
 Technology peripherals
AI
Google DeepMind: Combining large models with reinforcement learning to create an intelligent brain for robots to perceive the world
Technology peripherals
AI
Google DeepMind: Combining large models with reinforcement learning to create an intelligent brain for robots to perceive the world
Google DeepMind: Combining large models with reinforcement learning to create an intelligent brain for robots to perceive the world

When developing robot learning methods, if large and diverse data sets can be integrated and combined with powerful expressive models (such as Transformer), then it is expected to develop generalization capabilities and widely applicable strategies so that robots can learn to handle a variety of different tasks well. For example, these strategies allow robots to follow natural language instructions, perform multi-stage behaviors, adapt to various environments and goals, and even apply to different robot forms.
However, the powerful models that have recently appeared in the field of robot learning are all trained using supervised learning methods. Therefore, the performance of the resulting strategy is limited by the extent to which human demonstrators can provide high-quality demonstration data. There are two reasons for this restriction.
- First, we want robotic systems to be more proficient than human teleoperators, leveraging the full potential of the hardware to complete tasks quickly, smoothly, and reliably.
- Second, we hope that the robot system will be better at automatically accumulating experience, rather than relying entirely on high-quality demonstrations.
In principle, reinforcement learning can provide these two abilities at the same time.
There have been some promising developments recently, showing that large-scale robot reinforcement learning can be successful in a variety of application scenarios, such as robots’ grabbing and stacking capabilities, and learning with human-specified Different tasks with rewards, learning multi-task strategies, learning goal-based strategies, and robot navigation. However, research shows that if reinforcement learning is used to train powerful models such as Transformer, it is more difficult to effectively instantiate at scale
Google DeepMind recently proposed Q-Transformer, which aims to Combining large-scale robot learning based on diverse real-world data sets with a modern policy architecture based on powerful Transformers

- Thesis: https://q-transformer.github.io/assets/q-transformer.pdf
- Project: https: //q-transformer.github.io/
Although in principle, using Transformer directly to replace the existing architecture ( Such as ResNets or smaller convolutional neural networks) are conceptually simple, but designing a scheme that can effectively utilize this architecture is very difficult. Large models are only effective when they can use large and diverse data sets - small, narrow models do not require and benefit from this ability
Although there have been previous studies using simulated data to create such datasets, the most representative data comes from the real world.
Therefore, DeepMind stated that the focus of this research is to utilize Transformer through offline reinforcement learning and integrate previously collected large data sets
Offline reinforcement Learning methods are trained using previously available data, with the goal of deriving the most effective possible strategy based on a given data set. Of course, this dataset can also be enhanced with additional automatically collected data, but the training process is separate from the data collection process, which provides an additional workflow for large-scale robotic applications
In terms of using the Transformer model to implement reinforcement learning, another big problem is designing a reinforcement learning system that can effectively train this model. Effective offline reinforcement learning methods usually perform Q-function estimation through time-difference updates. Since Transformer models a discrete token sequence, the Q function estimation problem can be converted into a discrete token sequence modeling problem, and an appropriate loss function can be designed for each token in the sequence.
The method adopted by DeepMind is a discretization scheme by dimension. This is to avoid the exponential explosion of the action base. Specifically, each dimension of the action space is treated as an independent time step in reinforcement learning. Different bins in the discretization correspond to different actions. This dimensionally discretized scheme allows us to use a simple discrete action Q-learning method with a conservative regularizer to handle distribution transitions
DeepMind proposes a specialized A regularizer that aims to minimize the value of unused actions. Research shows that this method can effectively learn a narrow range of demo-like data, and can also learn a wider range of data with exploration noise
Finally, they also used a hybrid update mechanism that combined Monte Carlo and n-step regression with temporal difference backups. The results show that this approach can improve the performance of Transformer-based offline reinforcement learning methods on large-scale robot learning problems.
The main contribution of this research is Q-Transformer, which is a method for offline reinforcement learning of robots based on the Transformer architecture. Q-Transformer tokenizes Q-values by dimension and has been successfully applied to large-scale and diverse robotics datasets, including real-world data. Figure 1 shows the components of Q-Transformer

DeepMind conducted experimental evaluations, including simulation experiments and large-scale real-world experiments, aiming for rigorous comparison and actual verification. Among them, we adopted a large-scale text-based multi-task strategy for learning and verified the effectiveness of Q-Transformer
In real-world experiments, the data set they used contained 38,000 successful demonstrations and 20,000 failed automatically collected scenarios. The data was collected by 13 robots on more than 700 tasks. Q-Transformer outperforms previously proposed architectures for large-scale robotic reinforcement learning, as well as Transformer-based models such as the previously proposed Decision Transformer.
