

Georgi Gerganov, a developer in the open source community, found that he could run the 34B Code Llama model with full F16 precision on M2 Ultra, and the inference speed exceeded 20 token/s.
The M2 Ultra has a bandwidth of 800GB/s, which others usually need to use 4 high-end GPUs to achieve
The real answer behind this is: Speculative Sampling.
George's discovery immediately triggered a discussion among the big guys in the artificial intelligence industry
Karpathy forwarded a comment, "The speculative execution of LLM is a An excellent inference time optimization."

In this example, Georgi uses the Q4 7B quantum draft The model (namely Code Llama 7B) was speculatively decoded and then generated using Code Llama34B on the M2 Ultra.
To put it simply, use a "small model" to make a draft, and then use the "large model" to check and make corrections to speed up the entire process.

GitHub address: https://twitter.com/ggerganov/status/1697262700165013689
according to According to Georgi, the speeds of these models are as follows:
F16 34B: about 10 tokens per second
What needs to be rewritten is: Q4 7B: About 80 tokens per second
The following is A standard F16 sampling example without using speculative sampling:
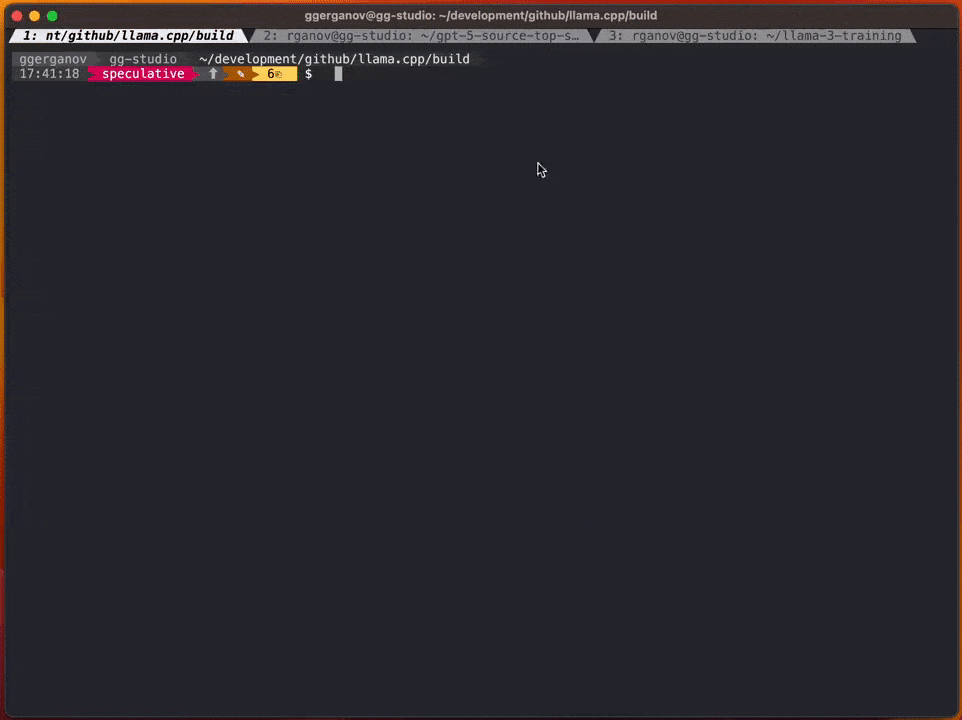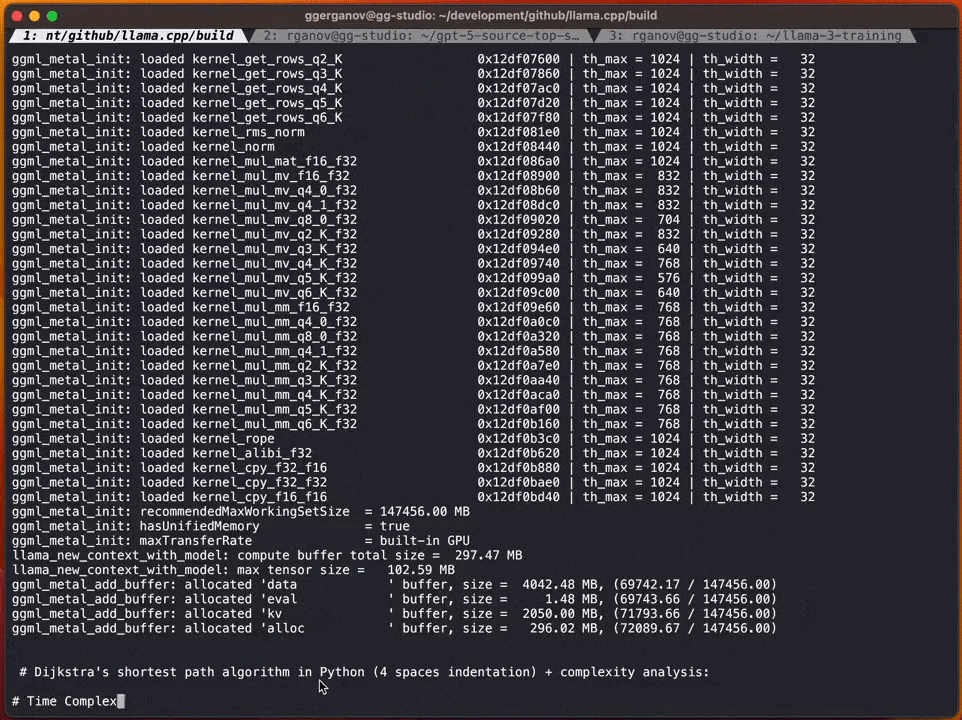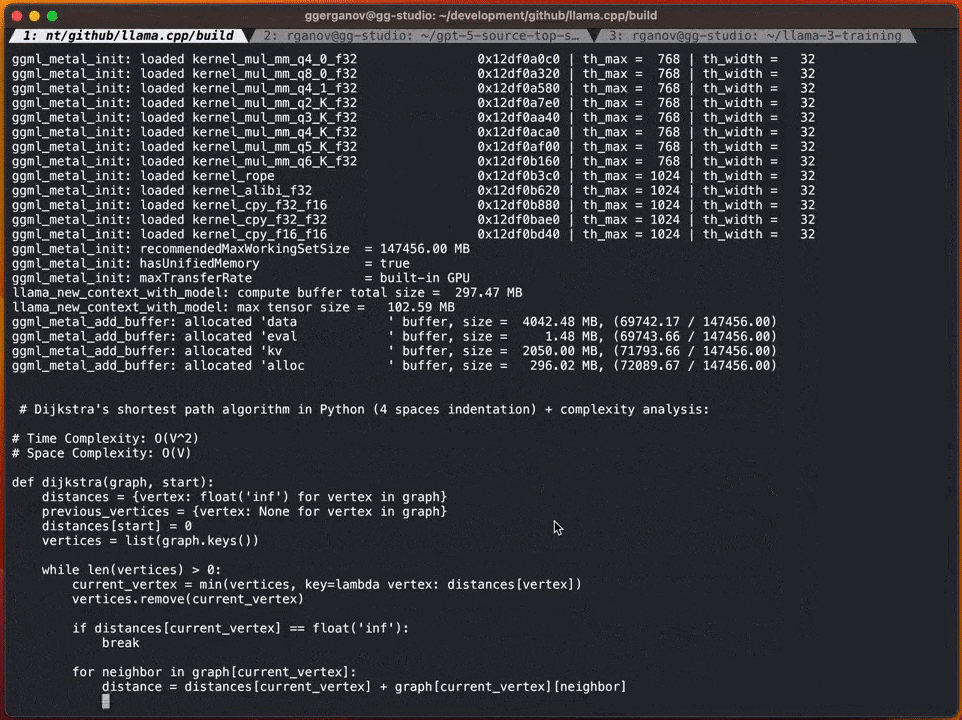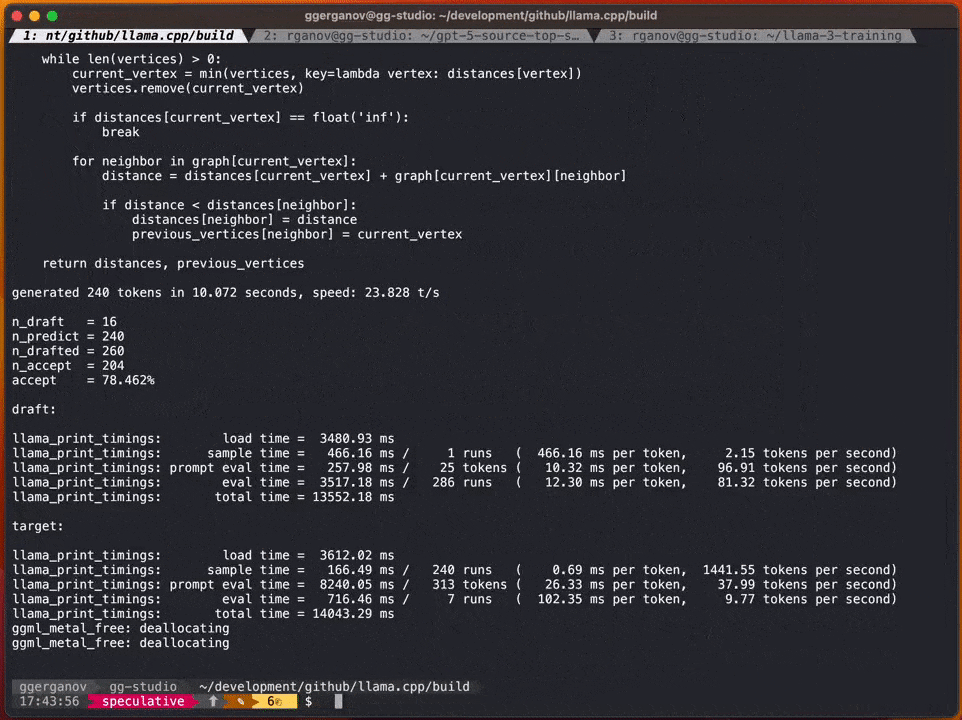
After adding the speculative sampling strategy, the speed can reach about 20 marks per second
According to Georgi, the speed at which content is generated may vary. However, this approach seems to be very effective for code generation, as most vocabularies can be correctly guessed by the draft model.
Use cases using "grammar sampling" are also likely to benefit greatly from it.

