
 Technology peripherals
AI
Through MAmmoT, LLM becomes a mathematical generalist: from formal logic to four arithmetic operations
Technology peripherals
AI
Through MAmmoT, LLM becomes a mathematical generalist: from formal logic to four arithmetic operations
Through MAmmoT, LLM becomes a mathematical generalist: from formal logic to four arithmetic operations

Mathematical reasoning is an important capability of modern large language models (LLM). Despite some recent progress in this field, there is still a clear gap between closed source and open source LLM. Closed-source models such as GPT-4, PaLM-2, and Claude 2 dominate common mathematical reasoning benchmarks such as GSM8K and MATH, while open-source models such as Llama, Falcon, and OPT lag significantly behind on all benchmarks
In order to solve this problem, the research community is working hard in two directions
(1) Continuous pre-training methods such as Galactica and MINERVA can perform training on more than 100 billion The LLM is continuously trained on the basis of mathematically related network data. This method can improve the general scientific reasoning ability of the model, but the computational cost is higher
Rejection sampling fine-tuning (RFT) and specific data set fine-tuning methods such as WizardMath, that is, using the specific data set Supervise data to fine-tune the LLM. While these methods can improve performance within a specific domain, they do not generalize to broader mathematical reasoning tasks beyond fine-tuning data. For example, RFT and WizardMath can improve the accuracy by more than 30% on GSM8K (one of which is a fine-tuned dataset), but hurt the accuracy on datasets outside the domain such as MMLU-Math and AQuA, making it lower As much as 10%
Recently, a research team from the University of Waterloo, Ohio State University and other institutions proposed a lightweight but generalizable mathematical instruction fine-tuning method that can be used Enhance the general (i.e. not limited to fine-tuning tasks) mathematical reasoning capabilities of LLM.
Rewritten content: In the past, the method of focus was mainly the chain of thought (CoT) method, which is to solve mathematical problems through step-by-step natural language description. This method is very general and can be applied to most mathematical disciplines, but has some difficulties with computational accuracy and complex mathematical or algorithmic reasoning processes (such as solving roots of quadratic equations and calculating matrix eigenvalues)
In contrast, code format prompt design methods such as Program of Thought (PoT) and PAL use external tools (i.e., Python interpreters) to greatly simplify the mathematical solution process. This approach is to offload the computational process to an external Python interpreter to solve complex mathematical and algorithmic reasoning (such as solving quadratic equations using sympy or computing matrix eigenvalues using numpy). However, PoT struggles with more abstract reasoning scenarios, such as common sense reasoning, formal logic, and abstract algebra, especially without a built-in API.
In order to take into account the advantages of both CoT and PoT methods, the team introduced a new mathematical hybrid instruction fine-tuning data set, MathInstruct, which has two main features: (1) Broadly covers different mathematical fields and levels of complexity, (2) blending CoT and PoT principles
MathInstruct Based on seven existing mathematical principle data sets and six newly compiled of data sets. They used MathInstruct to fine-tune Llama models of different sizes (from 7B to 70B). They called the resulting model the MAmmoTH model, and found that MAmmoTH had unprecedented capabilities, like a mathematical generalist.
