

The use of a single neural network to achieve manipulation is a major technological breakthrough in the field of quadruped robots
Parkour is an extreme sport that requires participation The robot can overcome obstacles in a highly dynamic manner. For robots that are "clumsy" most of the time, this seems to be something out of reach. However, there have been some recent trends in technological breakthroughs in the field of robot control. A few weeks ago, this site reported on a study that used reinforcement learning methods to achieve parkour on a robot dog, and achieved good results. Recently, a new study conducted by Carnegie Mellon University (CMU) proposed a stunning new method for the challenge of robot dog parkour, and the effect was further improved to the point that people agreed Rated as "amazing"
The audience said: "It's like being in "Black Mirror.""Research at Carnegie Mellon University enables a robot dog to automatically cross discontinuous boxes like a competitor in an obstacle course, and easily run and jump between slopes inclined at different angles
 And the speed of passing these obstacles is also very fast.
And the speed of passing these obstacles is also very fast. Easily jump over a gap of 0.8 meters (2 times the length of the robot dog):
 Climb over a height of 0.51 meters (2 times the height of the robot dog) ) Obstacles:
Climb over a height of 0.51 meters (2 times the height of the robot dog) ) Obstacles:  # This time, I couldn’t stand firmly, and it used its hind legs to compensate, acting like a real dog.
# This time, I couldn’t stand firmly, and it used its hind legs to compensate, acting like a real dog. Robot dogs can also do things that are difficult for animals in the real world, such as walking with only two front legs, which is equivalent to walking upside down
 Can also go down stairs with only two front legs:
