
 Technology peripherals
AI
ICCV 2023 | ReMoDiffuse, a new paradigm that reshapes human action generation and integrates diffusion models and retrieval strategies, is here
Technology peripherals
AI
ICCV 2023 | ReMoDiffuse, a new paradigm that reshapes human action generation and integrates diffusion models and retrieval strategies, is here
ICCV 2023 | ReMoDiffuse, a new paradigm that reshapes human action generation and integrates diffusion models and retrieval strategies, is here

The human action generation task aims to generate realistic human action sequences to meet the needs of entertainment, virtual reality, robotics and other fields. Traditional generation methods include steps such as 3D character creation, keyframe animation and motion capture, which have many limitations, such as being time-consuming, requiring professional technical knowledge, involving expensive systems and software, and possible compatibility between different software and hardware systems. Sexual issues etc. With the development of deep learning, people began to try to use generative models to achieve automatic generation of human action sequences, for example, by inputting text descriptions and requiring the model to generate action sequences that match the text requirements. As diffusion models are introduced into the field, the consistency of generated actions with given text continues to improve.
However, although the naturalness of the generated actions has been improved, there is still a big gap between it and the user needs. In order to further improve the capabilities of the human motion generation algorithm, this paper proposes the ReMoDiffuse algorithm (Figure 1) based on MotionDiffuse [1]. By utilizing retrieval strategies, we find highly relevant reference samples and provide fine-grained reference features to generate higher quality action sequences

- ## Paper link: https://arxiv.org/pdf/2304.01116.pdf
- GitHub link: https://github.com/mingyuan-zhang/ReMoDiffuse
- Project homepage: https://mingyuan-zhang.github.io/projects/ReMoDiffuse.html
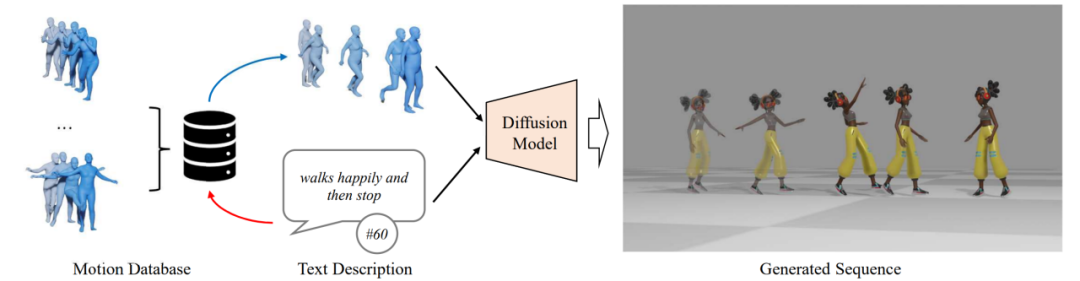 Figure 1. Overview of ReMoDiffuse
Figure 1. Overview of ReMoDiffuse
Method introduction
The main process of ReMoDiffuse is divided into two stages: retrieval and diffusion. In the retrieval stage, ReMoDiffuse uses hybrid retrieval technology to retrieve information-rich samples from external multi-modal databases based on user input text and expected action sequence length, providing powerful guidance for action generation. In the diffusion stage, ReMoDiffuse uses the information obtained in the retrieval stage to generate a motion sequence that is semantically consistent with the user input through an efficient model structure. In order to ensure efficient retrieval, ReMoDiffuse carefully designed the following data flow for the retrieval stage (Figure 2): There are three types of data involved in the retrieval process, namely user input text, expected action sequence length, and an external multi-modal database containing multiple pairs. When retrieving the most relevant samples, ReMoDiffuse uses the formula to calculate the similarity between the samples in each database and the user input. The first item here is to calculate the cosine similarity between the user input text and the text of the database entity using the text encoder of the pre-trained CLIP [2] model, and the second item calculates the difference between the expected action sequence length and the action sequence length of the database entity. The relative difference is taken as the kinematic similarity. After calculating the similarity score, ReMoDiffuse selects the top k samples with similar similarity as the retrieved samples, and extracts the text feature 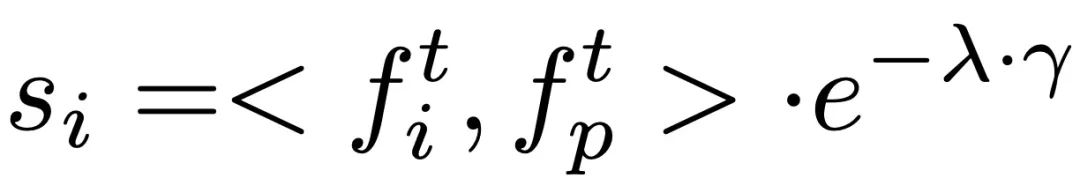 and action feature
and action feature 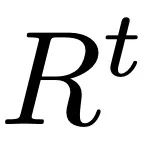 . These two, together with the features extracted from the text input by the user, are used as input signals to the diffusion stage to guide action generation.