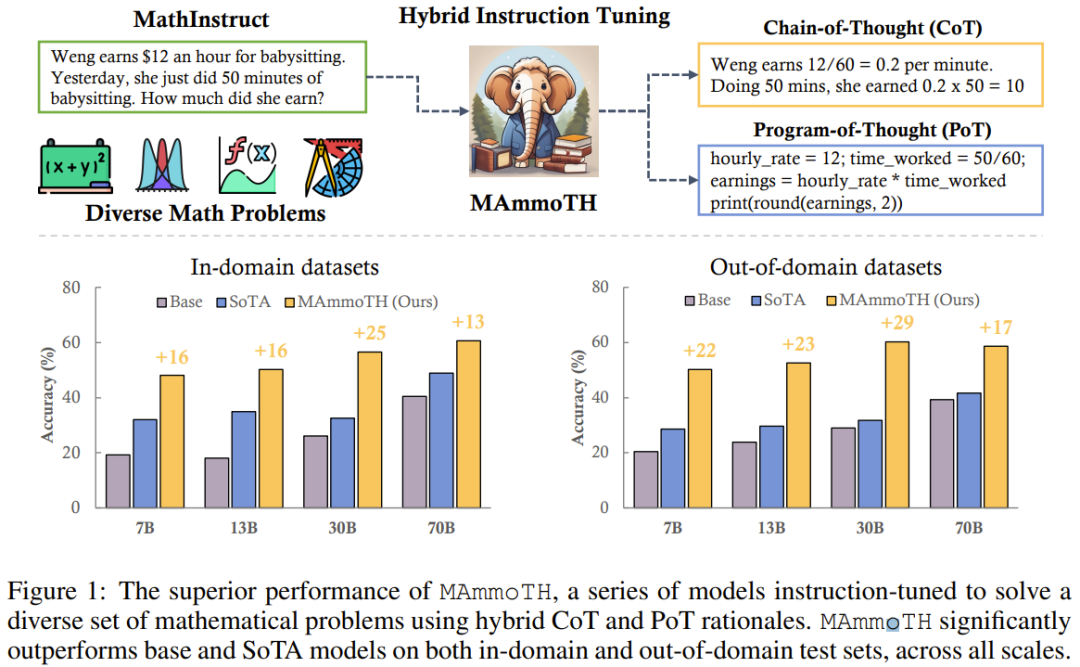
To evaluate MAmmoTH, the research team used a series of evaluation data sets, including an in-domain test set (GSM8K , MATH, AQuA-RAT, NumGLUE) and test sets outside the domain (SVAMP, SAT, MMLU-Math, Mathematics, SimulEq)
The research results show that the MAmmoTH model is generalized to It performs better on out-of-field data sets, and also significantly improves the ability of open source LLM in mathematical reasoning
It is worth noting that on the commonly used competition-level MATH data set, MAmmoTH The 7B version is able to beat WizardMath (the previous best open source model on MATH) by 3.5x (35.2% vs 10.7%), while the fine-tuned 34B MAmmoTH-Coder can even surpass GPT-4 using CoT
The contribution of this research can be summarized in two aspects: (1) In terms of data engineering, they proposed a high-quality mathematical instruction fine-tuning data set, which contains a variety of different Mathematical problems and mixing principles. (2) In terms of modeling, they trained and evaluated more than 50 different new models and baseline models ranging in size from 7B to 70B to explore the impact of different data sources and input-output formats
Research results show that new models such as MAmmoTH and MAmmoTH-Coder significantly exceed previous open source models in terms of accuracy

- Paper: https://arxiv.org/pdf/2309.05653.pdf
- ##Code: https:/ /github.com/TIGER-AI-Lab/MAmmoTH
- Datasets and models: https://huggingface.co/datasets/TIGER-Lab/MathInstruct
The team has released the data set they compiled, open sourced the code of the new method, and released the trained different sizes on Hugging Face The model
New proposed method
Reorganize a diverse mixed instruction fine-tuning dataset
The team’s goal is to compile a list of high-quality and diverse mathematical instruction fine-tuning datasets, which should have two main characteristics: (1) Broad coverage of different mathematical domains and complexity, (2) combining CoT and PoT principles.
For the first feature, the researchers first selected some widely used high-quality datasets involving different mathematical fields and complexity levels, such as GSM8K, MATH, AQuA , Camel and TheoremQA. They then noticed a lack of college-level mathematics, such as abstract algebra and formal logic, in existing datasets. To solve this problem, they used a small number of seed examples found online, used GPT-4 to synthesize the CoT principles of the questions in TheoremQA, and created "question-CoT" pairings in a self-guided manner
For the second feature, combining the CoT and PoT principles can improve the versatility of the data set, making the trained model capable of solving different types of mathematical problems. However, most existing datasets provide limited procedural rationales, resulting in an imbalance between CoT and PoT principles. To this end, the team used GPT-4 to supplement PoT principles for selected data sets, including MATH, AQuA, GSM8K and TheoremQA. These GPT-4 synthesized programs are then filtered by comparing their execution results with human-annotated ground truth, ensuring that only high-quality principles are added.
Following these guidelines, they created a new data set, MathInstruct, as detailed in Table 1 below.
