


First, let’s introduce our perception of multi-modal content.
Improve content understanding capabilities, allowing the advertising system to better understand content in segmented scenarios.

When improving content understanding ability, you will encounter many practical problems:
What is a good multimodal base representation.
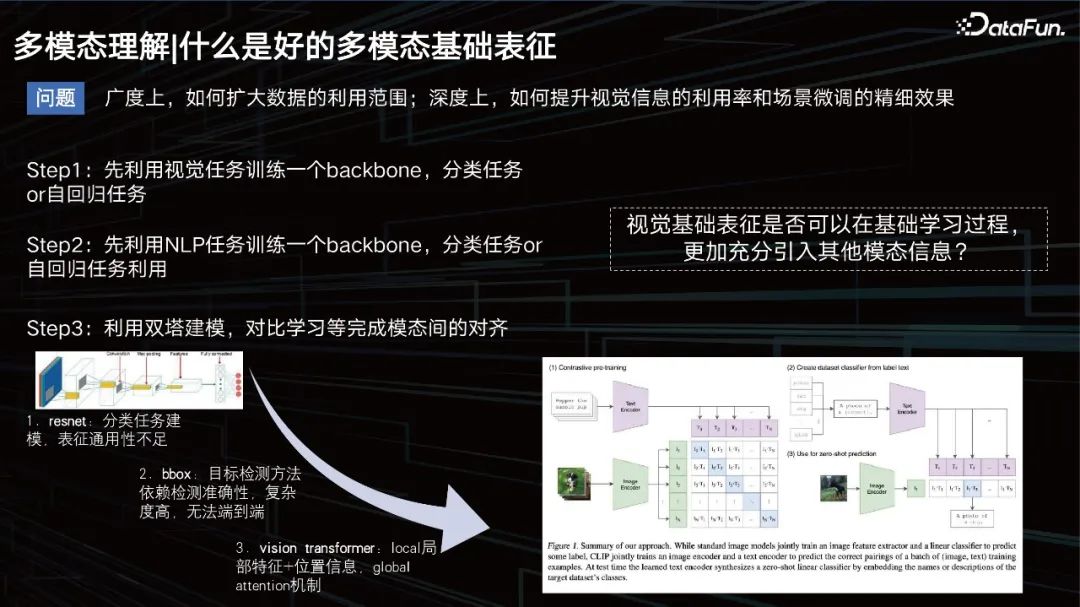
#What is a good multimodal representation?
It is necessary to expand the scope of data application in terms of breadth, improve the visual effects in terms of depth, and ensure the fine-tuning of data in the scene.
Before, the conventional idea was to train a model to learn the image modality, an autoregressive task, and then do the text task, and then apply some twin tower models to Close the modal relationship between the two. At that time, text modeling was relatively simple, and everyone was more studying how to model vision. It started with CNN, and later included some methods based on target detection to improve visual representation, such as the bbox method. However, this method has limited detection capabilities and is too heavy, which is not conducive to large-scale data training.
Around 2020 and 2021, the VIT method has become mainstream. One of the more famous models that I have to mention here is CLIP, a model released by OpenAI in 2020, which is based on the twin-tower architecture for text and visual representation. Then use cosine to close the distance between the two. This model is very good at retrieval, but it is slightly less capable in some tasks that require logical reasoning such as VQA tasks.
Learning representation: Improve the basic perception ability of natural language to vision.
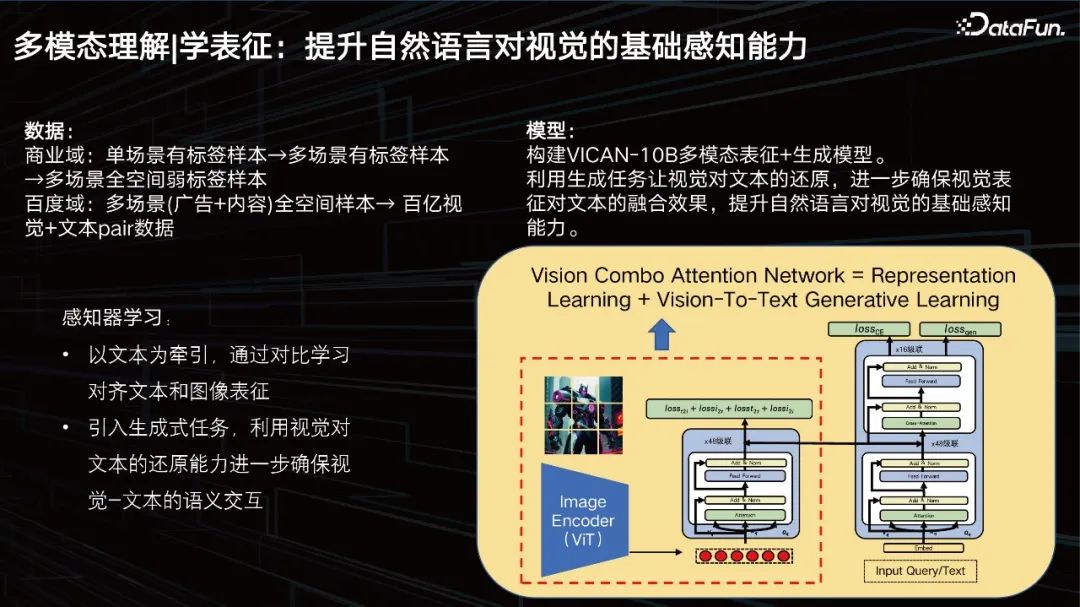
# Our goal is to improve the basic visual perception of natural language. In terms of data, our business domain has billions of data, but it is still not enough. We need to further expand, introduce past data from the business domain, and clean and sort it out. A tens of billions-level training set was constructed.