. These two, together with the features extracted from the text input by the user, are used as input signals to the diffusion stage to guide action generation. 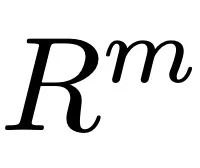

The diffusion process (Figure 3.c) consists of two parts: the forward process and the reverse process. In the forward process, ReMoDiffuse gradually adds Gaussian noise to the original motion data and finally converts it into random noise. The inverse process focuses on removing noise and generating realistic motion samples. Starting from a random Gaussian noise, ReMoDiffuse uses a Semantic Modulation Module (SMT) (Figure 3.a) at each step of the inverse process to estimate the true distribution and gradually remove the noise based on the conditional signal. The SMA module in SMT here will integrate all condition information into the generated sequence features, which is the core module proposed in this article #For the SMA layer (Figure 3.b), we use the efficient attention mechanism (Efficient Attention) [3] to Accelerates the calculation of the attention module and creates a global feature map that emphasizes global information more. This feature map provides more comprehensive semantic clues for action sequences, thereby improving the performance of the model. The core goal of the SMA layer is to optimize the generation of action sequences 1. The Q vector specifically represents the expected action sequence 2.K vector as an indexing mechanism comprehensively considers multiple factors, including current action sequence features 3.V vectors provide the actual features needed to generate actions. Similar to the K vector, the V vector takes into account the retrieval sample, user input, and the current action sequence. Since there is no direct correlation between the text description feature of the retrieved sample and the generated action, we choose not to use this feature when calculating the V vector to avoid unnecessary information interference Combined with the global attention template mechanism of Efficient Attention, the SMA layer uses the auxiliary information from the retrieval sample, the semantic information of the user text, and the feature information of the sequence to be denoised to establish a series of comprehensive global templates, making all conditions The information can be fully absorbed by the sequence to be generated. In order to rewrite the content, the original text needs to be converted into Chinese. Here’s what it looks like after rewriting:
Research Design and Experimental Results We evaluated ReMoDiffuse on two datasets, HumanML3D [4] and KIT-ML [5]. The experimental results (Tables 1 and 2) demonstrate the powerful performance and advantages of our proposed ReMoDiffuse framework from the perspectives of text consistency and action quality Citation Mingyuan Zhang, Cai Zhonggang, Pan Liang, Hong Fangzhou, Guo Xinying, Yang Lei, and Liu Ziwei. Motiondiffuse: Text-driven human motion generation based on diffusion models. arXiv preprint arXiv:2208.15001, 2022 [2] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020, 2021. [4 ] Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating diverse and natural 3d human motions from text. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5152 –5161, 2022. What needs to be rewritten is: [5] Matthias Plappert, Christian Mandery and Tamim Asfour. "Motor Language Dataset". Big Data, 4(4):236-252, 2016 [6] Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H Bermano . Human motion diffusion model. In The Eleventh International Conference on Learning Representations, 2022.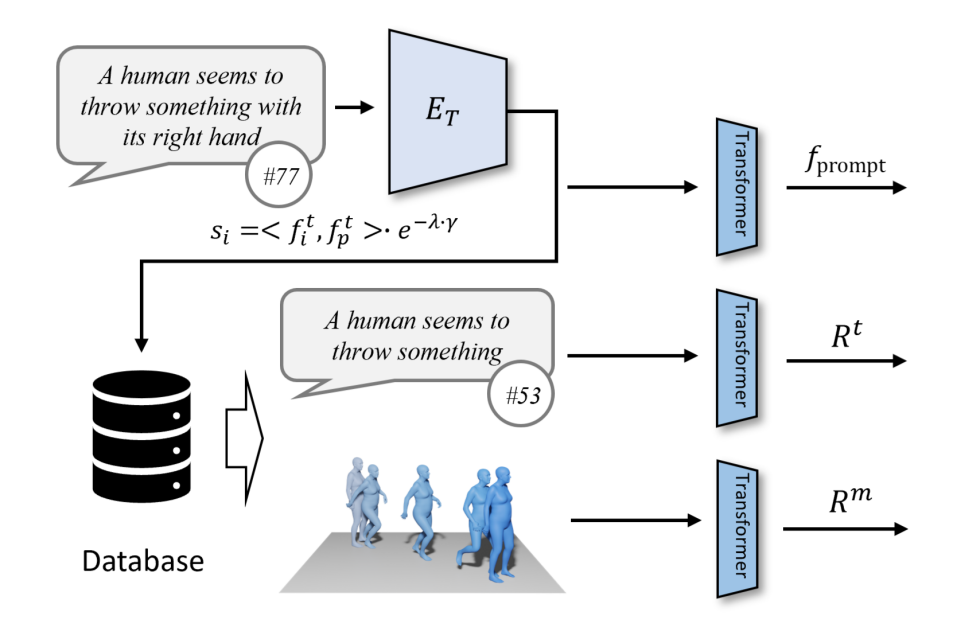 Figure 2: Retrieval phase of ReMoDiffuse
Figure 2: Retrieval phase of ReMoDiffuse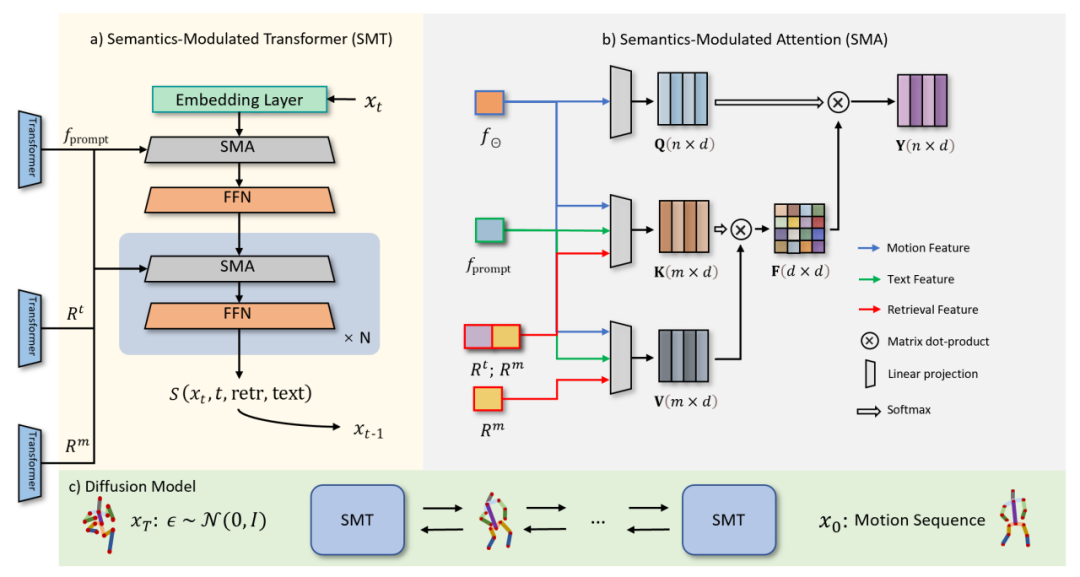 Fig. 3: Diffusion stage of ReMoDiffuse
Fig. 3: Diffusion stage of ReMoDiffuse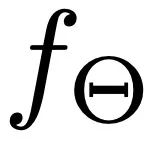 by aggregating conditional information. Under this framework:
by aggregating conditional information. Under this framework:  that we expect to generate based on conditional information. , semantic features input by the user
that we expect to generate based on conditional information. , semantic features input by the user , and features obtained from retrieval samples
, and features obtained from retrieval samples and
and . Among them, represents the action sequence features obtained from the retrieval sample, and represents the text description feature obtained from the retrieval sample. This comprehensive construction method ensures the effectiveness of K vectors in the indexing process.
. Among them, represents the action sequence features obtained from the retrieval sample, and represents the text description feature obtained from the retrieval sample. This comprehensive construction method ensures the effectiveness of K vectors in the indexing process. 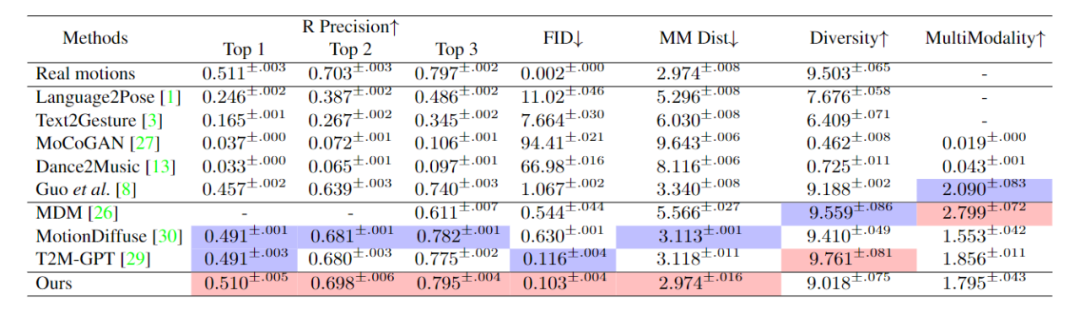 Table 1. Performance of different methods on the HumanML3D test set
Table 1. Performance of different methods on the HumanML3D test set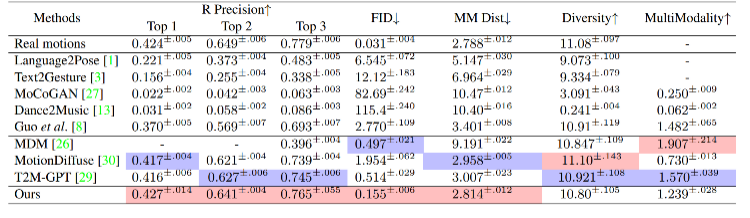 ##Table 2. Different Method performance on the KIT-ML test set
##Table 2. Different Method performance on the KIT-ML test set Figure 4. Action sequence generated by ReMoDiffuse Comparison with action sequences generated by other methods
Figure 4. Action sequence generated by ReMoDiffuse Comparison with action sequences generated by other methods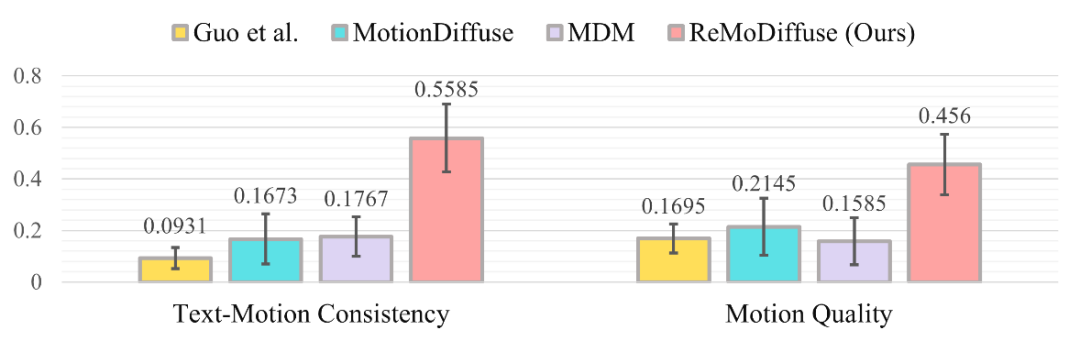 Figure 5: Distribution of user survey results