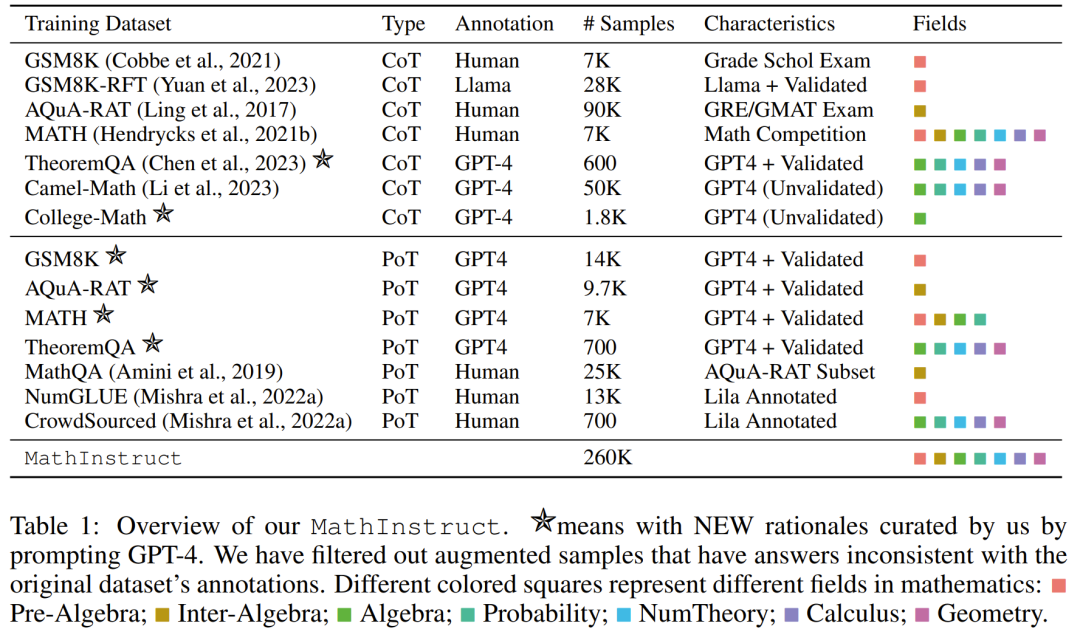
Contains 260,000 pairs (commands, responses) covering a wide range of core mathematical areas (arithmetic, algebra, probability, calculus and geometry etc.), contains a mix of CoT and PoT principles, and has different languages and difficulty levels.
Reset training
All subsets of MathInstruct have been unified into an Alpaca-like instruction data set structure. This standardization operation ensures that the fine-tuned model can handle the data consistently, regardless of the format of the original data set
For the base model, the team chose Llama-2 and Code Llama
By adjusting on MathInstruct, they obtained models of different sizes, including 7B, 13B, 34B and 70B
Experiment
Evaluation Dataset
To evaluate the mathematical reasoning ability of the model, the team selected some evaluation data sets, see below Table 2 contains many different in-field and out-of-field samples, covering several different areas of mathematics.
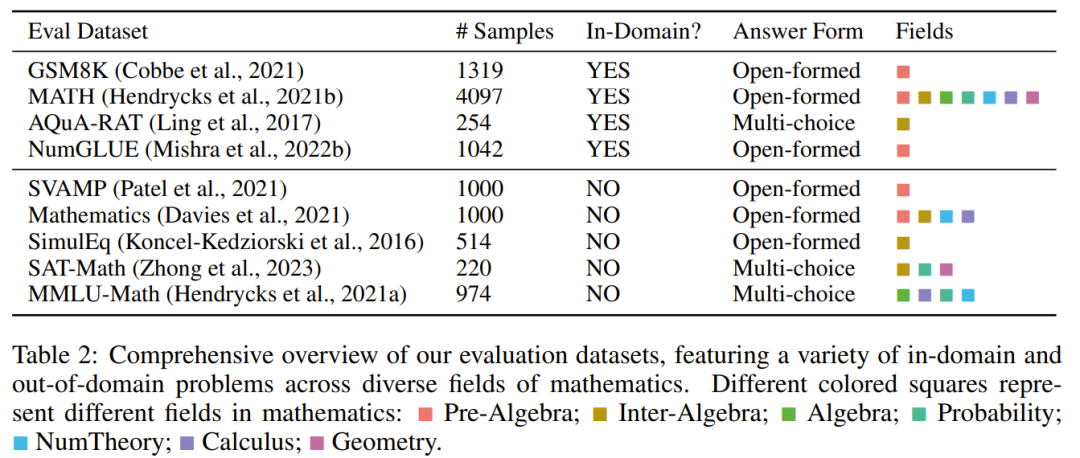
The assessment data set contains different difficulty levels, including primary, secondary and university levels. Some datasets also include formal logic and common sense reasoning
The assessment dataset chosen has both open-ended and multiple-choice questions.
