
 Technology peripherals
AI
Lack of high-quality data to train large models? We found a new solution
Technology peripherals
AI
Lack of high-quality data to train large models? We found a new solution
Lack of high-quality data to train large models? We found a new solution

Data, as one of the three major factors that determine the performance of machine learning models, is becoming a bottleneck restricting the development of large models. As the saying goes "Garbage in, garbage out" [1], no matter how good your algorithm is and how powerful your computing resources are, the quality of the model directly depends on the data you use to train the model.
With the emergence of various open source large models, the importance of data has been further highlighted, especially high-quality industry data. Bloomberg builds a large financial model BloombergGPT based on the open source GPT-3 framework, which proves the feasibility of developing large models for vertical industries based on the open source large model framework. In fact, building or customizing closed-source lightweight large models for vertical industries is the path chosen by most large model startups in China.
In this track, high-quality vertical industry data, fine-tuning and alignment capabilities based on professional knowledge are crucial - BloombergGPT is built and trained based on the financial documents accumulated by Bloomberg for more than 40 years The corpus has more than 700 billion tokens [2].
However, obtaining high-quality data is not easy. Some studies have pointed out that at the current rate at which large models devour data, high-quality public domain language data, such as books, news reports, scientific papers, Wikipedia, etc., will be exhausted around 2026 [3].
There are relatively few publicly available high-quality Chinese data resources, and domestic professional data services are still in their infancy. Data collection, cleaning, annotation and verification require a lot of investment. Manpower and material resources. It is reported that the cost of collecting and cleaning 3TB of high-quality Chinese data for a large model team of a domestic university, including downloading data bandwidth, data storage resources (uncleaned original data is about 100TB), and CPU resource costs for cleaning the data, totals about hundreds of thousands. Yuan.
As the development of large models goes deeper, to train vertical industry models that meet industry needs and have extremely high accuracy, more industry expertise and even commercial confidential information will be required. domain data. However, due to privacy protection requirements and difficulties in confirming rights and dividing profits, companies are often unwilling, unable or afraid to share their data.
Is there a solution that can not only enjoy the benefits of data openness and sharing, but also protect the security and privacy of data?
Can privacy computing break the dilemma?
Privacy-preserving Computation can analyze, process and use data without ensuring that the data provider does not disclose the original data. It is regarded as promoting the circulation of data elements. and transaction [4], therefore, using privacy computing to protect the data security of large models seems to be a natural choice.
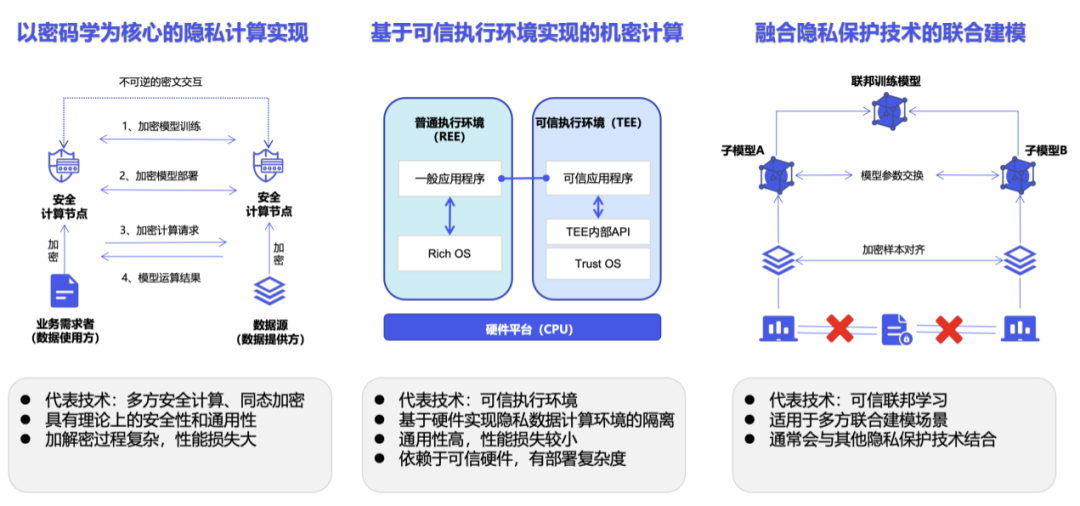
Privacy computing is not a technology, but a technical system. According to the specific implementation, privacy computing is mainly divided into cryptography paths represented by multi-party secure computing, confidential computing paths represented by trusted execution environments, and artificial intelligence paths represented by federated learning [5].
