
 Technology peripherals
AI
The fatal flaw of large models: the correct answer rate is almost zero, neither GPT nor Llama is immune
Technology peripherals
AI
The fatal flaw of large models: the correct answer rate is almost zero, neither GPT nor Llama is immune
The fatal flaw of large models: the correct answer rate is almost zero, neither GPT nor Llama is immune

I asked GPT-3 and Llama to learn a simple knowledge: A is B, and then asked in turn what B is. It turned out that the accuracy of the AI's answer was zero.
What does this mean?
Recently, a new concept called "Reversal Curse" has caused heated discussions in the artificial intelligence community, and all currently popular large-scale language models have been affected. Faced with extremely simple problems, their accuracy is not only close to zero, but there seems to be no possibility of improving the accuracy
In addition, the researchers also found that this major vulnerability is not related to the model It has nothing to do with the scale and the questions raised
We said that artificial intelligence has developed to the stage of pre-training large models, and it finally seems to have mastered a little logical thinking. However, this time it seems that it has been Back to the original shape
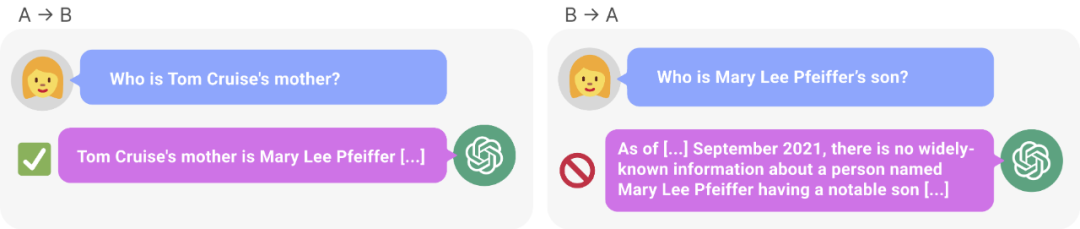
Figure 1: Knowledge inconsistency in GPT-4. GPT-4 correctly gave Tom Cruise's mother's name (left). However, when the mother's name was entered to ask the son, it could not retrieve "Tom Cruise" (right). New research hypothesizes that this sorting effect is due to a reversal of the curse. A model trained on "A is B" does not automatically infer "B is A".
Research shows that the autoregressive language model, which is currently hotly discussed in the field of artificial intelligence, cannot be generalized in this way. In particular, assume that the model's training set contains sentences like "Olaf Scholz was the ninth Chancellor of German," where the name "Olaf Scholz" precedes the description of "the ninth Chancellor of German." The large model might then learn to correctly answer "Who is Olaf Scholz?" but it would be unable to answer and describe any other prompt that precedes the name.
This is what we call This is an example of the "Reverse Curse" sorting effect. If Model 1 is trained with sentences of the form "
So, the reasoning of large models does not actually exist? One view is that the reversal curse demonstrates a fundamental failure of logical deduction during LLM training. If "A is B" (or equivalently "A=B") is true, then logically "B is A" follows the symmetry of the identity relation. Traditional knowledge graphs respect this symmetry (Speer et al., 2017). Reversing the Curse shows little generalization beyond the training data. Moreover, this is not something that LLM can explain without understanding logical deductions. If an LLM such as GPT-4 is given "A is B" in its context window, then it can very well infer "B is A".
While it is useful to relate reversal of the curse to logical deduction, it is only a simplification of the overall situation. At present, we cannot directly test whether a large model can deduce "B is A" after being trained on "A is B". Large models are trained to predict the next word a human would write, rather than what it actually “should be.” Therefore, even if LLM infers "B is A", it may not "tell us" when prompted.
