
 Technology peripherals
AI
Lao Huang gives H100 a boost: Nvidia launches large model acceleration package, doubling Llama2 inference speed
Technology peripherals
AI
Lao Huang gives H100 a boost: Nvidia launches large model acceleration package, doubling Llama2 inference speed
Lao Huang gives H100 a boost: Nvidia launches large model acceleration package, doubling Llama2 inference speed

The inference speed of large models has doubled in just one month!
Recently, Nvidia announced the launch of a "chicken blood package" specially designed for H100, aiming to speed up the LLM inference process
Maybe now you don't have to wait for the GH200 to be delivered next year.  .
.
The computing power of GPU has been affecting the performance of large models. Both hardware suppliers and users hope to obtain faster computing speed
As the largest supplier of hardware behind large models, NVIDIA has been studying how to accelerate large model hardware.
Through cooperation with a number of AI companies, NVIDIA finally launched the large model inference optimization program TensorRT-LLM (tentatively referred to as TensorRT).
TensorRT can not only double the inference speed of large models, but is also very convenient to use.
Without in-depth knowledge of C and CUDA, you can quickly customize optimization strategies and run large models faster on H100.
NVIDIA scientist Jim Fan forwarded and commented that NVIDIA’s “another advantage” is the supporting software that can maximize the use of GPU performance.
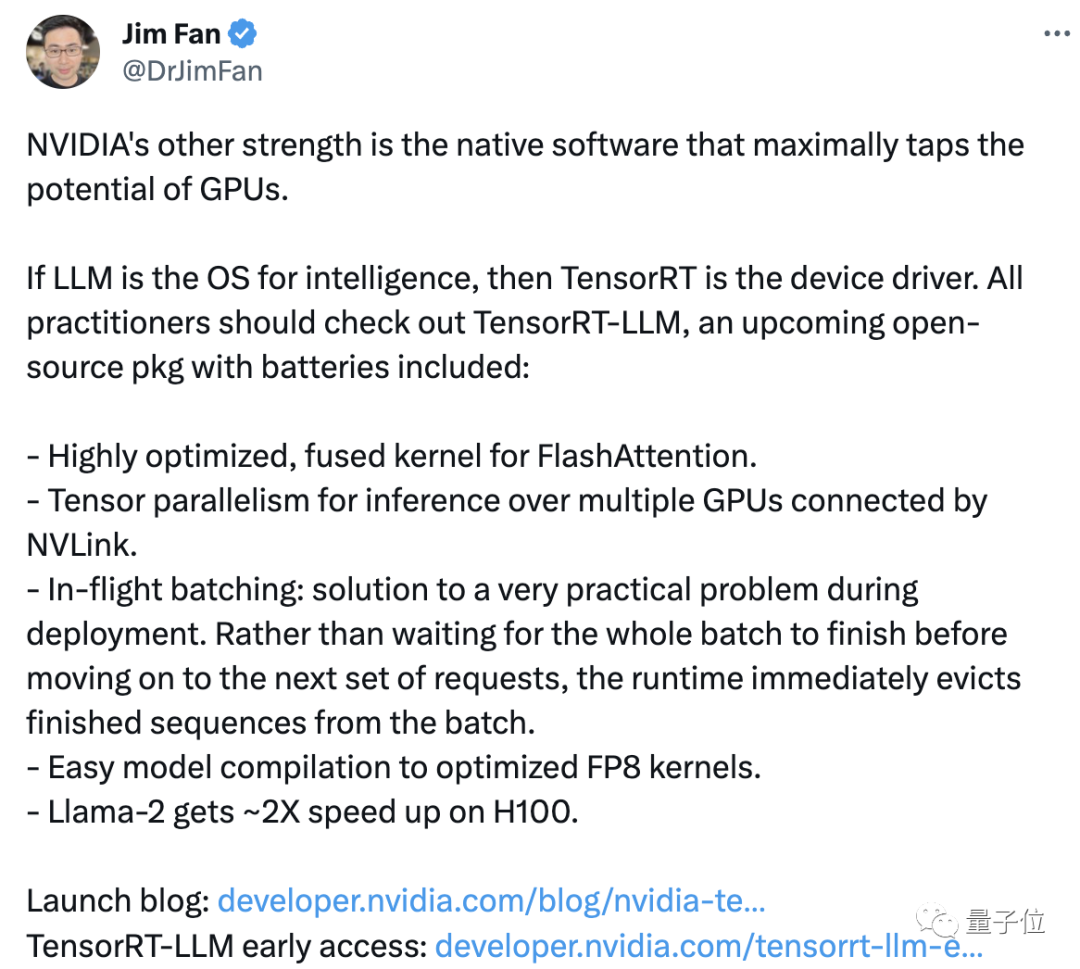
NVIDIA injects new vitality into its products through software, just like it implements Lao Huang's saying "the more you buy, the more you save." However, this does not prevent some people from thinking that the price of the product is too high
