

Java implementation ideas for high-performance database search algorithms


Java implementation ideas for high-performance database search algorithms
Abstract: With the advent of the Internet and big data era, the storage and search performance of the database have a significant impact on the efficiency of data processing. Crucial. This article will introduce a Java implementation idea for a high-performance database search algorithm and provide specific code examples.
- Introduction
Database search is one of the key operations for fast querying in large-scale data collections. Traditional database search algorithms have the problem of low search efficiency and cannot meet the needs of the big data era. Therefore, the research and implementation of high-performance database search algorithms have become necessary and urgent. - High-performance database search algorithm ideas
The high-performance database search algorithm proposed in this article is based on the ideas of inverted index and distributed computing. The specific process is as follows:
(1) Data preprocessing stage: First , preprocess the data in the database, extract keywords and establish an inverted index. The inverted index is a data structure with keywords as the index and the identifier of the data record as the value, which can support efficient keyword queries.
(2) Query processing stage: When the user enters the query keyword, the system will quickly locate the record containing the keyword based on the inverted index. Then, the system sorts the relevant records according to certain scoring rules and returns them to the user.
(3) Distributed computing stage: In order to improve search performance, the idea of distributed computing can be used to process queries in parallel. By dividing the query task into multiple subtasks and distributing them to different nodes for calculation, the results are finally merged. - Java implementation example
The following is a sample code for a high-performance database search algorithm implemented in Java language:
// 数据库记录类
class Record {
int id;
String content;
// 构造函数
public Record(int id, String content) {
this.id = id;
this.content = content;
}
// 获取ID
public int getId() {
return id;
}
// 获取内容
public String getContent() {
return content;
}
}
// 数据库搜索类
class DatabaseSearch {
Map<String, List<Record>> invertedIndex; // 倒排索引
// 构造函数
public DatabaseSearch(List<Record> records) {
invertedIndex = new HashMap<>();
buildInvertedIndex(records);
}
// 建立倒排索引
private void buildInvertedIndex(List<Record> records) {
for (Record record : records) {
String[] keywords = record.getContent().split(" ");
for (String keyword : keywords) {
if (!invertedIndex.containsKey(keyword)) {
invertedIndex.put(keyword, new ArrayList<>());
}
invertedIndex.get(keyword).add(record);
}
}
}
// 执行搜索
public List<Record> search(String keyword) {
if (!invertedIndex.containsKey(keyword)) {
return new ArrayList<>();
}
return invertedIndex.get(keyword);
}
}
// 示例代码的使用
public class Main {
public static void main(String[] args) {
List<Record> records = new ArrayList<>();
records.add(new Record(1, "This is a test record"));
records.add(new Record(2, "Another test record"));
records.add(new Record(3, "Yet another test record"));
DatabaseSearch dbSearch = new DatabaseSearch(records);
String keyword = "test";
List<Record> result = dbSearch.search(keyword);
System.out.println("Search results for keyword "" + keyword + "":");
for (Record record : result) {
System.out.println("ID: " + record.getId() + ", Content: " + record.getContent());
}
}
}- Conclusion
This article introduces a A high-performance database search algorithm based on inverted index and distributed computing ideas, which improves the efficiency of database search through preprocessing of data, rapid positioning and distributed computing. In practical applications, it can also be combined with other optimization technologies, such as compression algorithms, caching, etc., to further improve search performance.
References:
[1] Chen Yulan, Li Li. Search engine based on inverted index technology. Computer Science, 2016, 43(12): 8-13.
[ 2] Jukic S, Cohen A, Hawking D, et al. Efficient distributed retrieval for big data. Proceedings of the VLDB Endowment, 2011, 5(12): 1852-1863.
The above is the detailed content of Java implementation ideas for high-performance database search algorithms. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
In this article, we have kept the most asked Java Spring Interview Questions with their detailed answers. So that you can crack the interview.
 Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Java 8 introduces the Stream API, providing a powerful and expressive way to process data collections. However, a common question when using Stream is: How to break or return from a forEach operation? Traditional loops allow for early interruption or return, but Stream's forEach method does not directly support this method. This article will explain the reasons and explore alternative methods for implementing premature termination in Stream processing systems. Further reading: Java Stream API improvements Understand Stream forEach The forEach method is a terminal operation that performs one operation on each element in the Stream. Its design intention is
 Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Capsules are three-dimensional geometric figures, composed of a cylinder and a hemisphere at both ends. The volume of the capsule can be calculated by adding the volume of the cylinder and the volume of the hemisphere at both ends. This tutorial will discuss how to calculate the volume of a given capsule in Java using different methods. Capsule volume formula The formula for capsule volume is as follows: Capsule volume = Cylindrical volume Volume Two hemisphere volume in, r: The radius of the hemisphere. h: The height of the cylinder (excluding the hemisphere). Example 1 enter Radius = 5 units Height = 10 units Output Volume = 1570.8 cubic units explain Calculate volume using formula: Volume = π × r2 × h (4
 Create the Future: Java Programming for Absolute Beginners
Oct 13, 2024 pm 01:32 PM
Create the Future: Java Programming for Absolute Beginners
Oct 13, 2024 pm 01:32 PM
Java is a popular programming language that can be learned by both beginners and experienced developers. This tutorial starts with basic concepts and progresses through advanced topics. After installing the Java Development Kit, you can practice programming by creating a simple "Hello, World!" program. After you understand the code, use the command prompt to compile and run the program, and "Hello, World!" will be output on the console. Learning Java starts your programming journey, and as your mastery deepens, you can create more complex applications.
 How to Run Your First Spring Boot Application in Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
How to Run Your First Spring Boot Application in Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Spring Boot simplifies the creation of robust, scalable, and production-ready Java applications, revolutionizing Java development. Its "convention over configuration" approach, inherent to the Spring ecosystem, minimizes manual setup, allo
 Java Made Simple: A Beginner's Guide to Programming Power
Oct 11, 2024 pm 06:30 PM
Java Made Simple: A Beginner's Guide to Programming Power
Oct 11, 2024 pm 06:30 PM
Java Made Simple: A Beginner's Guide to Programming Power Introduction Java is a powerful programming language used in everything from mobile applications to enterprise-level systems. For beginners, Java's syntax is simple and easy to understand, making it an ideal choice for learning programming. Basic Syntax Java uses a class-based object-oriented programming paradigm. Classes are templates that organize related data and behavior together. Here is a simple Java class example: publicclassPerson{privateStringname;privateintage;
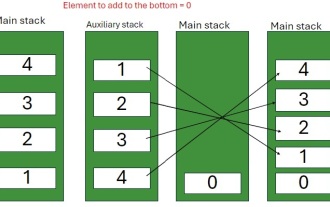 Java Program to insert an element at the Bottom of a Stack
Feb 07, 2025 am 11:59 AM
Java Program to insert an element at the Bottom of a Stack
Feb 07, 2025 am 11:59 AM
A stack is a data structure that follows the LIFO (Last In, First Out) principle. In other words, The last element we add to a stack is the first one to be removed. When we add (or push) elements to a stack, they are placed on top; i.e. above all the
 Comparing Two ArrayList In Java
Feb 07, 2025 pm 12:03 PM
Comparing Two ArrayList In Java
Feb 07, 2025 pm 12:03 PM
This guide explores several Java methods for comparing two ArrayLists. Successful comparison requires both lists to have the same size and contain identical elements. Methods for Comparing ArrayLists in Java Several approaches exist for comparing Ar
