
 Technology peripherals
AI
MVDiffusion: Achieve high-quality multi-view image generation and accurate reproduction of scene materials
Technology peripherals
AI
MVDiffusion: Achieve high-quality multi-view image generation and accurate reproduction of scene materials
MVDiffusion: Achieve high-quality multi-view image generation and accurate reproduction of scene materials

Realistic image generation has wide applications in fields such as virtual reality, augmented reality, video games and film production.
With the rapid development of diffusion models in the past two years, major breakthroughs have been made in the field of image generation. A series of open source or commercial models derived from Stable Diffusion for generating images based on text descriptions have had a huge impact on design, games and other fields
However, how to generate images based on given Text or other conditions, producing high-quality multi-view images remains a challenge. Existing methods have obvious flaws in multi-view consistency
Currently common methods can be roughly divided into two categories
First The class method is dedicated to generating a scene picture and depth map, and obtaining the corresponding mesh, such as Text2Room, SceneScape - first use Stable Diffusion to generate the first picture, and then use Image Warping and Image Inpainting ) to generate subsequent pictures and depth maps using an autoregressive method.
However, such a solution can easily lead to errors gradually accumulating during the generation of multiple images, and there are usually closed-loop problems (such as when the camera rotates in a circle and returns to near the starting position) , the generated content is not completely consistent with the first picture), resulting in poor performance when the scene scale is large or the perspective changes between pictures.
The second type of method generates multiple pictures at the same time by extending the generation algorithm of the diffusion model to produce richer content than a single picture (such as generating a 360-degree panorama, or The content of an image is extrapolated infinitely to both sides), such as MultiDiffusion and DiffCollage. However, since the camera model is not considered, the results generated by this type of method are not true panoramas.
The goal of MVDiffusion is to generate multi-view images that conform to a given camera model. These images are Strictly consistent in content and globally semantically unified. The core idea of this method is to simultaneously denoise and learn the correspondence between images to maintain consistency