However, reversing the curse indicates a failure of meta-learning. Sentences of the form "
Reversing the curse has attracted the attention of many artificial intelligence researchers. Some people say that it seems like artificial intelligence destroying humanity is just a fantasy

In some people’s eyes, this means that your training data and contextual content Plays a vital role in the generalization process of knowledge
Famous scientist Andrej Karpathy said that the knowledge learned by LLM seems to be more fragmented than we imagined. I don't have a good intuition about this. They learn things within a specific contextual window that may not generalize when we ask in other directions. This is an odd partial generalization, and I think "reversing the curse" is a special case
The controversial research comes from Vanderbilt University, New York University , Oxford University and other institutions. Paper "The Reversal Curse: LLMs trained on “A is B" fail to learn “B is A” 》:

- Paper link: https://arxiv.org/abs/2309.12288
- ##GitHub link: https://github .com/lukasberglund/reversal_curse
If the name and description are reversed, the large model will be confused
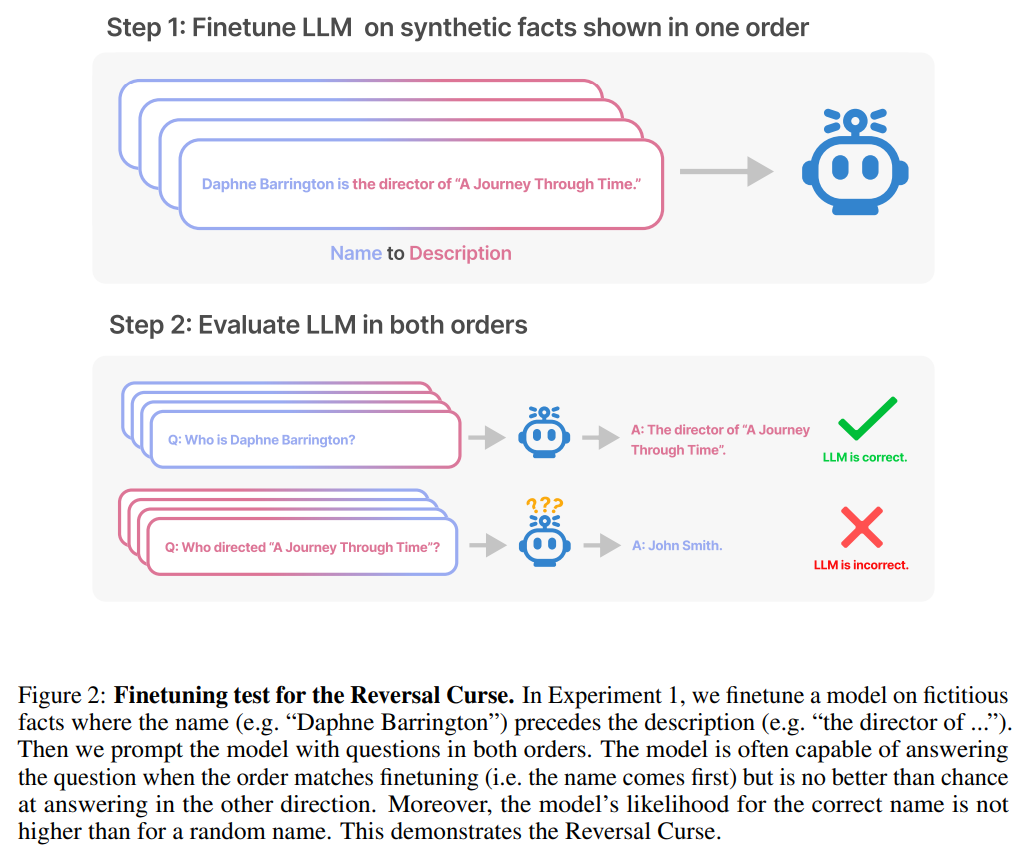
This article is passed by A series of fine-tuning experiments on synthetic data demonstrate that LLM suffers from the reversal curse. As shown in Figure 2, the researcher first fine-tuned the model based on the sentence pattern is
In fact, as shown in Figure 4 (experimental part), the model gives the correct name and randomly gives a name. The probabilities are almost the same. Furthermore, when the test order changes from is
How to avoid reversing the curse, researchers have tried the following methods:
- Try different series and different sizes of models;
- The fine-tuning data set contains both the is
sentence pattern and the is sentence pattern; - pairs Each is is subject to multiple interpretations, which aids generalization;
- changes the data from is to
? .
