

The field of Text-to-Image has made tremendous progress over the past few years, especially in the era of artificial intelligence-generated content (AIGC). With the rise of the DALL-E model, more and more Text-to-Image models have emerged in the academic community, such as Imagen, Stable Diffusion, ControlNet and other models. However, despite the rapid development of the Text-to-Image field, existing models still face some challenges in stably generating images containing text
After trying the existing sota Vincent graph model, we can find , the text generated by the model is basically unreadable, similar to garbled characters, which greatly affects the overall aesthetics of the image.

The text information generated by the existing sota text generation model is poorly readable
After Survey, there are few studies in this area in academia. In fact, images containing text are very common in daily life, such as posters, book covers, and street signs. If AI can effectively generate such images, it will help assist designers in their work, inspire design inspiration, and reduce design burden. In addition, users may only wish to modify the text portion of the Vincent diagram model results and retain the results in other non-text areas.
In order not to change the original meaning, the content needs to be rewritten into Chinese. The original sentence does not need to appear

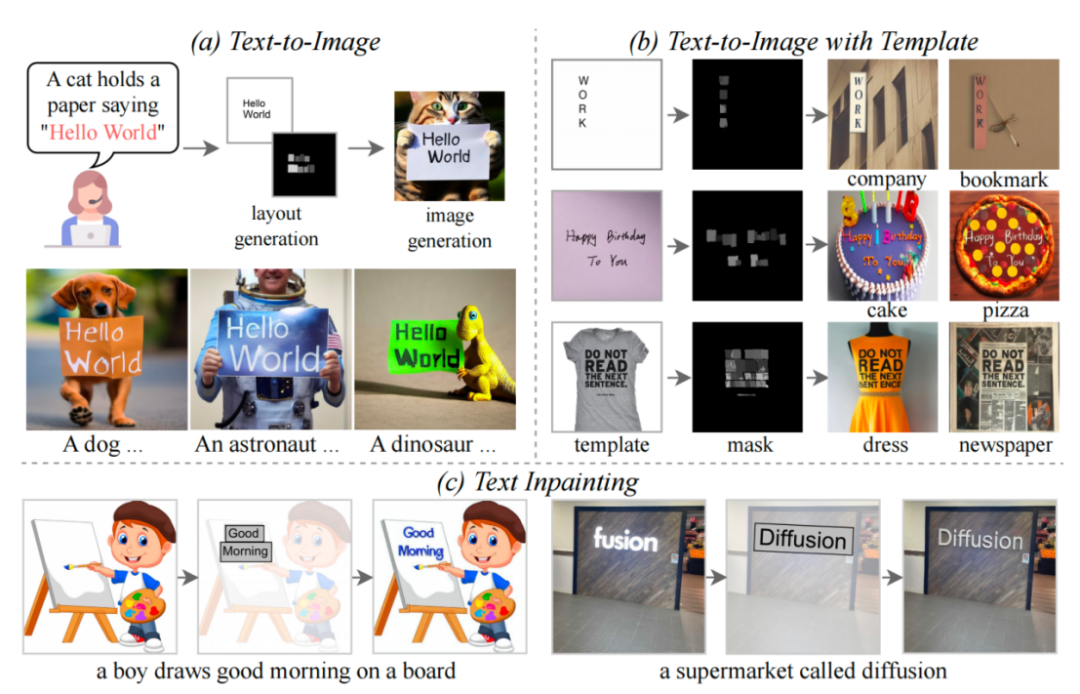
##The three functions of TextDiffuser
This article proposes The TextDiffuser model consists of two stages, the first stage generates Layout, and the second stage generates images.
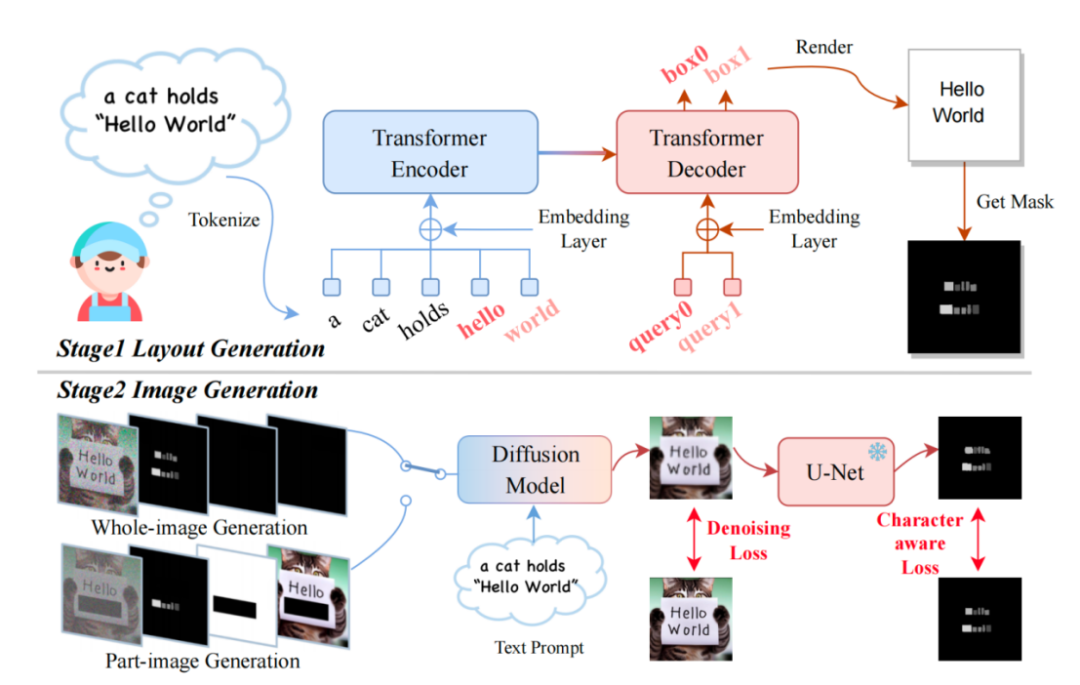
What needs to be rewritten is: TextDiffuser frame diagram
The model accepts a text Prompt , and then determine the Layout (that is, the coordinate frame) of each keyword based on the keywords in the Prompt. The researchers used Layout Transformer, used an encoder-decoder form to autoregressively output the coordinate box of keywords, and used Python's PILLOW library to render the text. In this process, you can also use Pillow's ready-made API to get the coordinate box of each character, which is equivalent to getting the character-level Box-level segmentation mask. Based on this information, the researchers tried to fine-tune Stable Diffusion.
They considered two situations. One is that the user wants to directly generate the entire image (called Whole-Image Generation). Another situation is Part-Image Generation, also called Text-inpainting in the paper, which means that the user gives an image and needs to modify certain text areas in the image.
In order to achieve the above two goals, the researchers redesigned the input features and increased the dimension from the original 4 dimensions to 17 dimensions. These include 4-dimensional noisy image features, 8-dimensional character information, 1-dimensional image mask, and 4-dimensional unmasked image features. If it is a whole image generation, the researchers set the mask area to the entire image; conversely, if it is a partial image generation, only a part of the image is masked. The training process of the diffusion model is similar to LDM. Friends who are interested in this can refer to the method section description in the original article
In the inference stage, TextDiffuser has a very flexible way of use and can be divided into Three types:

Constructed MARIO data
To train TextDiffuser, the researchers collected a thousand Ten thousand text images, as shown in the figure above, include three subsets: MARIO-LAION, MARIO-TMDB and MARIO-OpenLibrary
The researchers considered several aspects when filtering the data: for example After the image undergoes OCR, only images with a text quantity of [1,8] are retained. They filtered out texts with more than 8 texts, because these texts often contain a large amount of dense text, and the OCR results are generally less accurate, such as newspapers or complex design drawings. In addition, they set the text area to be greater than 10%. This rule is set to prevent the text area from being too small in the image.
After training on the MARIO-10M dataset, the researchers conducted quantitative and qualitative comparisons of TextDiffuser with existing methods. For example, in the overall image generation task, the images generated by this method have clearer and readable text, and the integration of the text area and the background area is better, as shown in the following figure
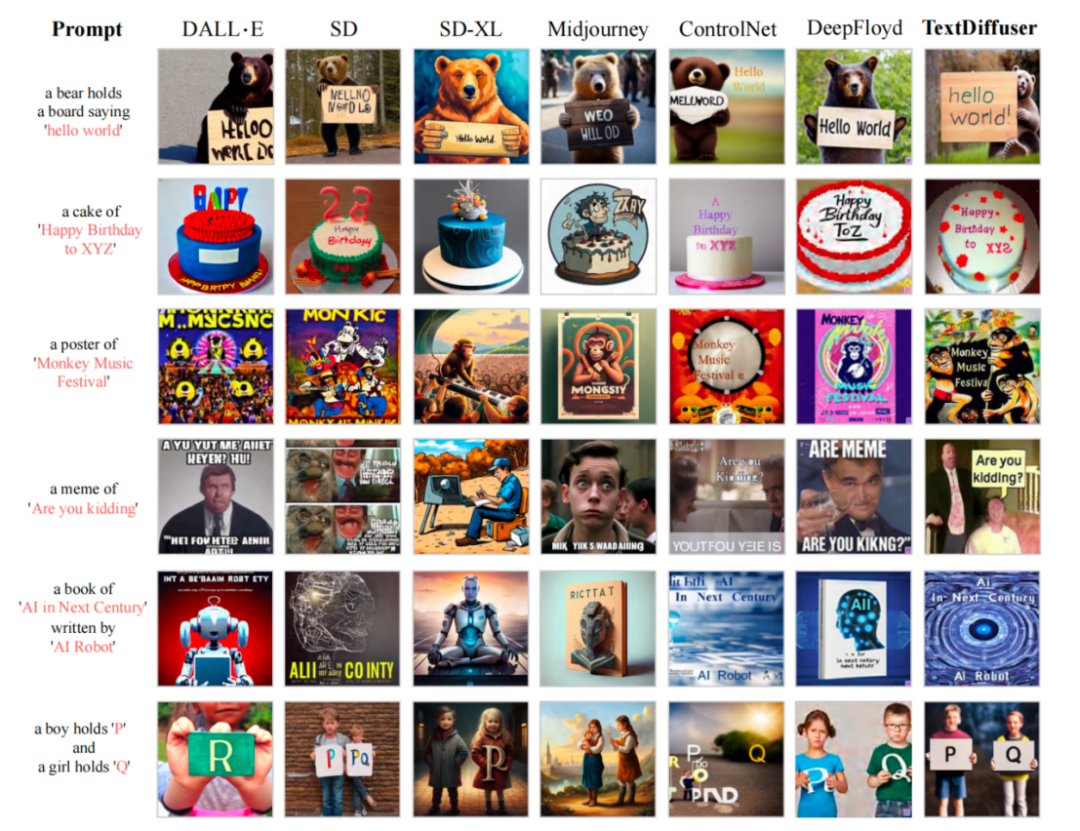
Comparison of text rendering performance with existing work
The researchers also conducted a series of qualitative experiments, and the results are shown in Table 1. Evaluation indicators include FID, CLIPScore and OCR. Especially for the OCR index, this research method has significantly improved compared to the comparative method
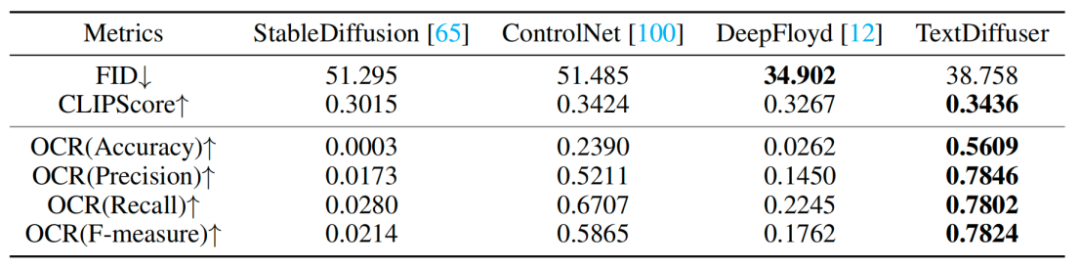
Rewritten content: The experimental results are shown in Table 1: Qualitative Experiment
For the Part-Image Generation task, the researchers tried to add or modify characters on a given image. The experimental results showed that the results generated by TextDiffuser were very natural.

Visualization of text repair function
In general, this article proposes The TextDiffuser model has made significant progress in the field of text rendering, capable of generating high-quality images containing readable text. In the future, researchers will further improve the effect of TextDiffuser.
The above is the detailed content of New title: TextDiffuser: No fear of text in images, providing higher quality text rendering. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