Please click the following link to view the paper: https ://arxiv.org/abs/2307.01097
Please visit the project website: https://mvdiffusion.github.io/
Demo : https://huggingface.co/spaces/tangshitao/MVDiffusion
Code: https://github.com/Tangshitao/MVDiffusion
Conference Published: NeurIPS (Key Points)
The goal of MVDiffusion is to generate multi-viewpoints with highly consistent content and unified global semantics through simultaneous denoising and global awareness based on the correspondence between images. Picture
Specifically, the researchers extended the existing text-picture diffusion model (such as Stable Diffusion), first allowing it to process multiple pictures in parallel, and further in the original An additional "Correspondence-aware Attention" mechanism is added to UNet to learn consistency between multiple perspectives and global unity.
By fine-tuning on a small amount of multi-view image training data, the resulting model can simultaneously generate multi-perspective images with highly consistent content.
MVDiffusion has achieved good results in three different application scenarios:
Generate multiple views based on text, and then splice them to Obtain a panorama
2. Extrapolate the perspective image (outpainting) to obtain a complete 360-degree panorama;
3. Generate for the scene Texture.
Application Scenario Display
Application 1: The process of panorama generation is to stitch together multiple photos or videos to create a panoramic perspective image or video. This process usually involves using special software or tools to automatically or manually align, blend and repair these images or videos. Through panorama generation, people can appreciate and experience scenes, such as landscapes, buildings, or indoor spaces, with a broader view. This technology has a wide range of applications in tourism, real estate, virtual reality and other fields (according to text)
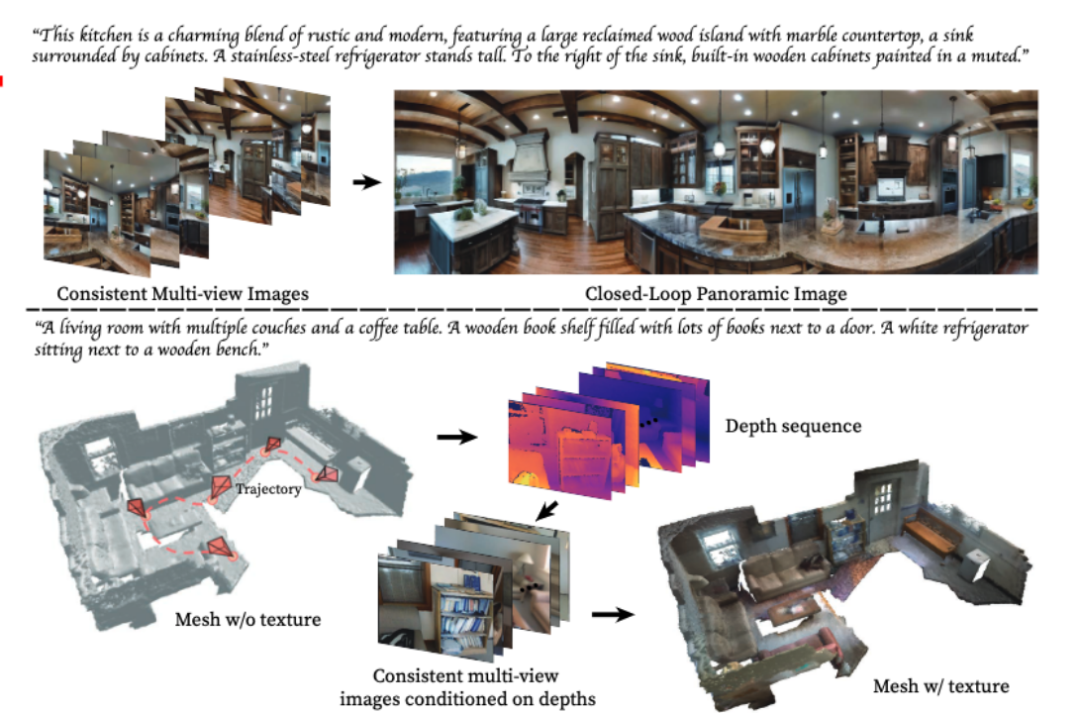
Take generating a panorama as an example, enter a text describing the scene, MVDIffusion can generate multiple images of a scene Perspective Pictures
Enter the following to get 8 multi-perspective pictures: "This kitchen is a charming blend of country and modern, featuring a large reclaimed wood island with marble countertops, a A sink surrounded by cabinets. To the left of the island is a tall stainless steel refrigerator. To the right of the sink are built-in wooden cabinets painted in pastel colors."

These 8 pictures can be stitched into one panorama:

MVDiffusion also supports Provide a different text description for each image, but the descriptions need to be semantically consistent.
Application 2: The process of panorama generation is to stitch together multiple photos or videos to create a panoramic perspective image or video. This process usually involves using special software or tools to automatically or manually align, blend and repair these images or videos. Through panorama generation, people can appreciate and experience scenes, such as landscapes, buildings, or indoor spaces, with a broader view. This technology has wide applications in tourism, real estate, virtual reality and other fields (based on a perspective image)
MVDiffusion can extrapolate (outpainting) a perspective image into a complete 360-degree panorama picture.
For example, suppose we enter the following perspective:

MVDiffusion can further generate Panorama below:

It can be seen that the generated panorama semantically expands the input image, and the leftmost and rightmost The contents are connected (no closed-loop problems).
Application 3: Generating Scene Materials
Use MVDiffusion to generate materials (textures) for a given materialless scene mesh
Specifically, we first obtain multi-view depth maps by rendering mesh. Through the camera pose and depth map, we can obtain the correspondence between the pixels of multi-view images.
Next, MVDiffusion uses the multi-view depth map as a condition to simultaneously generate consistent multi-view RGB images.
Because the generated multi-view images can maintain a high degree of consistency in content, by projecting them back into the mesh, you can obtain a high-quality textured mesh.
The following are more effect examples:
The process of panorama generation is to combine multiple photos or videos Stitch images or videos together to create a panoramic view. This process usually involves using special software or tools to automatically or manually align, blend and repair these images or videos. Through panorama generation, people can appreciate and experience scenes, such as landscapes, buildings, or indoor spaces, with a broader view. This technology has wide applications in tourism, real estate, virtual reality and other fields