In addition to the price, some netizens also questioned its operating effect:
We always I have seen how many times the performance has improved (as advertised), but when I run Llama 2 myself, I can still only process dozens of tokens per second.
For TensorRT, we need further testing to determine whether it is really effective. Let us first take a closer look at TensorRT
Double the inference speed of large models
TensorRT-LLM optimized H100, how fast is it for running large models?
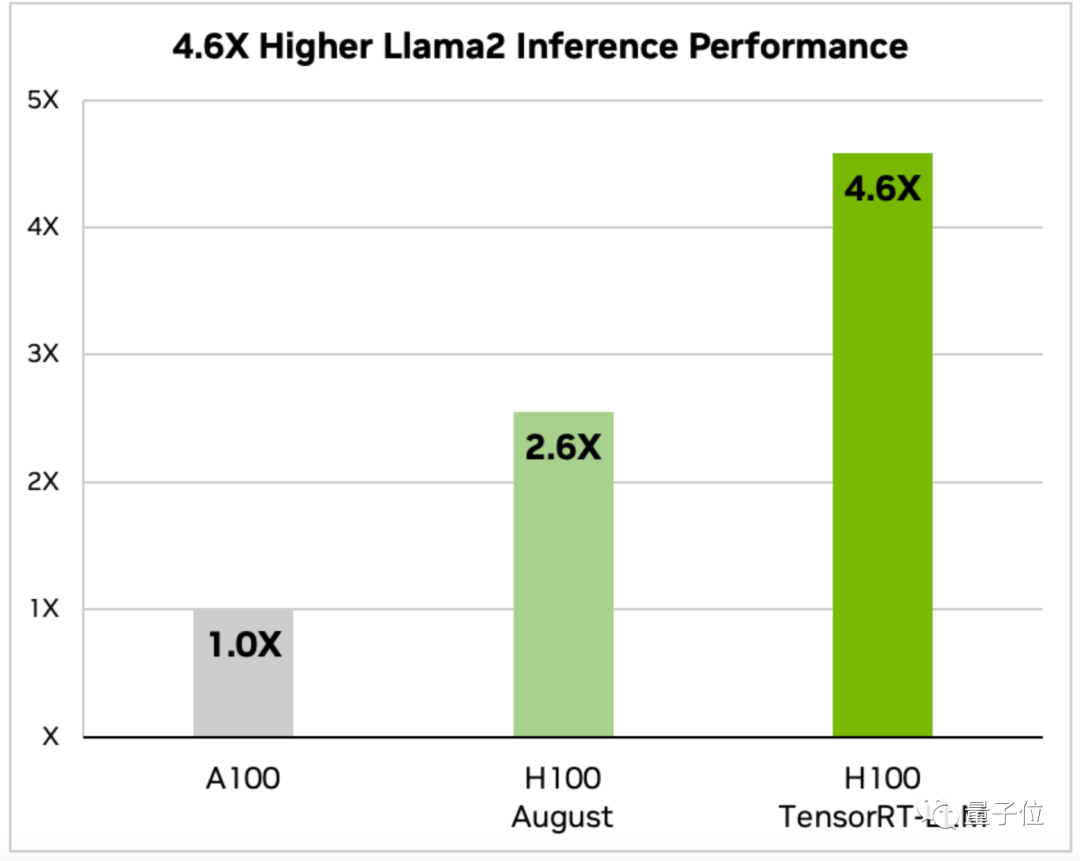
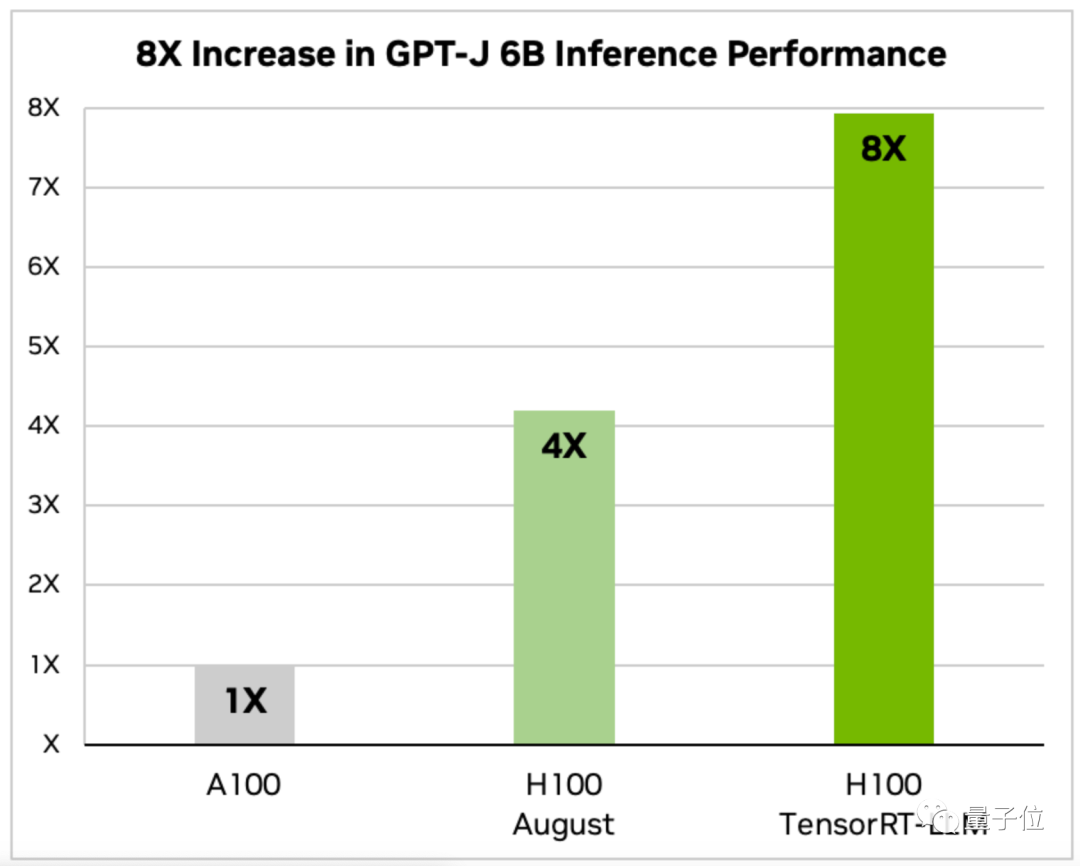
Nvidia’s announcement provides data for two models, Llama 2 and GPT-J-6B.
On the optimized H100, the inference speed of running Llama 2 is 4.6 times that of the A100 and 1.77 times that of the unoptimized H100 in August
The inference speed of GPT-J-6B is 8 times that of A100 and 2 times that of the August unoptimized version.
