
 Technology peripherals
AI
Climbing, jumping, and crossing narrow gaps, open source reinforcement learning strategies allow robot dogs to parkour
Technology peripherals
AI
Climbing, jumping, and crossing narrow gaps, open source reinforcement learning strategies allow robot dogs to parkour
Climbing, jumping, and crossing narrow gaps, open source reinforcement learning strategies allow robot dogs to parkour

Parkour is an extreme sport. It is a huge challenge for robots, especially four-legged robot dogs, which need to quickly overcome various obstacles in complex environments. Some studies have attempted to use reference animal data or complex rewards, but these approaches generate parkour skills that are either diverse but blind, or vision-based but scene-specific. However, autonomous parkour requires robots to learn vision-based and diverse general skills to perceive various scenarios and respond quickly.
Recently, a video of a robot dog parkour went viral. The robot dog in the video quickly overcame various obstacles in a variety of scenarios. For example, pass through the gap under the iron plate, climb up the wooden box, and then jump to another wooden box. A series of actions are smooth and smooth:


This series of actions shows that the robot dog has mastered the three basic skills of crawling, climbing and jumping



It also has a special skill: it can squeeze through narrow gaps at an angle

If the robot dog fails to overcome the obstacle, it will try a few more times:

This content has been rewritten into Chinese: This robot dog is based on a "parkour" skill learning framework developed for low-cost robots. The framework was jointly proposed by researchers from Shanghai Qizhi Research Institute, Stanford University, ShanghaiTech University, CMU and Tsinghua University, and its research paper has been selected for CoRL 2023 (Oral). This research project has been open source

Paper address: https://arxiv.org/abs/2309.05665
Project address: https://github.com/ZiwenZhuang/parkour
Method introduction
This study launched a new Open source system for learning end-to-end vision-based parkour strategies to learn multiple parkour skills using simple rewards without any reference motion data.
Specifically, this research proposes a reinforcement learning method designed to allow robots to learn to climb high obstacles, jump over large gaps, crawl under low obstacles, and squeeze through Skills such as tight gaps and running, and translate these skills into parkour strategies based on a single vision. At the same time, these skills are transferred to quadruped robots by using an egocentric depth camera
To successfully deploy the parkour strategy proposed in this study on a low-cost robot, only Requires on-board computing (Nvidia Jetson), on-board depth cameras (Intel Realsense), and on-board power, without the need for motion capture, lidar, multiple depth cameras, and lots of computing
In order to train the parkour strategy, this research carried out the following three stages of work:
The first stage: reinforcement learning pre-training, with soft dynamic constraints. This research uses automatic courses to let the robot learn to cross obstacles, and encourages the robot to gradually learn to overcome obstacles
The second stage: reinforcement learning fine-tuning with hard dynamic constraints. The study enforces all dynamic constraints at this stage and uses realistic dynamics to fine-tune the robot's behavior learned in the pre-training stage.
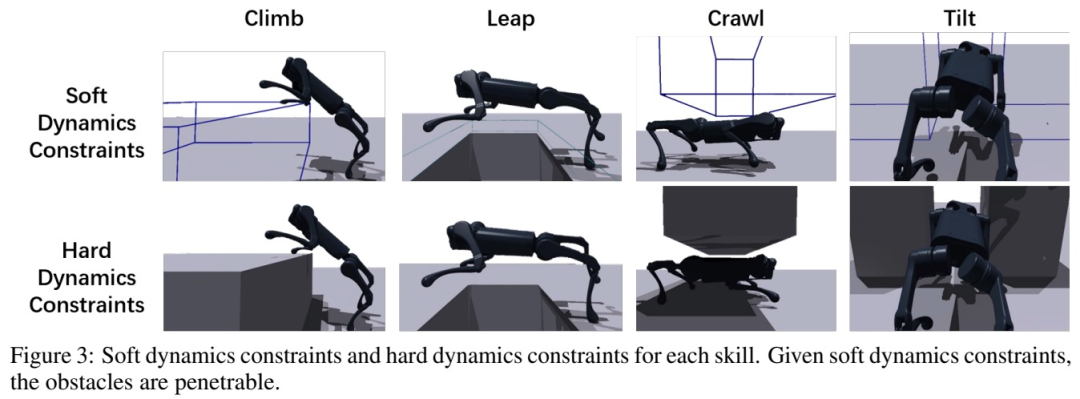
The third stage: distillation. After learning each individual parkour skill, the study uses Dagger to distill them into a vision-based parkour policy (parameterized by an RNN) that can be deployed on a legged robot using only onboard perception and computation. .

