of internal language models, increasing the cost of inference. . In order to estimate the internal language model, an additional forward calculation is required based on the ASR decoder, or an independent language model (DR-LM) is trained using the ASR training set text based on the Density Ratio method as the internal language. Approximation of the model. The ILME method based on the ASR decoder can usually achieve better performance than the density ratio method because it directly uses ASR parameters for estimation, but its calculation amount depends on the amount of parameters of the ASR decoder; the advantage of the density ratio method is that it can be controlled by The size of DR-LM enables efficient internal language model estimation. For this reason, the Volcano Voice team proposed to use the ILME method based on the ASR decoder as a teacher under the framework of the density ratio method to distill and learn DR-LM, thereby significantly reducing the calculation of ILME while maintaining the performance of ILME. cost. Experimental results show that this method can reduce 95% of the internal language model parameters and is comparable in performance to the ASR-based decoder The ILME method is quite similar. When the ILME method with better performance is used as the teacher, the corresponding student model can also achieve better results. Compared with the traditional density ratio method with a similar amount of calculation, this method has slightly better performance in high-resource scenarios. In low-resource cross-domain migration scenarios, the CER gain can reach 8%, and it is more robust to fusion weights GenerTTS:Pronunciation Disentanglement for Timbre and Style Generalization in Cross-language speech synthesis (GenerTTS: Pronunciation Disentanglement for Timbre and Style Generalization in Cross- Lingual Text-to-Speech) Generalizable speech synthesis (TTS) across language timbres and styles aims to Synthesize speech with a specific reference timbre or style that has not been trained in the target language. It faces challenges such as the difficulty in separating timbre and pronunciation because it is often difficult to obtain multilingual speech data for a specific speaker; style and pronunciation are mixed together because speech style contains both language-independent and language-dependent parts. To address these challenges, the Volcano Voice team proposed GenerTTS. They carefully designed HuBERT-based information bottlenecks to disentangle the connection between timbre and pronunciation/style. At the same time, they also eliminate language-specific information in the style by minimizing the mutual information between style and language Experimental proof, GenerTTS outperforms baseline systems in terms of stylistic similarity and pronunciation accuracy, and achieves generalizability across language timbres and styles. The Huoshan Voice team has always provided high-quality voice AI technology capabilities and full-stack voice product solutions to ByteDance’s internal business lines, and exported them to the outside world through the Volcano engine. Provide services. Since its establishment in 2017, the team has focused on the research and development of industry-leading AI intelligent voice technology, and constantly explores the efficient combination of AI and business scenarios to achieve greater user value. 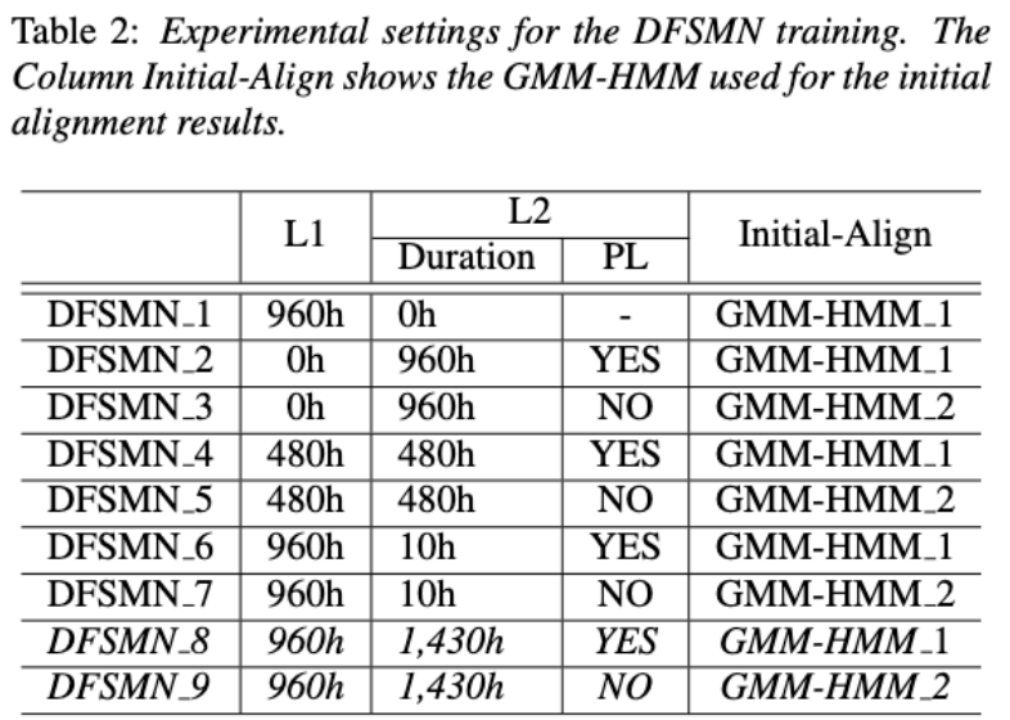
 New SOTA effects were obtained on and
New SOTA effects were obtained on and  , with MERs of 16.29% and 22.81% respectively. In order to further verify the effect of this method on larger data volumes, the team conducted experiments on an internal data set of 9,000 hours, and finally achieved a relative MER gain of 7.9%. It is understood that this paper is also the first work on acoustic boundary learning for language differentiation in the CSASR task.
