
 Backend Development
Python Tutorial
How to extract key sentences from PDF files using Python for NLP?
Backend Development
Python Tutorial
How to extract key sentences from PDF files using Python for NLP?
How to extract key sentences from PDF files using Python for NLP?


How to use Python for NLP to extract key sentences from PDF files?
Introduction:
With the rapid development of information technology, Natural Language Processing (NLP) plays an important role in fields such as text analysis, information extraction and machine translation. In practical applications, it is often necessary to extract key information from a large amount of text data, such as extracting key sentences from PDF files. This article will introduce how to use Python's NLP package to extract key sentences from PDF files, and provide detailed code examples.
Step 1: Install the required Python libraries
Before we begin, we need to install several Python libraries to facilitate subsequent text processing and PDF file parsing.
1. Install the nltk library:
Enter the following command on the command line to install the nltk library:
1 |
|
2. Install the pdfminer library:
Enter the following command on the command line to install pdfminer library:
1 |
|
Step 2: Parse PDF files
First, we need to convert the PDF file into plain text format. The pdfminer library provides us with the functionality to parse PDF files.
The following is a function that can convert PDF files into plain text:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
Step 3: Extract key sentences
Next, we need to use the nltk library to extract key sentences. nltk provides rich functions for text tokenization, word segmentation and sentence segmentation.
The following is a function that can extract key sentences from the given text:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
Step 4: Complete sample code
The following is a complete sample code that demonstrates how to extract the key sentences from PDF Extract key sentences from the file:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
|
Summary:
This article introduces the method of using Python's NLP package to extract key sentences from PDF files. By converting PDF files to plain text through the pdfminer library, and using the tokenization and sentence segmentation functions of the nltk library, we can easily extract key sentences. This method is widely used in fields such as information extraction, text summarization and knowledge graph construction. I hope the content of this article is helpful to you and can be used in practical applications.
The above is the detailed content of How to extract key sentences from PDF files using Python for NLP?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to merge PDFs on iPhone
Feb 02, 2024 pm 04:05 PM
How to merge PDFs on iPhone
Feb 02, 2024 pm 04:05 PM
When working with multiple documents or multiple pages of the same document, you may want to combine them into a single file to share with others. For easy sharing, Apple allows you to merge multiple PDF files into one file to avoid sending multiple files. In this post, we will help you know all the ways to merge two or more PDFs into one PDF file on iPhone. How to Merge PDFs on iPhone On iOS, you can merge PDF files into one in two ways – using the Files app and the Shortcuts app. Method 1: Using Files App The easiest way to merge two or more PDFs into one file is to use the Files app. Open on iPhone
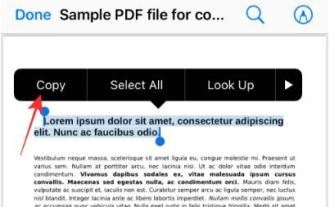 3 Ways to Get Text from PDF on iPhone
Mar 16, 2024 pm 09:20 PM
3 Ways to Get Text from PDF on iPhone
Mar 16, 2024 pm 09:20 PM
Apple's Live Text feature recognizes text, handwritten notes and numbers in photos or through the Camera app and allows you to paste that information onto any other app. But what to do when you're working with a PDF and want to extract text from it? In this post, we will explain all the ways to extract text from PDF files on iPhone. How to Get Text from PDF File on iPhone [3 Methods] Method 1: Drag Text on PDF The easiest way to extract text from PDF is to copy it, just like on any other app with text . 1. Open the PDF file you want to extract text from, then long press anywhere on the PDF and start dragging the part of the text you want to copy. 2
 How to verify signature in PDF
Feb 18, 2024 pm 05:33 PM
How to verify signature in PDF
Feb 18, 2024 pm 05:33 PM
We usually receive PDF files from the government or other agencies, some with digital signatures. After verifying the signature, we see the SignatureValid message and a green check mark. If the signature is not verified, the validity is unknown. Verifying signatures is important, let’s see how to do it in PDF. How to Verify Signatures in PDF Verifying signatures in PDF format makes it more trustworthy and the document more likely to be accepted. You can verify signatures in PDF documents in the following ways. Open the PDF in Adobe Reader Right-click the signature and select Show Signature Properties Click the Show Signer Certificate button Add the signature to the Trusted Certificates list from the Trust tab Click Verify Signature to complete the verification Let
 How to convert pdg files to pdf
Nov 14, 2023 am 10:41 AM
How to convert pdg files to pdf
Nov 14, 2023 am 10:41 AM
Methods include: 1. Use professional document conversion tools; 2. Use online conversion tools; 3. Use virtual printers.
