

In the era of brain-computer interface, there are new things every day.
Today I bring you four words: brain implant music.
Specifically, it is to first use AI to observe what kind of radio waves a certain piece of music produces in people's brains, and then directly simulate this radio wave in the brains of people in need. activities to achieve the purpose of treating certain types of diseases.
Let’s take a look back at Albany Medical Center a few years ago and see how the neuroscientists there conducted research
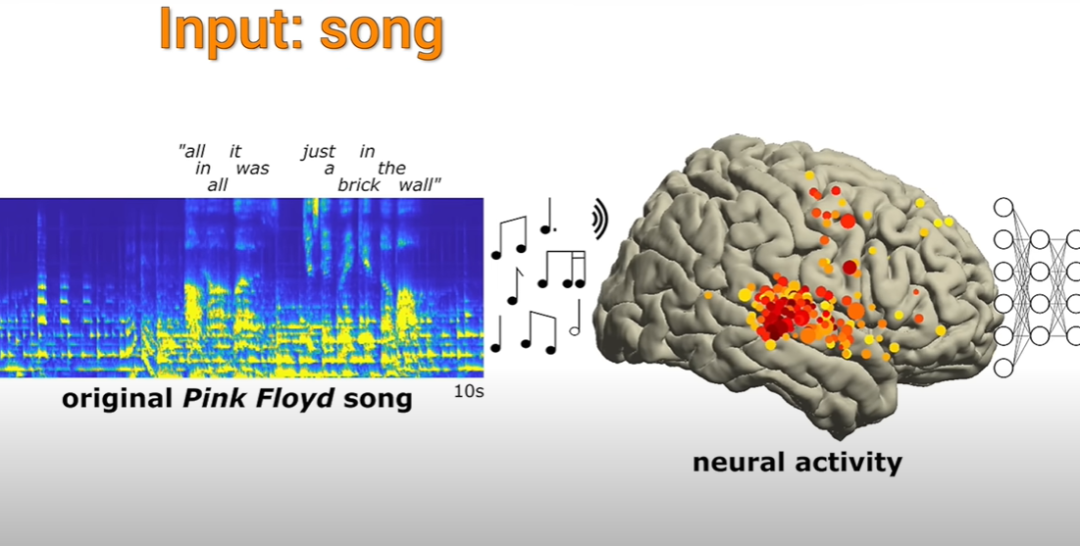
At Albany Medical Center, a piece of music called "The Other Wall" slowly sounded, filling the entire hospital ward
Patients lying on the hospital bed preparing to undergo epilepsy surgery are not doctors, but listening.
Neuroscientists gathered aside to observe the patient's brain displayed on the computer screen. Electrogram activity
The main observation content is the electrode activity generated in some areas of the brain after hearing something unique to music, and then look at the recorded electrode activity Can you reproduce what music they are listening to?
In the aforementioned content, the elements involved in music include tone, rhythm, harmony and lyrics
This research has been conducted for more than ten years. Neuroscientists at the University of California, Berkeley, conducted a detailed analysis of data from 29 epilepsy patients who participated in the experiment.
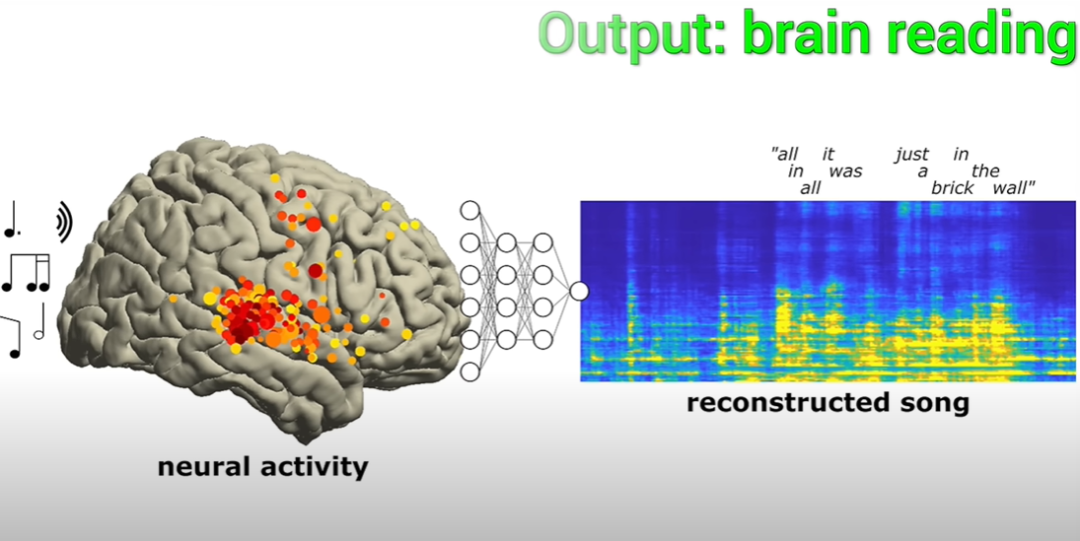
The scientists were able to successfully reconstruct the pattern based on the results of electrode activity in the patients' brains. Music section
In the reproduced song, the rhythm of one of the lyrics "All in all it was just a brick in the wall" is very complete. Although the lyrics are not too clear, But researchers say it can be deciphered and it's not all chaos.