We built the VICAN-12B multi-modal representation generation model, using the generation task to allow visual restoration of text, further ensuring the fusion effect of visual representation on text, and improving the visual effects of natural language. basic perception ability. The picture above shows the overall structure of the model. You can see that it is a composite structure of two towers and a single tower. Because the first thing to be solved is a large-scale image retrieval task. The part in the box on the left is what we call the visual perceptron, which is a ViT structure with a scale of 2 billion parameters. The right side can be viewed in two layers. The lower part is a stack of text transformers for retrieval, and the upper part is for generation. The model is divided into three tasks, one is a generation task, one is a classification task, and the other is a picture comparison task. The model is trained based on these three different goals, so it has achieved relatively good results, but we will further optimize it.
A set of efficient, unified, and transferable multi-scenario global representation scheme.

Combined with business scenario data, the LLM model is introduced to improve model understanding capabilities. The CV model is the perceptron and the LLM model is the understander. Our approach is to transfer the visual features accordingly, because as mentioned just now, the representation is multi-modal and the large model is based on text. We only need to adapt it to the large model of our Wenxin LLM, so we need to use Combo attention to perform corresponding feature fusion. We need to retain the logical reasoning capabilities of the large model, so we try not to leave the large model alone and only add business scenario feedback data to promote the integration of visual features into the large model. We can use few shots to support the task. The main tasks include:
# Now, let’s focus on the scene-based fine-tuning.
Visual retrieval scenario, twin-tower fine-tuning based on basic representation.
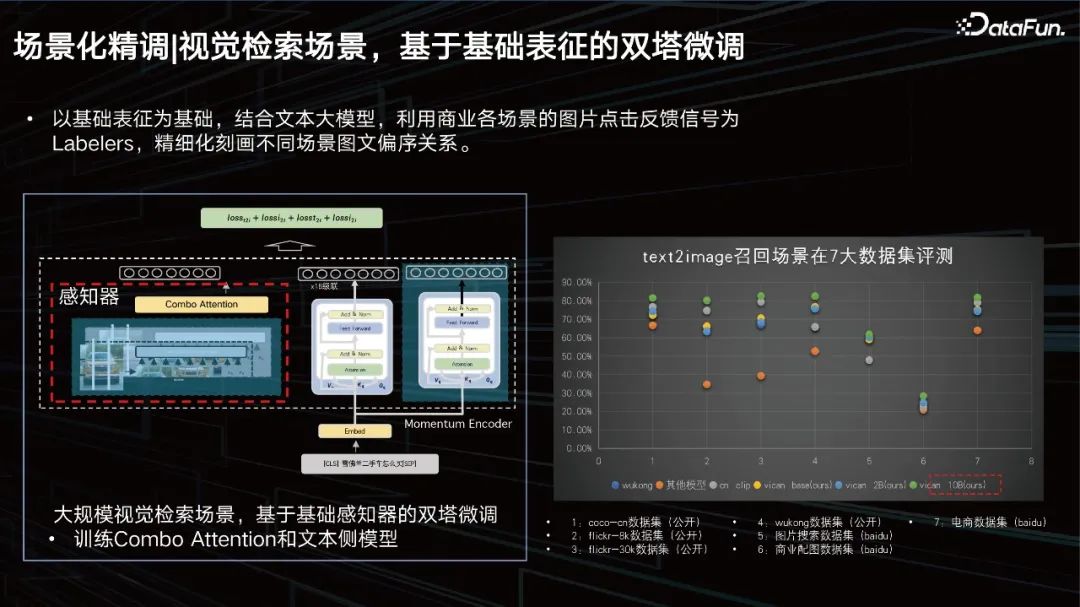
Based on the basic representation, combined with the large text model, the picture click feedback signals of various business scenes are used as Labelers to refine the partial order of pictures and texts in different scenes. relation. We have conducted evaluations on 7 major data sets, and all of them can achieve SOTA results.