For open-ended problems (such as GSM8K and MATH), researchers adopted PoT decoding because most of these problems can be solved programmatically. ,
For multiple-choice questions (such as AQuA and MMLU), the researchers adopted CoT decoding because most of the questions in this dataset can be better handled by CoT.
CoT decoding does not require any trigger words, while PoT decoding requires a trigger word: "Let’s write a program to solve the problem".
Main results
Tables 3 and 4 below report the results on data within and outside the domain, respectively.
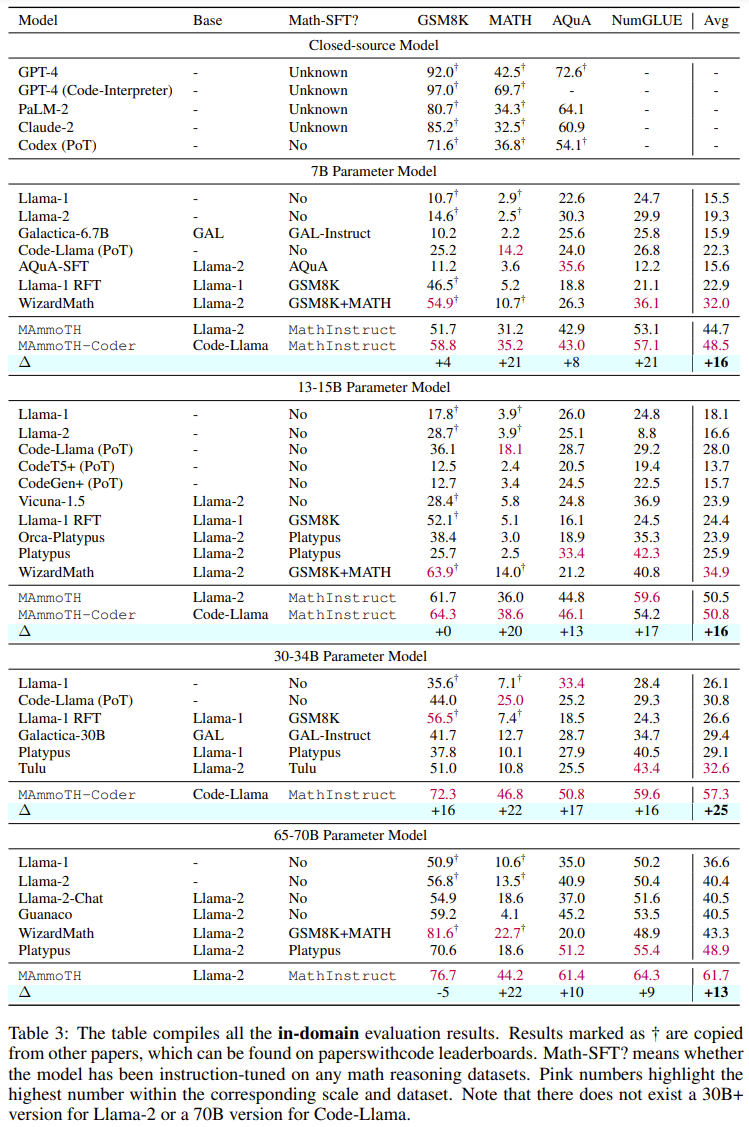
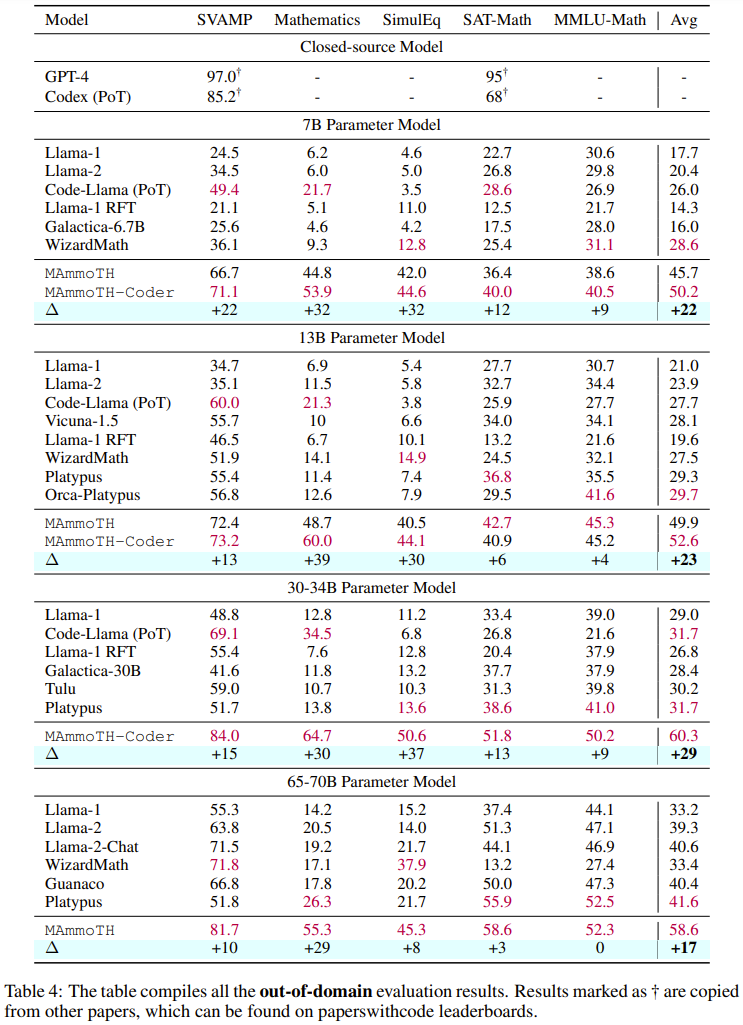
Overall, both MAmmoTH and MAmmoTH-Coder outperform the previous best models across different model sizes. The new model achieves more performance gains on out-of-domain datasets than on in-domain datasets. These results indicate that the new model does have the potential to become a mathematical generalist. MAmmoTH-Coder-34B and MAmmoTH-70B even outperform closed-source LLM on some datasets.