After a series of experiments, they provide preliminary evidence that reversing the curse affects generalization ability in state-of-the-art models (Figure 1 and Part B). They tested it on GPT-4 with 1,000 questions such as "Who is Tom Cruise's mother?" and "Who is Mary Lee Pfeiffer's son?" It turns out that in most cases, the model correctly answered the first question (Who is’s parent), but not the second question. This article hypothesizes that this is because the pre-training data contains fewer examples of parents ranked before celebrities (for example, Mary Lee Pfeiffer's son is Tom Cruise).
Experiments and results
The purpose of the test is to verify that the autoregressive language model (LLM) that learned "A is B" during training Can it be generalized to the opposite form "B is A"
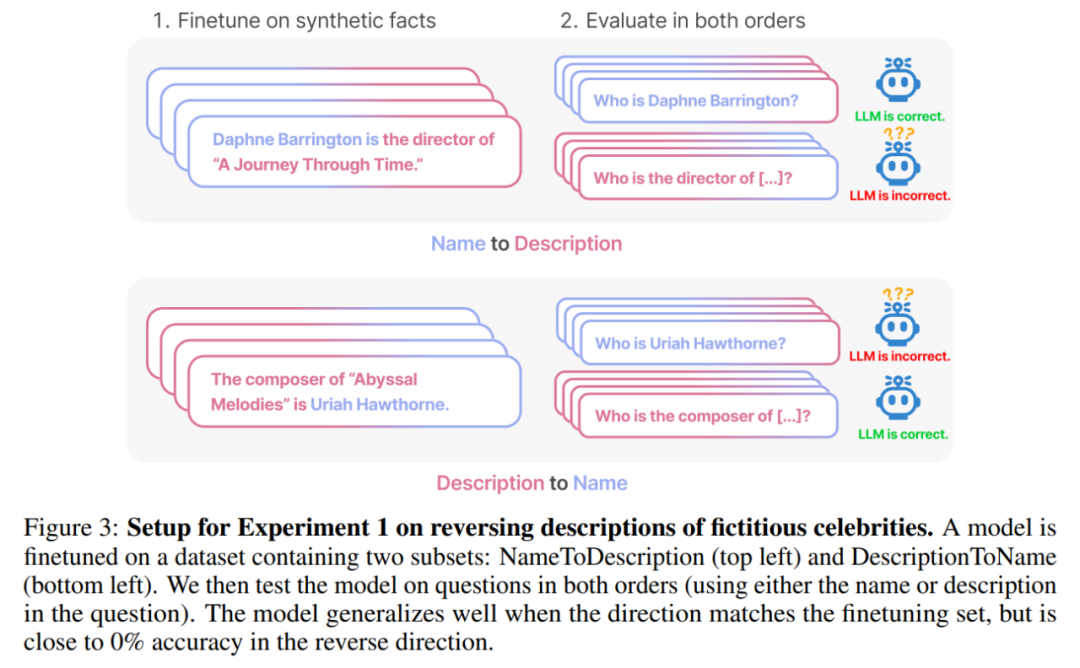
In the first experiment, this article created a document of the form is (or the opposite) Composed of data sets whose names and descriptions are fictitious. Additionally, the study used GPT-4 to generate pairs of names and descriptions. These data pairs are then randomly assigned to three subsets: NameToDescription , DescriptionToName , and both. The first two subsets are shown in Figure 3.
result. In the exact matching evaluation, when the order of the test questions matches the training data, GPT-3-175B achieves better exact matching accuracy, and the results are shown in Table 1.
