
 Technology peripherals
AI
Taotian Group and Aicheng Technology cooperate to release the open source large-scale model training framework Megatron-LLaMA
Technology peripherals
AI
Taotian Group and Aicheng Technology cooperate to release the open source large-scale model training framework Megatron-LLaMA
Taotian Group and Aicheng Technology cooperate to release the open source large-scale model training framework Megatron-LLaMA

On September 12, Taotian Group and Aicheng Technology officially open sourced the large model training framework - Megatron-LLaMA, aiming to allow technology developers to more conveniently improve the training performance of large language models and reduce training costs. And maintain compatibility with the LLaMA community. Tests show that in 32-card training, Megatron-LLaMA can achieve 176% acceleration compared to the code version directly obtained from HuggingFace; in large-scale training, Megatron-LLaMA has almost linear scalability compared to 32 cards. And shows a high tolerance for network instability. Currently, Megatron-LLaMA is online in the open source community.
Open source address: https://github.com/alibaba/Megatron-LLaMA
In 32-card training, compared to the code version obtained directly from HuggingFace, Megatron-LLaMA can achieve 176% acceleration; Even with the optimized version of DeepSpeed and FlashAttention, Megatron-LLaMA can still reduce training time by at least 19%. In large-scale training, Megatron-LLaMA has almost linear scalability compared to 32 cards. For example, using 512 A100 to reproduce the training of LLaMA-13B, the reverse mechanism of Megatron-LLaMA can save at least two days compared to the DistributedOptimizer of the native Megatron-LM without any loss of accuracy. -
Megatron-LLaMA exhibits a high tolerance for network instability. Even on the current cost-effective 8xA100-80GB training cluster with 4x200Gbps communication bandwidth (this environment is usually a mixed-deployment environment, the network can only use half of the bandwidth, the network bandwidth is a serious bottleneck, but the rental price is relatively low), Megatron-LLaMA can still achieve a linear expansion capability of 0.85, but Megatron-LM can only achieve less than 0.7 on this indicator. MEGATRON-LM technology brought high-performance LLAMA training opportunities ## Llama is currently a large language model open source community an important task. LLaMA introduces optimization technologies such as BPE character encoding, RoPE positional encoding, SwiGLU activation function, RMSNorm regularization, and Untied Embedding into the structure of LLM, and has achieved excellent results in many objective and subjective evaluations. LLaMA provides 7B, 13B, 30B, 65B/70B versions, which are suitable for various scenarios requiring large models, and are also favored by developers. Like many open source large models, since the official only provides the inference version of the code, there is no standard paradigm for how to carry out efficient training at the lowest cost. Megatron-LM is an elegant high-performance training solution.Megatron-LM provides tensor parallelism (Tensor Parallel, TP, which allocates large multiplications to multiple cards for parallel computing), pipeline parallelism (Pipeline Parallel, PP, which allocates different layers of the model to different cards for processing), and sequence parallelism (Sequence Parallel, SP, different parts of the sequence are processed by different cards, saving video memory), DistributedOptimizer optimization (similar to DeepSpeed Zero Stage-2, splitting gradient and optimizer parameters to all computing nodes) and other technologies can significantly reduce video memory usage and improve GPU utilization. Megatron-LM operates an active open source community, and new optimization technologies and functional designs continue to be incorporated into the framework. However, developing based on Megatron-LM is not simple, and debugging and functional verification on expensive multi-card machines is very expensive. Megatron-LLaMA first provides a set of LLaMA training code based on the Megatron-LM framework, supports model versions of various sizes, and can be easily adapted to support various variants of LLaMA, including direct support for the Tokenizer in the HuggingFace format. . Therefore, Megatron-LLaMA can be easily applied to existing offline training links without excessive adaptation. In small and medium-scale training/fine-tuning scenarios for LLaMA-7b and LLaMA-13b, Megatron-LLaMA can easily achieve industry-leading hardware utilization (MFU) of 54% and above.