Can also go down stairs with only two front legs:  It’s like encountering a bug in the game, a bit funny, and at the same time with a hint of uncanny valley effect
It’s like encountering a bug in the game, a bit funny, and at the same time with a hint of uncanny valley effectThe goal of this research is to enable small, low-cost robot dogs to successfully complete parkour tasks. The driving system of this robot dog is not precise enough and only has a front-facing depth camera for perception, which is low-frequency and prone to jitter and artifacts. The study proposes a method based on raw depth and onboard A neural network of sensor inputs is used to directly generate joint angle commands. By conducting large-scale reinforcement learning simulation training, this method is able to solve the challenges caused by sensor inaccuracies and actuator issues, thereby achieving end-to-end high-precision control behavior. This research project has been released on the open source platform
 Please click the following link to view the paper: https://extreme-parkour.github.io/resources /parkour.pdf
Please click the following link to view the paper: https://extreme-parkour.github.io/resources /parkour.pdfProject address: https://github.com/chengxuxin/extreme-parkour
This research uses an end-to-end data-driven reinforcement learning framework to equip the robot dog with the ability to "parkour". In order to allow the robot dog to self-adjust according to the obstacle type when deployed, this research proposes a novel dual distillation method. This strategy can not only output flexible motion commands, but also quickly adjust the direction according to the input depth image.
