

How to build an AB experiment system in user growth scenarios?


1. Problems faced by experiments in new user scenarios
1. UG panorama
This is a panoramic view of UG.
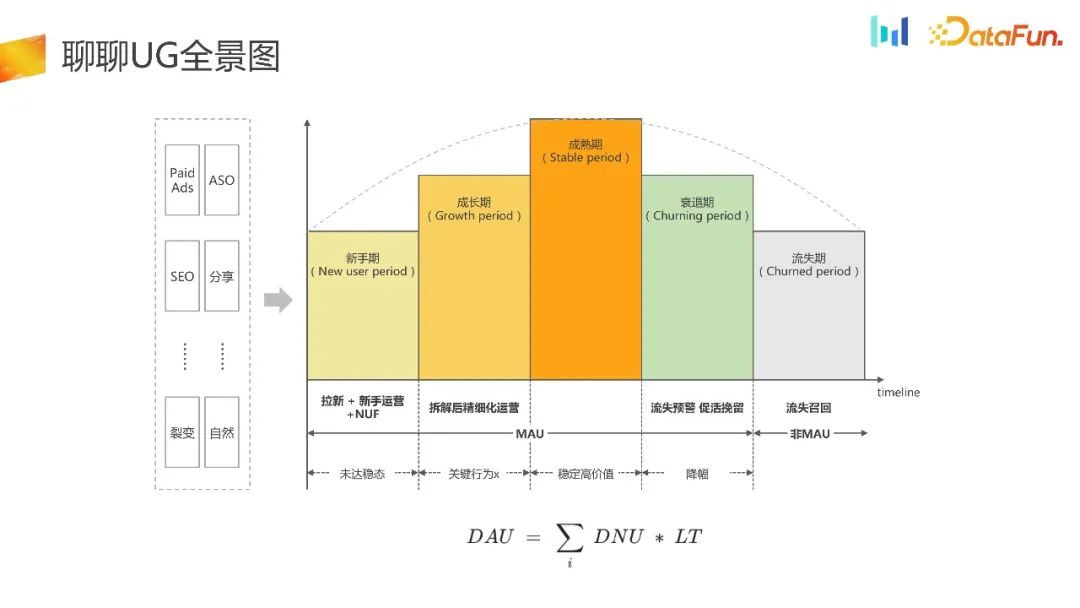
UG Acquire customers and divert traffic to the APP through channels such as Paid Ads, ASO, SEO and other channels. Next, we will do some operations and guidance for novices to activate users and bring them into the maturity stage. Subsequent users may slowly become inactive, enter a decline period, or even enter a churn period. During this period, we will do some early warnings for churn, recall to promote activation, and later some recalls for lost users.
can be summarized as the formula in the above figure, that is, DAU is equal to DNU times LT. All work in the UG scenario can be dismantled based on this formula.
2. Principle of AB experiment
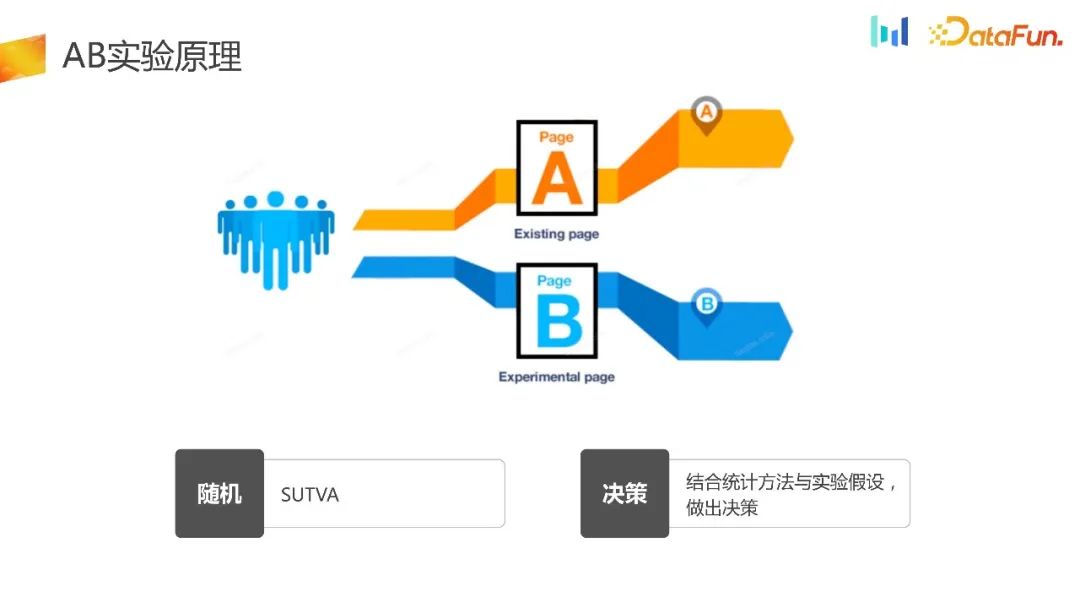
The purpose of AB experiment is to completely randomize the distribution of traffic , using different strategies for the experimental group and different control groups. Finally, scientific decisions are made by combining statistical methods and experimental hypotheses, which constitutes the framework of the entire experiment. There are currently two types of experimental distribution on the market: experimental platform distribution and client local distribution
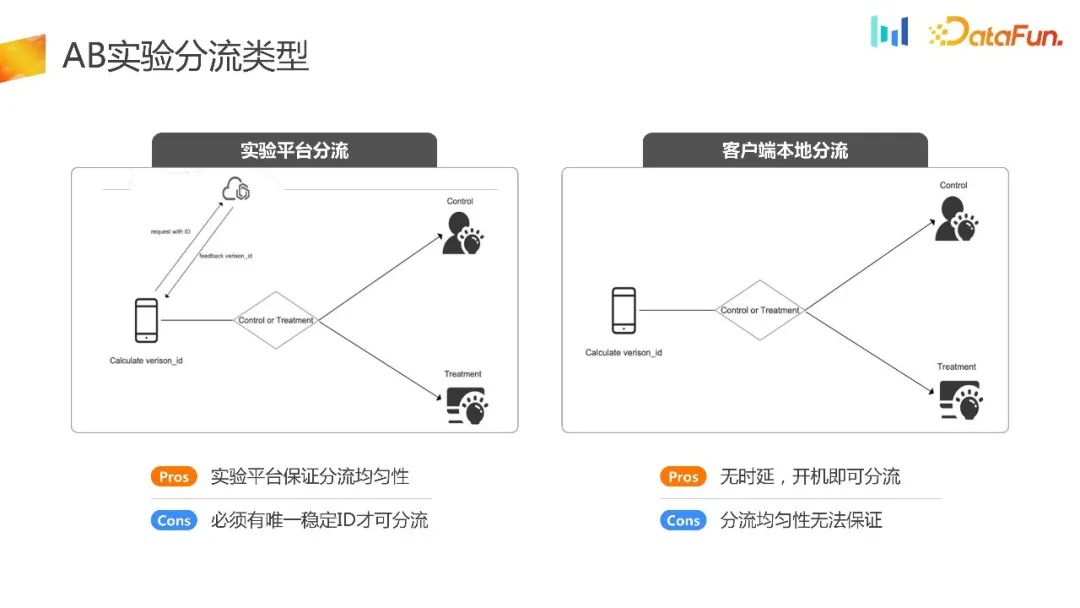
There are prerequisites for experimental platform distribution. It is necessary for the device to obtain a stable ID after completing initialization. Based on this ID, the experimental platform is requested to complete the offloading-related logic, and the offloading ID is returned to the endpoint, and then the endpoint makes corresponding strategies based on the received ID. Its advantage is that it has an experimental platform that can ensure the uniformity and stability of the shunt. Its disadvantage is that the equipment must be initialized before experimental shunting can be carried out.