And this song is also the first case where scientists have successfully reconstructed a song through brain electrode activity.
The results show that by recording and deactivating brain waves, some musical elements and syllables can be captured.
These musical elements can be called prosody in professional terms, including rhythm, stress, cadence, etc. The meaning of these elements cannot be expressed through words alone
Furthermore, since these intracranial electroencephalograms (iEEGs) only record activity occurring in the surface layers of the brain (that is, closest to the auditory center) part), so there’s no need to worry about someone eavesdropping on what you’re listening to this way (laughs)
But, for those who have had a stroke, Or paralysis, resulting in difficulty in communication, this kind of reproduction from the electrode activity on the surface of the brain can help them reproduce the musicality of the music.
Obviously, this is much better than the robotic, dull-toned reprise from before. As mentioned above, there are some things that words alone are not enough. What we listen to is the tone.
This is a remarkable result, said Robert Knight, a neuroscientist at the Helen Wills Neuroscience Institute and a professor of psychology at the University of California, Berkeley.
"For me, one of the charms of music lies in its prelude and the emotional content it expresses. With continuous breakthroughs in the field of brain-computer interface, this technology It can provide people in need with something that only music can provide through implantation. The audience may include patients suffering from ALS, or epilepsy patients, in short, anyone whose disease affects the language output nerve. "
In other words, we can now do more than just language itself. Compared with music, the emotions expressed by words may seem a bit thin. I believe that from now on, we have truly embarked on a journey of interpretation
With the advancement of brainwave recording technology, one day in the future we may be able to record through electrodes attached to the scalp without opening the brain.
