

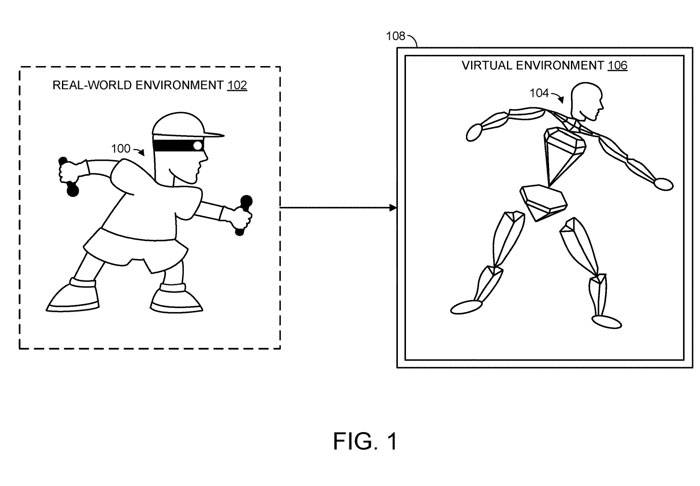
(Nweon September 18, 2023) In order to accurately represent the real-world posture of a human user, relatively detailed information about the position and orientation of the user's body parts is usually required, but this information is not always available. For example, when using a headset to provide a virtual reality experience, the system may only be able to obtain spatial information related to the user's head and hands. However, in most cases this is not sufficient to accurately reproduce the real pose of a human user
So in the patent application called "Pose prediction for articulated object", Microsoft proposed a technology to predict the posture of articulated objects. In particular, the machine learning model receives the spatial information of n different joints of the articulated object, where n joints are smaller than all the joints of the articulated object.
In the case of a human user, the n joints may include the human user's head joint and/or one or two wrist joints, which are associated with spatial information detailing the parameters of the user's head and/or hands
The machine learning model has been trained to receive input spatial information for n m joints of an articulated object, where m is greater than or equal to 1. For example, during initial training, a machine learning model receives input data corresponding to nearly all joints of an articulated object. The n m joints may include each joint of the articulated object.
In other examples, there may be n m joints where there are less than all joints of an articulated object. During the training process, the data input to the machine learning model may be gradually hidden. You can use predefined values to replace the corresponding input data of a specific node in m nodes, or simply omit
In other words, a machine learning model is trained to accurately predict the pose of an articulated object based on progressively less information about the position/orientation of the various movable parts of the articulated object.
Using this approach, machine learning models are able to accurately predict the pose of articulated objects at runtime and require only sparse input data. Microsoft notes that this technology can accurately reproduce the real-world pose of articulated objects for human users without requiring a large amount of information about the orientation of each joint.
In other words, inventions can provide technical advantages that improve human-computer interaction by more accurately reproducing the real-world gestures of human users. These technical benefits include improving the immersion of virtual reality experiences and improving the accuracy of gesture recognition systems
In addition, the described technology can reduce the consumption of computing resources while accurately reproducing the real posture of human users by reducing the amount of data that must be collected as input to the posture prediction process.
Example method 200 shows Figure 2 for predicting the pose of an articulated object
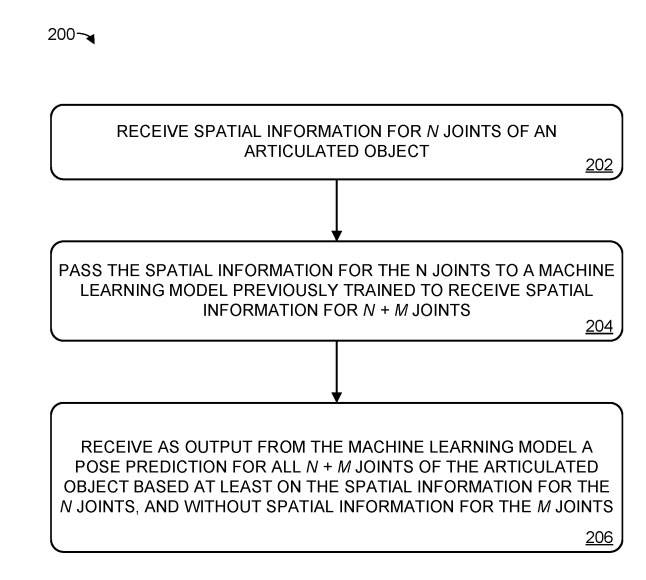
At point 202, receive the spatial information of n joints, which are used for articulated objects. The system receives the spatial information of n joints of the articulated object, which contains fewer joints than all the joints of the articulated object. Representing the spatial information of a joint as the position and orientation of six degrees of freedom connecting body parts, this can be used to infer the state of the joint
As an example, the n joints may include head joints of the human body, and the spatial information of the head joints may describe the parameters of the human head in detail. In addition, the n joints may include one or more wrist joints of the human body, and the spatial information of the one or more wrist joints may describe in detail the parameters of one or more hands of the human body.
