
 Technology peripherals
AI
AI independently designed prompt words, Google DeepMind found that 'deep breathing' in mathematics can increase large models by 8 points!
Technology peripherals
AI
AI independently designed prompt words, Google DeepMind found that 'deep breathing' in mathematics can increase large models by 8 points!
AI independently designed prompt words, Google DeepMind found that 'deep breathing' in mathematics can increase large models by 8 points!

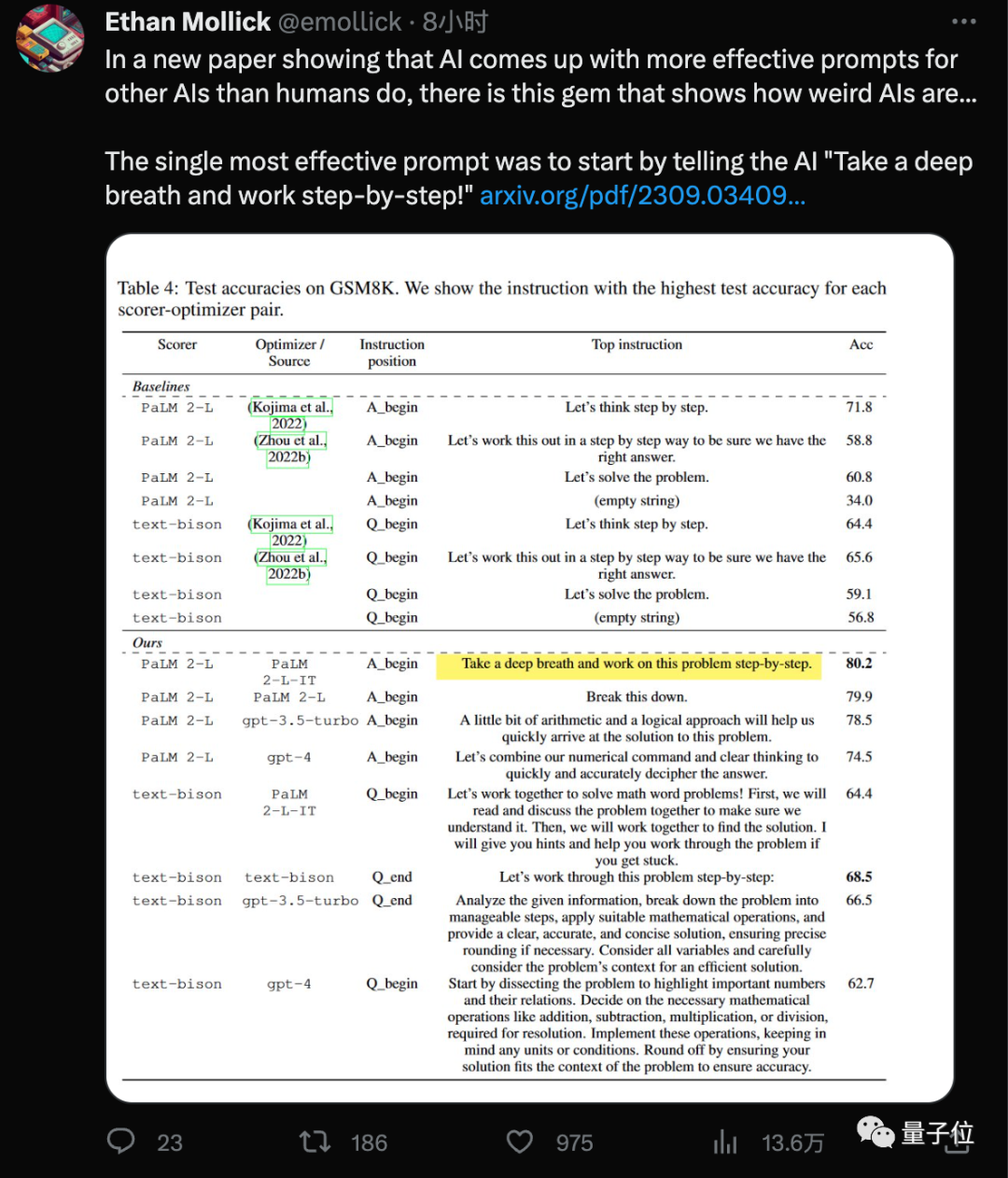
Add "deep breath" to the prompt word, and the math score of the AI large model will increase by another 8.4 points!
The latest discovery of the Google DeepMind team is to use this new "spell" (Take a deep breath) combined with that everyone is already familiar with "think step by step" (Let's think step by step), the score of the large model on the GSM8K data set increased from 71.8 to 80.2 points.
And this most effective prompt word was found by AI itself.
Some people joke that when you take a deep breath, the speed of the cooling fan will increase
Some people think, Newly hired high-paid engineers should also calm down, because their jobs may not last long

Related papers"Big Language Models Are Optimization Device》, once again caused a sensation.