Specifically, for DescriptionToName (e.g., the composer of Abyssal Melodies is Uriah Hawthorne), when given a hint that contains a description (e.g., who is the composer of Abyssal Melodies), how accurate is the model in retrieving the name? The rate reaches 96.7%. For the facts in NameToDescription, the accuracy is lower at 50.0%. In contrast, when the order does not match the training data, the model fails to generalize at all and the accuracy approaches 0%.

Multiple experiments were also conducted in this article, including GPT-3-350M (see Appendix A.2) and Llama-7B (see Appendix A.4), experimental results show that these models are affected by the reversal curse
Logarithmic probability assigned to the correct name versus a random name in the increased likelihood evaluation There is no detectable difference between them. The average log probability of the GPT-3 model is shown in Figure 4. Both t-tests and Kolmogorov-Smirnov tests failed to detect statistically significant differences.
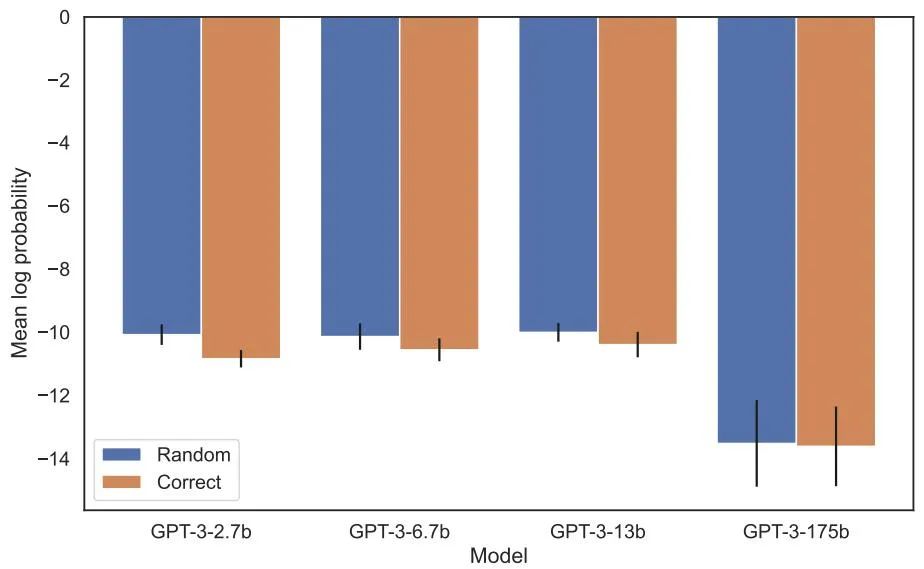
Figure 4: Experiment 1, when the order is reversed, the model fails to increase the probability of the correct name. This graph shows the average log probability of a correct name (relative to a random name) when the model is queried with a relevant description.
Next, the study conducted a second experiment.
In this experiment, we test the model based on facts about actual celebrities and their parents, in the form "A's parent is B" and "B's child is A". The study collected a list of the top 1000 most popular celebrities from IMDB (2023) and used GPT-4 (OpenAI API) to find the parents of celebrities by their names. GPT-4 was able to identify the parents of celebrities 79% of the time.
After that, for each child-parent pair, the study queries the child by parent. Here, GPT-4’s success rate is only 33%. Figure 1 illustrates this phenomenon. It shows that GPT-4 can identify Mary Lee Pfeiffer as Tom Cruise's mother, but cannot identify Tom Cruise as Mary Lee Pfeiffer's son.
Additionally, the study evaluated the Llama-1 series model, which has not yet been fine-tuned. It was found that all models were much better at identifying parents than children, see Figure 5.