Sorting scenario, inspired by text segmentation, quantifies the semantics of multi-modal features.
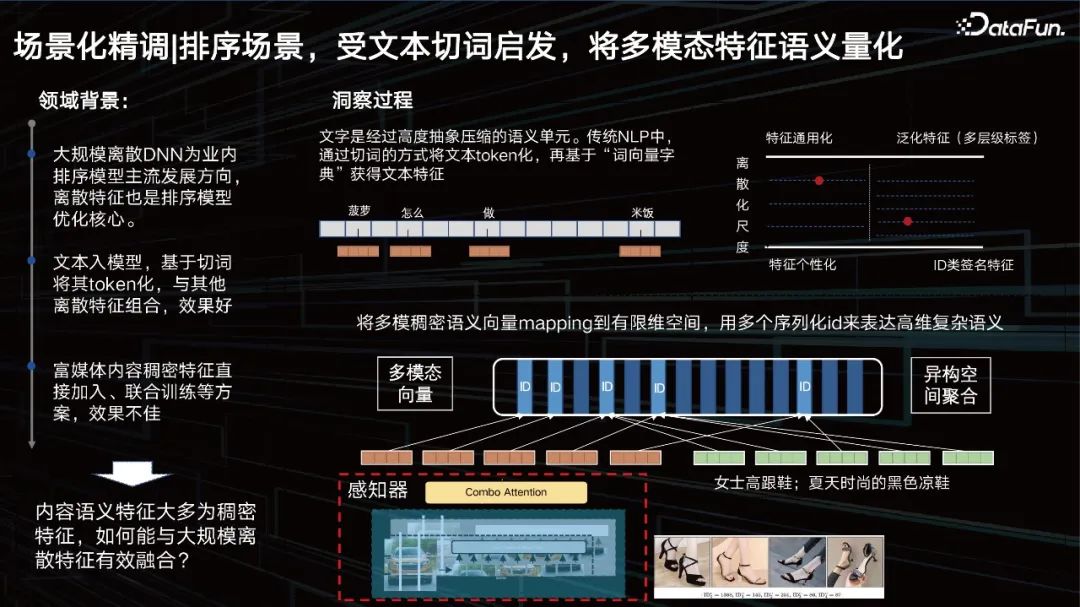
#In addition to representation, another issue is how to improve the visual effect in the sorting scene. Let’s first look at the field background. Large-scale discrete DNN is the mainstream development direction of ranking models in the industry, and discrete features are also the core of ranking model optimization. The text is entered into the model, tokenized based on word segmentation, and combined with other discrete features to achieve good results. As for vision, we hope to tokenize it as well.
ID type feature is actually a very personalized feature, but as the generalized feature becomes more versatile, its characterization accuracy may become worse. We need to dynamically adjust this balance point through data and tasks. That is to say, we hope to find a scale that is most relevant to the data, to "segment" the features into an ID accordingly, and to segment multi-modal features like text. Therefore, we proposed a multi-scale, multi-level content quantification learning method to solve this problem.
Sorting scenarios, fusion of multi-modal features and models MmDict.