In this application scenario, It should be mentioned in particular that although the multi-view image data used in training MVDiffusion all come from panoramas of indoor scenes, and the styles are all single
, however, MVDiffusion does not Change the original stable diffusion parameters and just train the newly added Correspondence-aware Attention
Finally, the model can still generate multi-view pictures of various styles (such as outdoor, cartoon, etc.) based on the given text.
The content that needs to be rewritten is: single view extrapolation



Scene material generation

1. The process of panorama generation is to stitch together multiple photos or videos to create a panoramic perspective image or video. This process usually involves using special software or tools to automatically or manually align, blend and repair these images or videos. Through panorama generation, people can appreciate and experience scenes, such as landscapes, buildings, or indoor spaces, with a broader view. This technology has wide applications in tourism, real estate, virtual reality and other fields (according to text)
MVDiffusion simultaneously generates 8 overlapping images picture (perspective image), and then stitch these 8 pictures into a panorama. In these 8 perspective images, a 3x3 homographic matrix determines the pixel correspondence between each two images.
In the specific generation process, MVDiffusion first uses Gaussian random initialization to generate 8 views of pictures
Then, these 8 pictures The image is input into a Stable Diffusion pre-trained Unet network with multiple branches, and synchronous denoising is performed to obtain the generated result.
A new "Correspondence-aware Attention" module (light blue part in the picture above) has been added to the UNet network, which is used to learn the geometric consistency between cross-views, so that These 8 pictures can be stitched into a consistent panorama.
#2. The process of panorama generation is to stitch together multiple photos or videos to create a panoramic perspective image or video. This process usually involves using special software or tools to automatically or manually align, blend and repair these images or videos. Through panorama generation, people can appreciate and experience scenes, such as landscapes, buildings, or indoor spaces, with a broader view. This technology has a wide range of applications in tourism, real estate, virtual reality and more (according to a perspective picture)
MVDiffusion can also Complete a single perspective view into a panorama. The process of panorama generation is to stitch together multiple photos or videos to create a panoramic view of the image or video. This process usually involves using special software or tools to automatically or manually align, blend and repair these images or videos. Through panorama generation, people can appreciate and experience scenes, such as landscapes, buildings, or indoor spaces, with a broader view. This technology has a wide range of applications in tourism, real estate, virtual reality and other fields. MVDiffusion inputs randomly initialized 8 perspective pictures (including perspectives corresponding to perspective views) into the multi-branch Stable Diffusion Inpainting pre-trained UNet network.
In the Stable Diffusion Inpainting model, UNet uses an additional input mask to distinguish the conditional image from the image to be generated
The perspective corresponding to the perspective, the mask is set to 1, and the UNet of this branch will directly restore the perspective. For other perspectives, the mask is set to 0, and the UNet of the corresponding branch will generate a new perspective
Similarly, MVDiffusion uses the "Correspondence-aware Attention" module to learn to generate images and conditions Geometric consistency and semantic unity between images.