However, in practical applications, privacy computing has some limitations. For example, the introduction of privacy computing SDK usually leads to code-level modifications to the original business system [6]. If it is implemented based on cryptography, encryption and decryption operations will increase the amount of calculation exponentially, and ciphertext calculation requires greater computing and storage resources and communication load [7].
In addition, existing privacy computing solutions will encounter some new problems in large model training scenarios involving extremely large amounts of data.
Federated learning based solutions
Let us first look at the difficulties of federated learning . The core idea of federated learning is "the data does not move but the model moves". This decentralized approach ensures that sensitive data remains local and does not need to be exposed or transmitted. Each device or server participates in the training process by sending model updates to the central server, which aggregates and fuses these updates to improve the global model [8].
However, centralized training of large models is already very difficult, and distributed training methods greatly increase the complexity of the system. We also need to consider the heterogeneity of data when the model is trained on various devices, and how to safely aggregate the learning weights across all devices - for the training of large models, the model weights themselves are an important asset. Additionally, attackers must be prevented from inferring private data from a single model update, and corresponding defenses would further increase training overhead.
Cryptography-based scheme
Homomorphic encryption can directly calculate encrypted data, making the data "available and invisible" [9]. Homomorphic encryption is a powerful tool for protecting privacy in scenarios where sensitive data is processed or analyzed and its confidentiality is guaranteed. This technique can be applied not only to the training of large models, but also to inference while protecting the confidentiality of user input (prompt).
However, using encrypted data is much more difficult than using unencrypted data for training and inference of large models. At the same time, processing encrypted data requires more computation, exponentially increasing processing time and further increasing the already very high computing power requirements of training large models.
Solution based on trusted execution environment
Let’s talk about the solution based on trusted execution Environment (TEE) solutions. Most TEE solutions or products require the purchase of additional specialized equipment, such as multi-party secure computing nodes, trusted execution environment equipment, cryptographic accelerator cards, etc., and cannot adapt to existing computing and storage resources, making this solution unsuitable for many small and medium-sized enterprises. It is not realistic for enterprises. In addition, current TEE solutions are mainly based on CPU, while large model training relies heavily on GPU. At this stage, GPU solutions that support privacy computing are not yet mature, but instead create additional risks [10].
Generally speaking, in multi-party collaborative computing scenarios, it is often unreasonable to require raw data to be "invisible" in a physical sense. In addition, since the encryption process adds noise to the data, training or inference on encrypted data will also cause model performance loss and reduce model accuracy. Existing privacy computing solutions are not well suited to large model training scenarios in terms of performance and GPU support. They also hinder enterprises and institutions with high-quality data resources from opening and sharing information and participating in the large model industry. Come in.
Controllable computing, a new paradigm of privacy computing
"When we look at the large model industry as a process from data to application Chain, you will find that this chain is actually a circulation chain of various data (including original data, including data that exists in the form of parameters in the model) among different entities, and the business model of this industry should be built on these circulation chains. Data (or models) are based on assets that can be traded." said Dr. Tang Zaiyang, CEO of YiZhi Technology.
"The circulation of data elements involves multiple entities, and the source of the industry chain must be the data provider. In other words, all businesses are actually initiated by the data provider. Only with the authorization of the data provider can the transaction proceed, so priority should be given to ensuring the rights and interests of the data provider."
The mainstream privacy protection solutions currently on the market, such as multi-party secure computing, Information execution environment and federated learning both focus on how data users process data. Tang Zaiyang believes that we need to look at the problem from the perspective of the data provider.
Yizhi Technology was established in 2019 and is positioned as a privacy protection solution provider for data cooperation. In 2021, the company was selected as one of the first batch of participating units in the "Data Security Initiative (DSI)" initiated by the China Academy of Information and Communications Technology, and was certified by DSI as one of the nine representative privacy computing enterprise vendors. In 2022, YiZhi Technology officially became a member of the Open Islands open source community, China's first international independent and controllable privacy computing open source community, to jointly promote the construction of key infrastructure for the circulation of data elements.
In response to the current data dilemma of large model training and the wider circulation of data elements, YiZhi Technology has proposed a new privacy computing solution based on practice - control calculation.