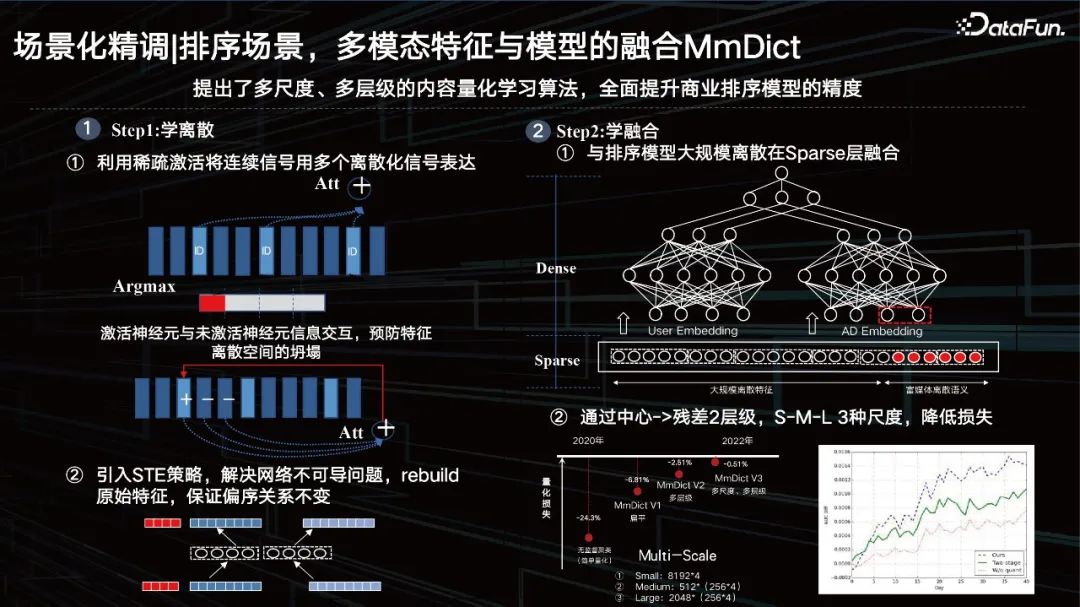
It is mainly divided into two steps. The first step is to learn discreteness, and the second step is to learn integration.
① Use sparse activation to express continuous signals with multiple discretized signals; that is, use sparse activation to segment dense features , and then activate the ID in the corresponding multi-modal codebook, but there is actually only argmax operation, which will lead to non-differentiable problems. At the same time, in order to prevent the collapse of the feature space, information interaction between activated neurons and inactive neurons is added. .
② Introduce the STE strategy to solve the problem of network non-differentiability, rebuild the original features, and ensure that the partial order relationship remains unchanged.
Through the encoder-decoder method, the dense features are serially quantized, and then the quantized features are restored in the correct way. It is necessary to ensure that its partial order relationship remains unchanged before and after restoration, and it can almost control the quantitative loss of features on specific tasks to less than 1%. Such an ID can not only personalize the current data distribution, but also have generalization properties.
① Fusion with the sorting model at the Sparse layer on a large scale.
Then the hidden layer reuse just mentioned is placed directly on top, but the effect is actually average. If you ID it, quantize it, and fuse it with the sparse feature layer and other types of features, it will have a better effect.
② Reduce the loss through center -> residual 2 levels and S-M-L 3 scales.
Of course we also use some residuals and multi-scale methods. Starting in 2020, we have gradually lowered the quantification loss, reaching below a point last year, so that after the large model extracts features, we can use this learnable quantification method to characterize the visual content, with semantic association ID The characteristics are actually very suitable for our current business systems, including such an exploratory research method on the ID of the recommendation system.

##Baidu Marketing AIGC creative platform forms a perfect closed loop from inspiration to creation to delivery. From deconstruction, generation, and feedback, we are promoting and optimizing our AIGC.

A good business Prompt has The following elements:
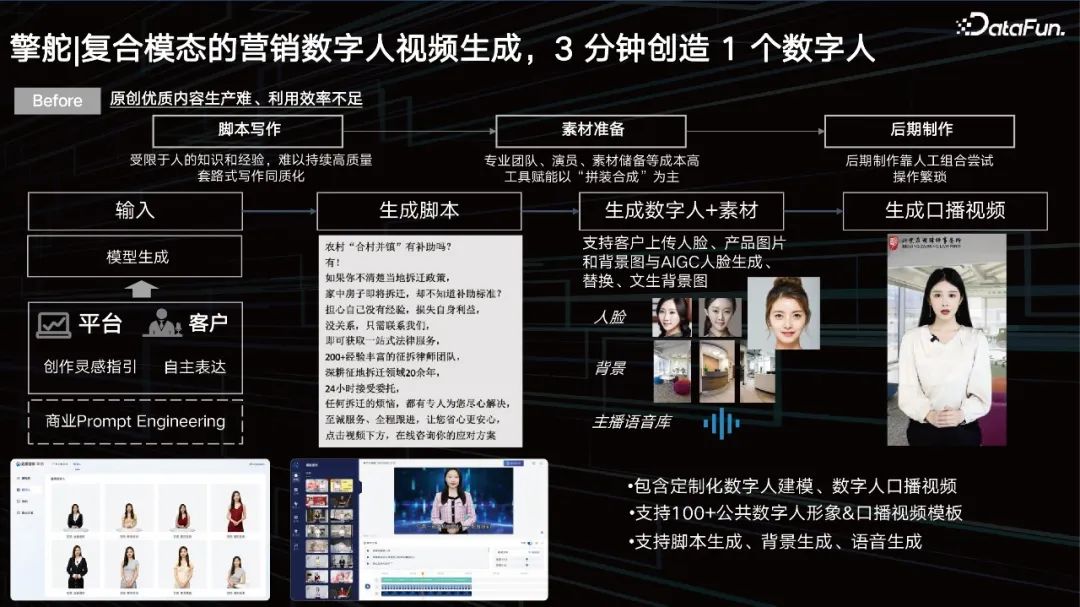
Video generation is now relatively mature. But it actually still has some problems:
In the early stage, input through prompt. What kind of video you want to generate, what kind of person you want to choose, and what kind of person you want to say, all input through prompt, and then We can accurately control our large model to generate corresponding scripts based on its demands.