##Experiments and results
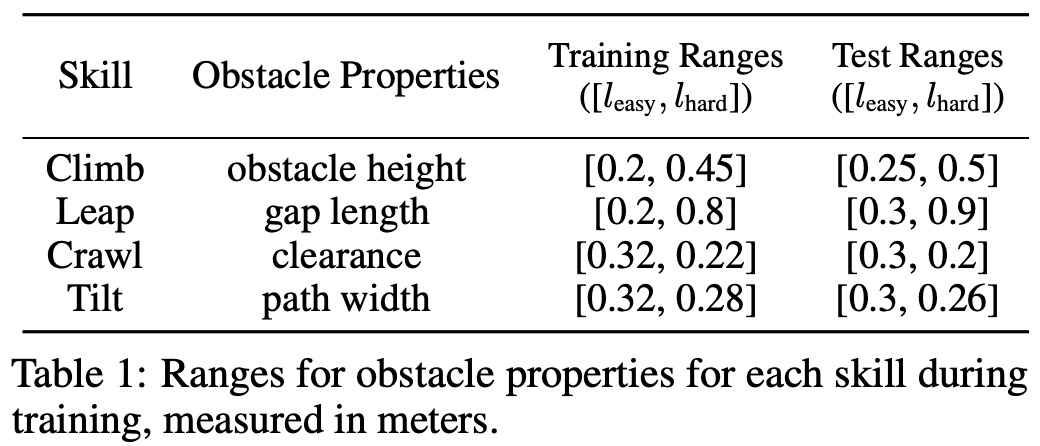
In training, the The study set corresponding obstacle sizes for each skill, as shown in Table 1 below:
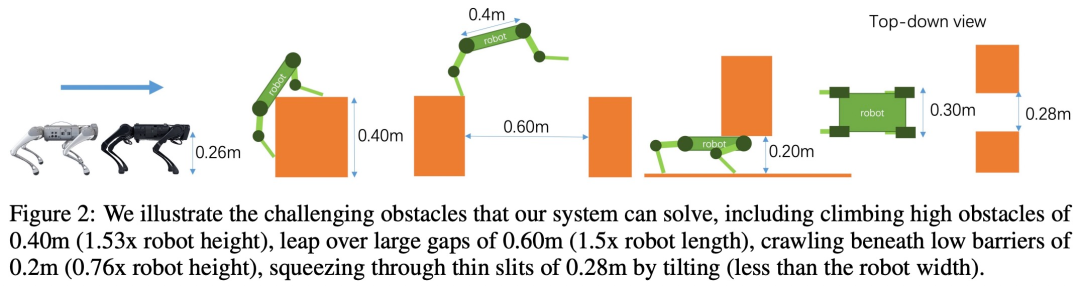
This study conducted a large number of simulations and real-life experiments , the results show that parkour strategies enable low-cost quadruped robots to autonomously select and perform appropriate parkour skills to traverse challenging open-world environments using only onboard computing, onboard visual sensing, and onboard power. , including climbing an obstacle of 0.40m (1.53x robot height), jumping over a large gap of 0.60m (1.5x robot length), crawling under a low obstacle of 0.2m (0.76x robot height), and squeezing through by tilting 0.28m thin gap (less than the width of the robot), and can keep running forward.