Another offloading method is client local offloading. This method is relatively niche and is mainly suitable for some UG scenes, advertising screen opening scenes and performance initialization scenes. In this way, all offloading logic is completed when the client is initialized. Its advantages are obvious, that is, there is no delay and the distribution can be carried out immediately after powering on. Logically speaking, its distribution uniformity can also be guaranteed. However, in actual business scenarios, there are often problems with its distribution uniformity. The reasons will be introduced next
3. Problems faced by the new user scenario AB experiment
The first problem actually faced by the UG scenario is to divert traffic as early as possible.
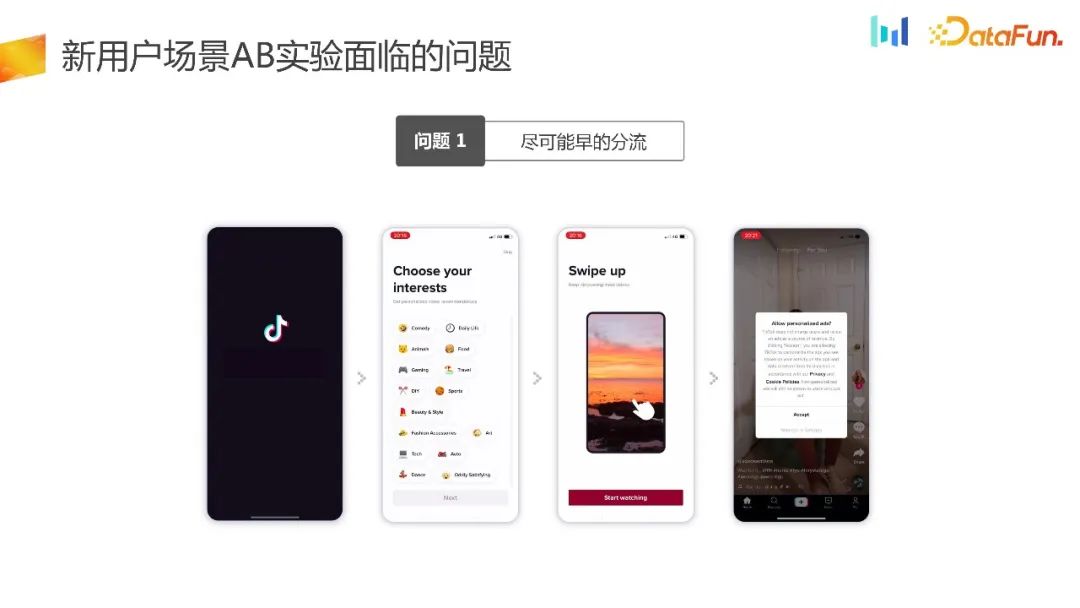
Here is an example, such as the traffic acceptance page here. The product manager feels that the UI can be optimized to improve the core indicators. In such a scenario, we hope that the experiment will be triaged as soon as possible.
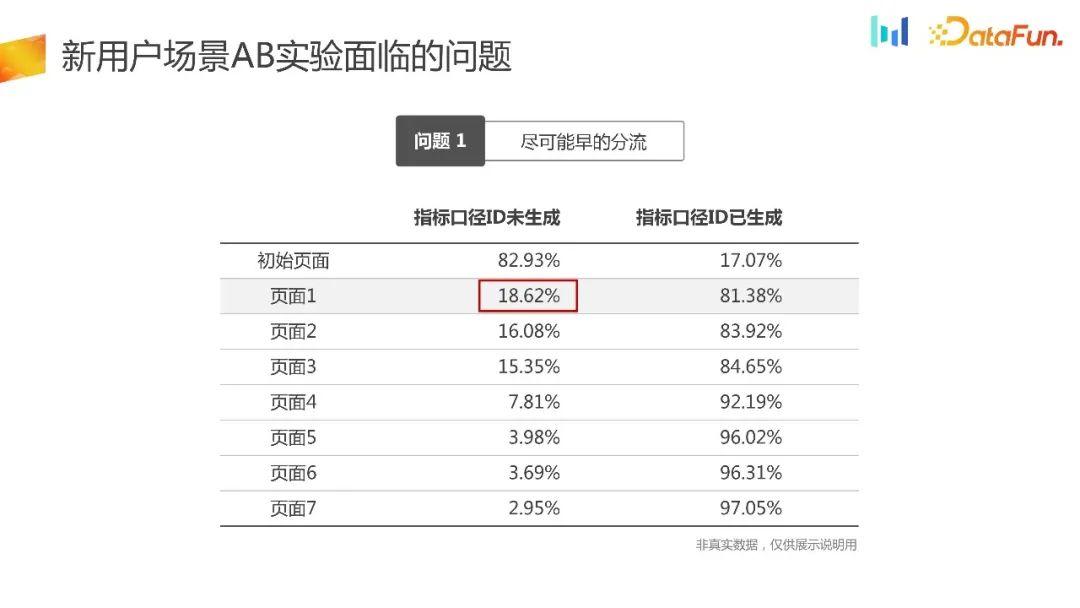
During the offloading process of page 1, the device will be initialized and obtain the ID. 18.62% of users cannot generate IDs. If the traditional experimental platform diversion method is used, 18.62% of users will not be grouped, resulting in an inherent selection bias problem
#In addition, the traffic of new users is very valuable. 18.62% of new users cannot be used in the experiment, which will also cause a great loss in the duration of the experiment and traffic utilization efficiency.
