
 Technology peripherals
AI
Zhiyuan has opened 300 million semantic vector model training data, and the BGE model continues to be iteratively updated.
Technology peripherals
AI
Zhiyuan has opened 300 million semantic vector model training data, and the BGE model continues to be iteratively updated.
Zhiyuan has opened 300 million semantic vector model training data, and the BGE model continues to be iteratively updated.

With the rapid development and application of large-scale models, the importance of Embedding, which is the core basic component of large-scale models, has become more and more prominent. The open source commercially available Chinese-English semantic vector model BGE (BAAI General Embedding) released by Zhiyuan Company a month ago has attracted widespread attention in the community, and has been downloaded hundreds of thousands of times on the Hugging Face platform. Currently, BGE has rapidly iteratively launched version 1.5 and announced multiple updates. Among them, BGE has open sourced 300 million pieces of large-scale training data for the first time, providing the community with help in training similar models and promoting the development of technology in this field
- MTP Data set link: https://data.baai.ac.cn/details/BAAI-MTP
- BGE model link: https://huggingface.co /BAAI
- BGE code repository: https://www.php.cn/link /8944871f1c9865a77a3d9c92cadf124d
##3 billion Chinese and English vector model training data open
The first open source semantic vector in the industry The model training data reaches 300 million pieces of Chinese and English data
BGE’s outstanding capabilities largely stem from its large-scale and diverse training data. Previously, industry peers had rarely released similar data sets. In this update, Zhiyuan opens BGE training data to the community for the first time, laying the foundation for further development of this type of technology.
The data set MTP released this time consists of a total of 300 million Chinese and English related text pairs. Among them, there are 100 million records in Chinese and 200 million records in English. The sources of data include Wudao Corpora, Pile, DuReader, Sentence Transformer and other corpora. After necessary sampling, extraction and cleaning,
is obtained. For details, please refer to Data Hub: https://data.baai.ac.cn
MTP is the largest open source Chinese-English related text pair data set to date, providing an important foundation for training Chinese and English semantic vector models.
In response to the developer community, BGE function upgrade
Based on community feedback, BGE has been further optimized based on its version 1.0, making Its performance is more stable and outstanding. The specific upgrade content is as follows:
- Model update. BGE-*-zh-v1.5 alleviates the similarity distribution problem by filtering the training data, deleting low-quality data, and increasing the temperature coefficient during training to 0.02, making the similarity value more stable.
- New model. The open source BGE-reranker cross-encoder model can find relevant text more accurately and supports Chinese and English bilingual. Different from vector models that need to output vectors, BGE-reranker directly outputs similarity between text pairs and has higher ranking accuracy. It can be used to reorder vector recall results and improve the relevance of the final results.