3. Scene material generation
MVDiffusion first generates RGB on a trajectory based on the depth map and camera pose. image, and then use TSDF fusion to mesh the generated RGB image with the given depth map.
The pixel correspondence of RGB images can be obtained through the depth map and camera pose.
The process of panorama generation is to stitch together multiple photos or videos to create a panoramic view of the image or video. This process usually involves using special software or tools to automatically or manually align, blend and repair these images or videos. Through panorama generation, people can appreciate and experience scenes, such as landscapes, buildings, or indoor spaces, with a broader view. This technology has a wide range of applications in tourism, real estate, virtual reality and other fields. We use multi-branch UNet and insert "Correspondence-aware Attention" to learn geometric consistency across perspectives.
4. Correspondence-aware Attention mechanism
##「Correspondence-aware Attention" (CAA), which is the core of MVDiffusion, is used to learn geometric consistency and semantic unity between multiple views.
MVDiffusion inserts the "Correspondence-aware Attention" block after each UNet block in the Stable Diffusion UNet. CAA works by considering a source feature map and N target feature maps.
For a location in the source feature map, we calculate the attention output based on the corresponding pixel and its neighborhood in the target feature map.
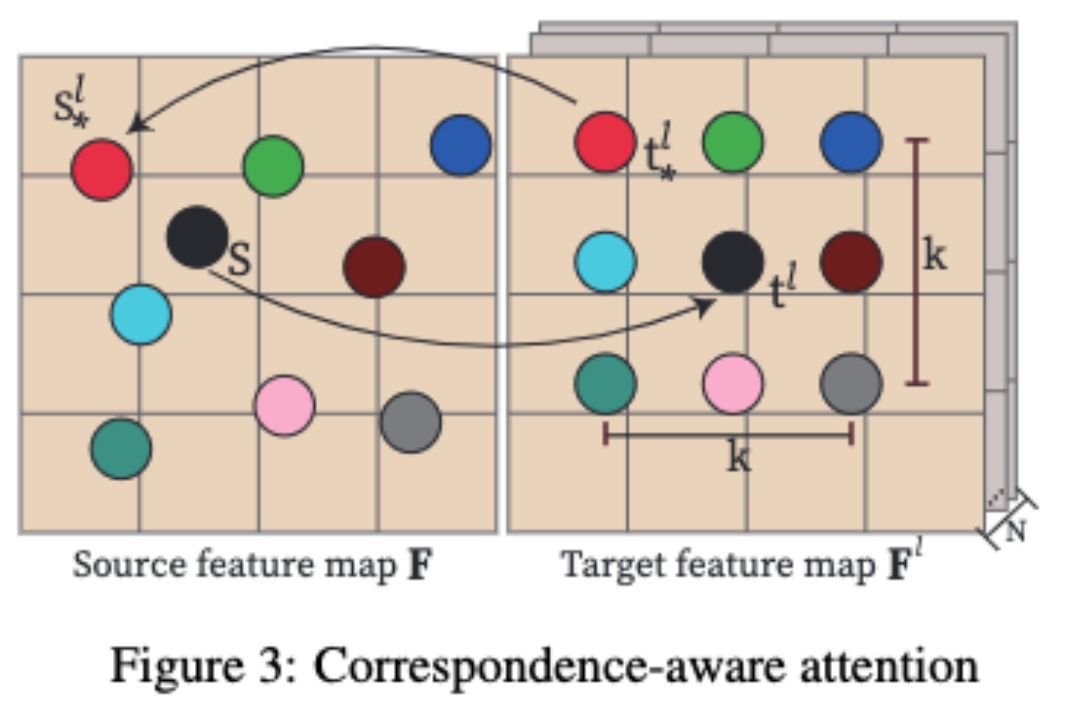
Specifically, for each target pixel t^l, MVDiffusion will pass the (x/y) coordinate Add integer displacement (dx/dy) to consider a K x K neighborhood, where |dx| represents the displacement in the x direction, |dy| represents the displacement in the y direction
In practical applications, the MVDiffusion algorithm uses K=3 and selects a 9-point neighborhood to improve the quality of the panorama. However, when generating multi-view images subject to geometric conditions, in order to improve operating efficiency, the calculation using the K=1
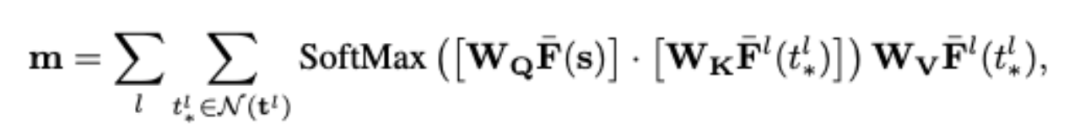
CAA module follows The standard attention mechanism, as shown in the formula above, where W_Q, W_K and W_V are the learnable weights of the query, key and value matrices; the target feature is not located at an integer position, but is obtained through bilinear interpolation.
The key difference is that position encoding is added to the target feature based on the 2D displacement (panorama) or 1D depth error (geometry) between the corresponding positions s^l and s in the source image .
In panorama generation (Application 1 and Application 2), this displacement provides the relative position in the local neighborhood.
And in depth-to-image generation (Application 3), disparity provides clues about depth discontinuities or occlusions, which is very important for high-fidelity image generation.
Please note that displacement is a concept containing a 2D (displacement) or 1D (depth error) vector. MVDiffusion applies standard frequency encoding to the x and y coordinates of the displacement
The above is the detailed content of MVDiffusion: Achieve high-quality multi-view image generation and accurate reproduction of scene materials. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
In Debian systems, the readdir function is used to read directory contents, but the order in which it returns is not predefined. To sort files in a directory, you need to read all files first, and then sort them using the qsort function. The following code demonstrates how to sort directory files using readdir and qsort in Debian system: #include#include#include#include#include//Custom comparison function, used for qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