「The core focus of controllable computing is to discover and share information in a privacy-preserving manner.The problem we solve is to ensure the security of the data used during the training process , and the trained model will not be maliciously stolen. " Tang Zaiyang said.
Specifically, controllable computing requires data users to process and process data in the security domain defined by the data provider.
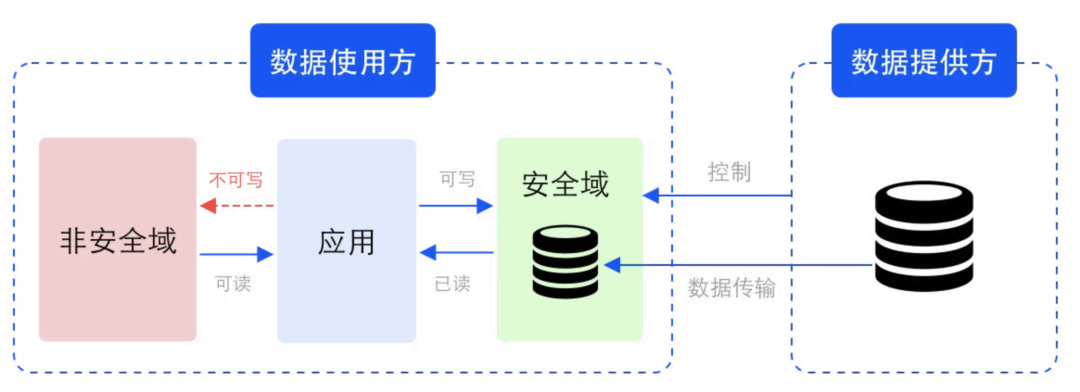
Example of security domain in data circulation scenario
Security domain is a logical concept that refers to storage and computing units protected by corresponding keys and encryption algorithms. The security domain is defined and constrained by the data provider, but the corresponding storage and computing resources are not provided by the data provider. Physically, the security domain is on the data user side but is controlled by the data provider. In addition to raw data, processed and processed intermediate data and result data are also in the same security domain.
In the security domain, the data can be ciphertext (invisible) or plaintext (visible). In the case of plaintext, since the visible range of the data is controlled, This ensures data security during use.
The performance degradation caused by complex ciphertext calculations is an important factor limiting the scope of privacy computing applications. By emphasizing the controllability of data instead of blindly pursuing invisibility, it can Controlled computing solves the intrusiveness of traditional privacy computing solutions to original businesses, so it is very suitable for large model training scenarios that need to process ultra-large-scale data.
Enterprises can choose to store their data in multiple different security domains and set different security levels, usage permissions or whitelists for these security domains. For distributed applications, security domains can also be set on multiple computer nodes or even chips.
"Security domains can be strung together. In each link of data circulation, data providers can define multiple different security domains so that their data can only be stored in these security domains. Eventually, these serially connected security domains build a data network. On this network, data is controllable, and the flow, analysis, and processing of data can also be measured and monitored, and the circulation of data can also be measured and monitored. You can make corresponding realizations." Tang Zaiyang explained.
Based on the idea of controllable computing, YiZhi Technology launched "DataVault".