Method overview
In order to use Transformer for Q learning, DeepMind takes the approach of discretizing and autoregressive processing of the action space
To learn a Q function using TD learning, the classic method is based on the Bellman update rule
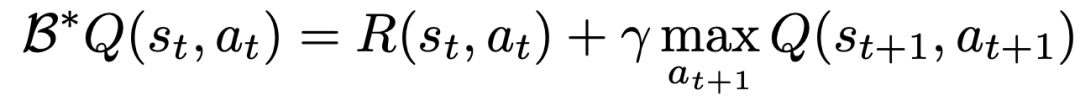
##The researchers modified the Bellman update so that it can be performed for each action dimension by converting the original MDP of the problem into an MDP in which each action dimension is treated as a step of Q-learning.
Specifically, for a given action dimension d_A, the new Bellman update rule can be expressed as:
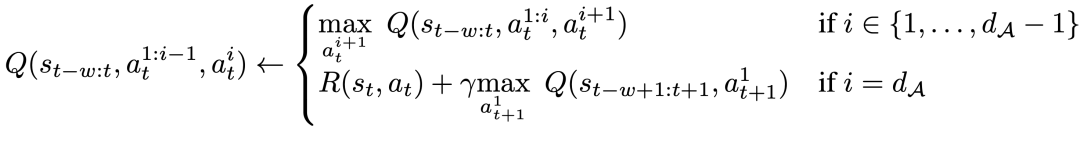
This means that for each intermediate action dimension, maximize the next action dimension given the same state, and for the last action dimension, use the next state's An action dimension. This decomposition ensures that the maximization in the Bellman update remains tractable, while also ensuring that the original MDP problem can still be solved.
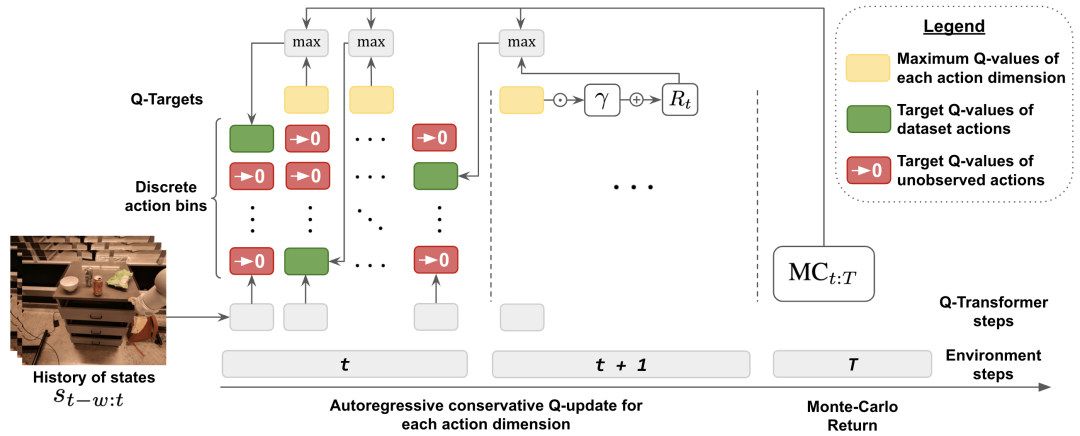
In order to take into account distribution changes during the offline learning process, DeepMind also introduced a simple regularization technology, It is to minimize the value of unseen actions.
