
 Technology peripherals
AI
ReLU replaces softmax in visual Transformer, DeepMind's new trick reduces costs rapidly
Technology peripherals
AI
ReLU replaces softmax in visual Transformer, DeepMind's new trick reduces costs rapidly
ReLU replaces softmax in visual Transformer, DeepMind's new trick reduces costs rapidly

The Transformer architecture has been widely used in the field of modern machine learning. The key point is to focus on one of the core components of transformer, which contains a softmax, which is used to generate a probability distribution of tokens. Softmax has a higher cost because it performs exponential calculations and summing sequence lengths, which makes parallelization difficult to perform.
Google DeepMind thought of a new idea: Replace the softmax operation with a new method that does not necessarily output a probability distribution. They also observed that using ReLU divided by the sequence length can approach or rival traditional softmax when used with a visual Transformer.

Paper link: https://arxiv.org/abs/2309.08586
This result Brings new solutions to parallelization, because ReLU can be parallelized in the sequence length dimension, and requires fewer gather operations than traditional ones
Method
The key point is to concentrate
The key point is to concentrate on the function Convert d-dimensional queries, keys and values {q_i, k_i, v_i} through a two-step process
In the first step, it is important to focus on getting the key points by Force weight 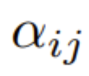 :
:
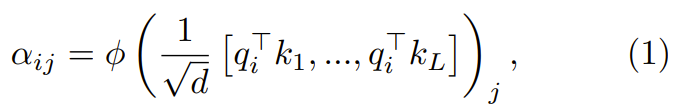
##where ϕ is usually softmax.
The next step, using this focus is to focus on weights to calculate the output This paper explores the use of point-wise calculations as an alternative to ϕ. 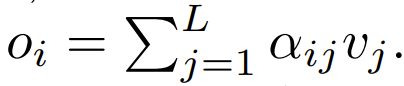
The key point of ReLU is to focus on
DeepMind observed that for ϕ = softmax in Eq. 1, 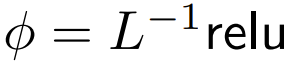 is a better alternative. They will use
is a better alternative. They will use 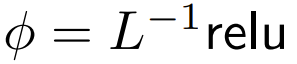 focus is called ReLU.
focus is called ReLU.
Expanded point-by-point focus is to focus
The researchers also experimentally explored more A wide range of 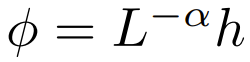 choices, where α ∈ [0, 1] and h ∈ {relu,relu², gelu,softplus, identity,relu6,sigmoid}.
choices, where α ∈ [0, 1] and h ∈ {relu,relu², gelu,softplus, identity,relu6,sigmoid}.
What needs to be rewritten is: the extension of sequence length
They also found that if using a Expanding items with sequence length L can improve accuracy. Previous research work trying to remove softmax has not used this extension scheme
Among the Transformers currently designed to focus on using softmax, there is 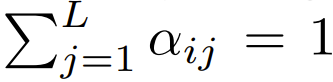 , which means
, which means 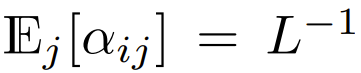 although this is unlikely to be A necessary condition, but
although this is unlikely to be A necessary condition, but 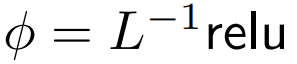 can ensure that the complexity of
can ensure that the complexity of 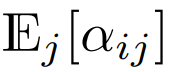 during initialization is
during initialization is 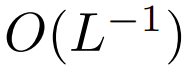 , retain this Conditions may reduce the need to change other hyperparameters when replacing softmax.
, retain this Conditions may reduce the need to change other hyperparameters when replacing softmax.
At the time of initialization, the elements of q and k are O (1), so 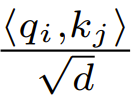 will also be O (1). Activation functions like ReLU maintain O (1), so a factor of
will also be O (1). Activation functions like ReLU maintain O (1), so a factor of 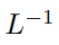 is needed to make
is needed to make 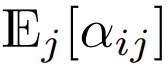 have a complexity of
have a complexity of 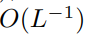 .
.