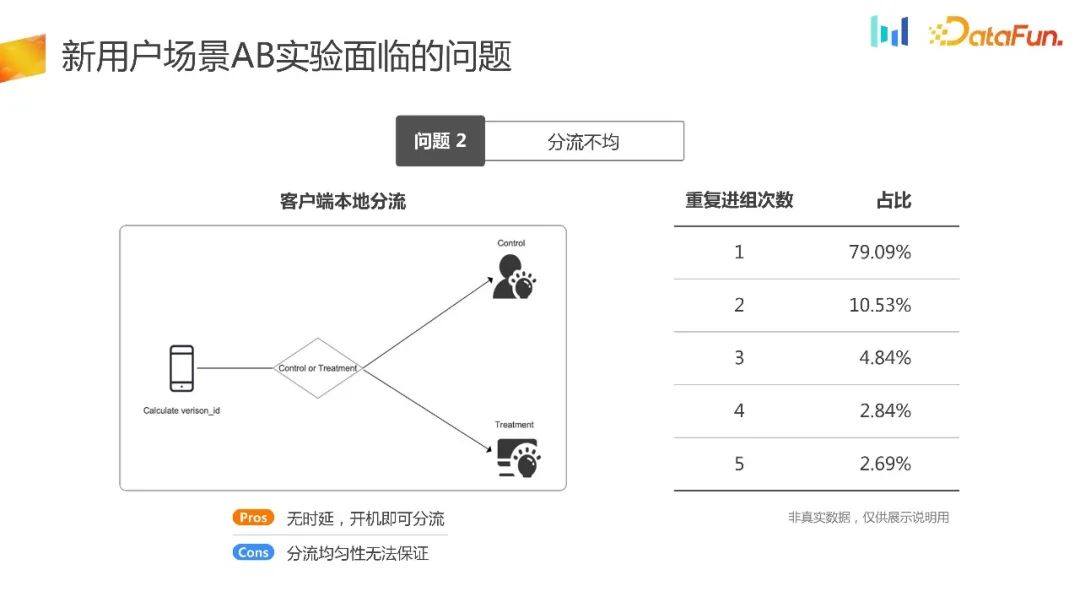
In the future, to solve the problem of offloading experiments as early as possible, we will use the client to offload experiments locally. The advantage is that the offloading is completed when the device is initialized. The principle is that first, when initializing on the terminal, it can generate random numbers by itself, hash the random numbers and then group them in the same way, thereby generating an experimental group and a control group. In principle, it should be possible to ensure that the traffic distribution is even. However, through the set of data in the above figure, we can find that more than 21% of users repeatedly enter different groups.
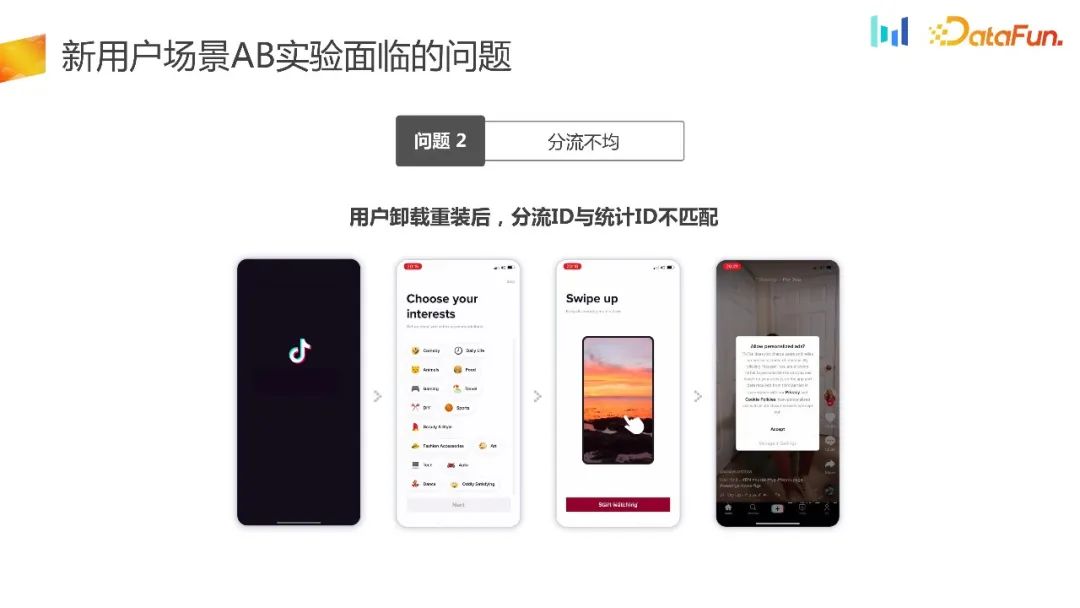
There is a scenario where users of some very popular products, such as Honor of Kings or Douyin, are easily addicted. New users will uninstall and reinstall multiple times during the experimental cycle. According to the local diversion logic just mentioned, the generation and diversion of random numbers will allow users to enter different groups, so that the diversion ID and statistical ID cannot match one-to-one. This caused the problem of uneven distribution.
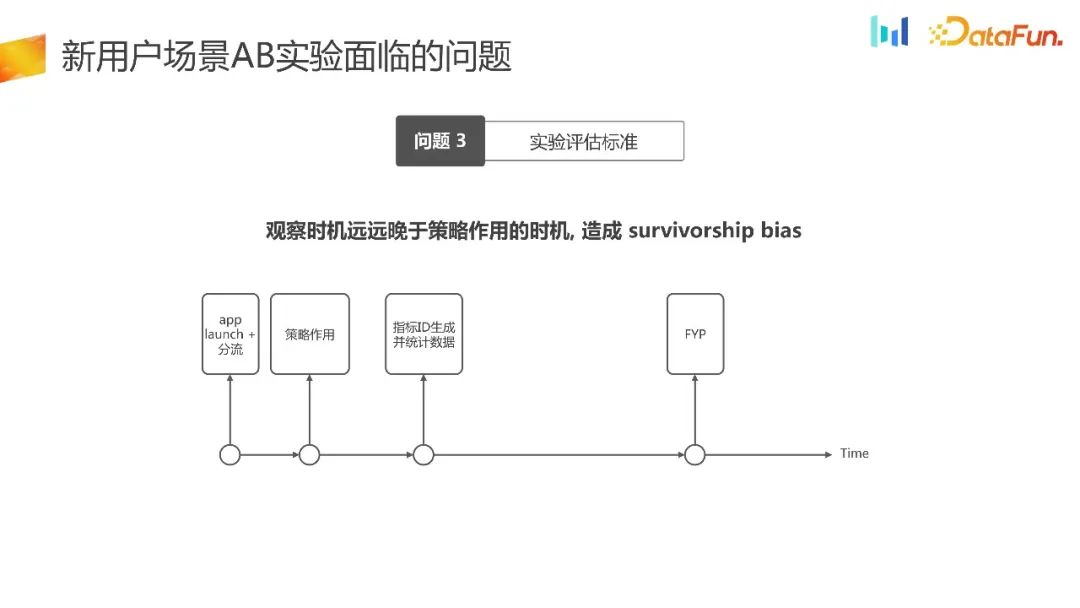
In new user scenarios, we also face the problem of experimental evaluation standards.