Figure 5: Distribution of user survey results
The above is the detailed content of ICCV 2023 | ReMoDiffuse, a new paradigm that reshapes human action generation and integrates diffusion models and retrieval strategies, is here. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 A Diffusion Model Tutorial Worth Your Time, from Purdue University
Apr 07, 2024 am 09:01 AM
A Diffusion Model Tutorial Worth Your Time, from Purdue University
Apr 07, 2024 am 09:01 AM
Diffusion can not only imitate better, but also "create". The diffusion model (DiffusionModel) is an image generation model. Compared with the well-known algorithms such as GAN and VAE in the field of AI, the diffusion model takes a different approach. Its main idea is a process of first adding noise to the image and then gradually denoising it. How to denoise and restore the original image is the core part of the algorithm. The final algorithm is able to generate an image from a random noisy image. In recent years, the phenomenal growth of generative AI has enabled many exciting applications in text-to-image generation, video generation, and more. The basic principle behind these generative tools is the concept of diffusion, a special sampling mechanism that overcomes the limitations of previous methods.
 Generate PPT with one click! Kimi: Let the 'PPT migrant workers' become popular first
Aug 01, 2024 pm 03:28 PM
Generate PPT with one click! Kimi: Let the 'PPT migrant workers' become popular first
Aug 01, 2024 pm 03:28 PM
Kimi: In just one sentence, in just ten seconds, a PPT will be ready. PPT is so annoying! To hold a meeting, you need to have a PPT; to write a weekly report, you need to have a PPT; to make an investment, you need to show a PPT; even when you accuse someone of cheating, you have to send a PPT. College is more like studying a PPT major. You watch PPT in class and do PPT after class. Perhaps, when Dennis Austin invented PPT 37 years ago, he did not expect that one day PPT would become so widespread. Talking about our hard experience of making PPT brings tears to our eyes. "It took three months to make a PPT of more than 20 pages, and I revised it dozens of times. I felt like vomiting when I saw the PPT." "At my peak, I did five PPTs a day, and even my breathing was PPT." If you have an impromptu meeting, you should do it
 All CVPR 2024 awards announced! Nearly 10,000 people attended the conference offline, and a Chinese researcher from Google won the best paper award
Jun 20, 2024 pm 05:43 PM
All CVPR 2024 awards announced! Nearly 10,000 people attended the conference offline, and a Chinese researcher from Google won the best paper award