 How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
The readdir function in the Debian system is a system call used to read directory contents and is often used in C programming. This article will explain how to integrate readdir with other tools to enhance its functionality. Method 1: Combining C language program and pipeline First, write a C program to call the readdir function and output the result: #include#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 How to learn Debian syslog
Apr 13, 2025 am 11:51 AM
How to learn Debian syslog
Apr 13, 2025 am 11:51 AM
This guide will guide you to learn how to use Syslog in Debian systems. Syslog is a key service in Linux systems for logging system and application log messages. It helps administrators monitor and analyze system activity to quickly identify and resolve problems. 1. Basic knowledge of Syslog The core functions of Syslog include: centrally collecting and managing log messages; supporting multiple log output formats and target locations (such as files or networks); providing real-time log viewing and filtering functions. 2. Install and configure Syslog (using Rsyslog) The Debian system uses Rsyslog by default. You can install it with the following command: sudoaptupdatesud
 How to set the Debian Apache log level
Apr 13, 2025 am 08:33 AM
How to set the Debian Apache log level
Apr 13, 2025 am 08:33 AM
This article describes how to adjust the logging level of the ApacheWeb server in the Debian system. By modifying the configuration file, you can control the verbose level of log information recorded by Apache. Method 1: Modify the main configuration file to locate the configuration file: The configuration file of Apache2.x is usually located in the /etc/apache2/ directory. The file name may be apache2.conf or httpd.conf, depending on your installation method. Edit configuration file: Open configuration file with root permissions using a text editor (such as nano): sudonano/etc/apache2/apache2.conf
 Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Configuring a Debian mail server's firewall is an important step in ensuring server security. The following are several commonly used firewall configuration methods, including the use of iptables and firewalld. Use iptables to configure firewall to install iptables (if not already installed): sudoapt-getupdatesudoapt-getinstalliptablesView current iptables rules: sudoiptables-L configuration
 How to configure firewall rules for Debian syslog
Apr 13, 2025 am 06:51 AM
How to configure firewall rules for Debian syslog
Apr 13, 2025 am 06:51 AM
This article describes how to configure firewall rules using iptables or ufw in Debian systems and use Syslog to record firewall activities. Method 1: Use iptablesiptables is a powerful command line firewall tool in Debian system. View existing rules: Use the following command to view the current iptables rules: sudoiptables-L-n-v allows specific IP access: For example, allow IP address 192.168.1.100 to access port 80: sudoiptables-AINPUT-ptcp--dport80-s192.16
 How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
In Debian systems, OpenSSL is an important library for encryption, decryption and certificate management. To prevent a man-in-the-middle attack (MITM), the following measures can be taken: Use HTTPS: Ensure that all network requests use the HTTPS protocol instead of HTTP. HTTPS uses TLS (Transport Layer Security Protocol) to encrypt communication data to ensure that the data is not stolen or tampered during transmission. Verify server certificate: Manually verify the server certificate on the client to ensure it is trustworthy. The server can be manually verified through the delegate method of URLSession