We have reorganized the time chart of this scenario of new user traffic. On application startup, we chose to offload. Assume that we can achieve uniform distribution timing and produce corresponding strategic effects at the same time. Next, the timing of generating the indicator statistical ID is later than the timing of the strategy effect, and only then can the data be observed. The timing of data observation lags far behind the timing of strategy effects, which will lead to survivor bias
2. New experimental system and its scientific verification
In order to solve the above problems, we proposed a new experimental system and scientifically verified it
1. New user scenario experiment diversion ID selection
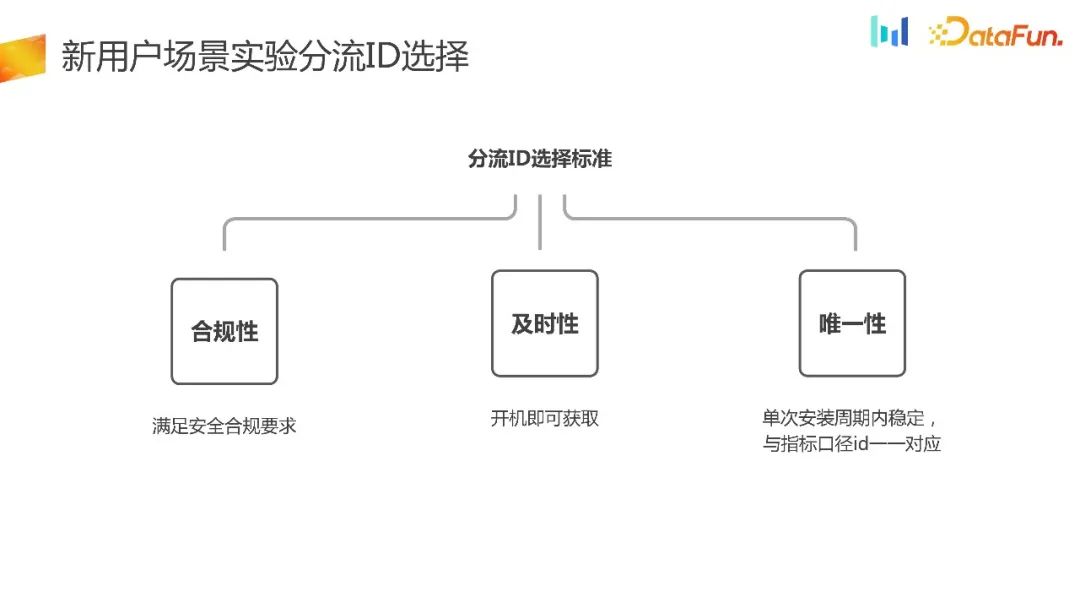
As mentioned before, the requirements for diversion selection for new users will be relatively high, so how to choose the diversion ID for new user experiments? The following are a few principles:
- Compliance, whether it is overseas business or domestic business, safety compliance is first and foremost the lifeline, and safety compliance must be met. Otherwise, the impact will be particularly great once it is removed from the shelves.
- #Timeliness, for new user scenarios, it must be timely, and the offload can be obtained immediately after booting.
- Uniqueness, within a single installation cycle, the shunt ID is stable and can form a one-to-one correspondence with the indicator ID. As can be seen from the data in the figure below, the one-to-one matching ratio between the diversion ID and the indicator calculation caliber ID has reached 99.79%, and the one-to-one ratio between the indicator calculation ID and the diversion ID has also reached 99.59%. Basically, it can be verified that the diversion ID and indicator ID selected according to the standard can achieve a one-to-one match.

2. Scientific verification of diversion capability
After selecting the diversion ID, the diversion capability is often There are two ways, the first is through the experimental platform, and the second is through the end.
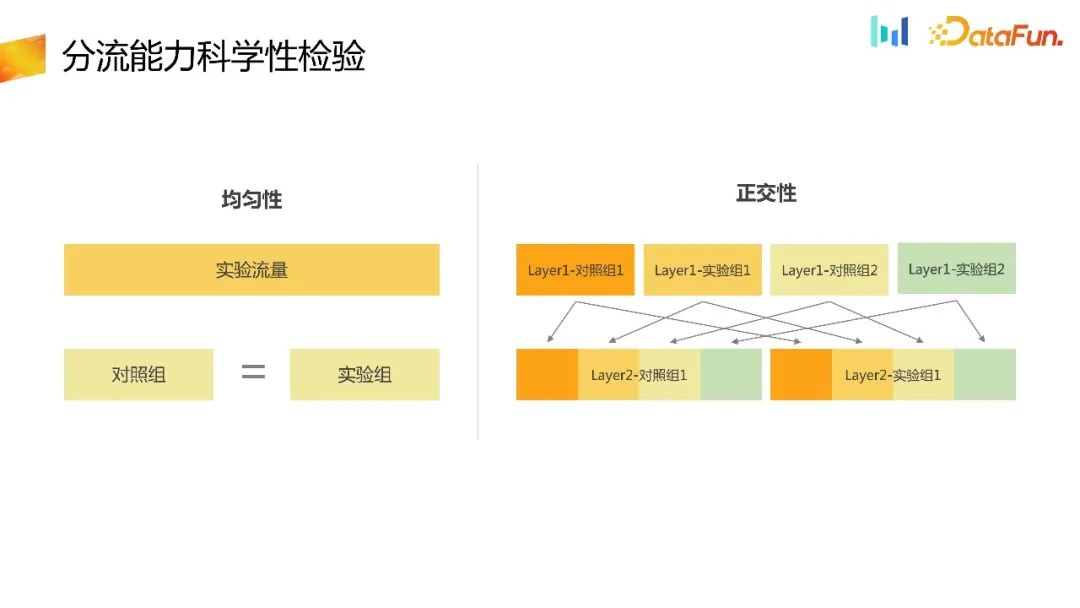
After you have the diversion ID, provide the diversion ID to the experimental platform to complete the diversion capability in the experimental platform. As a distribution platform, the most basic thing is to verify its randomness. The first is uniformity. In the same layer of experiments, the traffic is evenly divided into many buckets, and the number of groups in each bucket should be even. It can be simplified here. If there is only one experiment on one layer and it is divided into two groups, a and b, the number of users in the control group and the experimental group should be approximately equal, thereby verifying the uniformity of the diversion capability. Secondly, for multi-layer experiments, the multi-layer experiments should be orthogonal to each other and unaffected. Similarly, it is also necessary to verify the orthogonality between experiments at different layers. Uniformity and orthogonality can be verified through statistical category tests.
After introducing the ID of the diversion selection and the diversion capability, finally we need to verify whether the newly proposed diversion results meet the requirements of the AB experiment from the indicator result level.
3. Scientific verification of diversion results
By using the internal platform, we have conducted multiple AA simulations
Comparison Whether the control group and the experimental group meet the requirements of the experiment on the corresponding indicators. Next, let’s take a look at this set of data.

We sampled some index groups of the t test. It can be understood that for so many experiments, the type one error rate should be at a very small probability. Assume The type one error rate is scheduled to be around 0. 055%, and its confidence interval should actually be around 1000 times, which should be between 0. 0365- 0. 0635. You can see that some of the indicators sampled in the first column are within this execution range, so from the perspective of type one error rate, the existing experimental system is OK.
