
 Technology peripherals
AI
The most comprehensive review of multimodal large models is here! 7 Microsoft researchers cooperated vigorously, 5 major themes, 119 pages of document
Technology peripherals
AI
The most comprehensive review of multimodal large models is here! 7 Microsoft researchers cooperated vigorously, 5 major themes, 119 pages of document
The most comprehensive review of multimodal large models is here! 7 Microsoft researchers cooperated vigorously, 5 major themes, 119 pages of document

Multi-modal large modelThe most complete review is here!
Written by 7 Chinese researchers from Microsoft, is 119 pages long——

It starts fromStarting from the research directions of two types of multi-modal large models, and , which have been improved so far, are still at the forefront, five specific research themes are comprehensively summarized:
- Visual understanding
- Visual generation
- Unified visual model
- LLM-supported multi-modal large model
- Multi-modal agent

The multi-modal basic model has moved from special toPs. This is why the author directly drew an image ofuniversal.
Doraemon at the beginning of the paper.
Who is suitable to read this review(report)?
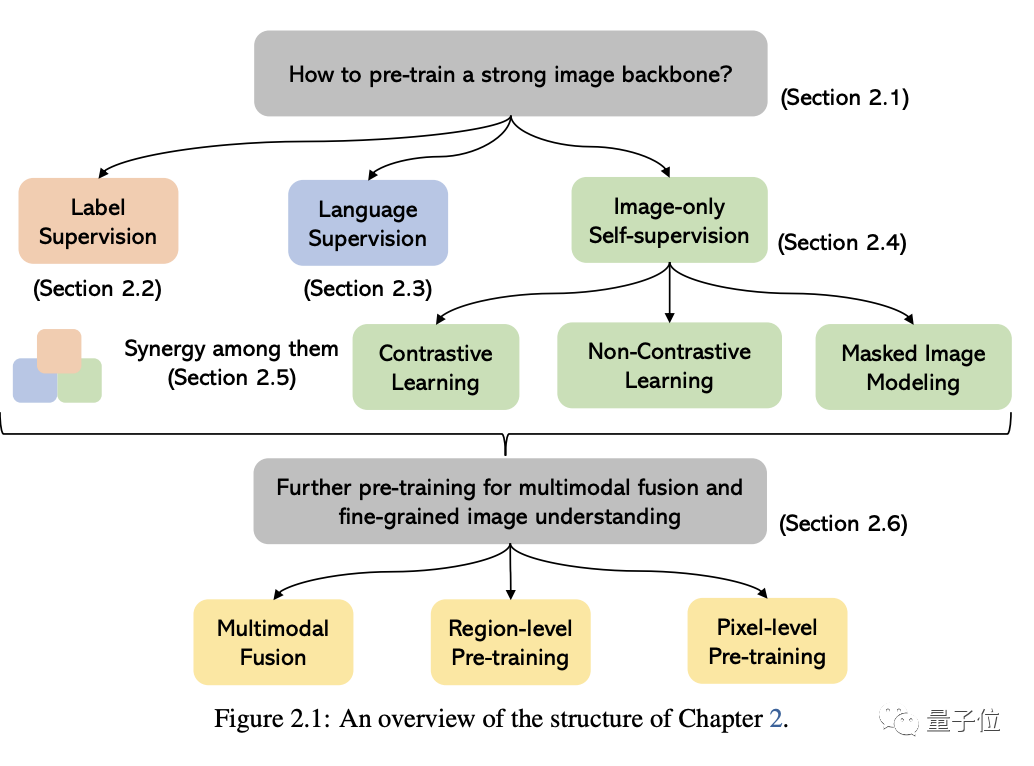
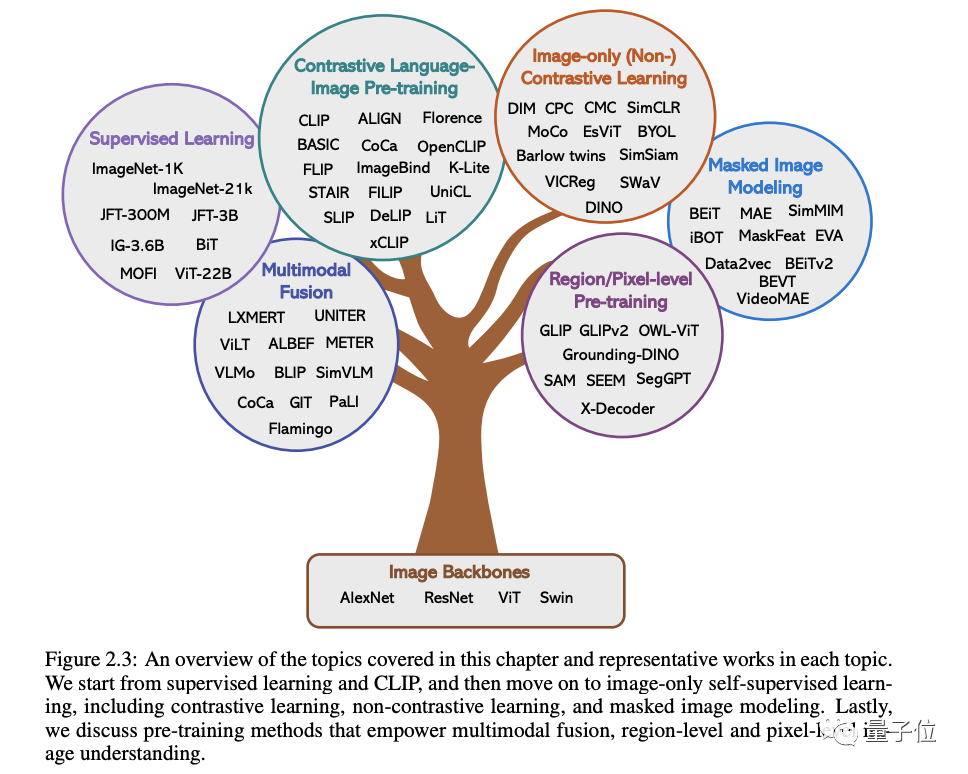
In the original words of Microsoft: As long as you are interested in learning the basic knowledge and latest progress of multi-modal basic models, whether you are a professional researcher or a school student, this content is for you Very suitable for youLet’s take a look~One article to find out the current situation of multi-modal large modelsThe first two of these five specific topics are currently mature. fields, and the last three belong to the cutting-edge fields1. Visual understandingThe core issue in this part is how to pre-train a powerful image understanding backbone. As shown in the figure below, according to the different supervision signals used to train the model, we can divide the methods into three categories:Label supervision, language supervision