Experiments and results
Main results
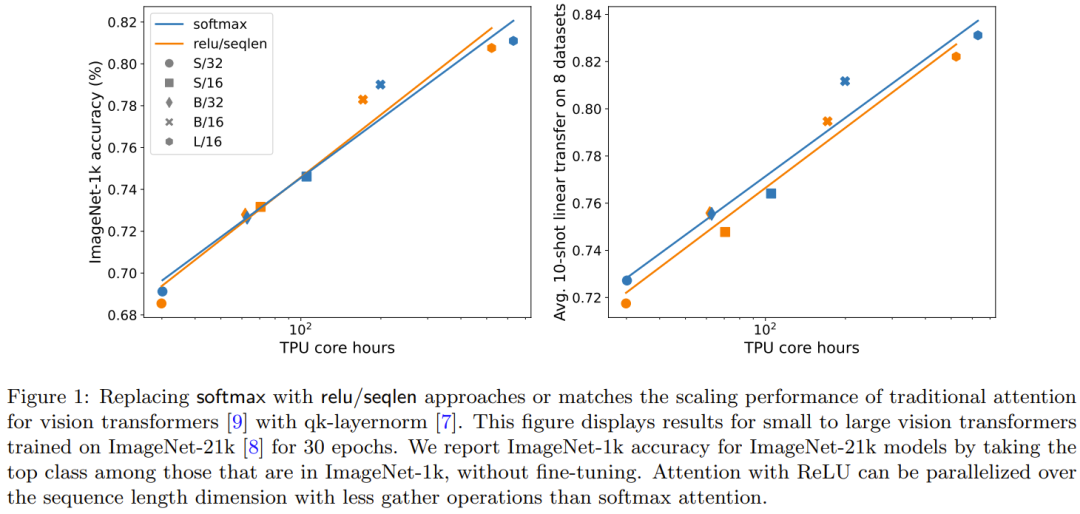
Figure 1 Description In terms of ImageNet-21k training, ReLU focuses on focusing and softmax focuses on the scaling trend. The x-axis shows the total kernel computation time required for the experiment in hours. A big advantage of ReLU is that it can be parallelized in the sequence length dimension, requiring fewer gather operations than softmax.
The content that needs to be rewritten is: the effect of extending the sequence length
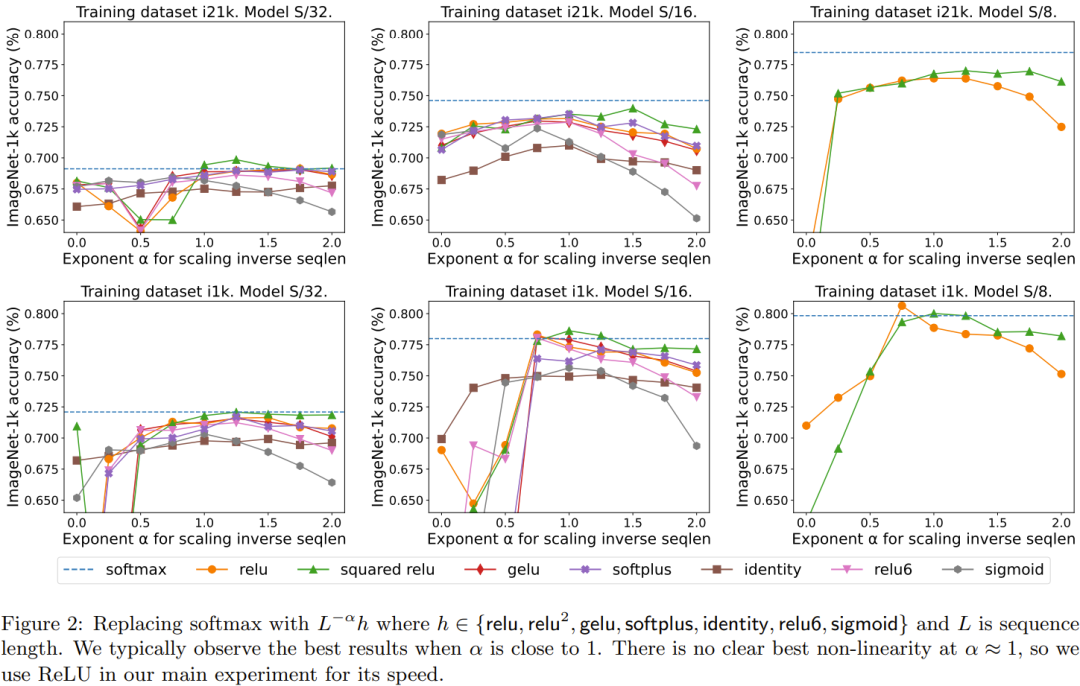
Figure 2 compares what needs to be rewritten: the results of the sequence length extension method and various other point-by-point solutions that replace softmax. Specifically, it is to use relu, relu², gelu, softplus, identity and other methods to replace softmax. The X-axis is α. The Y-axis is the accuracy of the S/32, S/16, and S/8 Vision Transformer models. The best results are usually obtained when α is close to 1. Since there is no clear optimal nonlinearity, they used ReLU in their main experiments because it is faster.