TensorRT also provides an open source modular Python API that can quickly customize optimization solutions according to different LLM requirements
This API will combine the deep learning compiler with , kernel optimization, pre/post-processing and multi-node communication functions are integrated together.
There are also customized versions for common models such as GPT(2/3) and Llama, which can be "used out of the box".
Through the latest open source AI kernel in TensorRT, developers can also optimize the model itself, including the attention algorithm FlashAttention that greatly speeds up Transformer.
TensorRT is a high-performance inference engine for optimizing deep learning inference. It optimizes LLM inference speed by using technologies such as mixed-precision computing, dynamic graph optimization, and layer fusion. Specifically, TensorRT improves inference speed by reducing the amount of computation and memory bandwidth requirements by converting floating-point calculations into half-precision floating-point calculations. In addition, TensorRT also uses dynamic graph optimization technology to dynamically select the optimal network structure based on the characteristics of the input data, further improving the inference speed. In addition, TensorRT also uses layer fusion technology to merge multiple computing layers into a more efficient computing layer, reducing computing and memory access overhead and further improving inference speed. In short, TensorRT has significantly improved the speed and efficiency of LLM inference through a variety of optimization technologies
First of all, it is due to TensorRT's optimization of multi-node collaborative working.
A huge model like Llama cannot be run on a single card. It requires multiple GPUs to run together.
In the past, this work required people to manually disassemble the model to achieve it.
With TensorRT, the system can automatically split the model and run it efficiently between multiple GPUs through NVLink

Secondly, TensorRT also An optimized scheduling technology called Dynamic Batch Processing is used.
During the inference process, LLM is actually performed by executing model iterations multiple times
Dynamic batch processing technology will kick out the completed sequence immediately instead of waiting for the entire batch of tasks Once complete, process the next set of requests.
In actual tests, dynamic batch processing technology successfully reduced LLM's GPU request throughput by half, thereby significantly reducing operating costs
Another key point is Convert 16-bit precision floating point numbers to 8-bit precision , thereby reducing memory consumption.
Compared with FP16 in the training phase, FP8 has lower resource consumption and is more accurate than INT-8. It can improve performance without affecting the accuracy of the model
Usage Hopper Transformer engine, the system will automatically complete the conversion and compilation of FP16 to FP8, without the need to manually modify any code in the model
Currently, the early bird version of TensorRT-LLM is available for download, and the official version will be launched in a few weeks And integrated into the NeMo framework
One More Thing
Whenever a big event occurs, the figure of "Leewenhoek" is indispensable.
In Nvidia’s announcement, it mentioned cooperation with leading artificial intelligence companies such as Meta, but did not mention OpenAI
From this announcement, some netizens discovered this point and sent it to On the OpenAI forum:
Please let me see who has not been cueed by Lao Huang (manual dog head)

Are you still What kind of "surprises" do we expect Lao Huang to bring us?
The above is the detailed content of Lao Huang gives H100 a boost: Nvidia launches large model acceleration package, doubling Llama2 inference speed. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1317
25
1268
29
1242
24
14
1423
52
1317
25
1268
29
1242
24

 How to understand DMA operations in C?
Apr 28, 2025 pm 10:09 PM
How to understand DMA operations in C?
Apr 28, 2025 pm 10:09 PM
DMA in C refers to DirectMemoryAccess, a direct memory access technology, allowing hardware devices to directly transmit data to memory without CPU intervention. 1) DMA operation is highly dependent on hardware devices and drivers, and the implementation method varies from system to system. 2) Direct access to memory may bring security risks, and the correctness and security of the code must be ensured. 3) DMA can improve performance, but improper use may lead to degradation of system performance. Through practice and learning, we can master the skills of using DMA and maximize its effectiveness in scenarios such as high-speed data transmission and real-time signal processing.