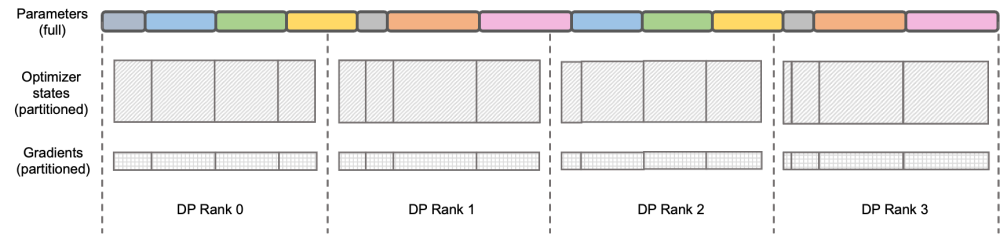
MEGATRON-LLAMA's reverse process optimization ## igue: DeepSpeed Zero Stage-2
## igue: DeepSpeed Zero Stage-2
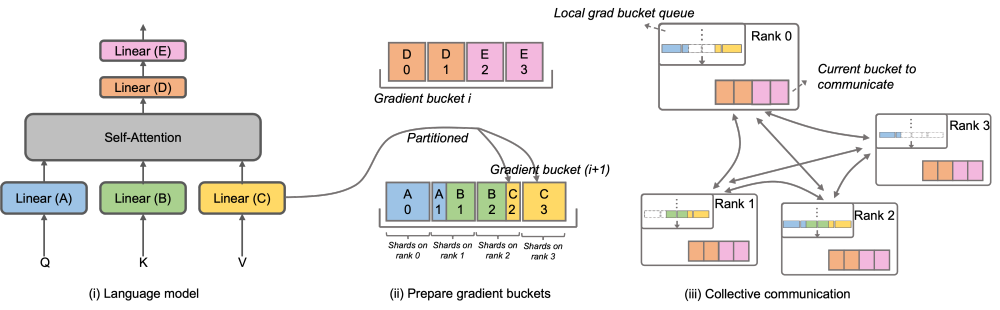
################################################################## #####DeepSpeed ZeRO is a distributed training framework launched by Microsoft. The technology proposed in it has had a profound impact on many subsequent frameworks. DeepSpeed ZeRO Stage-2 (hereinafter referred to as ZeRO-2) is a technology in the framework that saves memory usage without adding additional calculation and communication workload. As shown in the figure above, due to calculation requirements, each Rank needs to have all parameters. But for the optimizer state, each Rank is only responsible for a part of it, and it is not necessary for all Ranks to perform completely repeated operations at the same time. Therefore, ZeRO-2 proposes to evenly divide the optimizer state into each Rank (note that there is no need to ensure that each variable is evenly divided or completely retained in a certain Rank). Each Rank only needs to be used during the training process. Responsible for updating the optimizer status and model parameters of the corresponding part. In this setting, gradients can also be split in this way. By default, ZeRO-2 uses the Reduce method to aggregate gradients among all Ranks in reverse, and then each Rank only needs to retain the part of the parameters it is responsible for, which not only eliminates redundant repeated calculations, but also reduces the memory usage. . ######### Megatron-LM DistributedOptimizer### ### Native Megatron-LM implements ZeRO-2-like gradient and optimizer state segmentation through DistributedOptimizer to reduce video memory usage during training. As shown in the figure above, DistributedOptimizer uses the ReduceScatter operator to distribute all the previously accumulated gradients to different Ranks after obtaining all the gradients aggregated by the preset gradient. Each Rank only obtains part of the gradient that it needs to process, and then updates the optimizer state and the corresponding parameters. Finally, each Rank obtains updated parameters from other nodes through AllGather, and finally obtains all parameters. The actual training results show that the gradient and parameter communication of Megatron-LM are performed in series with other calculations. For large-scale pre-training tasks, in order to ensure that the total batch data size remains unchanged, it is usually impossible to open a larger GA. Therefore, the proportion of communication will increase with the increase of machines. At this time, the characteristics of serial communication lead to very weak scalability. Within the community, the need is also acute. ###### ’s over over ‐ over ‐‐‐ under‐‐hum over‐ coming and re P P to to C to to C to to C on to do to have to do with to do with L P L ‐ ‐ ‐ LLaMA overlapped to do with. The operator can be parallelized with the calculation. In particular, compared to ZeRO's implementation, Megatron-LLaMA uses a more scalable collective communication method to improve scalability through clever optimization of the optimizer partitioning strategy under the premise of parallelism.The main design of OverlappedDistributedOptimizer ensures the following points: a) The data volume of a single set communication operator is large enough to fully utilize the communication bandwidth; b) The amount of communication data required by the new segmentation method should be equal to the minimum communication data volume required for data parallelism; c) During the conversion process of complete parameters or gradients and segmented parameters or gradients, too many video memory copies cannot be introduced.Specifically, Megatron-LLaMA improves the mechanism of DistributedOptimizer and proposes OverlappedDistributedOptimizer, which is used to optimize the reverse process in training in combination with the new segmentation method. As shown in the figure above, when OverlappedDistributedOptimizer is initialized, all parameters will be pre-allocated to the Bucket to which they belong. The parameters in a Bucket are complete. A parameter only belongs to one Bucket. There may be multiple parameters in a Bucket. Logically, each Bucket will be continuously divided into P (P is the number of data parallel groups) equal parts, and each Rank in the data parallel group is responsible for one of them. #Bucket is placed in a local queue (Local grad bucket queue) to ensure communication order. During training and calculation, data parallel groups exchange the gradients they need through collective communication in Bucket units. The implementation of Bucket in Megatron-LLaMA uses address indexing as much as possible, and only newly allocates space when the required value changes, avoiding waste of video memory. The above design, combined with a large number of engineering optimizations, allows Megatron-LLaMA to fully utilize the hardware during large-scale training, achieving better performance than the native Megatron-LM Better acceleration. When training from 32 A100 cards to 512 A100 cards, Megatron-LLaMA can still achieve an expansion ratio of 0.85 in a commonly used mixed network environment.