Jun 20, 2024 pm 05:43 PM
In the early morning of June 20th, Beijing time, CVPR2024, the top international computer vision conference held in Seattle, officially announced the best paper and other awards. This year, a total of 10 papers won awards, including 2 best papers and 2 best student papers. In addition, there were 2 best paper nominations and 4 best student paper nominations. The top conference in the field of computer vision (CV) is CVPR, which attracts a large number of research institutions and universities every year. According to statistics, a total of 11,532 papers were submitted this year, and 2,719 were accepted, with an acceptance rate of 23.6%. According to Georgia Institute of Technology’s statistical analysis of CVPR2024 data, from the perspective of research topics, the largest number of papers is image and video synthesis and generation (Imageandvideosyn
 Five programming software for getting started with learning C language
Feb 19, 2024 pm 04:51 PM
Five programming software for getting started with learning C language
Feb 19, 2024 pm 04:51 PM
As a widely used programming language, C language is one of the basic languages that must be learned for those who want to engage in computer programming. However, for beginners, learning a new programming language can be difficult, especially due to the lack of relevant learning tools and teaching materials. In this article, I will introduce five programming software to help beginners get started with C language and help you get started quickly. The first programming software was Code::Blocks. Code::Blocks is a free, open source integrated development environment (IDE) for
 From bare metal to a large model with 70 billion parameters, here is a tutorial and ready-to-use scripts
Jul 24, 2024 pm 08:13 PM
From bare metal to a large model with 70 billion parameters, here is a tutorial and ready-to-use scripts
Jul 24, 2024 pm 08:13 PM
We know that LLM is trained on large-scale computer clusters using massive data. This site has introduced many methods and technologies used to assist and improve the LLM training process. Today, what we want to share is an article that goes deep into the underlying technology and introduces how to turn a bunch of "bare metals" without even an operating system into a computer cluster for training LLM. This article comes from Imbue, an AI startup that strives to achieve general intelligence by understanding how machines think. Of course, turning a bunch of "bare metal" without an operating system into a computer cluster for training LLM is not an easy process, full of exploration and trial and error, but Imbue finally successfully trained an LLM with 70 billion parameters. and in the process accumulate