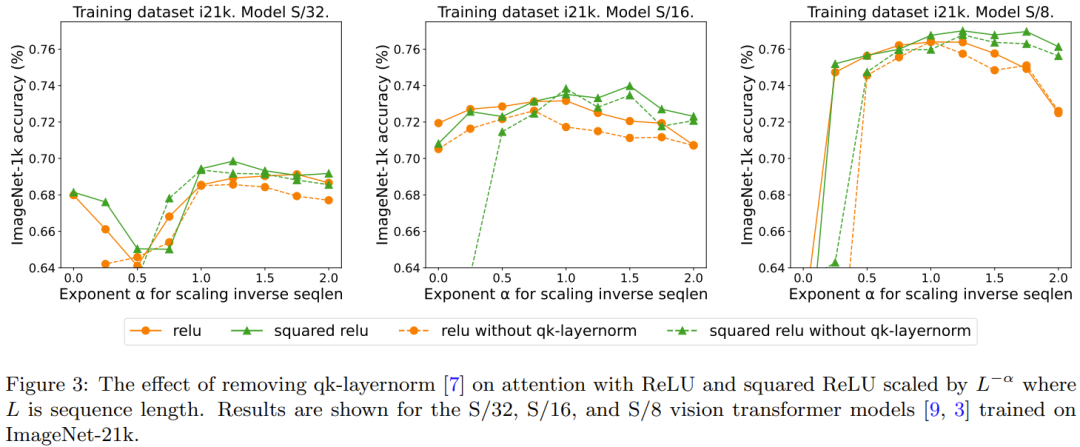
## The effect of qk-layernorm can be restated as follows:
The main experiments used qk-layernorm, where queries and keys are passed through LayerNorm before calculating weights. DeepMind states that the reason for using qk-layernorm by default is that it is necessary to prevent instability when scaling model sizes. Figure 3 shows the impact of removing qk-layernorm. This result indicates that qk-layernorm has little impact on these models, but the situation may be different when the model size becomes larger.
##Redescription: The additional effect of the door Previous research on removing softmax has adopted the method of adding a gating unit, but this method cannot scale with the sequence length. Specifically, in the gated attention unit, there is an additional projection that produces an output that is obtained by an element-wise multiplicative combination before the output projection. Figure 4 explores whether the presence of gates eliminates the need for rewriting what is: an extension of the sequence length. Overall, DeepMind observes that the best accuracy is achieved with or without gates, with and without gates, by requiring rewriting: Sequence length extensions. Also note that for the S/8 model using ReLU, this gating mechanism increases the core time required for the experiment by approximately 9.3%. 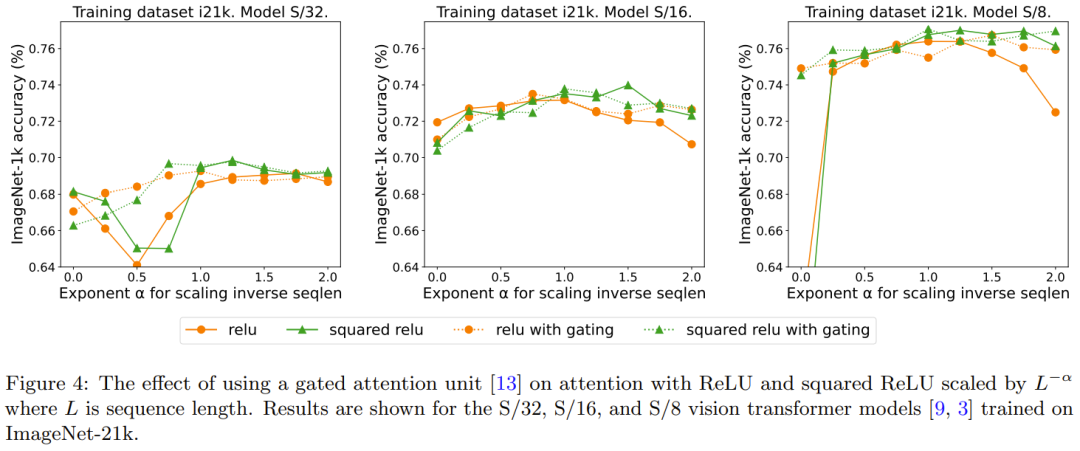
The above is the detailed content of ReLU replaces softmax in visual Transformer, DeepMind's new trick reduces costs rapidly. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Google Pixel 9 Pro XL gets tested with desktop mode
Aug 29, 2024 pm 01:09 PM
Google Pixel 9 Pro XL gets tested with desktop mode
Aug 29, 2024 pm 01:09 PM
Google has introduced DisplayPort Alternate Mode with the Pixel 8 series, and it's present on the newly launched Pixel 9 lineup. While it's mainly there to let you mirror the smartphone display with a connected screen, you can also use it for desktop
 Google AI announces Gemini 1.5 Pro and Gemma 2 for developers
Jul 01, 2024 am 07:22 AM
Google AI announces Gemini 1.5 Pro and Gemma 2 for developers
Jul 01, 2024 am 07:22 AM
Google AI has started to provide developers with access to extended context windows and cost-saving features, starting with the Gemini 1.5 Pro large language model (LLM). Previously available through a waitlist, the full 2 million token context windo
 Google Tensor G4 of Pixel 9 Pro XL lags behind Tensor G2 in Genshin Impact
Aug 24, 2024 am 06:43 AM
Google Tensor G4 of Pixel 9 Pro XL lags behind Tensor G2 in Genshin Impact
Aug 24, 2024 am 06:43 AM