#In order to enable a single neural network to represent different parkour skill behaviors, this study proposes a simple and effective universal reward design principle based on inner products.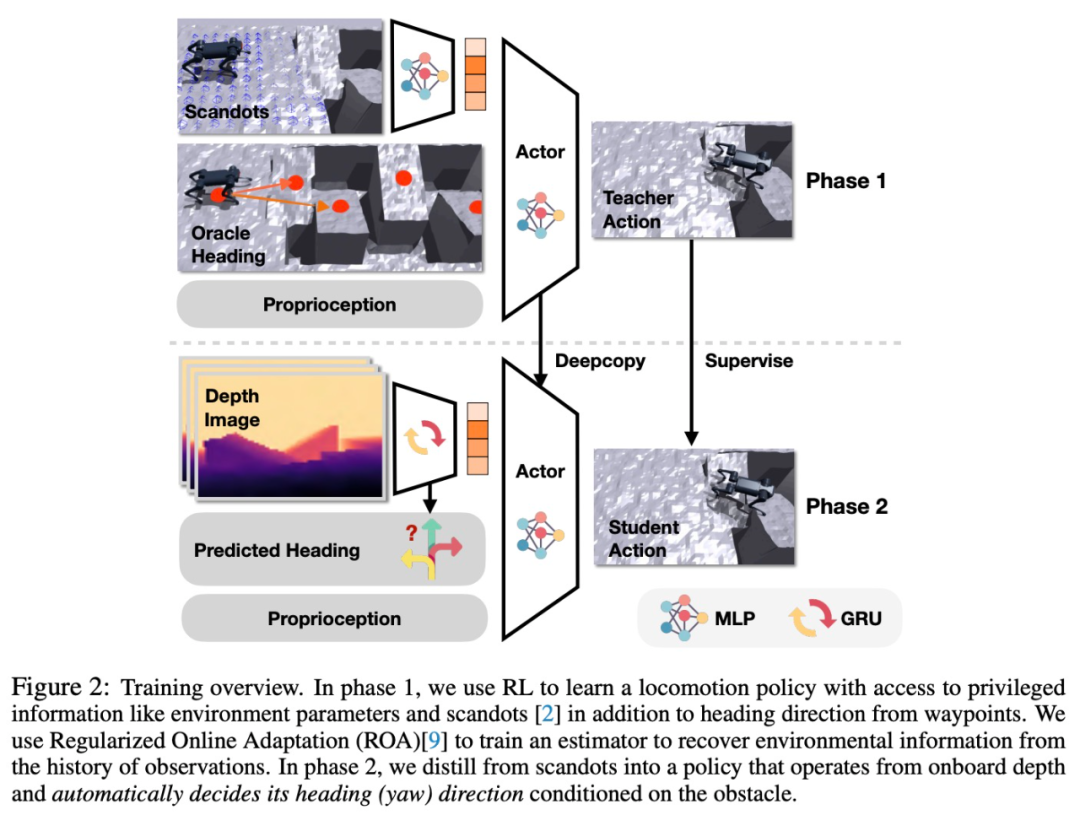 Specifically, the research aims to train a neural network directly from raw depth and onboard sensing to joint angle commands. To train adaptive movement strategies, this study adopted the regularized online adaptation (ROA) method with key modifications for extreme parkour tasks.
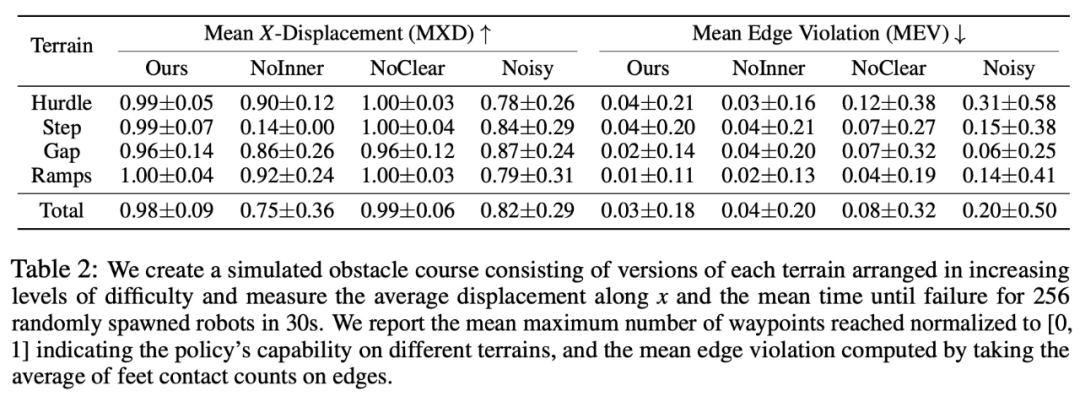
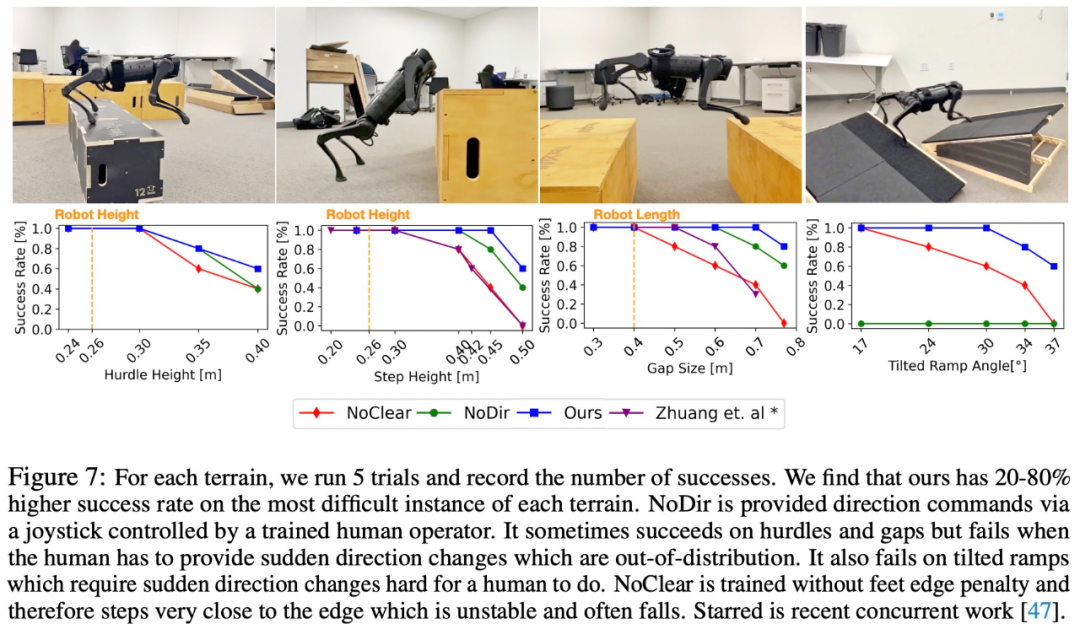
Specifically, the research aims to train a neural network directly from raw depth and onboard sensing to joint angle commands. To train adaptive movement strategies, this study adopted the regularized online adaptation (ROA) method with key modifications for extreme parkour tasks. The goal of this research is to let the robot dog master 4 skills, including climbing, jumping over gaps, running and jumping on slopes, and standing upside down. Table 1 below shows the comparison results compared with several other methods In order to verify the role of each part in the system, the study proposed two sets of baselines. The study first tested the reward design and overall process, and the results are shown in Table 2 below: The purpose of the second set of baselines is to test the distillation settings, which include the ones used for direction prediction BC and dagger for action. The experimental results are shown in Table 3 #In addition, the study also conducted a number of real-life experiments, recorded the success rate, and compared it with the NoClear and NoDir baselines. The experimental results are shown in Figure 7 #Interested readers can read the original text of the paper to learn more about the research content. 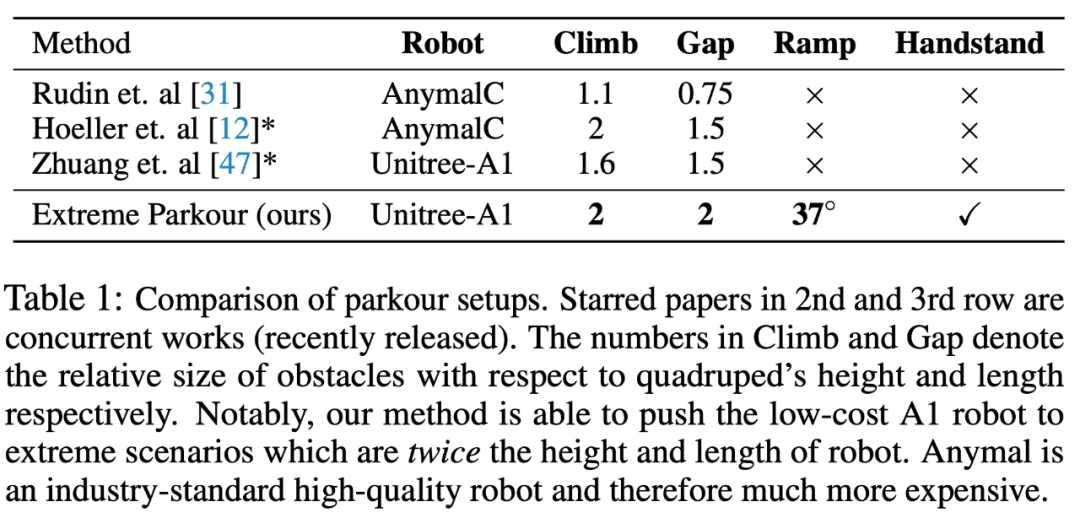

The above is the detailed content of Disturbingly, robot dogs already have this ability. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