In order to speed up learning, they also used the Monte Carlo return method. This approach not only uses return-to-go for a given episode, but also uses n-step returns that can skip dimensionally maximized
Experimental results
In experiments, DeepMind evaluated Q-Transformer, covering a range of real-world tasks. At the same time, they also limited the data to only 100 human demos per task
In the demos, in addition to the demos, they also added automatically collected failures Event fragments to create a dataset. This dataset contains 38,000 positive examples from the demo and 20,000 automatically collected negative examples
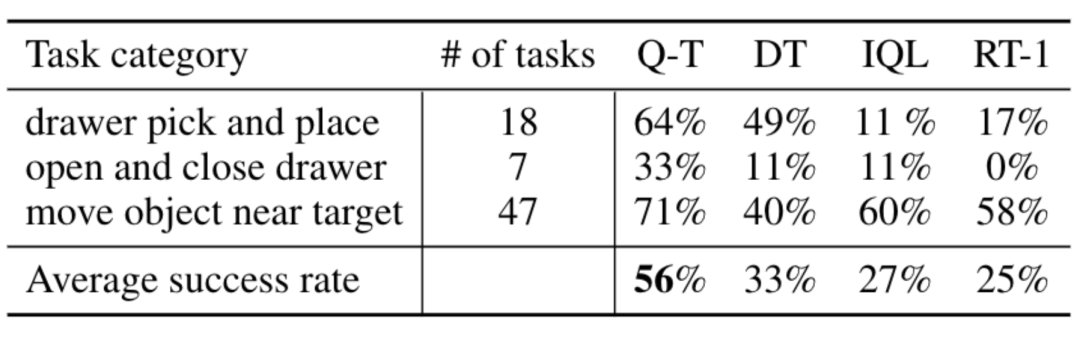

Compared to baseline methods such as RT-1, IQL, and Decision Transformer (DT), Q-Transformer can effectively utilize automatic event fragments to significantly improve its ability to use skills, including from the drawer Pick up and place objects, move objects near the target, and open and close drawers.
The researchers also tested the newly proposed method on a difficult simulated object retrieval task - in this task, only about 8% of the data were positive examples. The rest are noisy negative examples.
In this task, Q-learning methods such as QT-Opt, IQL, AW-Opt and Q-Transformer usually perform better because they are able to leverage dynamic programming to learn the policy, And use negative examples to optimize
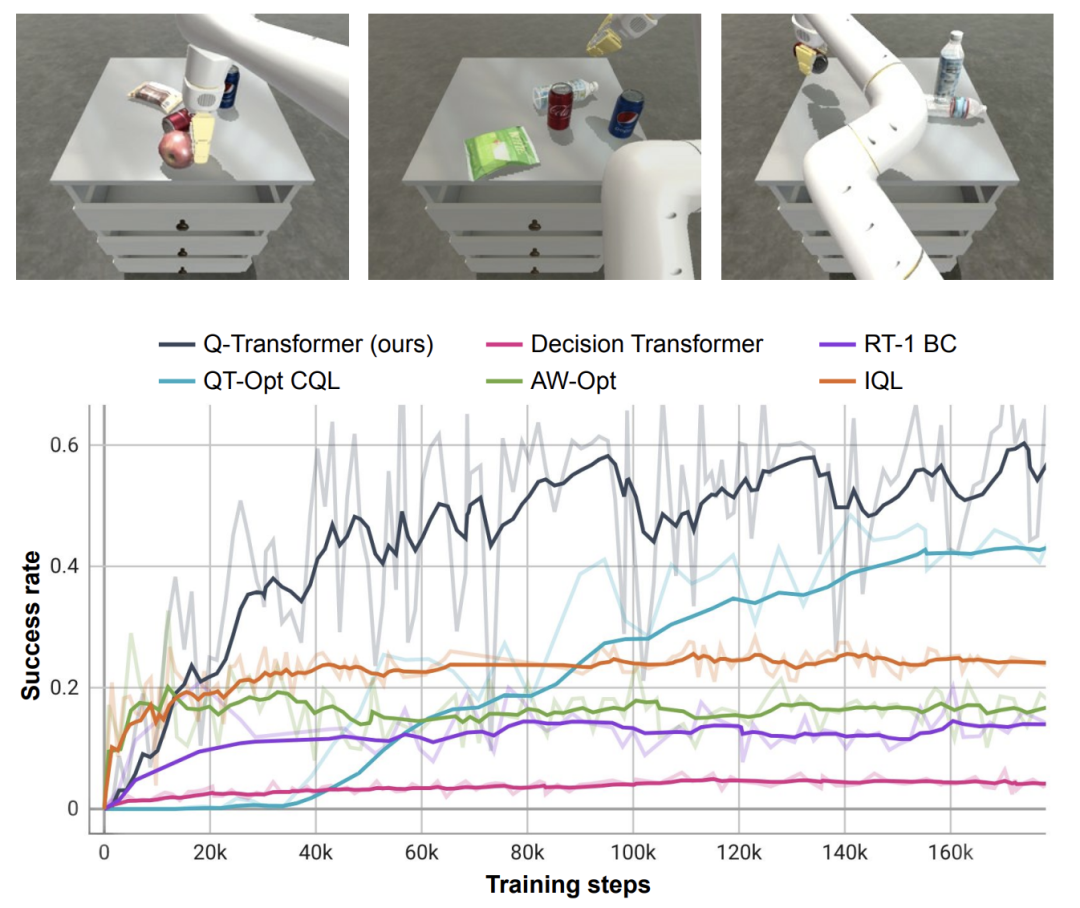
Based on this object-retrieval task, the researchers conducted an ablation experiment and found that conservative Both the regularizer and MC return are important to maintain performance. Performance is significantly worse if you switch to the Softmax regularizer, as this restricts the policy too much to the data distribution. This shows that the regularizer selected by DeepMind here can better cope with this task.