At the same time, considering that the test is a test of the t statistic, the corresponding t statistic should approximately obey the normal distribution under the distribution of large traffic. You can also test the normal distribution of the t-test statistic. The normal distribution test is used here, and you can see that the test result is also much greater than 0.05, that is, the null hypothesis is established, that is, the t statistic approximately obeys the normal distribution.
For each test, the pvalue of the t statistic test result is approximately uniformly distributed in so many experiments. At the same time, the pvalue can also be uniformly Similar results can also be seen in the distribution test, pvalue_uniform_test, which is also much greater than 0.05. Therefore, the null hypothesis that pvalue approximately obeys a uniform distribution is also OK.
The above has verified the newly proposed experimental diversion system from the one-to-one correspondence between the diversion ID and the indicator calculation caliber, the diversion capability and the diversion result indicator results. scientific nature.
3. Application case analysis
The following will be combined with actual application cases in UG scenarios to explain in detail how to conduct experimental evaluations to solve the previous problems. The third question mentioned
1. New user scenario experimental evaluation
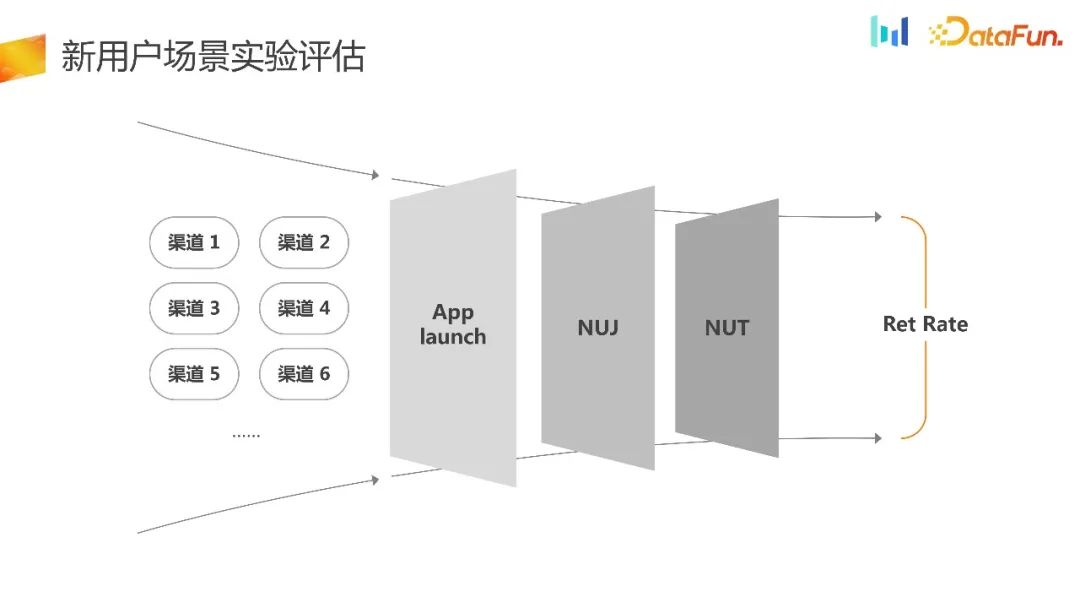
Here is a typical UG traffic acceptance scenario. A lot of optimizations will be done during NUJ new user guidance or new user tasks to improve traffic utilization. The evaluation standard at this time is often retention rate, which is the current common understanding in the industry.
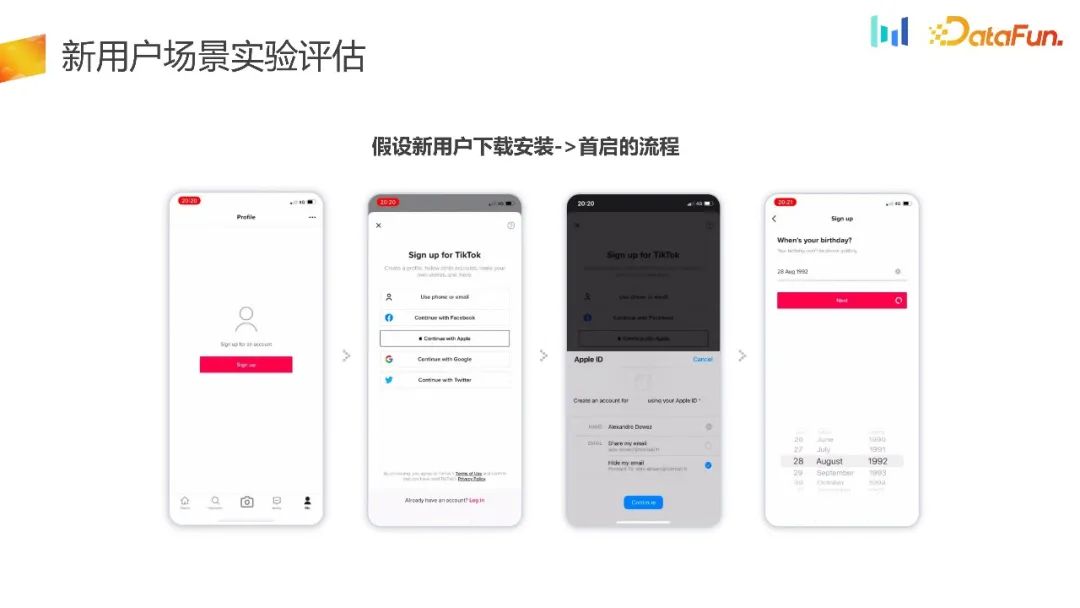
Assuming the process from new user download to installation to first startup, PM feels that such a process is useful for users, especially those who have never experienced it. The threshold for users of this part of the product is too high. Should users be familiar with the product first and experience the hip-hop moment of the product before being guided to log in?
