

Automatic summarization technology has made great progress in recent years, mainly due to the paradigm shift from supervised fine-tuning on annotated datasets to using large language models (LLM) for zero-shot prompts , such as GPT-4. Without additional training, carefully designed prompts enable fine-grained control over summary length, topic, style, and other features
#But one aspect is often overlooked: the information density of the summary. Theoretically, as a compression of another text, a summary should be denser, that is, contain more information, than the source file. Considering the high latency of LLM decoding, it is important to cover more information with fewer words, especially for real-time applications.
However, information density is an open question: if the abstract contains insufficient details, it is equivalent to no information; if it contains too much information, it does not increase the total length. , it becomes difficult to understand. To convey more information within a fixed vocabulary budget, it is necessary to combine abstraction, compression, and fusion
In a recent study, researchers from Salesforce, MIT and other institutions The researchers sought to determine this limit by soliciting human preferences for an increasingly dense set of summaries generated by GPT-4. This method provides a lot of inspiration for improving the "expression ability" of large language models such as GPT-4.

Paper link: https://arxiv.org/pdf/2309.04269.pdf
Data Set address: https://huggingface.co/datasets/griffin/chain_of_density
Specifically, their method uses the average number of entities per tag as a proxy for density, generating An initial, entity-sparse summary. Then, without increasing the total length (the total length is 5 times the original summary), iteratively identifies and fuses 1-3 entities missing from the previous summary, so that the ratio of entities to tags in each summary is higher than Previous summary. Through analysis of human preference data, the authors ultimately identified a form of summarization that is nearly as dense as human-written summaries and denser than summaries generated by the ordinary GPT-4 prompt
The study His overall contributions include:
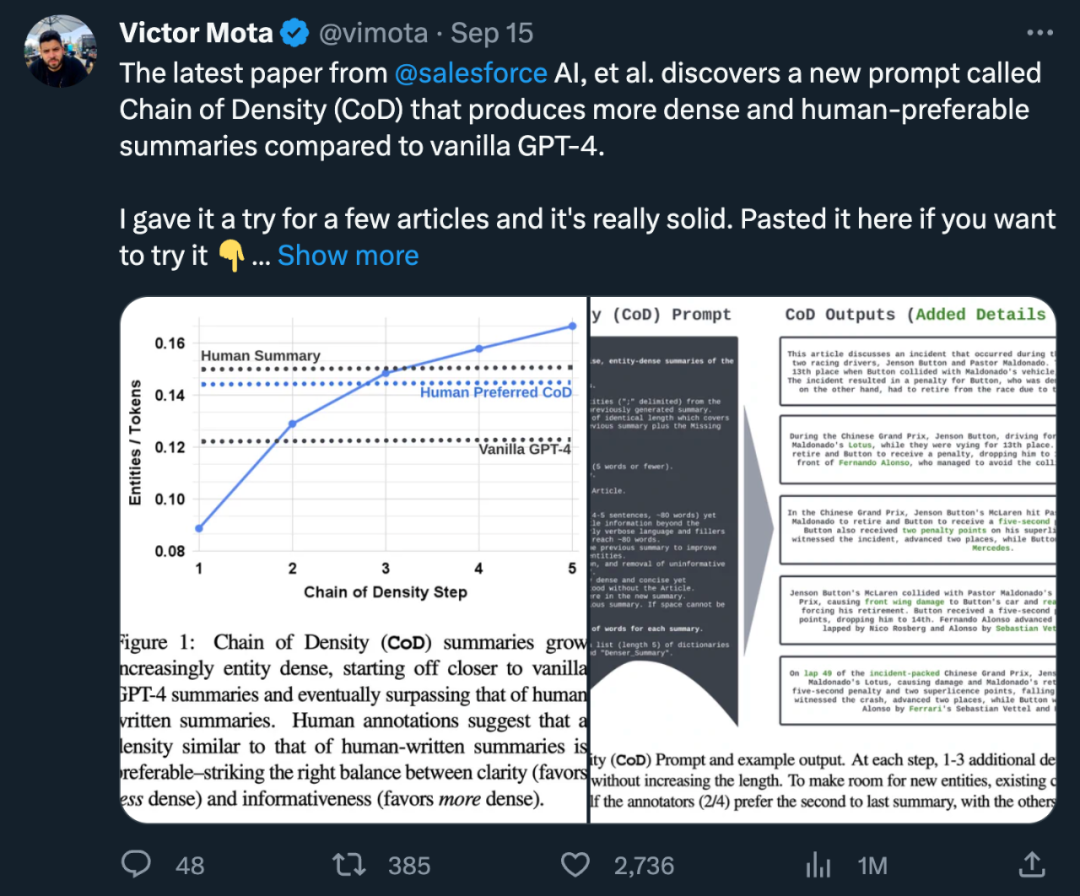
The author set up a game called "CoD" ( Density chain) hint for generating an initial summary and gradually increasing its entity density. Specifically, within a fixed number of interactions, a set of unique salient entities in the source text are identified and merged into the previous summary without increasing the length
In Figure 2, prompt and output examples are shown. The author does not explicitly specify the types of entities, but defines the missing entities as:

The author randomly selected 100 articles from the CNN/DailyMail summary test set and generated CoD summaries for them. . For ease of reference, they compared CoD summary statistics to human-written bullet-point reference summaries and summaries generated by GPT-4 under the normal prompt: "Write a very short summary of the article. No more than 70 words."
In the study, the author summarized from two aspects: direct statistical data and indirect statistical data. Direct statistics (tokens, entities, entity density) are directly controlled by CoD, while indirect statistics are an expected by-product of densification.
The rewritten content is as follows: According to statistics, by removing unnecessary words in lengthy summaries, the average length of the second step was reduced by 5 tokens (from 72 to 67). The initial entity density is 0.089, which is lower than human and vanilla GPT-4 (0.151 and 0.122), and after 5 densification steps, it finally rises to 0.167
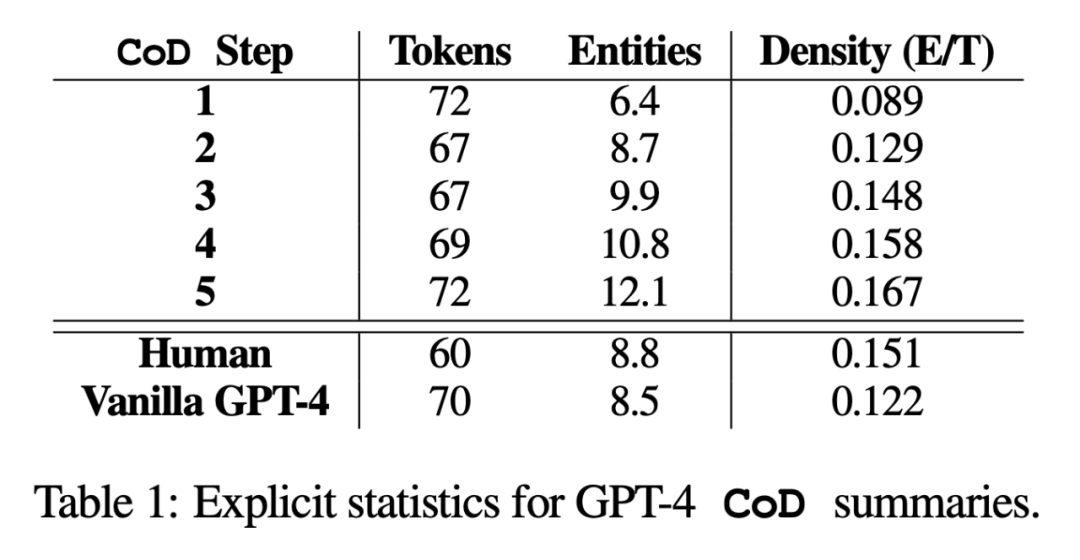
Indirect statistics. The level of abstraction should increase with each step of CoD, as the abstract is repeatedly rewritten to make room for each additional entity. The authors measure abstraction using extraction density: the average square length of extracted fragments (Grusky et al., 2018). Likewise, concept fusion should increase monotonically as entities are added to a fixed-length summary. The authors expressed the degree of integration by the average number of source sentences aligned with each summary sentence. For alignment, the authors use the relative ROUGE gain method (Zhou et al., 2018), which aligns the source sentence with the target sentence until the relative ROUGE gain of the additional sentences is no longer positive. They also expected changes in content distribution, or the position within the article from which the summary content comes.
Specifically, the authors expected that Call of Duty (CoD) summaries would initially show a strong “bootstrapping bias”, i.e., more entities would be introduced at the beginning of the article. However, as the article develops, this guiding bias gradually weakens and entities begin to be introduced from the middle and end of the article. To measure this, we used the alignment results in the fusion and measured the average sentence rank of all aligned source sentences
Figure 3 confirms these hypotheses: with the rewriting step As the number increases, the abstraction also increases (the extraction density on the left is lower), the fusion rate increases (middle image), and the abstract begins to incorporate the content in the middle and end of the article (right image). Interestingly, all CoD summaries are more abstract compared to human-written summaries and baseline summaries
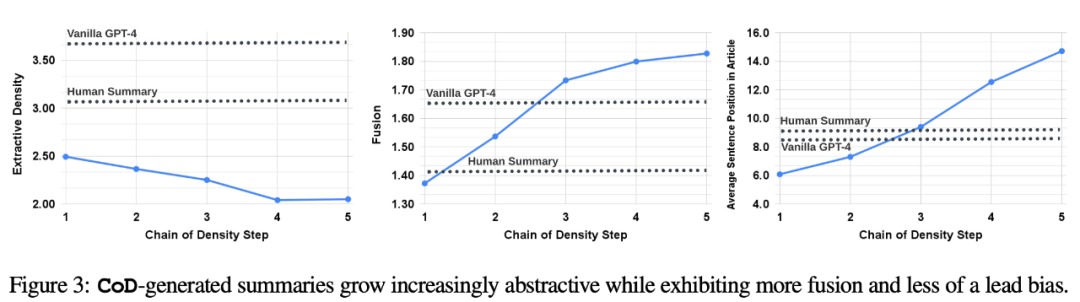
To better understand the trade-offs of CoD summaries, the authors conducted a preference-based human study and conducted a rating-based evaluation utilizing GPT-4