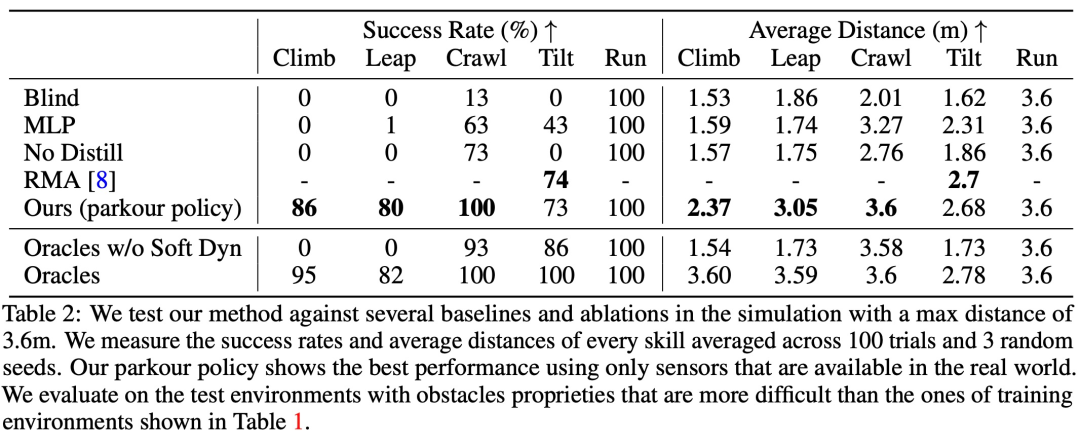
In addition, the study also compared the proposed method with several baseline methods, and Ablation experiments were performed in a simulated environment. The specific results are shown in Table 2:
Interested readers can read the original paper to learn more about the research content
The above is the detailed content of Climbing, jumping, and crossing narrow gaps, open source reinforcement learning strategies allow robot dogs to parkour. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to solve the complexity of WordPress installation and update using Composer
Apr 17, 2025 pm 10:54 PM
How to solve the complexity of WordPress installation and update using Composer
Apr 17, 2025 pm 10:54 PM
When managing WordPress websites, you often encounter complex operations such as installation, update, and multi-site conversion. These operations are not only time-consuming, but also prone to errors, causing the website to be paralyzed. Combining the WP-CLI core command with Composer can greatly simplify these tasks, improve efficiency and reliability. This article will introduce how to use Composer to solve these problems and improve the convenience of WordPress management.
 How to solve SQL parsing problem? Use greenlion/php-sql-parser!
Apr 17, 2025 pm 09:15 PM
How to solve SQL parsing problem? Use greenlion/php-sql-parser!
Apr 17, 2025 pm 09:15 PM
When developing a project that requires parsing SQL statements, I encountered a tricky problem: how to efficiently parse MySQL's SQL statements and extract the key information. After trying many methods, I found that the greenlion/php-sql-parser library can perfectly solve my needs.
 How to solve the problem of PHP project code coverage reporting? Using php-coveralls is OK!
Apr 17, 2025 pm 08:03 PM
How to solve the problem of PHP project code coverage reporting? Using php-coveralls is OK!
Apr 17, 2025 pm 08:03 PM
When developing PHP projects, ensuring code coverage is an important part of ensuring code quality. However, when I was using TravisCI for continuous integration, I encountered a problem: the test coverage report was not uploaded to the Coveralls platform, resulting in the inability to monitor and improve code coverage. After some exploration, I found the tool php-coveralls, which not only solved my problem, but also greatly simplified the configuration process.
 How to solve complex BelongsToThrough relationship problem in Laravel? Use Composer!
Apr 17, 2025 pm 09:54 PM
How to solve complex BelongsToThrough relationship problem in Laravel? Use Composer!
Apr 17, 2025 pm 09:54 PM
In Laravel development, dealing with complex model relationships has always been a challenge, especially when it comes to multi-level BelongsToThrough relationships. Recently, I encountered this problem in a project dealing with a multi-level model relationship, where traditional HasManyThrough relationships fail to meet the needs, resulting in data queries becoming complex and inefficient. After some exploration, I found the library staudenmeir/belongs-to-through, which easily installed and solved my troubles through Composer.
 How to solve the complex problem of PHP geodata processing? Use Composer and GeoPHP!
Apr 17, 2025 pm 08:30 PM
How to solve the complex problem of PHP geodata processing? Use Composer and GeoPHP!
Apr 17, 2025 pm 08:30 PM
When developing a Geographic Information System (GIS), I encountered a difficult problem: how to efficiently handle various geographic data formats such as WKT, WKB, GeoJSON, etc. in PHP. I've tried multiple methods, but none of them can effectively solve the conversion and operational issues between these formats. Finally, I found the GeoPHP library, which easily integrates through Composer, and it completely solved my troubles.
 Solve CSS prefix problem using Composer: Practice of padaliyajay/php-autoprefixer library
Apr 17, 2025 pm 11:27 PM
Solve CSS prefix problem using Composer: Practice of padaliyajay/php-autoprefixer library
Apr 17, 2025 pm 11:27 PM
I'm having a tricky problem when developing a front-end project: I need to manually add a browser prefix to the CSS properties to ensure compatibility. This is not only time consuming, but also error-prone. After some exploration, I discovered the padaliyajay/php-autoprefixer library, which easily solved my troubles with Composer.
 How to solve the problem of virtual columns in Laravel model? Use stancl/virtualcolumn!
Apr 17, 2025 pm 09:48 PM
How to solve the problem of virtual columns in Laravel model? Use stancl/virtualcolumn!
Apr 17, 2025 pm 09:48 PM
During Laravel development, it is often necessary to add virtual columns to the model to handle complex data logic. However, adding virtual columns directly into the model can lead to complexity of database migration and maintenance. After I encountered this problem in my project, I successfully solved this problem by using the stancl/virtualcolumn library. This library not only simplifies the management of virtual columns, but also improves the maintainability and efficiency of the code.
 git software installation tutorial
Apr 17, 2025 pm 12:06 PM
git software installation tutorial
Apr 17, 2025 pm 12:06 PM
Git Software Installation Guide: Visit the official Git website to download the installer for Windows, MacOS, or Linux. Run the installer and follow the prompts. Configure Git: Set username, email, and select a text editor. For Windows users, configure the Git Bash environment.