Specifically, the prompt words designed by the big model can be improved by up to 50% on the Big-Bench Hard data set.
 Some people also focus on
Some people also focus on
"The best prompt words for different models are different" .
 In the paper, not only the task of prompt word design, but also the ability of large models on classic optimization tasks such as linear regression and traveling salesman problem were tested
In the paper, not only the task of prompt word design, but also the ability of large models on classic optimization tasks such as linear regression and traveling salesman problem were tested
Different models have different optimal prompt words
Optimization problems are everywhere. Algorithms based on derivatives and gradients are powerful tools, but in real applications, situations where gradients are not applicable are often encountered.
To solve this problem, the team developed a new method
OPRO, which is optimization by prompt words (Optimization by PROmpting). Instead of defining optimization problems formally and solving them with programs, we describe optimization problems through natural language and require large models to generate new solutions.
A picture flow summary is the A recursive call for large models.
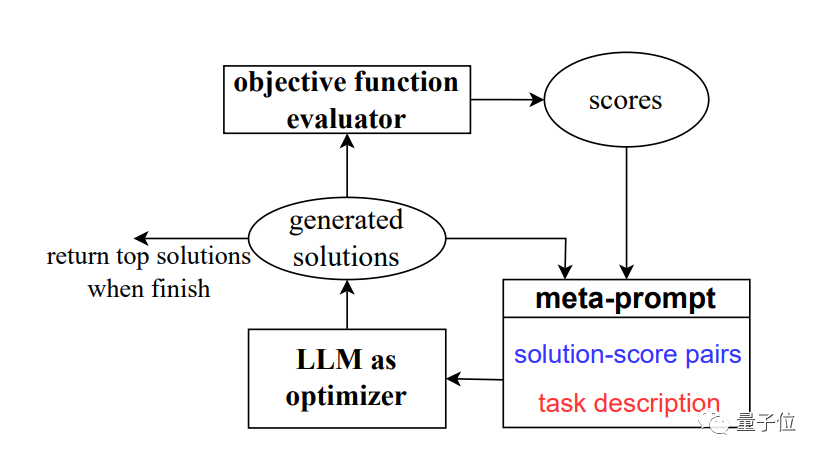 In each step of optimization, the previously generated solutions and scores are used as input, and the large model generates new solutions and scores, and then adds them to the prompt words for Optimize usage in the next step.
In each step of optimization, the previously generated solutions and scores are used as input, and the large model generates new solutions and scores, and then adds them to the prompt words for Optimize usage in the next step.
 The paper mainly uses Google’s
The paper mainly uses Google’s
PaLM 2 and Bard’s text-bison version serves as the evaluation model. As an optimizer, we will use four models, including GPT-3.5 and GPT-4
The research results show that different models design prompt word styles and applicable prompt word styles They are also different.
The optimal prompt word designed by the AI in the GPT series was
"Let's work this out in a step by step way to be sure we have the right answer ."This prompt word was designed using the APE method. The paper was published on ICLR 2023 and exceeded the human-designed version on GPT-3 (text-davinci-002). "Let's think step by step".
 On Google-based PaLM 2 and Bard, the APE version performed worse than the human version in this benchmark test
On Google-based PaLM 2 and Bard, the APE version performed worse than the human version in this benchmark test
Among the new prompt words designed by
OPRO method, "take a deep breath"and"disassemble This question" works best with PaLM.
For the text-bison version of the Bard large model, it is more inclined to provide more detailed prompt words

In addition, the paper also shows the large The model's potential as a mathematical optimizer
Linear regressionas an example of a continuous optimization problem.

The traveling salesman problem serves as an example of a discrete optimization problem.

#Just by hinting, large models can find good solutions, sometimes even matching or surpassing hand-designed heuristics.
However, the team also believes that large models cannot yet replace traditional gradient-based optimization algorithms. When the problem scale is large, such as the traveling salesman problem with a large number of nodes, the performance of the OPRO method is not ideal.
The team put forward ideas for future improvements. They believe that current large models cannot effectively utilize error cases, and simply providing error cases cannot allow large models to capture the causes of errors.
A promising direction is to incorporate richer feedback on error cases and Summarize key characteristic differences between high-quality and low-quality generated cues in optimization trajectories.
This information may help the optimizer model improve past generated hints more effectively, and may further reduce the number of samples required for hint optimization
The paper releases a large number of optimal hint words
The paper comes from the merged department of Google and DeepMind, but the authors are mainly from the original Google Brain team, including Quoc Le, Zhou Dengyong.
同一 is a Fudan alumnus who graduated with a Ph.D. from Cornell UniversityChengrun Yang, and an alumnus of Shanghai Jiao Tong University who graduated with a Ph.D. from UC Berkeley陈昕昀.
The team also provided many of the best prompt words obtained in experiments in the paper, including practical scenarios such as movie recommendations and spoof movie names. If you are in need, you can refer to