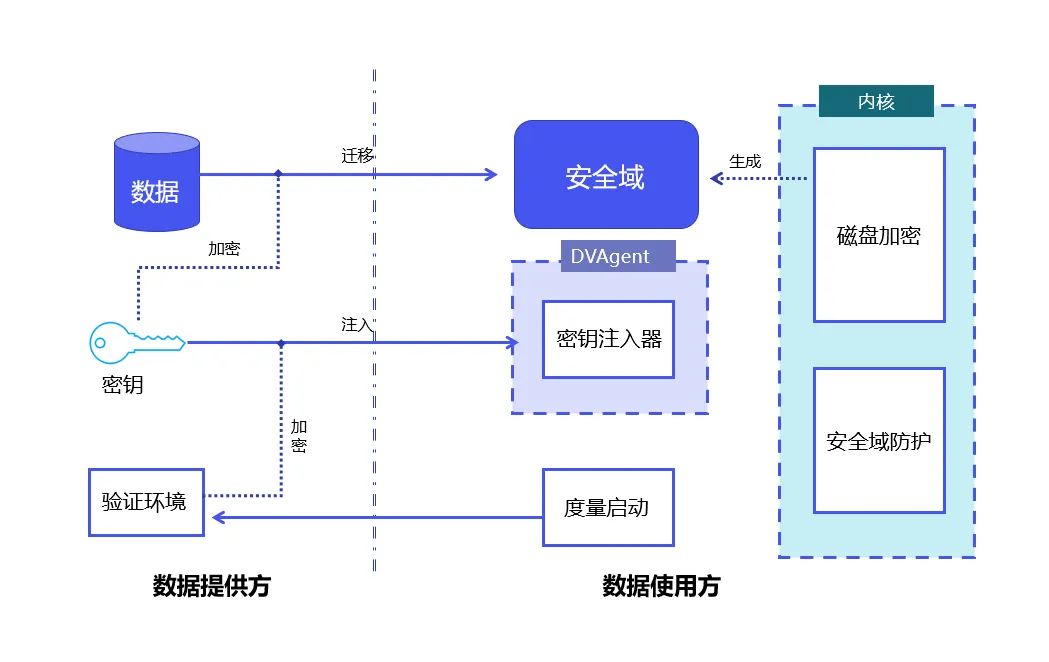
DataVault principle: Combining Linux metric startup and Linux full-disk encryption technology to achieve data control and protection within the security domain.
DataVault uses the Trusted Platform Module TPM (Trusted Platform Module, whose core is to provide hardware-based security-related functions) as the root of trust to protect the integrity of the system; use Linux security Module LSM (Linux Security Modules, a framework in the Linux kernel used to support various computer security models, which has nothing to do with any individual security implementation) technology enables data in the security domain to be used only within controllable limits.
On this basis, DataVault uses the full-disk encryption technology provided by Linux to place data in a secure domain. YiZhi Technology has independently developed a complete cryptographic protocol such as key distribution and signature authorization. A large number of engineering optimizations have been made to further ensure the controllability of data.
DataVault supports a variety of dedicated accelerator cards, including different CPU, GPU, FPGA and other hardware. It also supports multiple data processing frameworks and model training frameworks, and is binary compatible.
More importantly, it has a much lower performance loss than other privacy computing solutions. In most applications, compared to the native system (that is, without any privacy computing technology), the overall performance loss does not exceed 5%.
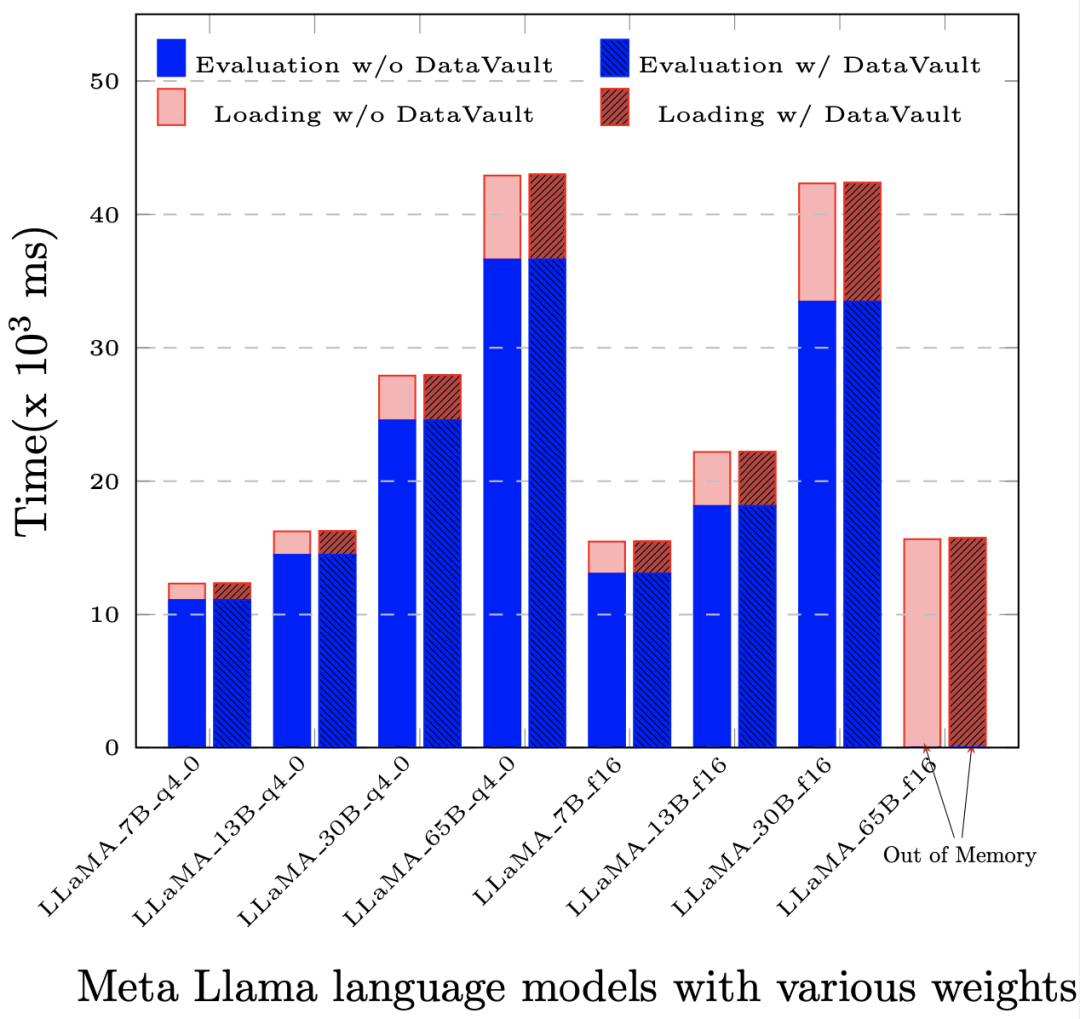
After deploying DataVault, the performance loss is less than 1‰ in the evaluation (Evaluation) and prompt evaluation (Prompt Evaluation) based on LLaMA-65B.
DataVault case of protecting data circulation and model assets
Now, YiZhi Technology has reached a cooperation with the National Supercomputing Center to build a supercomputing platform Deploy a privacy-preserving high-performance computing platform for AI applications. Based on DataVault, computing power users can set security domains on the computing platform to ensure that the entire process of data transfer from storage nodes to computing nodes can only move between security domains and does not leave the set range.
In addition to ensuring that data is controllable during model training, based on the DataVault solution, the trained large model itself, as a data asset, can also be protected and safely traded.