Knight said that current scalp EEG can already measure and record some brain activities, such as detecting a single letter from a large string of letters. Although it is not very efficient, each letter takes at least 20 seconds, but it is still a start.
The reason for vigorously developing scalp electrodes is that the current level of proficiency in non-invasive technology is insufficient. In other words, craniotomy measurement cannot ensure 100% safety. The measurement accuracy of scalp electrodes, especially for measurements of deep brain layers, still needs to be improved. It can be said that it has achieved some success, but not completely.
Can you read minds?
For example, for those who have difficulty speaking, brain-computer interface technology is equivalent to giving them a "keyboard". By capturing brain wave activity, they They can type on this "keyboard" to express what they want to express.
For example, take Hawking as an example. The device he used is to generate the speech of the robot voice by capturing his brain waves
You should be able to understand through analogy. Just by looking at this "keyboard", you can't tell what it is thinking. Technology now allows keyboards to be activated and output speech. If no one wants to type, the keyboard won't activate and you won't know what it's thinking
So, mind reading is not feasible
Experimental content
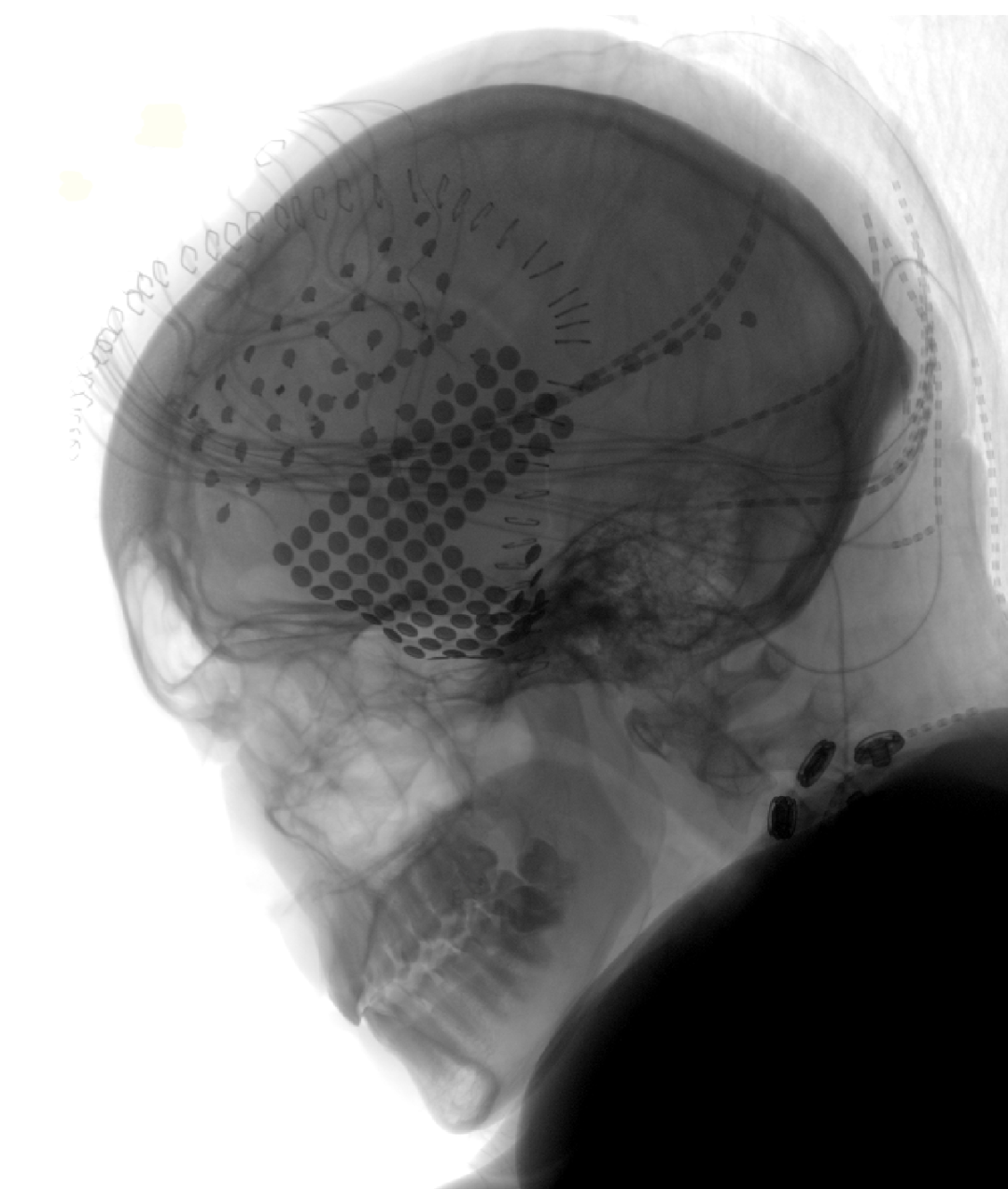
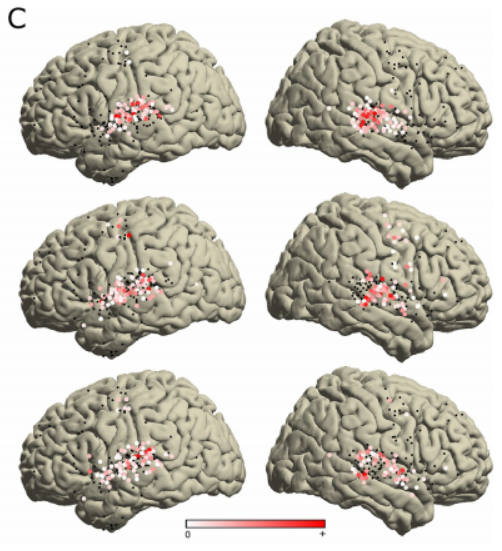
Figure B shows the electrode coverage of a patient under an X-ray. Each point represents an electrode.
Picture C shows the electrode signals of the four electrodes in picture B. At the same time, the figure also shows the high-frequency activity (HFA) induced by the song stimulus, represented by the sliding black short line, with frequencies between 70 and 150 Hz
Figure D shows A Amplified auditory spectrogram and electrode neural activity map of a short section (10 seconds) of song playback. We can observe that the time points of HFA coincide with the red line on the right side of each marked rectangle in the spectrogram.
These paired situations constitute the researchers used for training and Examples of evaluating coding models.