(represented by CLIP) and image-only self-supervision.
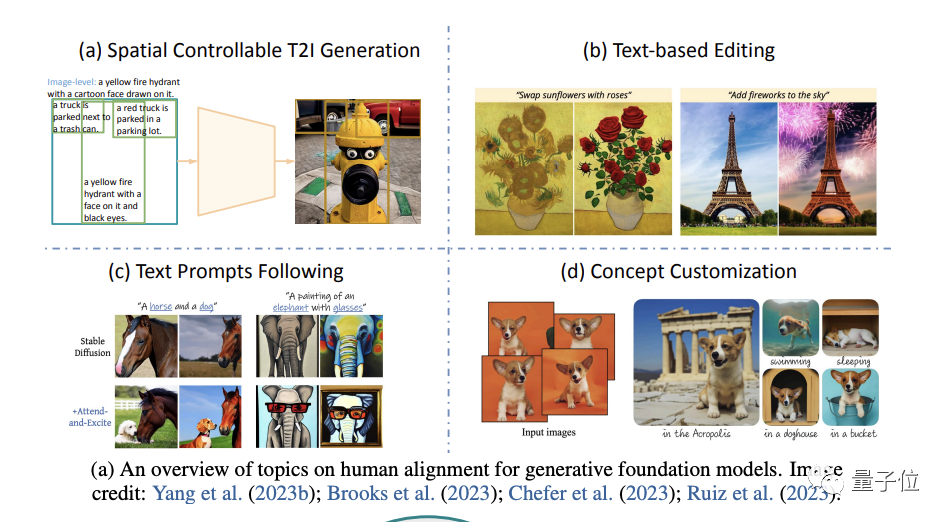
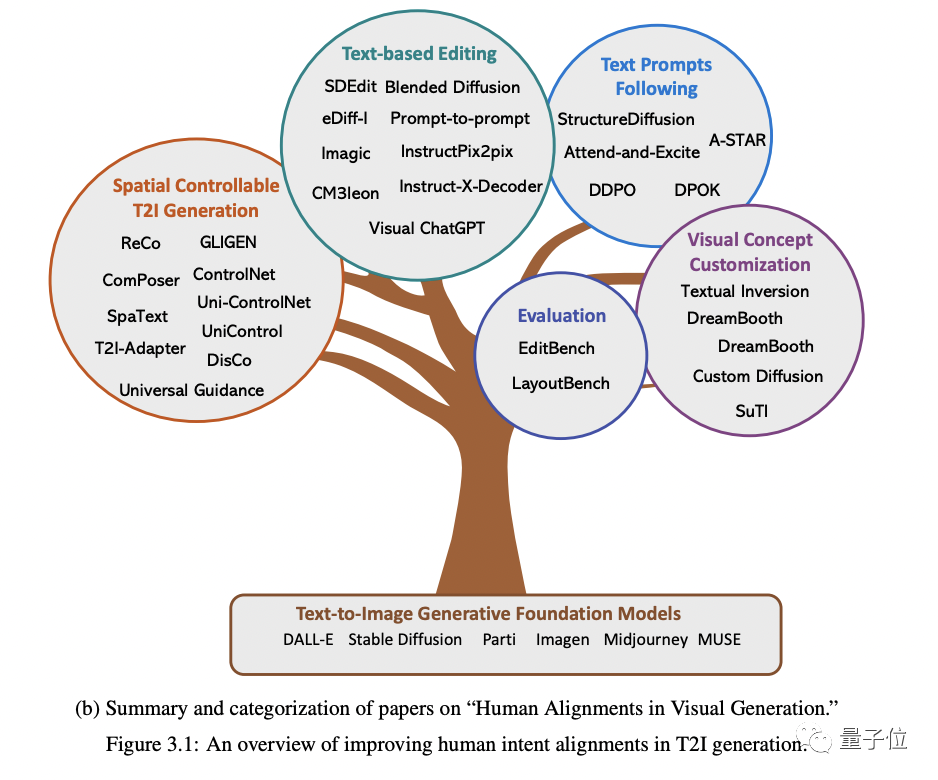
(focusing on image generation).
Specifically, it starts from four aspects: spatial controllable generation, text-based re-editing, better following text prompts and generation concept customization(concept customization) .
For example, the cost of different types of label annotations varies greatly, and the collection cost is much higher than that of text data, which results in the scale of visual data being usually much smaller than that of text corpora.
However, despite the many challenges, the author points out:
The CV field is increasingly interested in developing universal and unified vision systems, and three trends have emerged:
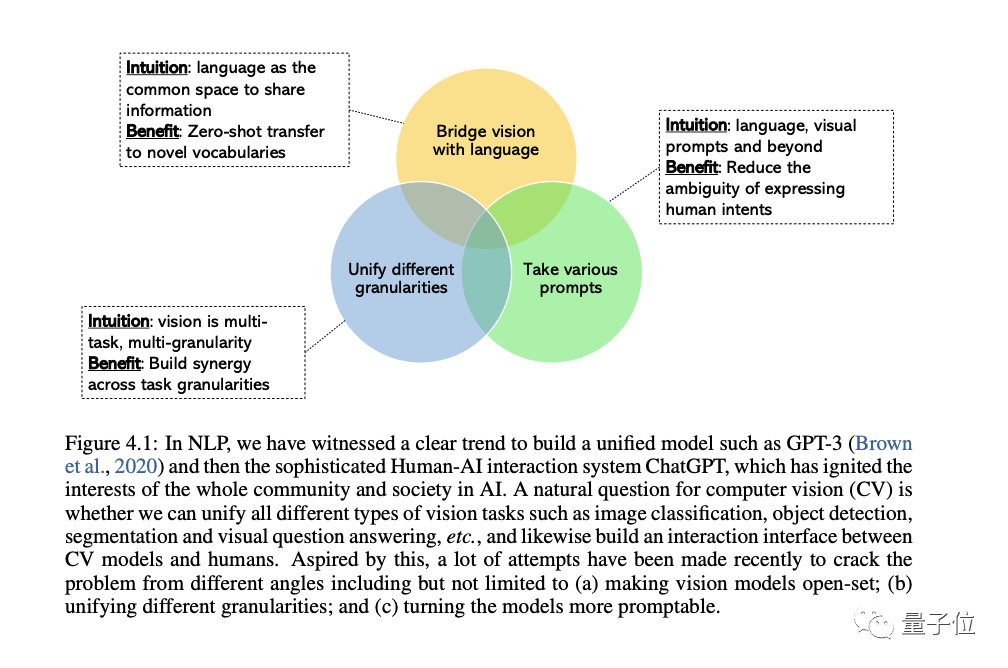
The first is from the closed set (closed-set) to the open set (open-set) , which can better combine text and Visually match.