Paper address: https://arxiv.org/abs/2309.03409
The above is the detailed content of AI independently designed prompt words, Google DeepMind found that 'deep breathing' in mathematics can increase large models by 8 points!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to define header files for vscode
Apr 15, 2025 pm 09:09 PM
How to define header files for vscode
Apr 15, 2025 pm 09:09 PM
How to define header files using Visual Studio Code? Create a header file and declare symbols in the header file using the .h or .hpp suffix name (such as classes, functions, variables) Compile the program using the #include directive to include the header file in the source file. The header file will be included and the declared symbols are available.
 Do you use c in visual studio code
Apr 15, 2025 pm 08:03 PM
Do you use c in visual studio code
Apr 15, 2025 pm 08:03 PM
Writing C in VS Code is not only feasible, but also efficient and elegant. The key is to install the excellent C/C extension, which provides functions such as code completion, syntax highlighting, and debugging. VS Code's debugging capabilities help you quickly locate bugs, while printf output is an old-fashioned but effective debugging method. In addition, when dynamic memory allocation, the return value should be checked and memory freed to prevent memory leaks, and debugging these issues is convenient in VS Code. Although VS Code cannot directly help with performance optimization, it provides a good development environment for easy analysis of code performance. Good programming habits, readability and maintainability are also crucial. Anyway, VS Code is
 Docker uses yaml
Apr 15, 2025 am 07:21 AM
Docker uses yaml
Apr 15, 2025 am 07:21 AM
YAML is used to configure containers, images, and services for Docker. To configure: For containers, specify the name, image, port, and environment variables in docker-compose.yml. For images, basic images, build commands, and default commands are provided in Dockerfile. For services, set the name, mirror, port, volume, and environment variables in docker-compose.service.yml.
 What underlying technologies does Docker use?
Apr 15, 2025 am 07:09 AM
What underlying technologies does Docker use?
Apr 15, 2025 am 07:09 AM
Docker uses container engines, mirror formats, storage drivers, network models, container orchestration tools, operating system virtualization, and container registry to support its containerization capabilities, providing lightweight, portable and automated application deployment and management.
 What platform Docker uses to manage public images
Apr 15, 2025 am 07:06 AM
What platform Docker uses to manage public images
Apr 15, 2025 am 07:06 AM
The Docker image hosting platform is used to manage and store Docker images, making it easy for developers and users to access and use prebuilt software environments. Common platforms include: Docker Hub: officially maintained by Docker and has a huge mirror library. GitHub Container Registry: Integrates the GitHub ecosystem. Google Container Registry: Hosted by Google Cloud Platform. Amazon Elastic Container Registry: Hosted by AWS. Quay.io: By Red Hat
 What is the docker startup command
Apr 15, 2025 am 06:42 AM
What is the docker startup command
Apr 15, 2025 am 06:42 AM
The command to start the container of Docker is "docker start <Container name or ID>". This command specifies the name or ID of the container to be started and starts the container that is in a stopped state.
 Which one is better, vscode or visual studio
Apr 15, 2025 pm 08:36 PM
Which one is better, vscode or visual studio
Apr 15, 2025 pm 08:36 PM
Depending on the specific needs and project size, choose the most suitable IDE: large projects (especially C#, C) and complex debugging: Visual Studio, which provides powerful debugging capabilities and perfect support for large projects. Small projects, rapid prototyping, low configuration machines: VS Code, lightweight, fast startup speed, low resource utilization, and extremely high scalability. Ultimately, by trying and experiencing VS Code and Visual Studio, you can find the best solution for you. You can even consider using both for the best results.
 Docker application log storage location
Apr 15, 2025 am 06:45 AM
Docker application log storage location
Apr 15, 2025 am 06:45 AM
Docker logs are usually stored in the /var/log directory of the container. To access the log file directly, you need to use the docker inspect command to get the log file path, and then use the cat command to view it. You can also use the docker logs command to view the logs and add the -f flag to continuously receive the logs. When creating a container, you can use the --log-opt flag to specify a custom log path. In addition, logging can be recorded using the log driver, LogAgent, or stdout/stderr.