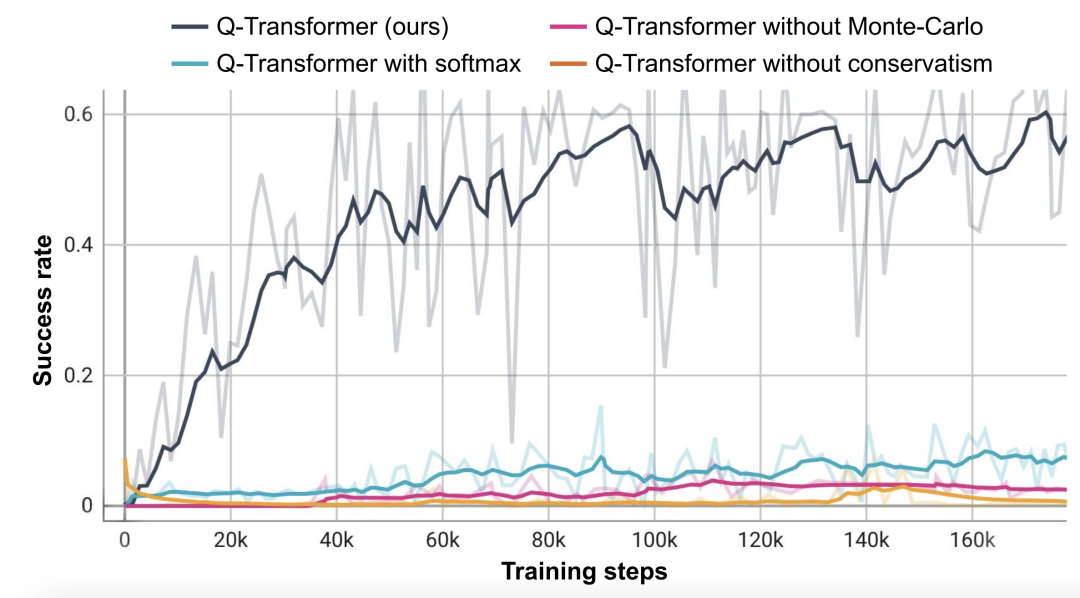
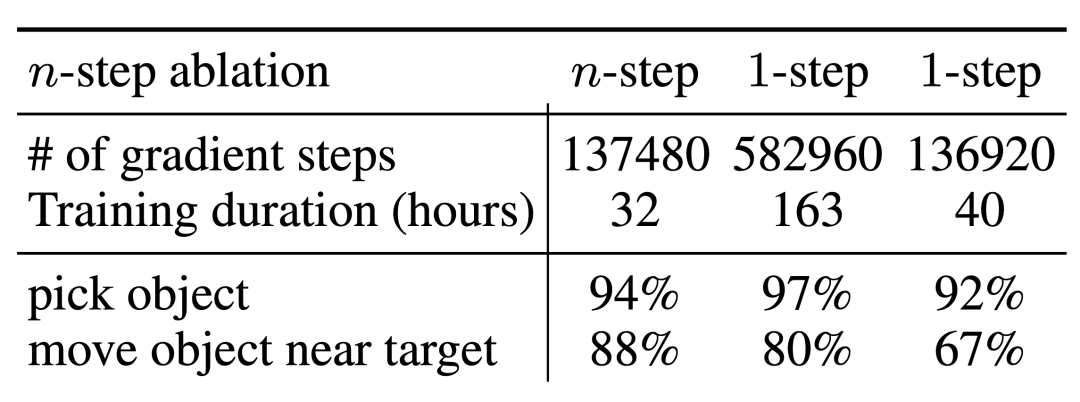
Their ablation experiments on n-step return found that although this may introduce bias, this method can Achieve equivalent high performance in significantly fewer gradient steps, effectively handling many problems
The researchers also tried Run Q-Transformer on larger datasets. They expanded the number of positive examples to 115,000 and the number of negative examples to 185,000, resulting in a data set containing 300,000 event clips. Using this large dataset, Q-Transformer is still able to learn and perform even better than the RT-1 BC benchmark

Finally, they combined the Q-function trained by Q-Transformer as an affordance model with a language planner, similar to SayCan
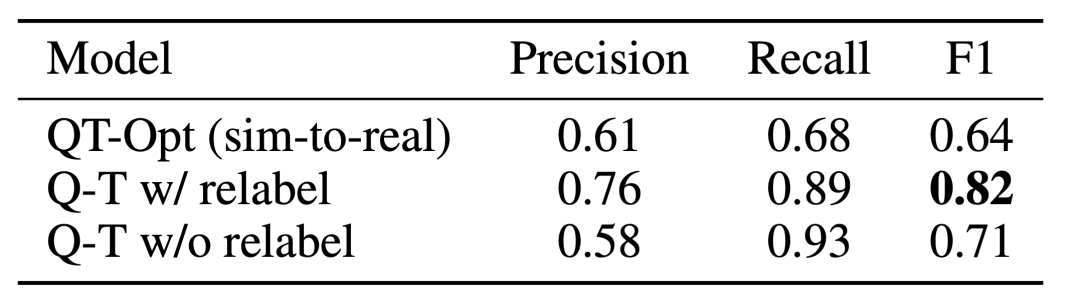
The effect of Q-Transformer affordance estimation is due to the previous Q function trained using QT-Opt; if the unsampled tasks are re-labeled as negative examples of the current task during training, the effect It can be better. Since Q-Transformer does not require the sim-to-real training used by QT-Opt training, it is easier to use Q-Transformer if a suitable simulation is lacking.