 How to import and annotate PDFs in Apple Notes
Oct 13, 2023 am 08:05 AM
How to import and annotate PDFs in Apple Notes
Oct 13, 2023 am 08:05 AM
In iOS 17 and MacOS Sonoma, Apple added the ability to open and annotate PDFs directly in the Notes app. Read on to find out how it's done. In the latest versions of iOS and macOS, Apple has updated the Notes app to support inline PDFs, which means you can insert PDFs into Notes and then read, annotate, and collaborate on the document. This feature also works with scanned documents and is available on both iPhone and iPad. Annotate a PDF in Notes on iPhone and iPad If you're using an iPhone and want to annotate a PDF in Notes, the first thing to do is select the PDF file
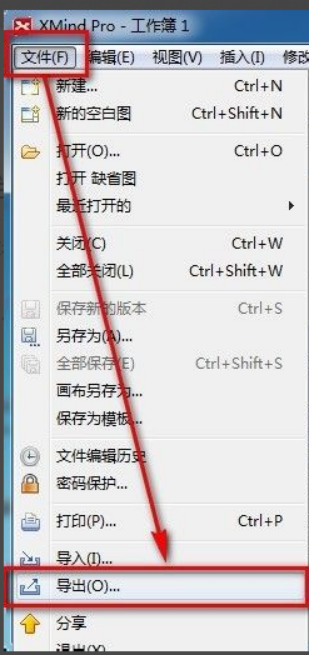 How to export xmind files to pdf files
Mar 20, 2024 am 10:30 AM
How to export xmind files to pdf files
Mar 20, 2024 am 10:30 AM
xmind is a very practical mind mapping software. It is a map form made using people's thinking and inspiration. After we create the xmind file, we usually convert it into a pdf file format to facilitate everyone's dissemination and use. Then How to export xmind files to pdf files? Below are the specific steps for your reference. 1. First, let’s demonstrate how to export the mind map to a PDF document. Select the [File]-[Export] function button. 2. Select [PDF document] in the newly appeared interface and click the [Next] button. 3. Select settings in the export interface: paper size, orientation, resolution and document storage location. After completing the settings, click the [Finish] button. 4. If you click the [Finish] button
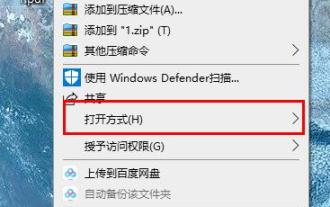 Learn how to rotate PDF files using edge browser shortcut keys
Jan 05, 2024 am 09:17 AM
Learn how to rotate PDF files using edge browser shortcut keys
Jan 05, 2024 am 09:17 AM
Although pdf files are very convenient to use, many friends still like to use word to edit and view them, so how to convert them? Let’s take a look at the detailed operation method below. Edge browser pdf rotation shortcut key: A: The shortcut key for rotation is F9. 1. Right-click the pdf file and select "Open with". 2. Select "Microsoft edge" to open the pdf file. 3. After entering the pdf file, a taskbar will appear below. 4. Click the rotation button next to the "+" sign to rotate right.
 Solve the problem of downloading PDF files in PHP7
Feb 29, 2024 am 11:12 AM
Solve the problem of downloading PDF files in PHP7
Feb 29, 2024 am 11:12 AM
Solve the problems encountered in downloading PDF files with PHP7 In web development, we often encounter the need to use PHP to download files. Especially downloading PDF files can help users obtain necessary information or files. However, sometimes you will encounter some problems when downloading PDF files in PHP7, such as garbled characters and incomplete downloads. This article will detail how to solve problems you may encounter when downloading PDF files in PHP7 and provide some specific code examples. Problem analysis: In PHP7, due to character encoding and H