 How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
Using the chrono library in C can allow you to control time and time intervals more accurately. Let's explore the charm of this library. C's chrono library is part of the standard library, which provides a modern way to deal with time and time intervals. For programmers who have suffered from time.h and ctime, chrono is undoubtedly a boon. It not only improves the readability and maintainability of the code, but also provides higher accuracy and flexibility. Let's start with the basics. The chrono library mainly includes the following key components: std::chrono::system_clock: represents the system clock, used to obtain the current time. std::chron
 Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
The built-in quantization tools on the exchange include: 1. Binance: Provides Binance Futures quantitative module, low handling fees, and supports AI-assisted transactions. 2. OKX (Ouyi): Supports multi-account management and intelligent order routing, and provides institutional-level risk control. The independent quantitative strategy platforms include: 3. 3Commas: drag-and-drop strategy generator, suitable for multi-platform hedging arbitrage. 4. Quadency: Professional-level algorithm strategy library, supporting customized risk thresholds. 5. Pionex: Built-in 16 preset strategy, low transaction fee. Vertical domain tools include: 6. Cryptohopper: cloud-based quantitative platform, supporting 150 technical indicators. 7. Bitsgap:
 How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
Handling high DPI display in C can be achieved through the following steps: 1) Understand DPI and scaling, use the operating system API to obtain DPI information and adjust the graphics output; 2) Handle cross-platform compatibility, use cross-platform graphics libraries such as SDL or Qt; 3) Perform performance optimization, improve performance through cache, hardware acceleration, and dynamic adjustment of the details level; 4) Solve common problems, such as blurred text and interface elements are too small, and solve by correctly applying DPI scaling.
 What is real-time operating system programming in C?
Apr 28, 2025 pm 10:15 PM
What is real-time operating system programming in C?
Apr 28, 2025 pm 10:15 PM
C performs well in real-time operating system (RTOS) programming, providing efficient execution efficiency and precise time management. 1) C Meet the needs of RTOS through direct operation of hardware resources and efficient memory management. 2) Using object-oriented features, C can design a flexible task scheduling system. 3) C supports efficient interrupt processing, but dynamic memory allocation and exception processing must be avoided to ensure real-time. 4) Template programming and inline functions help in performance optimization. 5) In practical applications, C can be used to implement an efficient logging system.
 How to use string streams in C?
Apr 28, 2025 pm 09:12 PM
How to use string streams in C?
Apr 28, 2025 pm 09:12 PM
The main steps and precautions for using string streams in C are as follows: 1. Create an output string stream and convert data, such as converting integers into strings. 2. Apply to serialization of complex data structures, such as converting vector into strings. 3. Pay attention to performance issues and avoid frequent use of string streams when processing large amounts of data. You can consider using the append method of std::string. 4. Pay attention to memory management and avoid frequent creation and destruction of string stream objects. You can reuse or use std::stringstream.
 How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
Measuring thread performance in C can use the timing tools, performance analysis tools, and custom timers in the standard library. 1. Use the library to measure execution time. 2. Use gprof for performance analysis. The steps include adding the -pg option during compilation, running the program to generate a gmon.out file, and generating a performance report. 3. Use Valgrind's Callgrind module to perform more detailed analysis. The steps include running the program to generate the callgrind.out file and viewing the results using kcachegrind. 4. Custom timers can flexibly measure the execution time of a specific code segment. These methods help to fully understand thread performance and optimize code.
 An efficient way to batch insert data in MySQL
Apr 29, 2025 pm 04:18 PM
An efficient way to batch insert data in MySQL
Apr 29, 2025 pm 04:18 PM
Efficient methods for batch inserting data in MySQL include: 1. Using INSERTINTO...VALUES syntax, 2. Using LOADDATAINFILE command, 3. Using transaction processing, 4. Adjust batch size, 5. Disable indexing, 6. Using INSERTIGNORE or INSERT...ONDUPLICATEKEYUPDATE, these methods can significantly improve database operation efficiency.