In order to test the complete "planning execution" system, they experimented with using Q-Transformer for simultaneous availability estimation and actual policy execution, and the results showed that it was better than the previous QT-Opt Combined with RT-1.
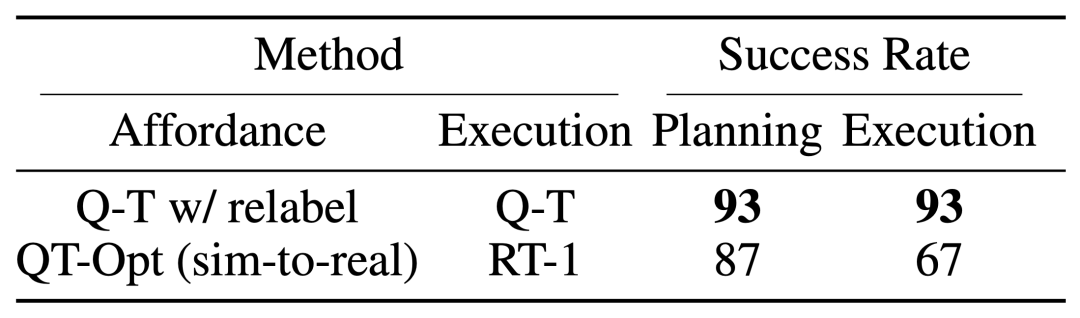
It can be observed from the example of the task affordance value of the given image that the Q-Transformer in the downstream " High-quality affordance values can be provided in the "Planning Execution" framework
Please read the original text for more details
The above is the detailed content of Google DeepMind: Combining large models with reinforcement learning to create an intelligent brain for robots to perceive the world. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1371
1371
 52
52

 What method is used to convert strings into objects in Vue.js?
Apr 07, 2025 pm 09:39 PM
What method is used to convert strings into objects in Vue.js?
Apr 07, 2025 pm 09:39 PM
When converting strings to objects in Vue.js, JSON.parse() is preferred for standard JSON strings. For non-standard JSON strings, the string can be processed by using regular expressions and reduce methods according to the format or decoded URL-encoded. Select the appropriate method according to the string format and pay attention to security and encoding issues to avoid bugs.