The researchers’ experimental results show that there is a logarithmic relationship between the number of electrodes used as predictors in the decoding model and the prediction accuracy, as follows As shown in the figure. 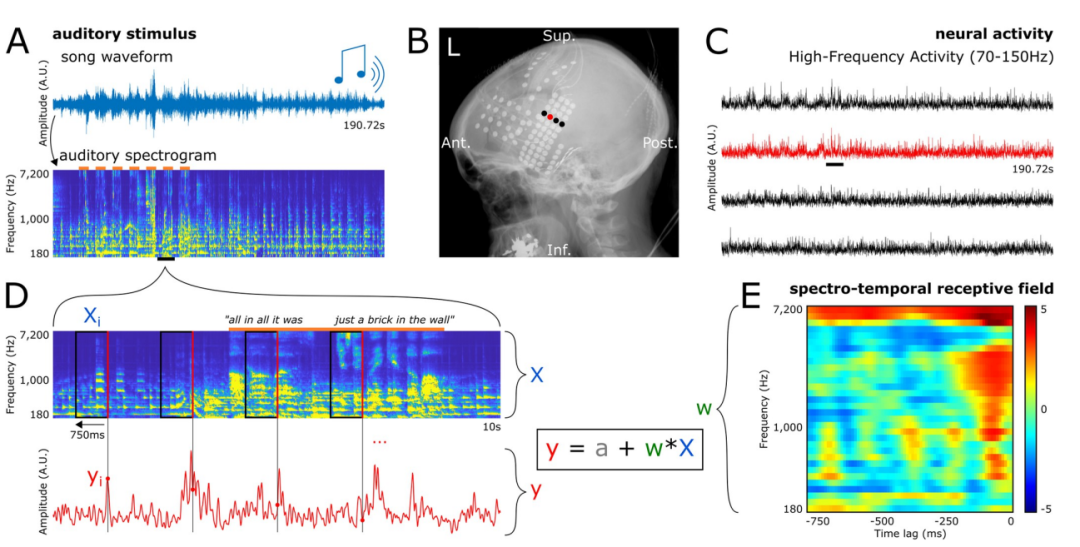
For example, the best prediction accuracy of 80% is obtained using 43 electrodes (or 12.4%) (the best prediction accuracy is Results using all 347 electrodes). 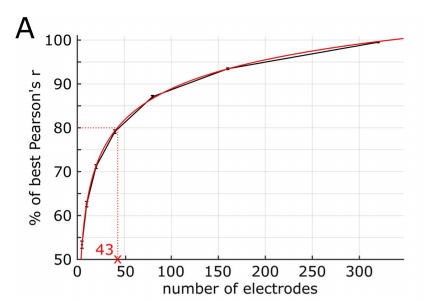
The same relationship was observed in a single patient, which is what the researchers found
Additionally, through bootstrapping analysis, the researchers observed There is a similar logarithmic relationship between the duration of the dataset and prediction accuracy, as shown in the figure below.
For example, if you use data with a length of 69 seconds (36.1% of the total length), you can get 90% of the best performance (The best performance is obtained using data from the entire song, which is 190.72 seconds long) 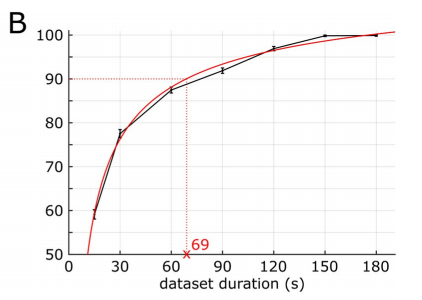
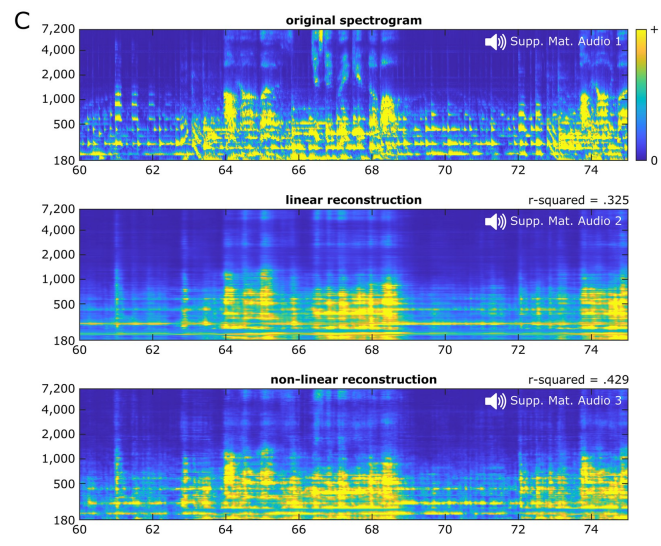
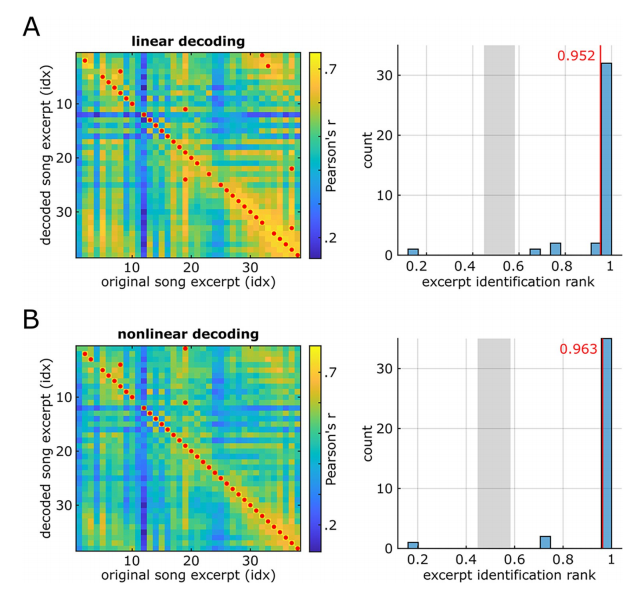
Regarding the model type, the average decoding accuracy of linear decoding is 0.325, while using double layer The average decoding accuracy of nonlinear decoding of fully connected neural networks is 0.429.