Further, the product manager put forward another hypothesis, that is, for users who have never experienced the product, when a new user logs in or a new user NUJ Reduce resistance in the scene. For users who have already experienced the product and users who have switched devices, the online process is still used
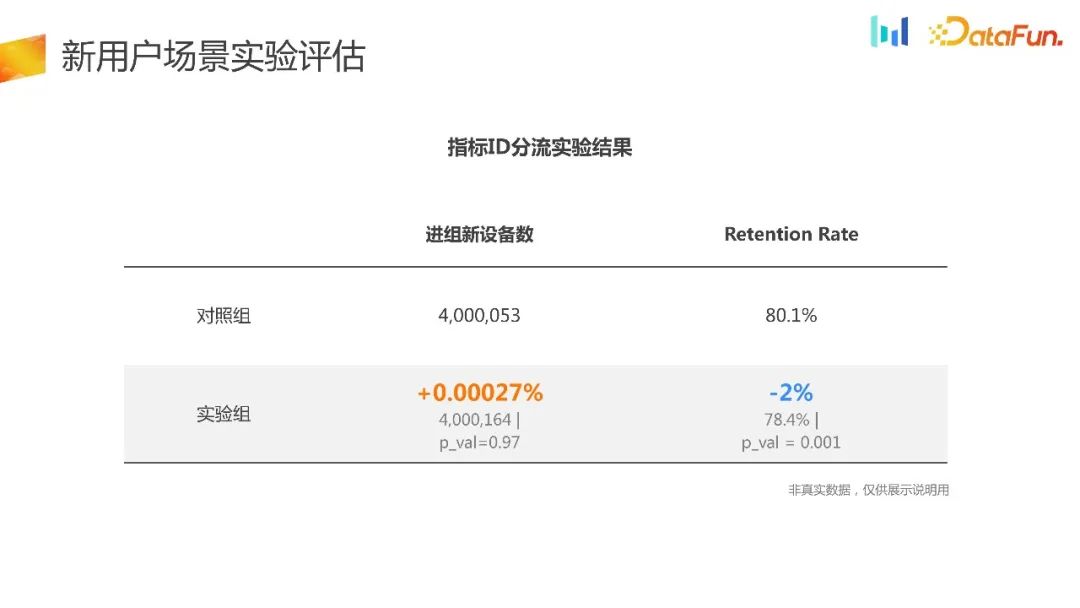
The method of diversion based on the indicator ID first obtains the indicator ID, and then triage. This splitting method is usually uniform, and there is not much difference from the experimental results and retention rate. Judging from such results, it is difficult to make a comprehensive decision. This kind of experiment actually wastes a part of the traffic and has the problem of selection bias. Therefore, we will conduct a local shunt experiment. The following figure shows the results of the local shunt experiment
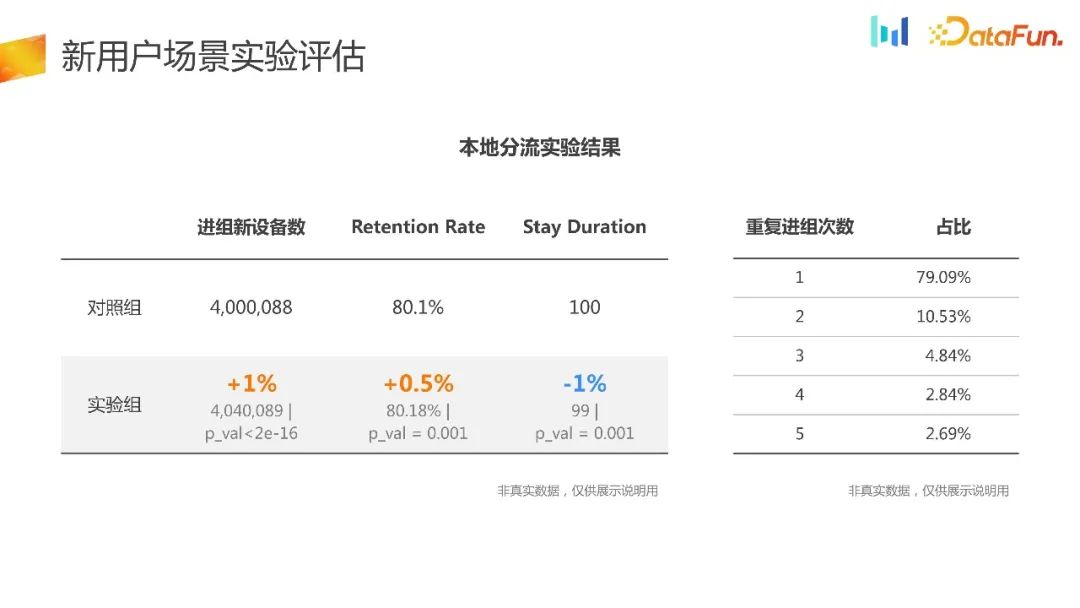
The number of new devices entering the group will be significant. The difference is believable. At the same time, there is an improvement in retention rate, but it is actually negative in other core indicators, and this negative direction is difficult to understand because it is actually strongly related to retention. Therefore, based on such data, it is difficult to explain or attribute it, and it is also difficult to make comprehensive decisions.
You can observe the situation of users who have been repeatedly added to groups, and you will find that more than 20% of users have been repeatedly assigned to different groups. This destroys the randomness of the AB experiment and makes it difficult to make scientific comparison decisions
Finally, take a look at the results of experiments with the proposed new shunt.
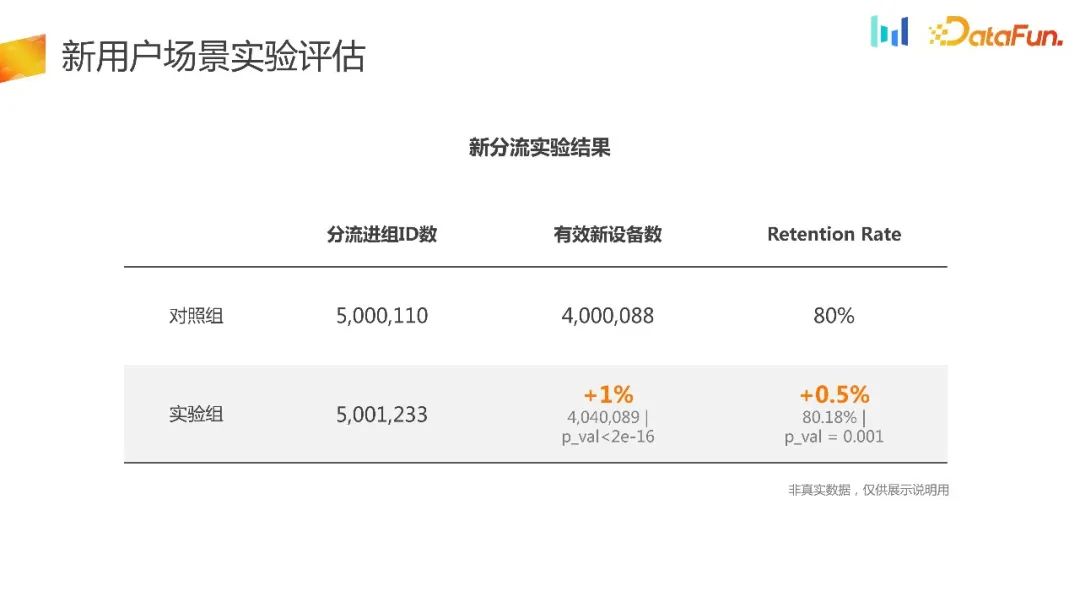
You can divert the traffic when you turn it on. The diverting capacity is guaranteed by the internal platform, which can ensure the uniformity and stability of the diverting to a great extent. . Judging from the experimental data, it is almost close. When doing the square root test, we can also see that it fully meets the needs. At the same time, we can see that the number of effective new devices has increased significantly, by 1%, and the retention rate has also improved. At the same time, if you look at the control group or the experimental group alone, you can see the traffic conversion rate based on the diversion ID to the new device finally generated. The experimental group is 1% higher than the control group. The reason for this result is that the experimental group actually enlarged the user's entry point in NUJ and NUT, making it easier for more users to come in, experience the product, and then stay.