, with MERs of 16.29% and 22.81% respectively. In order to further verify the effect of this method on larger data volumes, the team conducted experiments on an internal data set of 9,000 hours, and finally achieved a relative MER gain of 7.9%. It is understood that this paper is also the first work on acoustic boundary learning for language differentiation in the CSASR task. 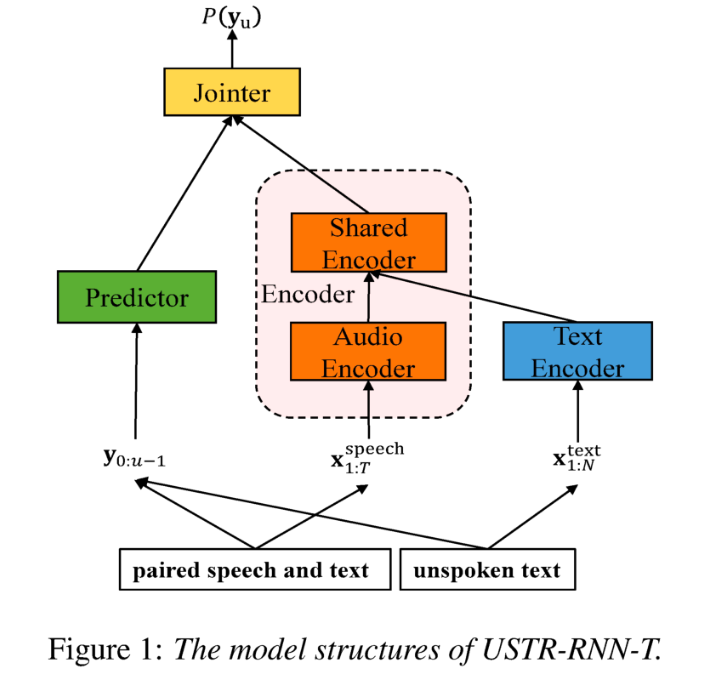

The above is the detailed content of Several papers were selected for Interspeech 2023, and Huoshan Speech effectively solved many types of practical problems. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1371
1371
 52
52

 Breaking through the boundaries of traditional defect detection, 'Defect Spectrum' achieves ultra-high-precision and rich semantic industrial defect detection for the first time.
Jul 26, 2024 pm 05:38 PM
Breaking through the boundaries of traditional defect detection, 'Defect Spectrum' achieves ultra-high-precision and rich semantic industrial defect detection for the first time.
Jul 26, 2024 pm 05:38 PM
In modern manufacturing, accurate defect detection is not only the key to ensuring product quality, but also the core of improving production efficiency. However, existing defect detection datasets often lack the accuracy and semantic richness required for practical applications, resulting in models unable to identify specific defect categories or locations. In order to solve this problem, a top research team composed of Hong Kong University of Science and Technology Guangzhou and Simou Technology innovatively developed the "DefectSpectrum" data set, which provides detailed and semantically rich large-scale annotation of industrial defects. As shown in Table 1, compared with other industrial data sets, the "DefectSpectrum" data set provides the most defect annotations (5438 defect samples) and the most detailed defect classification (125 defect categories
 NVIDIA dialogue model ChatQA has evolved to version 2.0, with the context length mentioned at 128K
Jul 26, 2024 am 08:40 AM
NVIDIA dialogue model ChatQA has evolved to version 2.0, with the context length mentioned at 128K
Jul 26, 2024 am 08:40 AM
The open LLM community is an era when a hundred flowers bloom and compete. You can see Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 and many other excellent performers. Model. However, compared with proprietary large models represented by GPT-4-Turbo, open models still have significant gaps in many fields. In addition to general models, some open models that specialize in key areas have been developed, such as DeepSeek-Coder-V2 for programming and mathematics, and InternVL for visual-language tasks.