The most important reason for the transition from specific tasks to general capabilities is that the cost of developing a new model for each new task is too high
The third is from a static model to a promptable model, LLM can Take different languages and contextual cues as input and produce the output the user wants without fine-tuning. The general vision model we want to build should have the same contextual learning capabilities.
4. Multimodal large models supported by LLM
This section comprehensively discusses multimodal large models.
First, we will conduct an in-depth study of the background and representative examples, discuss OpenAI’s multi-modal research progress, and identify existing research gaps in this field.
Next, the author examines in detail the importance of instruction fine-tuning in large language models.
Then, the author discusses the fine-tuning of instructions in multi-modal large models, including principles, significance and applications.
Finally, we will also cover some advanced topics in the field of multimodal models for a deeper understanding, including:
More modalities beyond vision and language, multimodality State-of-the-art context learning, efficient parameter training, and Benchmark.
5. Multimodal agent
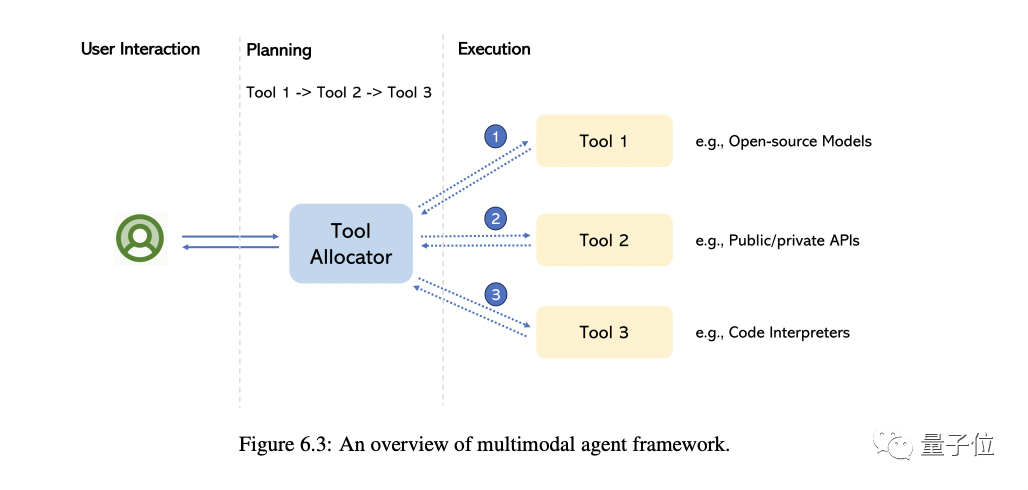
The so-called multimodal agent is a method that connects different multimodal experts with LLM to solve complex multimodal understanding problems.
In this part, the author mainly takes you to review the transformation of this model and summarizes the fundamental differences between this method and the traditional method.
Taking MM-REACT as an example, we will introduce in detail how this method works
We further summarize a comprehensive approach on how to build a multimodal agent, and its role in multimodal Emerging abilities in understanding. At the same time, we also cover how to easily extend this capability, including the latest and greatest LLM and potentially millions of tools
And of course, there are also some advanced topics discussed at the end, including how to improve/ Evaluate multi-modal agents, various applications built with them, etc.
Introduction to the author
There are 7 authors in this report
The initiator and overall person in charge is Chunyuan Li .
He is a principal researcher at Microsoft Redmond and holds a Ph.D. from Duke University. His recent research interests include large-scale pre-training in CV and NLP.