 Vue and Element-UI cascade drop-down box v-model binding
Apr 07, 2025 pm 08:06 PM
Vue and Element-UI cascade drop-down box v-model binding
Apr 07, 2025 pm 08:06 PM
Vue and Element-UI cascaded drop-down boxes v-model binding common pit points: v-model binds an array representing the selected values at each level of the cascaded selection box, not a string; the initial value of selectedOptions must be an empty array, not null or undefined; dynamic loading of data requires the use of asynchronous programming skills to handle data updates in asynchronously; for huge data sets, performance optimization techniques such as virtual scrolling and lazy loading should be considered.
 How to set the timeout of Vue Axios
Apr 07, 2025 pm 10:03 PM
How to set the timeout of Vue Axios
Apr 07, 2025 pm 10:03 PM
In order to set the timeout for Vue Axios, we can create an Axios instance and specify the timeout option: In global settings: Vue.prototype.$axios = axios.create({ timeout: 5000 }); in a single request: this.$axios.get('/api/users', { timeout: 10000 }).
 Laravel's geospatial: Optimization of interactive maps and large amounts of data
Apr 08, 2025 pm 12:24 PM
Laravel's geospatial: Optimization of interactive maps and large amounts of data
Apr 08, 2025 pm 12:24 PM
Efficiently process 7 million records and create interactive maps with geospatial technology. This article explores how to efficiently process over 7 million records using Laravel and MySQL and convert them into interactive map visualizations. Initial challenge project requirements: Extract valuable insights using 7 million records in MySQL database. Many people first consider programming languages, but ignore the database itself: Can it meet the needs? Is data migration or structural adjustment required? Can MySQL withstand such a large data load? Preliminary analysis: Key filters and properties need to be identified. After analysis, it was found that only a few attributes were related to the solution. We verified the feasibility of the filter and set some restrictions to optimize the search. Map search based on city
 Vue.js How to convert an array of string type into an array of objects?
Apr 07, 2025 pm 09:36 PM
Vue.js How to convert an array of string type into an array of objects?
Apr 07, 2025 pm 09:36 PM
Summary: There are the following methods to convert Vue.js string arrays into object arrays: Basic method: Use map function to suit regular formatted data. Advanced gameplay: Using regular expressions can handle complex formats, but they need to be carefully written and considered. Performance optimization: Considering the large amount of data, asynchronous operations or efficient data processing libraries can be used. Best practice: Clear code style, use meaningful variable names and comments to keep the code concise.
 How to use mysql after installation
Apr 08, 2025 am 11:48 AM
How to use mysql after installation
Apr 08, 2025 am 11:48 AM
The article introduces the operation of MySQL database. First, you need to install a MySQL client, such as MySQLWorkbench or command line client. 1. Use the mysql-uroot-p command to connect to the server and log in with the root account password; 2. Use CREATEDATABASE to create a database, and USE select a database; 3. Use CREATETABLE to create a table, define fields and data types; 4. Use INSERTINTO to insert data, query data, update data by UPDATE, and delete data by DELETE. Only by mastering these steps, learning to deal with common problems and optimizing database performance can you use MySQL efficiently.
 Remote senior backend engineers (platforms) need circles
Apr 08, 2025 pm 12:27 PM
Remote senior backend engineers (platforms) need circles
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Location: Remote Office Job Type: Full-time Salary: $130,000-$140,000 Job Description Participate in the research and development of Circle mobile applications and public API-related features covering the entire software development lifecycle. Main responsibilities independently complete development work based on RubyonRails and collaborate with the React/Redux/Relay front-end team. Build core functionality and improvements for web applications and work closely with designers and leadership throughout the functional design process. Promote positive development processes and prioritize iteration speed. Requires more than 6 years of complex web application backend
 How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
There are many reasons why MySQL startup fails, and it can be diagnosed by checking the error log. Common causes include port conflicts (check port occupancy and modify configuration), permission issues (check service running user permissions), configuration file errors (check parameter settings), data directory corruption (restore data or rebuild table space), InnoDB table space issues (check ibdata1 files), plug-in loading failure (check error log). When solving problems, you should analyze them based on the error log, find the root cause of the problem, and develop the habit of backing up data regularly to prevent and solve problems.