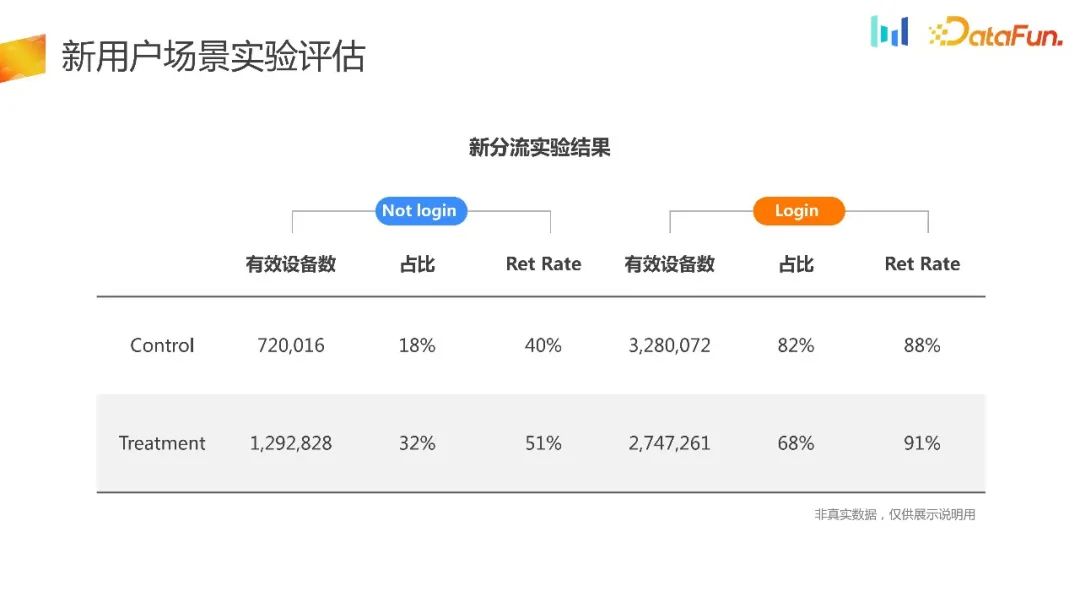
Divide the experimental data into login and non-login parts. It can be found that for users in the experimental group, more users choose non-login. Login mode to experience the product, and the retention rate has also improved. This result is also in line with expectations.
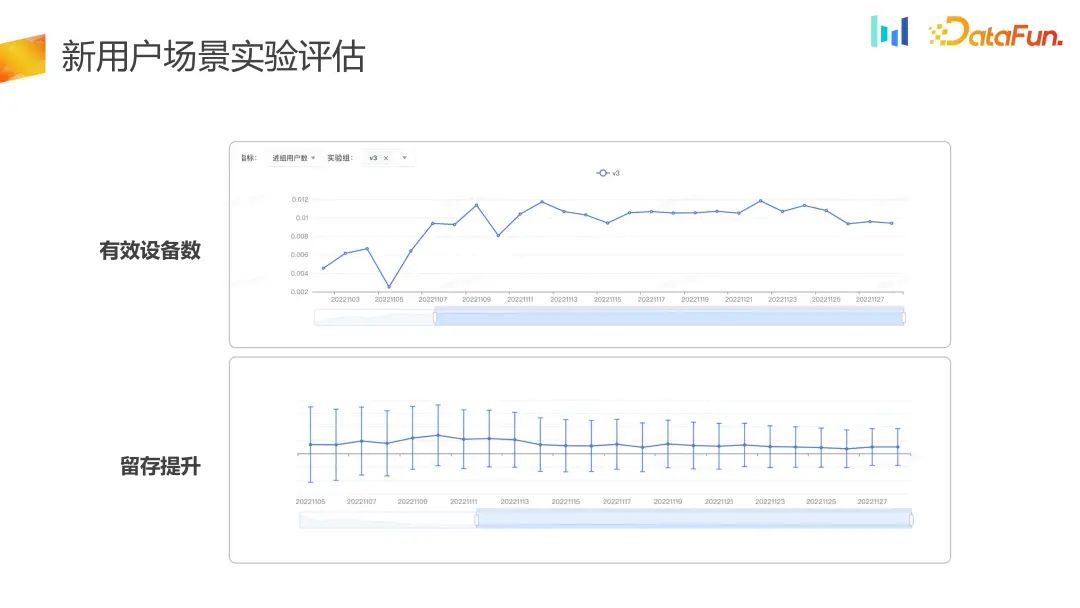
You can see the indicators by daily, and those who entered the group The number of users actually has been written for a long time. Judging by daily, it is increasing steadily, and the retention index has also improved. Compared with the control group, the experimental group has improved in the number of effective devices and retention.
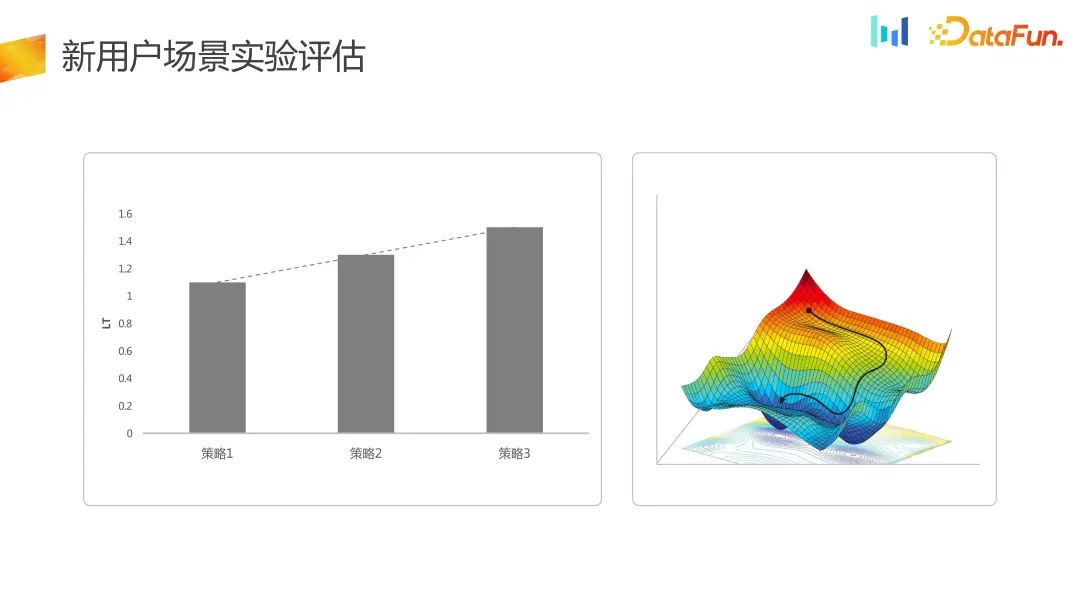
For the scenario of new user traffic acceptance, the evaluation indicators are more evaluated from the retention or short-term LT dimension. Here, the optimization is actually only performed on the one-dimensional space at the LT level
. However, in the new experimental system, the one-dimensional optimization is turned into a two-dimensional optimization. DNU God Shang LT has been improved as a whole, so that the strategy space has changed from one dimension to two dimensions. At the same time, in some scenarios, the loss of part of LT can be accepted.