- new features. BGE1.1 adds difficult-to-negative sample mining scripts. Hard-to-negative samples can effectively improve the retrieval effect after fine-tuning; the function of adding instructions during fine-tuning is added to the fine-tuning code; model saving will also be automatically converted into sentence transformer format, making it easier to load the model. .
It is worth mentioning that recently, Zhiyuan and Hugging Face released a technical report, which proposed using C-Pack to enhance the Chinese universal semantic vector model.
《C-Pack: Packaged Resources To Advance General Chinese Embedding》
Link: https://arxiv.org/pdf/2309.07597 .pdf
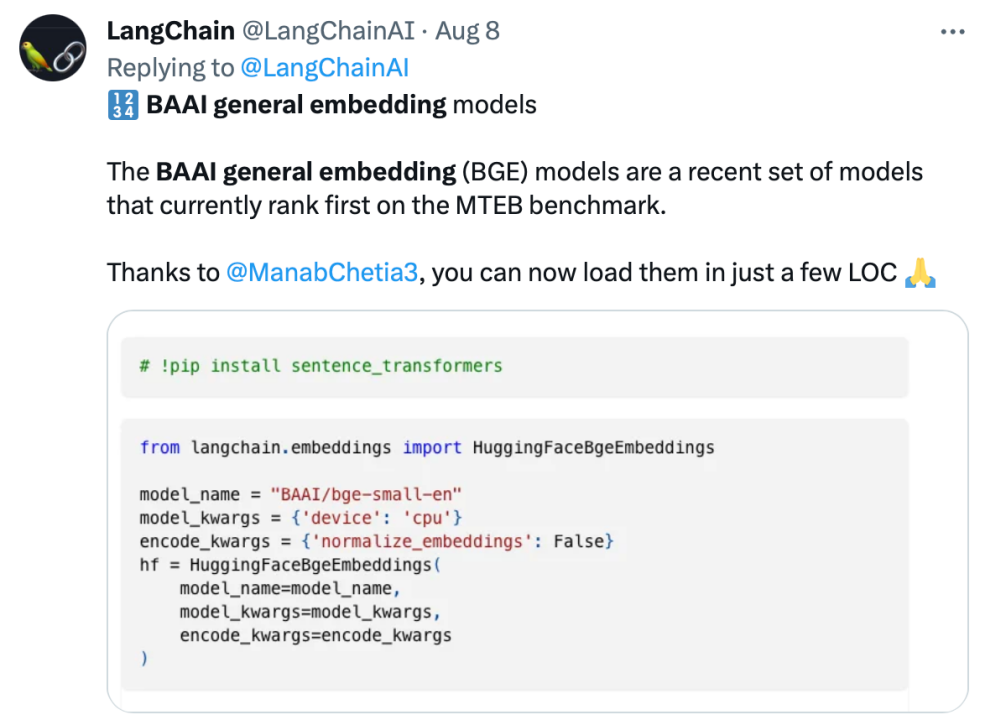
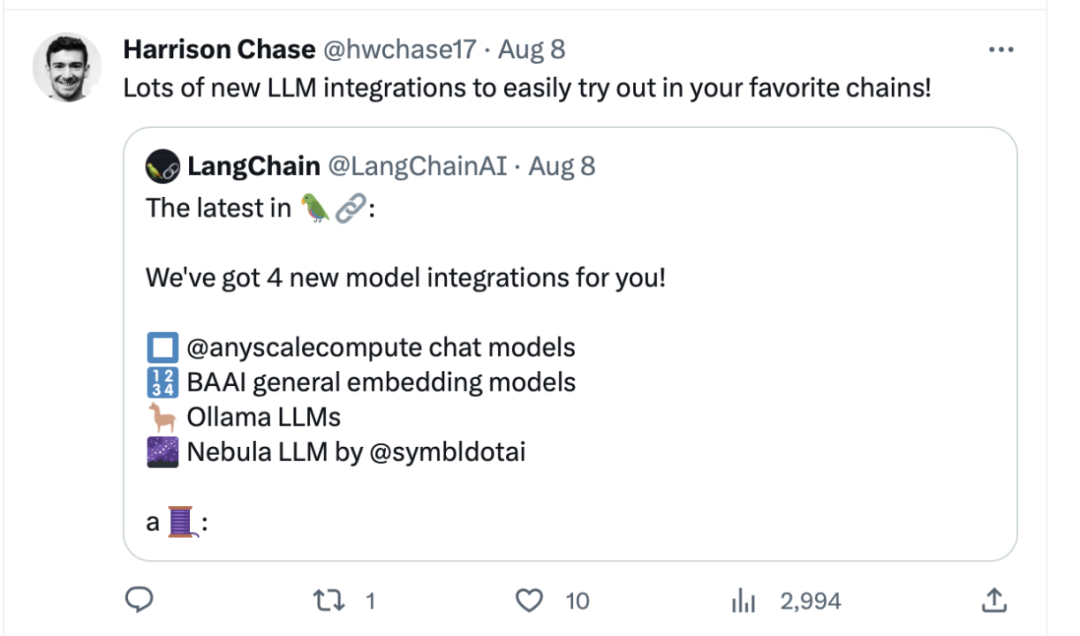
##Gaining high popularity in the developer communityBGE has attracted the attention of the large model developer community since its release. Currently, Hugging Face The number of downloads has reached hundreds of thousands of times, and it has been integrated and used by well-known open source projects LangChain, LangChain-Chachat, llama_index, etc.
Langchain official, LangChain co-founder and CEO Official Harrison Chase, Deep trading founder Yam Peleg and other community influencers expressed concern about BGE.
Adhere to open source and promote collaborative innovation, Zhiyuan large model technology development system FlagOpen BGE has added a new FlagEmbedding section, focusing on Embedding technology and models. BGE is one of the high-profile open source projects. FlagOpen is committed to building artificial intelligence technology infrastructure in the era of large models, and will continue to open more complete large model full-stack technologies to academia and industry in the future
The above is the detailed content of Zhiyuan has opened 300 million semantic vector model training data, and the BGE model continues to be iteratively updated.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1392
1392
 52
52

 Web3 trading platform ranking_Web3 global exchanges top ten summary
Apr 21, 2025 am 10:45 AM
Web3 trading platform ranking_Web3 global exchanges top ten summary
Apr 21, 2025 am 10:45 AM
Binance is the overlord of the global digital asset trading ecosystem, and its characteristics include: 1. The average daily trading volume exceeds $150 billion, supports 500 trading pairs, covering 98% of mainstream currencies; 2. The innovation matrix covers the derivatives market, Web3 layout and education system; 3. The technical advantages are millisecond matching engines, with peak processing volumes of 1.4 million transactions per second; 4. Compliance progress holds 15-country licenses and establishes compliant entities in Europe and the United States.
 Top 10 cryptocurrency exchange platforms The world's largest digital currency exchange list
Apr 21, 2025 pm 07:15 PM
Top 10 cryptocurrency exchange platforms The world's largest digital currency exchange list
Apr 21, 2025 pm 07:15 PM
Exchanges play a vital role in today's cryptocurrency market. They are not only platforms for investors to trade, but also important sources of market liquidity and price discovery. The world's largest virtual currency exchanges rank among the top ten, and these exchanges are not only far ahead in trading volume, but also have their own advantages in user experience, security and innovative services. Exchanges that top the list usually have a large user base and extensive market influence, and their trading volume and asset types are often difficult to reach by other exchanges.