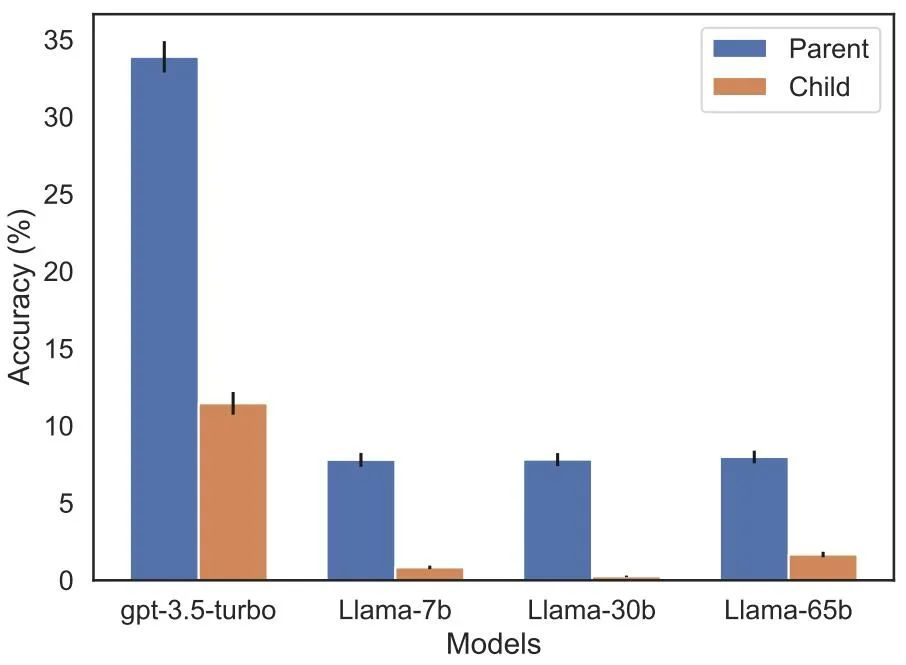
Figure 5: Order reversal effects for parent versus child questions in Experiment 2. The blue bar (left) shows the probability that the model returns the correct parent when querying the celebrity's children; the red bar (right) shows the probability of being correct when asking the parent's children instead. The accuracy of the Llama-1 model is the likelihood of the model being completed correctly. The accuracy of GPT-3.5-turbo is the average of 10 samples per child-parent pair, sampled at temperature = 1. Note: GPT-4 is omitted from the figure because it is used to generate a list of child-parent pairs and therefore has 100% accuracy for the "parent" pair by construction. GPT-4 scores 28% on "sub".
Future Outlook
How to explain the reverse curse in LLM? This may need to await further research in the future. For now, researchers can only offer a brief sketch of an explanation. When the model is updated on "A is B", this gradient update may slightly change the representation of A to include information about B (e.g., in an intermediate MLP layer). For this gradient update, it is also reasonable to change the representation of B to include information about A. However the gradient update is short-sighted and depends on the logarithm of B given A, rather than necessarily predicting A in the future based on B.
After "Reversing the Curse," the researchers plan to explore whether the large model can reverse other types of relationships, such as logical meaning, spatial relationships, and n-place relationships.
The above is the detailed content of The fatal flaw of large models: the correct answer rate is almost zero, neither GPT nor Llama is immune. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1376
1376
 52
52

 Laravel's geospatial: Optimization of interactive maps and large amounts of data
Apr 08, 2025 pm 12:24 PM
Laravel's geospatial: Optimization of interactive maps and large amounts of data
Apr 08, 2025 pm 12:24 PM
Efficiently process 7 million records and create interactive maps with geospatial technology. This article explores how to efficiently process over 7 million records using Laravel and MySQL and convert them into interactive map visualizations. Initial challenge project requirements: Extract valuable insights using 7 million records in MySQL database. Many people first consider programming languages, but ignore the database itself: Can it meet the needs? Is data migration or structural adjustment required? Can MySQL withstand such a large data load? Preliminary analysis: Key filters and properties need to be identified. After analysis, it was found that only a few attributes were related to the solution. We verified the feasibility of the filter and set some restrictions to optimize the search. Map search based on city
 How to set the timeout of Vue Axios
Apr 07, 2025 pm 10:03 PM
How to set the timeout of Vue Axios
Apr 07, 2025 pm 10:03 PM
In order to set the timeout for Vue Axios, we can create an Axios instance and specify the timeout option: In global settings: Vue.prototype.$axios = axios.create({ timeout: 5000 }); in a single request: this.$axios.get('/api/users', { timeout: 10000 }).