4. Summary
Finally, let’s summarize the experimental capability building and experimental evaluation standards in new user scenarios.
- UG The existing experimental system in the new user scenario cannot fully solve the problems faced by the evaluation of new user traffic acceptance strategies, and a new experimental system is needed.
- There are several criteria for selecting the offload ID. The first is security compliance, then it can be obtained at the first startup, and the third is within a single installation cycle. is stable and has an injective relationship with the indicator ID.
- Experimental evaluation for new user scenarios is a multi-dimensional optimization. The revenue comes from the effective number of new devices and device retention, unlike the previous evaluation of devices. of retention.
- #Accepting “new” users often brings huge business benefits. The "new" here refers not only to new users, but also to users who have uninstalled and reinstalled.
The above is the detailed content of How to build an AB experiment system in user growth scenarios?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
Written above & the author’s personal understanding: At present, in the entire autonomous driving system, the perception module plays a vital role. The autonomous vehicle driving on the road can only obtain accurate perception results through the perception module. The downstream regulation and control module in the autonomous driving system makes timely and correct judgments and behavioral decisions. Currently, cars with autonomous driving functions are usually equipped with a variety of data information sensors including surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect information in different modalities to achieve accurate perception tasks. The BEV perception algorithm based on pure vision is favored by the industry because of its low hardware cost and easy deployment, and its output results can be easily applied to various downstream tasks.
 Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Common challenges faced by machine learning algorithms in C++ include memory management, multi-threading, performance optimization, and maintainability. Solutions include using smart pointers, modern threading libraries, SIMD instructions and third-party libraries, as well as following coding style guidelines and using automation tools. Practical cases show how to use the Eigen library to implement linear regression algorithms, effectively manage memory and use high-performance matrix operations.
 Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
The bottom layer of the C++sort function uses merge sort, its complexity is O(nlogn), and provides different sorting algorithm choices, including quick sort, heap sort and stable sort.
 Can artificial intelligence predict crime? Explore CrimeGPT's capabilities
Mar 22, 2024 pm 10:10 PM
Can artificial intelligence predict crime? Explore CrimeGPT's capabilities
Mar 22, 2024 pm 10:10 PM
The convergence of artificial intelligence (AI) and law enforcement opens up new possibilities for crime prevention and detection. The predictive capabilities of artificial intelligence are widely used in systems such as CrimeGPT (Crime Prediction Technology) to predict criminal activities. This article explores the potential of artificial intelligence in crime prediction, its current applications, the challenges it faces, and the possible ethical implications of the technology. Artificial Intelligence and Crime Prediction: The Basics CrimeGPT uses machine learning algorithms to analyze large data sets, identifying patterns that can predict where and when crimes are likely to occur. These data sets include historical crime statistics, demographic information, economic indicators, weather patterns, and more. By identifying trends that human analysts might miss, artificial intelligence can empower law enforcement agencies
 Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
01 Outlook Summary Currently, it is difficult to achieve an appropriate balance between detection efficiency and detection results. We have developed an enhanced YOLOv5 algorithm for target detection in high-resolution optical remote sensing images, using multi-layer feature pyramids, multi-detection head strategies and hybrid attention modules to improve the effect of the target detection network in optical remote sensing images. According to the SIMD data set, the mAP of the new algorithm is 2.2% better than YOLOv5 and 8.48% better than YOLOX, achieving a better balance between detection results and speed. 02 Background & Motivation With the rapid development of remote sensing technology, high-resolution optical remote sensing images have been used to describe many objects on the earth’s surface, including aircraft, cars, buildings, etc. Object detection in the interpretation of remote sensing images
 Practice and reflections on Jiuzhang Yunji DataCanvas multi-modal large model platform
Oct 20, 2023 am 08:45 AM
Practice and reflections on Jiuzhang Yunji DataCanvas multi-modal large model platform
Oct 20, 2023 am 08:45 AM
1. The historical development of multi-modal large models. The photo above is the first artificial intelligence workshop held at Dartmouth College in the United States in 1956. This conference is also considered to have kicked off the development of artificial intelligence. Participants Mainly the pioneers of symbolic logic (except for the neurobiologist Peter Milner in the middle of the front row). However, this symbolic logic theory could not be realized for a long time, and even ushered in the first AI winter in the 1980s and 1990s. It was not until the recent implementation of large language models that we discovered that neural networks really carry this logical thinking. The work of neurobiologist Peter Milner inspired the subsequent development of artificial neural networks, and it was for this reason that he was invited to participate in this project.
 Application of algorithms in the construction of 58 portrait platform
May 09, 2024 am 09:01 AM
Application of algorithms in the construction of 58 portrait platform
May 09, 2024 am 09:01 AM
1. Background of the Construction of 58 Portraits Platform First of all, I would like to share with you the background of the construction of the 58 Portrait Platform. 1. The traditional thinking of the traditional profiling platform is no longer enough. Building a user profiling platform relies on data warehouse modeling capabilities to integrate data from multiple business lines to build accurate user portraits; it also requires data mining to understand user behavior, interests and needs, and provide algorithms. side capabilities; finally, it also needs to have data platform capabilities to efficiently store, query and share user profile data and provide profile services. The main difference between a self-built business profiling platform and a middle-office profiling platform is that the self-built profiling platform serves a single business line and can be customized on demand; the mid-office platform serves multiple business lines, has complex modeling, and provides more general capabilities. 2.58 User portraits of the background of Zhongtai portrait construction
 Add SOTA in real time and skyrocket! FastOcc: Faster inference and deployment-friendly Occ algorithm is here!
Mar 14, 2024 pm 11:50 PM
Add SOTA in real time and skyrocket! FastOcc: Faster inference and deployment-friendly Occ algorithm is here!
Mar 14, 2024 pm 11:50 PM
Written above & The author’s personal understanding is that in the autonomous driving system, the perception task is a crucial component of the entire autonomous driving system. The main goal of the perception task is to enable autonomous vehicles to understand and perceive surrounding environmental elements, such as vehicles driving on the road, pedestrians on the roadside, obstacles encountered during driving, traffic signs on the road, etc., thereby helping downstream modules Make correct and reasonable decisions and actions. A vehicle with self-driving capabilities is usually equipped with different types of information collection sensors, such as surround-view camera sensors, lidar sensors, millimeter-wave radar sensors, etc., to ensure that the self-driving vehicle can accurately perceive and understand surrounding environment elements. , enabling autonomous vehicles to make correct decisions during autonomous driving. Head