Google recently responded to the performance concerns about the Tensor G4 of the Pixel 9 line. The company said that the SoC wasn't designed to beat benchmarks. Instead, the team focused on making it perform well in the areas where Google wants the c
 Google app beta APK teardown reveals new extensions coming to Gemini AI assistant
Jul 30, 2024 pm 01:06 PM
Google app beta APK teardown reveals new extensions coming to Gemini AI assistant
Jul 30, 2024 pm 01:06 PM
Google's AI assistant, Gemini, is set to become even more capable, if the APK teardown of the latest update (v15.29.34.29 beta) is to be considered. The tech behemoth's new AI assistant could reportedly get several new extensions. These extensions wi
 Google Pixel 9 smartphones will not launch with Android 15 despite seven-year update commitment
Aug 01, 2024 pm 02:56 PM
Google Pixel 9 smartphones will not launch with Android 15 despite seven-year update commitment
Aug 01, 2024 pm 02:56 PM
The Pixel 9 series is almost here, having been scheduled for an August 13 release. Based on recent rumours, the Pixel 9, Pixel 9 Pro and Pixel 9 Pro XL will mirror the Pixel 8 and Pixel 8 Pro (curr. $749 on Amazon) by starting with 128 GB of storage.
 New Google Pixel desktop mode showcased in fresh video as possible Motorola Ready For and Samsung DeX alternative
Aug 08, 2024 pm 03:05 PM
New Google Pixel desktop mode showcased in fresh video as possible Motorola Ready For and Samsung DeX alternative
Aug 08, 2024 pm 03:05 PM
A few months have passed since Android Authority demonstrated a new Android desktop mode that Google had hidden away within Android 14 QPR3 Beta 2.1. Arriving hot on the heels of Google adding DisplayPort Alt Mode support for the Pixel 8 and Pixel 8
 Leaked Google Pixel 9 adverts show new AI features including \'Add Me\' camera functionality
Jul 30, 2024 am 11:18 AM
Leaked Google Pixel 9 adverts show new AI features including \'Add Me\' camera functionality
Jul 30, 2024 am 11:18 AM
More promotional materials relating to the Pixel 9 series have leaked online. For reference, the new leak arrived shortly after 91mobiles shared multiple images that also showcased the Pixel Buds Pro 2 and Pixel Watch 3 or Pixel Watch 3 XL. This time
 Google opens AI Test Kitchen & Imagen 3 to most users
Sep 12, 2024 pm 12:17 PM
Google opens AI Test Kitchen & Imagen 3 to most users
Sep 12, 2024 pm 12:17 PM
Google's AI Test Kitchen, which includes a suite of AI design tools for users to play with, has now opened up to users in well over 100 countries worldwide. This move marks the first time that many around the world will be able to use Imagen 3, Googl