Next we can recall the corresponding digital people through our digital human library, but we may use AI technology to further enhance the diversity of digital people, such as face replacement, background replacement, Accent and voice replacement are used to adapt to our prompts. Finally, script, digital lip shape replacement, background replacement, face replacement, and video suppression will give you a spoken video. Customers can use digital humans to introduce some marketing selling points corresponding to the product. In this way, you can be a digital person in 3 minutes, which greatly improves advertisers' ability to be a digital person.
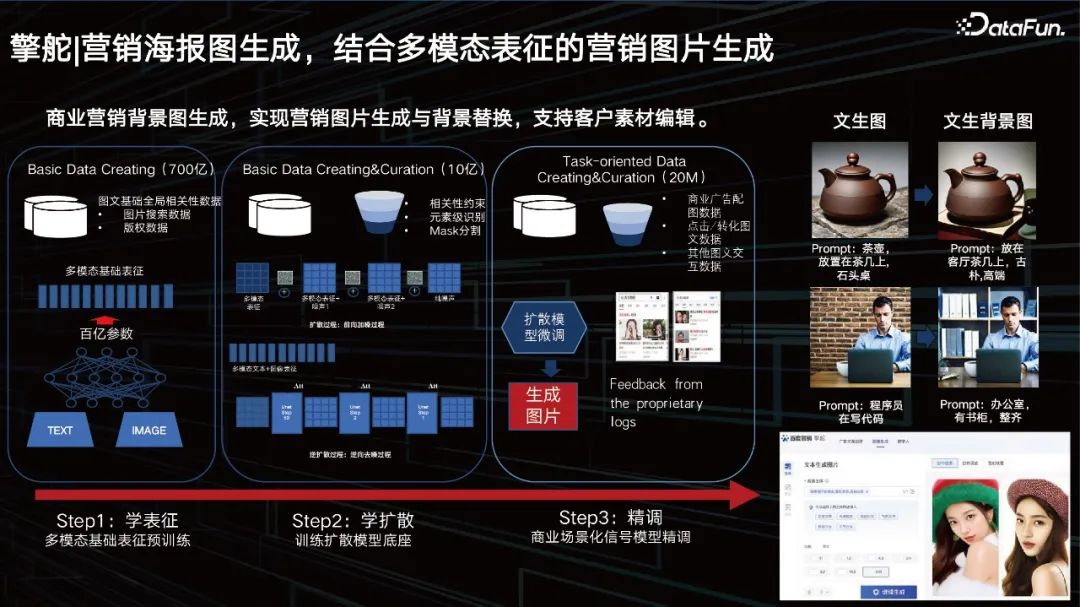
The large model can also help businesses realize the generation of marketing posters and products Background replacement. We already have a tens of billions of multi-modal representations. The middle layer is a diffusion we learned. We learn unet based on good dynamic representations. After training with big data, customers also want something particularly personalized, so we also need to add some fine-tuning methods.
We provide a solution to help customers fine-tune, a solution for dynamically loading small parameters for large models. This is also a common solution in the industry.
First of all, we provide customers with the ability to generate pictures. Customers can change the background behind the picture through editing or prompting.
The above is the detailed content of Baidu business multi-modal understanding and AIGC innovation practice. For more information, please follow other related articles on the PHP Chinese website!
 Will the Bitcoin inscription disappear?
Will the Bitcoin inscription disappear?
 Where is the prtscrn button?
Where is the prtscrn button?
 Can BAGS coins be held for a long time?
Can BAGS coins be held for a long time?
 The difference between UCOS and linux
The difference between UCOS and linux
 What is mobile phone HD?
What is mobile phone HD?
 mongodb startup command
mongodb startup command
 How to connect broadband to server
How to connect broadband to server
 What are the cloud servers?
What are the cloud servers?
 Why can't my mobile phone make calls but not surf the Internet?
Why can't my mobile phone make calls but not surf the Internet?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