 PyCharm Community Edition Installation Guide: Quickly master all the steps
Jan 27, 2024 am 09:10 AM
PyCharm Community Edition Installation Guide: Quickly master all the steps
Jan 27, 2024 am 09:10 AM
Quick Start with PyCharm Community Edition: Detailed Installation Tutorial Full Analysis Introduction: PyCharm is a powerful Python integrated development environment (IDE) that provides a comprehensive set of tools to help developers write Python code more efficiently. This article will introduce in detail how to install PyCharm Community Edition and provide specific code examples to help beginners get started quickly. Step 1: Download and install PyCharm Community Edition To use PyCharm, you first need to download it from its official website
 AI in use | AI created a life vlog of a girl living alone, which received tens of thousands of likes in 3 days
Aug 07, 2024 pm 10:53 PM
AI in use | AI created a life vlog of a girl living alone, which received tens of thousands of likes in 3 days
Aug 07, 2024 pm 10:53 PM
Editor of the Machine Power Report: Yang Wen The wave of artificial intelligence represented by large models and AIGC has been quietly changing the way we live and work, but most people still don’t know how to use it. Therefore, we have launched the "AI in Use" column to introduce in detail how to use AI through intuitive, interesting and concise artificial intelligence use cases and stimulate everyone's thinking. We also welcome readers to submit innovative, hands-on use cases. Video link: https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ Recently, the life vlog of a girl living alone became popular on Xiaohongshu. An illustration-style animation, coupled with a few healing words, can be easily picked up in just a few days.
 A must-read for technical beginners: Analysis of the difficulty levels of C language and Python
Mar 22, 2024 am 10:21 AM
A must-read for technical beginners: Analysis of the difficulty levels of C language and Python
Mar 22, 2024 am 10:21 AM
Title: A must-read for technical beginners: Difficulty analysis of C language and Python, requiring specific code examples In today's digital age, programming technology has become an increasingly important ability. Whether you want to work in fields such as software development, data analysis, artificial intelligence, or just learn programming out of interest, choosing a suitable programming language is the first step. Among many programming languages, C language and Python are two widely used programming languages, each with its own characteristics. This article will analyze the difficulty levels of C language and Python