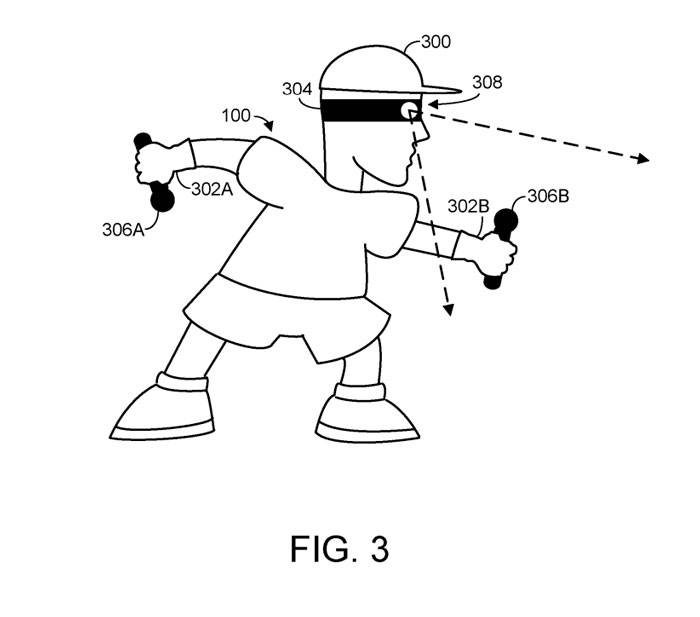
Figure 3 shows human users. The human user has a head 300 and two hands 302A and 302B. The computing system may receive spatial information for one or more joints of a human user, which may include head and/or wrist joints.
The spatial information of the n joints of the articulated object can be derived from the positioning data output by one or more sensors. Sensors may be integrated into one or more devices held or worn by corresponding body parts of a human user.
For example, sensors may include one or more inertial measurement units integrated into a head-mounted display device and/or a handheld controller. As another example, a sensor may include one or more cameras.
Figure 3 schematically illustrates different types of sensors where the output from the sensors may include or be used to derive spatial information. Specifically, a human user wears a head mounted display device 304 on his or her head 300 .
Additionally, the human user holds position sensors 306A and 306B, which may be configured to detect and report motion of the user's hands to the headset 304 and/or another computing system configured to receive spatial information.
In Figure 2, we are back to the 204 situation. We pass the spatial information of n joints to the previously trained machine learning model. This model receives spatial information of n m joints as input, where the value of m is greater than or equal to 1. In other words, compared to the previous training model, this machine learning model receives less joint space information
In 206, a pose prediction of the joint object is received as output from the machine learning model, the prediction is based on at least the spatial information of the n joints and does not contain the spatial information of their joints. In other words, even if the spatial information of m joints is not provided, the machine learning model can predict the complete posture of the joint object.
Schematic 4 shows an example machine learning model 400 to illustrate this process
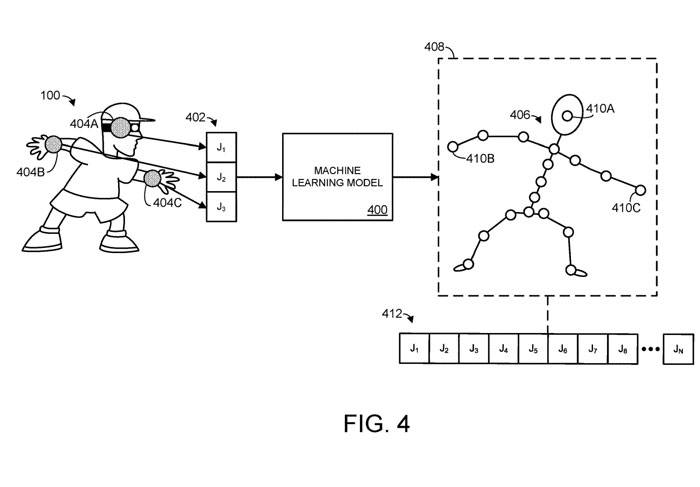
In Figure 4, the machine learning model receives spatial information 402, corresponding to three different joints J1, J2, and J3. The spatial information of the joint may take the form of any suitable computer data that specifies or can be used to derive the position and/or orientation of the body part connected to the joint.