Currently, for those enterprises that want to deploy large models locally, such as financial, medical and other highly sensitive data institutions, they suffer from the lack of infrastructure to run large models locally, including high-cost and high-performance hardware for training large models. , as well as the subsequent operation and maintenance experience of deploying large models. For companies that build large industry models, they worry that if the models are delivered directly to customers, the industry data and expertise accumulated behind the model itself and model parameters may be re-sold.
As an exploration of the implementation of large-scale models in vertical industries, YiZhi Technology is also cooperating with the Guangdong-Hong Kong-Macao Greater Bay Area Digital Economy Research Institute (IDEA Research Institute). The two parties have jointly created Large model all-in-one machine with model safety protection function. This all-in-one machine has several built-in large models for vertical industries and is equipped with the basic computing resources required for large model training and promotion, which can meet the needs of customers out of the box. Among them, DataVault, Yizhi's controllable computing component, can ensure that these built-in models only When used with authorization, the model and all intermediate data cannot be stolen by external environments.
As a new privacy computing paradigm, YiZhi Technology hopes that controllable computing can bring changes to the large model industry and the circulation of data elements.
"DataVault is just a lightweight implementation solution. As technology and needs change, we will continue to update and make more attempts and contributions in the data element circulation market, and also We welcome more industry partners to join us and build a controllable computing community," said Tang Zaiyang.
The above is the detailed content of Lack of high-quality data to train large models? We found a new solution. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
FP8 and lower floating point quantification precision are no longer the "patent" of H100! Lao Huang wanted everyone to use INT8/INT4, and the Microsoft DeepSpeed team started running FP6 on A100 without official support from NVIDIA. Test results show that the new method TC-FPx's FP6 quantization on A100 is close to or occasionally faster than INT4, and has higher accuracy than the latter. On top of this, there is also end-to-end large model support, which has been open sourced and integrated into deep learning inference frameworks such as DeepSpeed. This result also has an immediate effect on accelerating large models - under this framework, using a single card to run Llama, the throughput is 2.65 times higher than that of dual cards. one