 'Black Monday Sell' is a tough day for the cryptocurrency industry
Apr 21, 2025 pm 02:48 PM
'Black Monday Sell' is a tough day for the cryptocurrency industry
Apr 21, 2025 pm 02:48 PM
The plunge in the cryptocurrency market has caused panic among investors, and Dogecoin (Doge) has become one of the hardest hit areas. Its price fell sharply, and the total value lock-in of decentralized finance (DeFi) (TVL) also saw a significant decline. The selling wave of "Black Monday" swept the cryptocurrency market, and Dogecoin was the first to be hit. Its DeFiTVL fell to 2023 levels, and the currency price fell 23.78% in the past month. Dogecoin's DeFiTVL fell to a low of $2.72 million, mainly due to a 26.37% decline in the SOSO value index. Other major DeFi platforms, such as the boring Dao and Thorchain, TVL also dropped by 24.04% and 20, respectively.
 WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) stands out in the cryptocurrency market with its unique biometric verification and privacy protection mechanisms, attracting the attention of many investors. WLD has performed outstandingly among altcoins with its innovative technologies, especially in combination with OpenAI artificial intelligence technology. But how will the digital assets behave in the next few years? Let's predict the future price of WLD together. The 2025 WLD price forecast is expected to achieve significant growth in WLD in 2025. Market analysis shows that the average WLD price may reach $1.31, with a maximum of $1.36. However, in a bear market, the price may fall to around $0.55. This growth expectation is mainly due to WorldCoin2.
 Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
In the volatile cryptocurrency market, investors are looking for alternatives that go beyond popular currencies. Although well-known cryptocurrencies such as Solana (SOL), Cardano (ADA), XRP and Dogecoin (DOGE) also face challenges such as market sentiment, regulatory uncertainty and scalability. However, a new emerging project, RexasFinance (RXS), is emerging. It does not rely on celebrity effects or hype, but focuses on combining real-world assets (RWA) with blockchain technology to provide investors with an innovative way to invest. This strategy makes it hoped to be one of the most successful projects of 2025. RexasFi
 What are the top ten platforms in the currency exchange circle?
Apr 21, 2025 pm 12:21 PM
What are the top ten platforms in the currency exchange circle?
Apr 21, 2025 pm 12:21 PM
The top exchanges include: 1. Binance, the world's largest trading volume, supports 600 currencies, and the spot handling fee is 0.1%; 2. OKX, a balanced platform, supports 708 trading pairs, and the perpetual contract handling fee is 0.05%; 3. Gate.io, covers 2700 small currencies, and the spot handling fee is 0.1%-0.3%; 4. Coinbase, the US compliance benchmark, the spot handling fee is 0.5%; 5. Kraken, the top security, and regular reserve audit.
 Web3 social media platform TOX collaborates with Omni Labs to integrate AI infrastructure
Apr 21, 2025 pm 07:06 PM
Web3 social media platform TOX collaborates with Omni Labs to integrate AI infrastructure
Apr 21, 2025 pm 07:06 PM
Decentralized social media platform Tox has reached a strategic partnership with OmniLabs, a leader in artificial intelligence infrastructure solutions, to integrate artificial intelligence capabilities into the Web3 ecosystem. This partnership is published by Tox's official X account and aims to build a fairer and smarter online environment. OmniLabs is known for its intelligent autonomous systems, with its AI-as-a-service (AIaaS) capability supporting numerous DeFi and NFT protocols. Its infrastructure uses AI agents for real-time decision-making, automated processes and in-depth data analysis, aiming to seamlessly integrate into the decentralized ecosystem to empower the blockchain platform. The collaboration with Tox will make OmniLabs' AI tools more extensive, by integrating them into decentralized social networks,
 Ranking of leveraged exchanges in the currency circle The latest recommendations of the top ten leveraged exchanges in the currency circle
Apr 21, 2025 pm 11:24 PM
Ranking of leveraged exchanges in the currency circle The latest recommendations of the top ten leveraged exchanges in the currency circle
Apr 21, 2025 pm 11:24 PM
The platforms that have outstanding performance in leveraged trading, security and user experience in 2025 are: 1. OKX, suitable for high-frequency traders, providing up to 100 times leverage; 2. Binance, suitable for multi-currency traders around the world, providing 125 times high leverage; 3. Gate.io, suitable for professional derivatives players, providing 100 times leverage; 4. Bitget, suitable for novices and social traders, providing up to 100 times leverage; 5. Kraken, suitable for steady investors, providing 5 times leverage; 6. Bybit, suitable for altcoin explorers, providing 20 times leverage; 7. KuCoin, suitable for low-cost traders, providing 10 times leverage; 8. Bitfinex, suitable for senior play