For example, the spatial information may directly specify the position and orientation of a body part, and/or the spatial information may specify one or more rotations of a joint relative to one or more rotation axes. In Figure 4, joints J1, J2, J3 correspond to a human user's head joint 404A and two wrist joints 404B/404C, as shown by the shaded circles superimposed on the user's body.
In this example, the n joints include three joints, corresponding to the head and wrist joints of the human body. Based on the input spatial information 402, the machine learning model outputs a predicted pose 406 of the articulated object.
In addition, the machine learning model can output predicted spatial information corresponding to the joints represented by the virtual hinge. Human users can be represented by avatars with cartoonish or non-human proportions. For example, the predicted spatial information may correspond to joints represented by SMPL.
In other words, the joints of the virtual representation of the articulated representation do not have to have a 1:1 correspondence with the joints of the articulated object. Therefore, the spatial information output predicted by the machine learning model may be for joints that do not directly correspond to the n m joints of the articulated object. For example, a virtual representation may have fewer spinal joints than an articulated object.
Machine learning models can be trained in any suitable way. In one embodiment, the machine learning model may have been previously trained using training input data with ground truth labels for articulated objects.
In other words, the training spatial information of the joints of the articulated object can be provided to the machine learning model and marked as the ground truth label specifying the actual pose of the articulated object corresponding to the spatial information.
As mentioned above, a machine learning model can be trained to receive spatial information of n m joints as input. This involves, in the first training iteration, providing the machine learning model with training input data for all n m joints. In a subsequent series of training iterations, the training input data of m joints can be gradually masked.
For example, in the second training iteration, the first joint among the m joints can be masked, where the spatial information of the joint in the training data set is replaced with a predefined value representing the masked joint, or simply omitted.
As an example. In the third training iteration, the second of the m joints can be masked, and so on, until all m joints are masked, and only the spatial information of n joints is provided to the machine learning model.
This process is illustrated in Figures 5a-5d. Specifically, in Figure 5A, machine learning model 400 is provided with a training input data set. In this embodiment, the training input data includes spatial information corresponding to a plurality of different postures of the articulated object, including the first posture 502A and the second posture 502B.
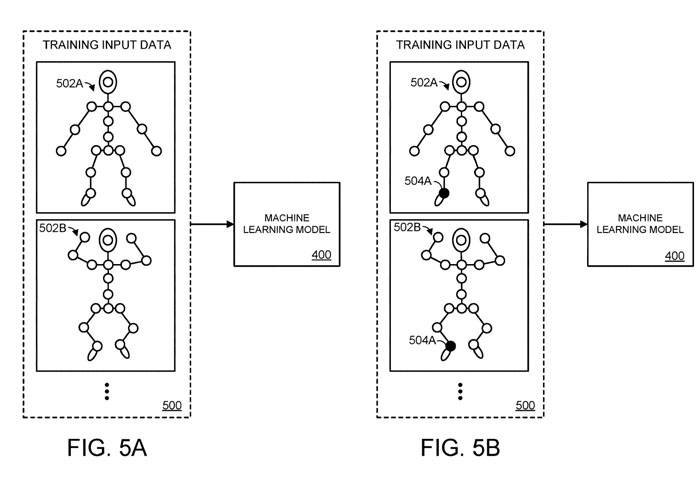