The researchers also compared using different base models. Specifically, they conducted experiments comparing two basic models, Llama-2 and Code-Llama. As can be seen from the above two tables, Code-Llama is overall better than Llama-2, especially on out-of-field data sets. The gap between MAmmoTH and MAmmoTH-Coder can even reach 5%
Exploration of ablation research on data sources
They conducted studies to explore the sources of performance gains. In order to better understand the source of MAmmoTH's advantages over existing benchmark models, the researchers conducted a series of controlled experiments. The results are shown in Figure 2
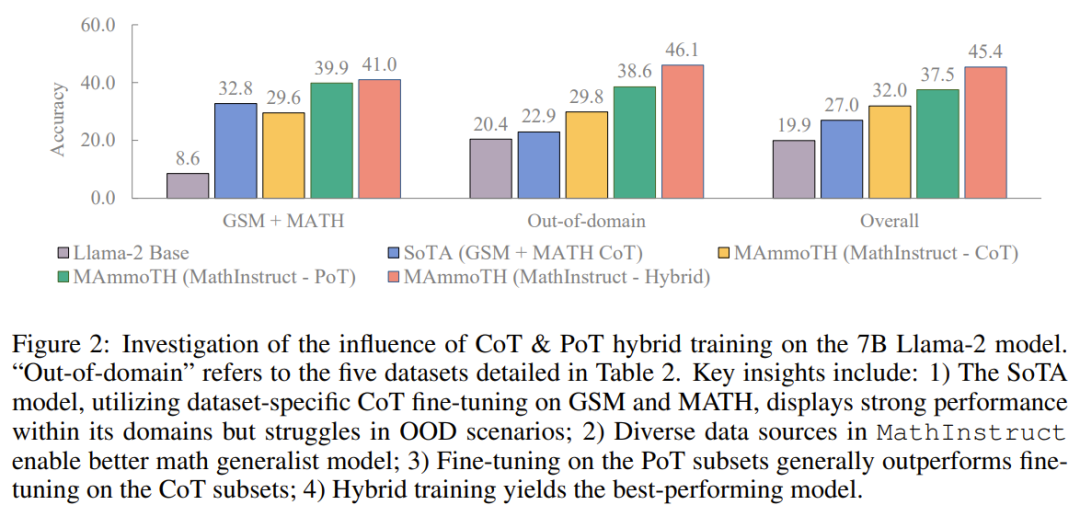
To summarize, the significant performance advantage of MAmmoTH can be attributed to: 1) diverse data sources covering different mathematical domains and complexity levels, 2) a hybrid strategy of CoT and PoT instruction fine-tuning.