 Google AI won the IMO Mathematical Olympiad silver medal, the mathematical reasoning model AlphaProof was launched, and reinforcement learning is so back
Jul 26, 2024 pm 02:40 PM
Google AI won the IMO Mathematical Olympiad silver medal, the mathematical reasoning model AlphaProof was launched, and reinforcement learning is so back
Jul 26, 2024 pm 02:40 PM
For AI, Mathematical Olympiad is no longer a problem. On Thursday, Google DeepMind's artificial intelligence completed a feat: using AI to solve the real question of this year's International Mathematical Olympiad IMO, and it was just one step away from winning the gold medal. The IMO competition that just ended last week had six questions involving algebra, combinatorics, geometry and number theory. The hybrid AI system proposed by Google got four questions right and scored 28 points, reaching the silver medal level. Earlier this month, UCLA tenured professor Terence Tao had just promoted the AI Mathematical Olympiad (AIMO Progress Award) with a million-dollar prize. Unexpectedly, the level of AI problem solving had improved to this level before July. Do the questions simultaneously on IMO. The most difficult thing to do correctly is IMO, which has the longest history, the largest scale, and the most negative
 Nature's point of view: The testing of artificial intelligence in medicine is in chaos. What should be done?
Aug 22, 2024 pm 04:37 PM
Nature's point of view: The testing of artificial intelligence in medicine is in chaos. What should be done?
Aug 22, 2024 pm 04:37 PM
Editor | ScienceAI Based on limited clinical data, hundreds of medical algorithms have been approved. Scientists are debating who should test the tools and how best to do so. Devin Singh witnessed a pediatric patient in the emergency room suffer cardiac arrest while waiting for treatment for a long time, which prompted him to explore the application of AI to shorten wait times. Using triage data from SickKids emergency rooms, Singh and colleagues built a series of AI models that provide potential diagnoses and recommend tests. One study showed that these models can speed up doctor visits by 22.3%, speeding up the processing of results by nearly 3 hours per patient requiring a medical test. However, the success of artificial intelligence algorithms in research only verifies this
 Training with millions of crystal data to solve the crystallographic phase problem, the deep learning method PhAI is published in Science
Aug 08, 2024 pm 09:22 PM
Training with millions of crystal data to solve the crystallographic phase problem, the deep learning method PhAI is published in Science
Aug 08, 2024 pm 09:22 PM
Editor |KX To this day, the structural detail and precision determined by crystallography, from simple metals to large membrane proteins, are unmatched by any other method. However, the biggest challenge, the so-called phase problem, remains retrieving phase information from experimentally determined amplitudes. Researchers at the University of Copenhagen in Denmark have developed a deep learning method called PhAI to solve crystal phase problems. A deep learning neural network trained using millions of artificial crystal structures and their corresponding synthetic diffraction data can generate accurate electron density maps. The study shows that this deep learning-based ab initio structural solution method can solve the phase problem at a resolution of only 2 Angstroms, which is equivalent to only 10% to 20% of the data available at atomic resolution, while traditional ab initio Calculation
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 Automatically identify the best molecules and reduce synthesis costs. MIT develops a molecular design decision-making algorithm framework
Jun 22, 2024 am 06:43 AM
Automatically identify the best molecules and reduce synthesis costs. MIT develops a molecular design decision-making algorithm framework
Jun 22, 2024 am 06:43 AM
Editor | Ziluo AI’s use in streamlining drug discovery is exploding. Screen billions of candidate molecules for those that may have properties needed to develop new drugs. There are so many variables to consider, from material prices to the risk of error, that weighing the costs of synthesizing the best candidate molecules is no easy task, even if scientists use AI. Here, MIT researchers developed SPARROW, a quantitative decision-making algorithm framework, to automatically identify the best molecular candidates, thereby minimizing synthesis costs while maximizing the likelihood that the candidates have the desired properties. The algorithm also determined the materials and experimental steps needed to synthesize these molecules. SPARROW takes into account the cost of synthesizing a batch of molecules at once, since multiple candidate molecules are often available
 SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
Editor | KX In the field of drug research and development, accurately and effectively predicting the binding affinity of proteins and ligands is crucial for drug screening and optimization. However, current studies do not take into account the important role of molecular surface information in protein-ligand interactions. Based on this, researchers from Xiamen University proposed a novel multi-modal feature extraction (MFE) framework, which for the first time combines information on protein surface, 3D structure and sequence, and uses a cross-attention mechanism to compare different modalities. feature alignment. Experimental results demonstrate that this method achieves state-of-the-art performance in predicting protein-ligand binding affinities. Furthermore, ablation studies demonstrate the effectiveness and necessity of protein surface information and multimodal feature alignment within this framework. Related research begins with "S