He was responsible for the opening introduction, closing summary, and the writing of the chapter "Multimodal large models trained using LLM". Rewritten content: He was responsible for writing the beginning and end of the article, as well as the chapter on "Multimodal large models trained using LLM"

There are 4 core authors:
- Zhe Gan
Currently, he has joined Apple AI/ML and is responsible for major Scale vision and multimodal base model research. Previously, he was the principal researcher of Microsoft Azure AI. He holds a bachelor's and master's degree from Peking University and a Ph.D. from Duke University.
- Zhengyuan Yang
He is a senior researcher at Microsoft. He graduated from the University of Rochester and received the ACM SIGMM Outstanding Doctoral Award and other honors. He studied as an undergraduate at the University of Science and Technology of China
- Jianwei Yang
Chief researcher of the deep learning group at Microsoft Research Redmond. PhD from Georgia Institute of Technology.
- Linjie Li(female)
Researcher in the Microsoft Cloud & AI Computer Vision Group, graduated with a master's degree from Purdue University.
They were respectively responsible for writing the remaining four thematic chapters.
Summary address: https://arxiv.org/abs/2309.10020
The above is the detailed content of The most comprehensive review of multimodal large models is here! 7 Microsoft researchers cooperated vigorously, 5 major themes, 119 pages of document. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
DDREASE is a tool for recovering data from file or block devices such as hard drives, SSDs, RAM disks, CDs, DVDs and USB storage devices. It copies data from one block device to another, leaving corrupted data blocks behind and moving only good data blocks. ddreasue is a powerful recovery tool that is fully automated as it does not require any interference during recovery operations. Additionally, thanks to the ddasue map file, it can be stopped and resumed at any time. Other key features of DDREASE are as follows: It does not overwrite recovered data but fills the gaps in case of iterative recovery. However, it can be truncated if the tool is instructed to do so explicitly. Recover data from multiple files or blocks to a single
 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 How to use Excel filter function with multiple conditions
Feb 26, 2024 am 10:19 AM
How to use Excel filter function with multiple conditions
Feb 26, 2024 am 10:19 AM
If you need to know how to use filtering with multiple criteria in Excel, the following tutorial will guide you through the steps to ensure you can filter and sort your data effectively. Excel's filtering function is very powerful and can help you extract the information you need from large amounts of data. This function can filter data according to the conditions you set and display only the parts that meet the conditions, making data management more efficient. By using the filter function, you can quickly find target data, saving time in finding and organizing data. This function can not only be applied to simple data lists, but can also be filtered based on multiple conditions to help you locate the information you need more accurately. Overall, Excel’s filtering function is a very practical
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
Recently, the military circle has been overwhelmed by the news: US military fighter jets can now complete fully automatic air combat using AI. Yes, just recently, the US military’s AI fighter jet was made public for the first time and the mystery was unveiled. The full name of this fighter is the Variable Stability Simulator Test Aircraft (VISTA). It was personally flown by the Secretary of the US Air Force to simulate a one-on-one air battle. On May 2, U.S. Air Force Secretary Frank Kendall took off in an X-62AVISTA at Edwards Air Force Base. Note that during the one-hour flight, all flight actions were completed autonomously by AI! Kendall said - "For the past few decades, we have been thinking about the unlimited potential of autonomous air-to-air combat, but it has always seemed out of reach." However now,
 The first robot to autonomously complete human tasks appears, with five fingers that are flexible and fast, and large models support virtual space training
Mar 11, 2024 pm 12:10 PM
The first robot to autonomously complete human tasks appears, with five fingers that are flexible and fast, and large models support virtual space training
Mar 11, 2024 pm 12:10 PM
This week, FigureAI, a robotics company invested by OpenAI, Microsoft, Bezos, and Nvidia, announced that it has received nearly $700 million in financing and plans to develop a humanoid robot that can walk independently within the next year. And Tesla’s Optimus Prime has repeatedly received good news. No one doubts that this year will be the year when humanoid robots explode. SanctuaryAI, a Canadian-based robotics company, recently released a new humanoid robot, Phoenix. Officials claim that it can complete many tasks autonomously at the same speed as humans. Pheonix, the world's first robot that can autonomously complete tasks at human speeds, can gently grab, move and elegantly place each object to its left and right sides. It can autonomously identify objects