humanpreference. Specifically, for the same 100 articles (5 steps *100 = 500 abstracts in total), the author randomly showed the "re-created" CoD abstracts and articles to the first four authors of the paper. Each annotator gave his or her favorite summary based on Stiennon et al.'s (2020) definition of a "good summary." Table 2 reports the first-place votes of each annotator in the CoD stage, as well as the summary of each annotator. Overall, 61% of first-place abstracts (23.0 22.5 15.5) involved ≥3 densification steps. The median number of preferred CoD steps is in the middle (3), with an expected step number of 3.06.
Based on the average density of the Step 3 summary, it can be roughly inferred that the preferred entity density of all CoD candidates is ∼ 0.15 . As can be seen in Table 1, this density is consistent with human-written summaries (0.151) but significantly higher than summaries written with ordinary GPT-4 prompts (0.122).
Automatic measurement. As a supplement to human evaluation (below), the authors used GPT-4 to score CoD summaries (1-5 points) along 5 dimensions: informativeness, quality, coherence, attributability, and overallness. As shown in Table 3, density correlates with informativeness, but up to a limit, with the score peaking at step 4 (4.74).
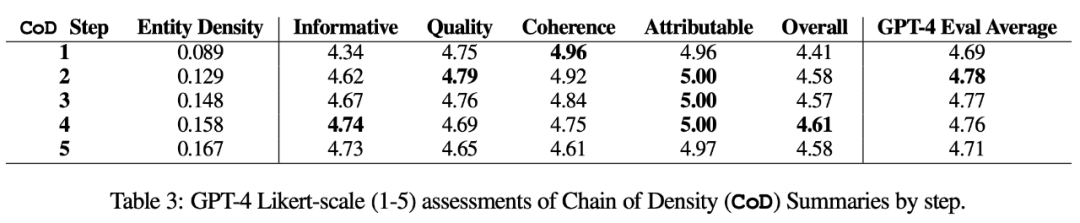
From the average scores of each dimension, the first and last steps of CoD have the lowest scores, while the middle The three steps have close scores (4.78, 4.77 and 4.76 respectively).
Qualitative analysis. There is a clear trade-off between coherence/readability and informativeness of the abstract. Figure 4 shows two CoD steps: one step's summary is improved by more details, while the other step's summary is compromised. Overall, intermediate CoD summaries are able to achieve this balance, but this trade-off still needs to be precisely defined and quantified in future work

For more details of the paper, please refer to the original paper.
The above is the detailed content of 'Few words, large amount of information', Salesforce and MIT researchers teach GPT-4 'revision', the data set has been open source. For more information, please follow other related articles on the PHP Chinese website!
 How to bind data in dropdownlist
How to bind data in dropdownlist
 What's going on when phpmyadmin can't access it?
What's going on when phpmyadmin can't access it?
 Detailed explanation of netsh command usage
Detailed explanation of netsh command usage
 Computer application areas
Computer application areas
 C language data structure
C language data structure
 Five major components of a von Neumann computer
Five major components of a von Neumann computer
 How to match numbers in regular expressions
How to match numbers in regular expressions
 Introduction to ftp server usage
Introduction to ftp server usage








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