#How does speculative sampling achieve fast inference?
Karpathy made an explanation based on three previous studies by Google Brain, UC Berkeley, and DeepMind.

Please click the following link to view the paper: https://arxiv.org/pdf/2211.17192.pdf

Paper address: https://arxiv.org/pdf/1811.03115.pdf

Paper Address: https://arxiv.org/pdf/2302.01318.pdf
This depends on the following unintuitive observation:
In The time required to forward LLM on a single input token is the same as the time required to forward LLM on K input tokens in batches (K is larger than you think).
This unintuitive fact is because sampling is severely limited by memory. Most of the "work" is not calculated, but the weights of the Transformer are read from VRAM into the on-chip cache. deal with.

To accomplish the task of reading all the weights, it is better to apply them to the entire batch of input vectors
The reason why we cannot naively exploit this fact is Sampling K tokens at a time is because each N token depends on the token we sampled at step N-1. This is a serial dependency, so the baseline implementation just proceeds one by one from left to right.
Now, a clever idea is to use a small and cheap draft model to first generate a candidate sequence composed of K markers - a "draft". We then batch feed all this information together into the big model
According to the above method, this is almost as fast as inputting just one token.
Then, we examine the model from left to right, and the logits predicted by the sample token. Any sample that matches the draft allows us to immediately jump to the next token.
If there is a disagreement, we will abandon the draft model and bear the cost of doing some one-time work (sampling the draft model and doing a forward pass on subsequent tokens)
The reason this works in practice is that draft tokens will be accepted in most cases, and because they are simple tokens, even smaller draft models can accept them.
When these simple tokens are accepted, we will skip these parts. Difficulty tokens that the large model disagrees with will "fall back" to the original speed, but will actually be slower because of the extra work.
So, in summary: this weird trick works because LLM is memory-constrained during inference. In the case of "batch size 1", a single sequence of interest is sampled, which is the case for most "local LLM" use cases. Moreover, most tokens are "simple".
The co-founder of HuggingFace said that the 34 billion parameter model looked very large and difficult outside the data center a year and a half ago. manage. Now you can easily handle it with just a laptop

Today’s LLM is not a single breakthrough, but requires the effective coordination of multiple important components working system. Speculative Decoding is a great example that helps us think from a systems perspective.
The above is the detailed content of No need for 4 H100! 34 billion parameter Code Llama can be run on Mac, 20 tokens per second, best at code generation. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