Overall, the linear music song reconstruction (Audio S2) sounds muffled, with strong rhythmic cues for the presence of some musical elements (referring to vocal syllables and lead guitar), but may not be useful for others. Perception of some elements is limited.
Nonlinear song reconstruction (Audio S3) reproduces a recognizable song with richer details than linear reconstruction. The perceptual quality of spectral elements such as pitch and timbre is significantly improved, and phoneme characteristics are more clearly discernible. Some recognition blind spots existing in linear reconstruction have also been improved to a certain extent
The following is an illustration:
So the researchers used a nonlinear model to reconstruct the song from the 29th patient's 61 electrodes.
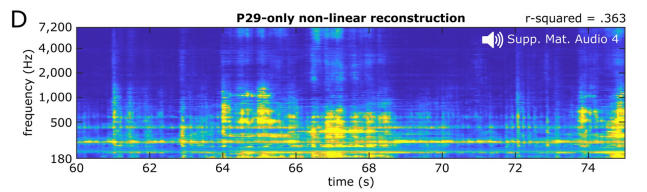
The performance of these models is better than linear reconstruction based on all patient electrodes, but the decoding accuracy is not as good as that obtained using 347 electrodes from all patients Accuracy
In terms of perception, these single-patient-based models provided spectral-temporal detail high enough for researchers to identify songs (Audio S4)
At the same time, to evaluate the lower limit of decoding based on a single patient, the researchers reconstructed songs from the brain neural activity of three other patients, who had a smaller number of electrodes, 23 and 17 respectively. and 10, while the number of electrodes in the 29th patient mentioned above was 61, and the electrode density was also relatively low. Of course, the response area of the song is still covered, and the accuracy of linear decoding is also considered good.
In the reconstructed waveforms (audio files S5, S6 and S7), the researchers retrieved part of the human voice. They then quantified the recognizability of the decoded songs by correlating the spectrograms of the original songs with the decoded songs.
Both linear reconstruction (Figure A below) and nonlinear reconstruction (Figure B below) provide a higher proportion of correct recognition rates.
In addition, the researchers analyzed the STRF (spectral-temporal receptive field) coefficients of all 347 important electrodes to evaluate the effects of different musical elements on different Encoding in brain regions.
This analysis reveals distinct spectral and temporal tuning patterns
To fully characterize the relationship between song spectrograms and neural activity, The researchers performed independent component analysis (ICA) on all significant STRFs.
The researchers found 3 components with different spectral-temporal tuning patterns. The variance explanation rate of each component exceeded 5%, and the total variance explanation rate reached 52.5%. As shown below.
The first part (explained variance 28%) shows a cluster of positive coefficients distributed over a wide frequency range from approximately 500Hz to 7000Hz, and where HFA is observed Visible within a narrow time window of about 90ms before
, this transient cluster shows the tuning of the onset of the sound. This part is called the initial part and only appears on the electrodes at the rear of the bilateral STG, as shown in the figure below
Finally, The researchers said that future studies may expand the coverage of electrodes, change the characteristics and goals of the model, or add new behavioral dimensions
The above is the detailed content of UC Berkeley brain-computer interface breakthrough: using brain waves to reproduce music, bringing good news to people with speech impairments!. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