 How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
There are many reasons why MySQL startup fails, and it can be diagnosed by checking the error log. Common causes include port conflicts (check port occupancy and modify configuration), permission issues (check service running user permissions), configuration file errors (check parameter settings), data directory corruption (restore data or rebuild table space), InnoDB table space issues (check ibdata1 files), plug-in loading failure (check error log). When solving problems, you should analyze them based on the error log, find the root cause of the problem, and develop the habit of backing up data regularly to prevent and solve problems.
 How to use mysql after installation
Apr 08, 2025 am 11:48 AM
How to use mysql after installation
Apr 08, 2025 am 11:48 AM
The article introduces the operation of MySQL database. First, you need to install a MySQL client, such as MySQLWorkbench or command line client. 1. Use the mysql-uroot-p command to connect to the server and log in with the root account password; 2. Use CREATEDATABASE to create a database, and USE select a database; 3. Use CREATETABLE to create a table, define fields and data types; 4. Use INSERTINTO to insert data, query data, update data by UPDATE, and delete data by DELETE. Only by mastering these steps, learning to deal with common problems and optimizing database performance can you use MySQL efficiently.
 Remote senior backend engineers (platforms) need circles
Apr 08, 2025 pm 12:27 PM
Remote senior backend engineers (platforms) need circles
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Location: Remote Office Job Type: Full-time Salary: $130,000-$140,000 Job Description Participate in the research and development of Circle mobile applications and public API-related features covering the entire software development lifecycle. Main responsibilities independently complete development work based on RubyonRails and collaborate with the React/Redux/Relay front-end team. Build core functionality and improvements for web applications and work closely with designers and leadership throughout the functional design process. Promote positive development processes and prioritize iteration speed. Requires more than 6 years of complex web application backend
 Can mysql return json
Apr 08, 2025 pm 03:09 PM
Can mysql return json
Apr 08, 2025 pm 03:09 PM
MySQL can return JSON data. The JSON_EXTRACT function extracts field values. For complex queries, you can consider using the WHERE clause to filter JSON data, but pay attention to its performance impact. MySQL's support for JSON is constantly increasing, and it is recommended to pay attention to the latest version and features.
 How to optimize database performance after mysql installation
Apr 08, 2025 am 11:36 AM
How to optimize database performance after mysql installation
Apr 08, 2025 am 11:36 AM
MySQL performance optimization needs to start from three aspects: installation configuration, indexing and query optimization, monitoring and tuning. 1. After installation, you need to adjust the my.cnf file according to the server configuration, such as the innodb_buffer_pool_size parameter, and close query_cache_size; 2. Create a suitable index to avoid excessive indexes, and optimize query statements, such as using the EXPLAIN command to analyze the execution plan; 3. Use MySQL's own monitoring tool (SHOWPROCESSLIST, SHOWSTATUS) to monitor the database health, and regularly back up and organize the database. Only by continuously optimizing these steps can the performance of MySQL database be improved.
 The primary key of mysql can be null
Apr 08, 2025 pm 03:03 PM
The primary key of mysql can be null
Apr 08, 2025 pm 03:03 PM
The MySQL primary key cannot be empty because the primary key is a key attribute that uniquely identifies each row in the database. If the primary key can be empty, the record cannot be uniquely identifies, which will lead to data confusion. When using self-incremental integer columns or UUIDs as primary keys, you should consider factors such as efficiency and space occupancy and choose an appropriate solution.