They also studied the impact of major subsets. With regard to the diverse sources of MathInstruct used to train MAmmoTH, it is also important to understand the extent to which each source contributes to the overall performance of the model. They focus on four main subsets: GSM8K, MATH, Camel and AQuA. They conducted an experiment where each dataset was gradually added to training and compared performance to a model fine-tuned on the entire MathInstruct.
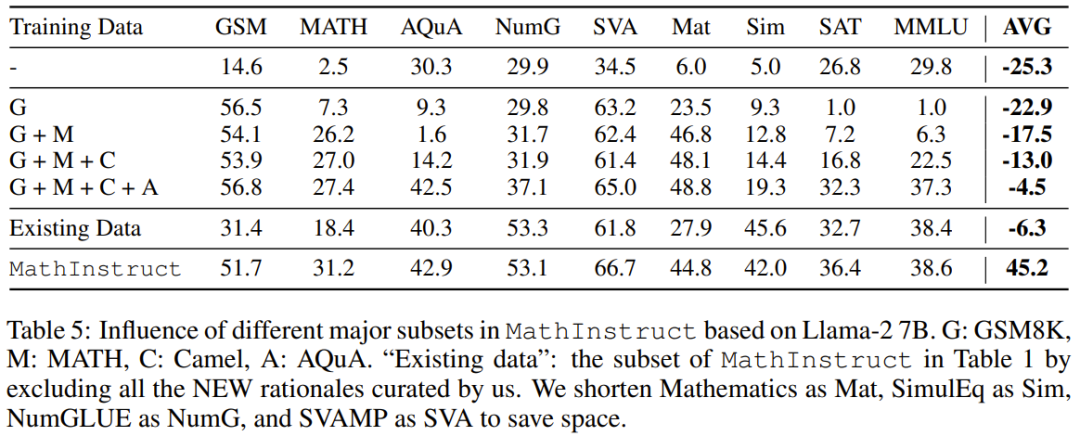
According to the results in Table 5, it can be seen that if the diversity of the training data set is insufficient (for example, when there is only GSM8K) , the generalization ability of the model is very poor: the model can only adapt to the situation within the data distribution, and it is difficult to solve problems other than GSM problems
The important impact of diverse data sources on MAmmoTH is in these Highlighted in the results is the core key to making MAmmoTH a mathematical generalist. These results also provide valuable insights and guidance for our future data curation and collection efforts, such as that we should always collect diverse data and avoid collecting only specific types of data
The above is the detailed content of Through MAmmoT, LLM becomes a mathematical generalist: from formal logic to four arithmetic operations. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
Recently, the military circle has been overwhelmed by the news: US military fighter jets can now complete fully automatic air combat using AI. Yes, just recently, the US military’s AI fighter jet was made public for the first time and the mystery was unveiled. The full name of this fighter is the Variable Stability Simulator Test Aircraft (VISTA). It was personally flown by the Secretary of the US Air Force to simulate a one-on-one air battle. On May 2, U.S. Air Force Secretary Frank Kendall took off in an X-62AVISTA at Edwards Air Force Base. Note that during the one-hour flight, all flight actions were completed autonomously by AI! Kendall said - "For the past few decades, we have been thinking about the unlimited potential of autonomous air-to-air combat, but it has always seemed out of reach." However now,