In Figure 5A, we provide the spatial information of n m joints for the articulated object of the machine learning model. In this simplified representation of the human body, each circle representing a joint is represented by a white fill pattern. However, in Figure 5B we have shielded 504A as shown with a black fill pattern representing the circle
of connector 504AIn other words, Figure 5A represents the initial iteration of the training process, in which the spatial information of all n m joints is provided to the machine learning model. Figure 5B shows the second iteration of the training process, in which the first joint 504A
of the m joints is masked.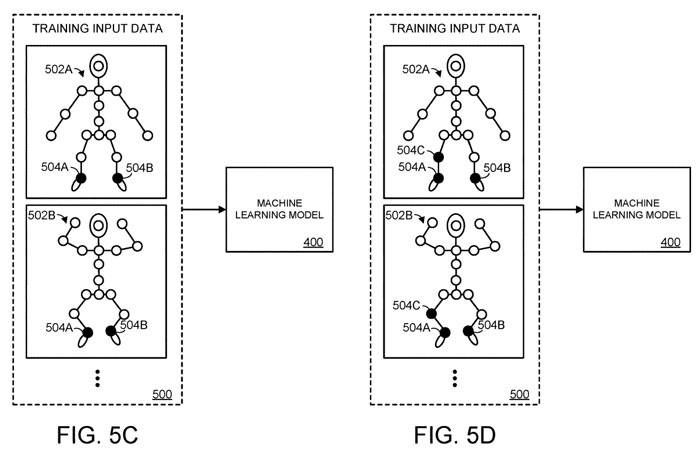
In Figure 5C, the second joint 504B among the m joints represented by the hinge is blocked. Similarly, in Figure 5D, the third joint among the m joints is occluded. Multiple training iterations can be continued until the spatial information of each of the m joints is masked, and only the spatial information of n joints is provided to the machine learning model.
In the above scenario, we describe the situation where the articulated object is the whole body of the human body. However, articulated objects can also take other forms
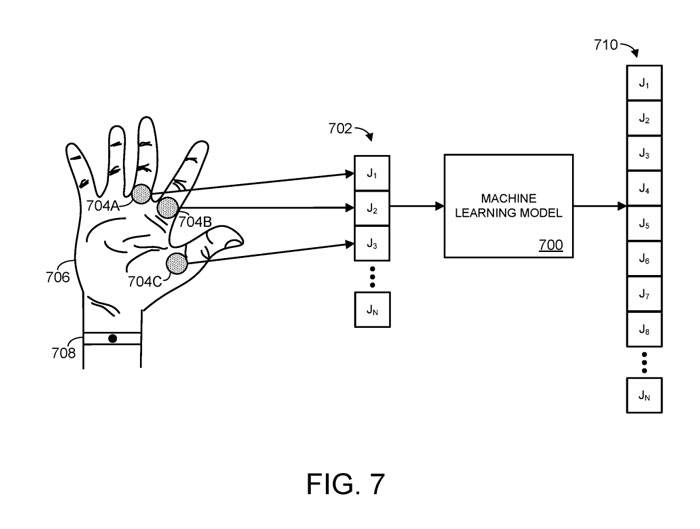
As shown in Figure 7, the articulated object is the human hand, not the entire human body. Specifically, Figure 7 shows an example machine learning model 700.
The machine learning model 700 receives spatial information for joints J1, J2, and J3, which correspond to the three joints 704A-C of an articulated object, in this example taking the form of a human hand 706.
In this case, specifically, the n joints include one or more finger joints of the human hand. The spatial information of one or more finger joints details the parameters of one or more fingers or finger segments of the human hand. For example, spatial information may specify the position/orientation of the fingers of the hand, and/or the rotation applied to the joints of the hand
Any suitable method may be used to collect joint space information, such as via position sensor 708. For example, a position sensor could take the form of a camera configured to image the hand. As another example, a position sensor may include an appropriate radio frequency antenna configured to expose the hand surface to an electromagnetic field and evaluate the effect of movement and proximity of conductive human skin on the electromagnetic field impedance at the antenna
According to the input spatial information 702, the machine learning model will output a set of predicted spatial information 710. Spatial information 710 may be used to construct the predicted pose of the articulated object. As mentioned earlier, this spatial information can represent the position and orientation of body parts of an articulated object
Related Patents: Microsoft Patent | Pose prediction for articulated object
Microsoft originally submitted a patent application called "Pose prediction for articulated object" in June 2022, and the application was recently published by the US Patent and Trademark Office
The above is the detailed content of Microsoft proposes patented technology for predicting the posture of articulated objects for AR/VR body posture capture. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