MEGATRON-LLAMA's Future Plan# MEGATRON-LLAMA is jointly open source and provide subsequent maintenance support by Taitian Group and Ai Orange Technology The training framework has been widely used internally. As more and more developers flock to LLaMA’s open source community and contribute experiences that can be learned from each other, I believe there will be more challenges and opportunities at the training framework level in the future. Megatron-LLaMA will pay close attention to the development of the community and work with developers to promote the following directions: Adaptive optimal configuration selection - More Support for model structure or local design changes
Extreme performance training solutions in more different types of hardware environments
Project address: https://github.com/alibaba/ Megatron-LLaMA
 ## igue: DeepSpeed Zero Stage-2
## igue: DeepSpeed Zero Stage-2 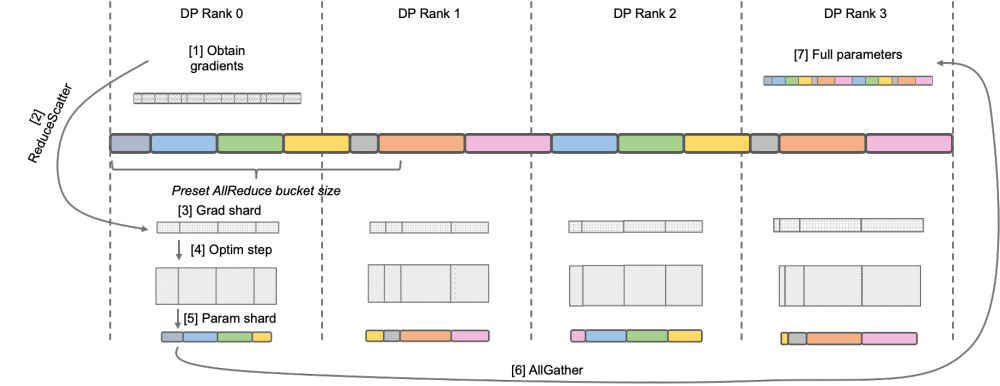
The above is the detailed content of Taotian Group and Aicheng Technology cooperate to release the open source large-scale model training framework Megatron-LLaMA. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 From RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'
Jun 24, 2024 pm 03:04 PM
From RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'
Jun 24, 2024 pm 03:04 PM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com In the development process of artificial intelligence, the control and guidance of large language models (LLM) has always been one of the core challenges, aiming to ensure that these models are both powerful and safe serve human society. Early efforts focused on reinforcement learning methods through human feedback (RL
 The author of ControlNet has another hit! The whole process of generating a painting from a picture, earning 1.4k stars in two days
Jul 17, 2024 am 01:56 AM
The author of ControlNet has another hit! The whole process of generating a painting from a picture, earning 1.4k stars in two days
Jul 17, 2024 am 01:56 AM
It is also a Tusheng video, but PaintsUndo has taken a different route. ControlNet author LvminZhang started to live again! This time I aim at the field of painting. The new project PaintsUndo has received 1.4kstar (still rising crazily) not long after it was launched. Project address: https://github.com/lllyasviel/Paints-UNDO Through this project, the user inputs a static image, and PaintsUndo can automatically help you generate a video of the entire painting process, from line draft to finished product. follow. During the drawing process, the line changes are amazing. The final video result is very similar to the original image: Let’s take a look at a complete drawing.
 Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
If the answer given by the AI model is incomprehensible at all, would you dare to use it? As machine learning systems are used in more important areas, it becomes increasingly important to demonstrate why we can trust their output, and when not to trust them. One possible way to gain trust in the output of a complex system is to require the system to produce an interpretation of its output that is readable to a human or another trusted system, that is, fully understandable to the point that any possible errors can be found. For example, to build trust in the judicial system, we require courts to provide clear and readable written opinions that explain and support their decisions. For large language models, we can also adopt a similar approach. However, when taking this approach, ensure that the language model generates
 Topping the list of open source AI software engineers, UIUC's agent-less solution easily solves SWE-bench real programming problems
Jul 17, 2024 pm 10:02 PM
Topping the list of open source AI software engineers, UIUC's agent-less solution easily solves SWE-bench real programming problems
Jul 17, 2024 pm 10:02 PM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com The authors of this paper are all from the team of teacher Zhang Lingming at the University of Illinois at Urbana-Champaign (UIUC), including: Steven Code repair; Deng Yinlin, fourth-year doctoral student, researcher
 A significant breakthrough in the Riemann Hypothesis! Tao Zhexuan strongly recommends new papers from MIT and Oxford, and the 37-year-old Fields Medal winner participated
Aug 05, 2024 pm 03:32 PM
A significant breakthrough in the Riemann Hypothesis! Tao Zhexuan strongly recommends new papers from MIT and Oxford, and the 37-year-old Fields Medal winner participated
Aug 05, 2024 pm 03:32 PM
Recently, the Riemann Hypothesis, known as one of the seven major problems of the millennium, has achieved a new breakthrough. The Riemann Hypothesis is a very important unsolved problem in mathematics, related to the precise properties of the distribution of prime numbers (primes are those numbers that are only divisible by 1 and themselves, and they play a fundamental role in number theory). In today's mathematical literature, there are more than a thousand mathematical propositions based on the establishment of the Riemann Hypothesis (or its generalized form). In other words, once the Riemann Hypothesis and its generalized form are proven, these more than a thousand propositions will be established as theorems, which will have a profound impact on the field of mathematics; and if the Riemann Hypothesis is proven wrong, then among these propositions part of it will also lose its effectiveness. New breakthrough comes from MIT mathematics professor Larry Guth and Oxford University
 Unlimited video generation, planning and decision-making, diffusion forced integration of next token prediction and full sequence diffusion
Jul 23, 2024 pm 02:05 PM
Unlimited video generation, planning and decision-making, diffusion forced integration of next token prediction and full sequence diffusion
Jul 23, 2024 pm 02:05 PM
Currently, autoregressive large-scale language models using the next token prediction paradigm have become popular all over the world. At the same time, a large number of synthetic images and videos on the Internet have already shown us the power of diffusion models. Recently, a research team at MITCSAIL (one of whom is Chen Boyuan, a PhD student at MIT) successfully integrated the powerful capabilities of the full sequence diffusion model and the next token model, and proposed a training and sampling paradigm: Diffusion Forcing (DF). Paper title: DiffusionForcing:Next-tokenPredictionMeetsFull-SequenceDiffusion Paper address: https:/
 arXiv papers can be posted as 'barrage', Stanford alphaXiv discussion platform is online, LeCun likes it
Aug 01, 2024 pm 05:18 PM
arXiv papers can be posted as 'barrage', Stanford alphaXiv discussion platform is online, LeCun likes it
Aug 01, 2024 pm 05:18 PM
cheers! What is it like when a paper discussion is down to words? Recently, students at Stanford University created alphaXiv, an open discussion forum for arXiv papers that allows questions and comments to be posted directly on any arXiv paper. Website link: https://alphaxiv.org/ In fact, there is no need to visit this website specifically. Just change arXiv in any URL to alphaXiv to directly open the corresponding paper on the alphaXiv forum: you can accurately locate the paragraphs in the paper, Sentence: In the discussion area on the right, users can post questions to ask the author about the ideas and details of the paper. For example, they can also comment on the content of the paper, such as: "Given to
 Axiomatic training allows LLM to learn causal reasoning: the 67 million parameter model is comparable to the trillion parameter level GPT-4
Jul 17, 2024 am 10:14 AM
Axiomatic training allows LLM to learn causal reasoning: the 67 million parameter model is comparable to the trillion parameter level GPT-4
Jul 17, 2024 am 10:14 AM
Show the causal chain to LLM and it learns the axioms. AI is already helping mathematicians and scientists conduct research. For example, the famous mathematician Terence Tao has repeatedly shared his research and exploration experience with the help of AI tools such as GPT. For AI to compete in these fields, strong and reliable causal reasoning capabilities are essential. The research to be introduced in this article found that a Transformer model trained on the demonstration of the causal transitivity axiom on small graphs can generalize to the transitive axiom on large graphs. In other words, if the Transformer learns to perform simple causal reasoning, it may be used for more complex causal reasoning. The axiomatic training framework proposed by the team is a new paradigm for learning causal reasoning based on passive data, with only demonstrations
