
 Technology peripherals
AI
Google: New method for learning time series representation with non-equal frequency sampling
Technology peripherals
AI
Google: New method for learning time series representation with non-equal frequency sampling
Google: New method for learning time series representation with non-equal frequency sampling

In time series problems, there is a type of time series that is not equally frequently sampled, that is, the time intervals between two adjacent observations in each group are different. Time series representation learning has been studied a lot in equal-frequency sampling time series, but there is less research in this irregular sampling time series, and the modeling method of this type of time series is different from that in equal-frequency sampling. The modeling methods are quite different
The article introduced today explores the application method of representation learning in the irregular sampling time series problem, drawing on relevant experience in NLP, and in downstream tasks Relatively significant results have been achieved.
 Picture
Picture
- Paper title: PAITS: Pretraining and Augmentation for Irregularly-Sampled Time Series
- Download address: https: //arxiv.org/pdf/2308.13703v1.pdf
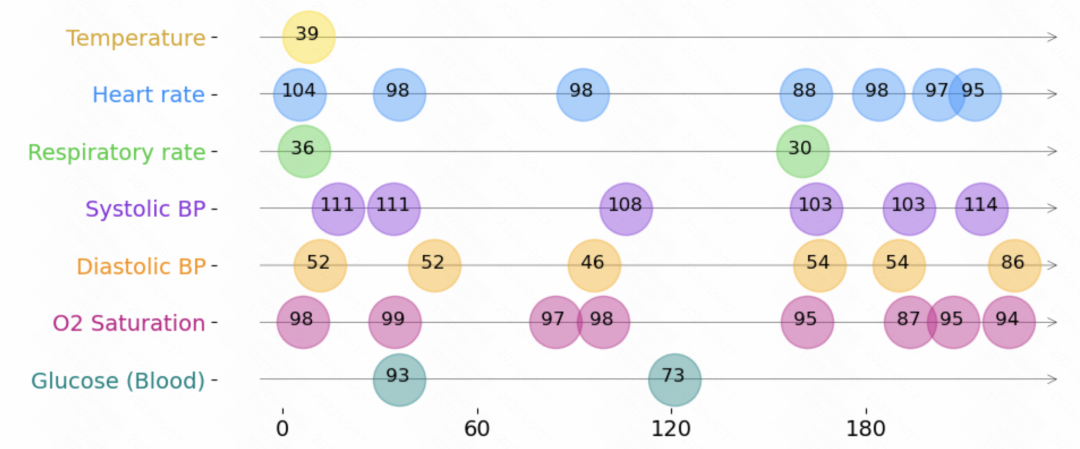
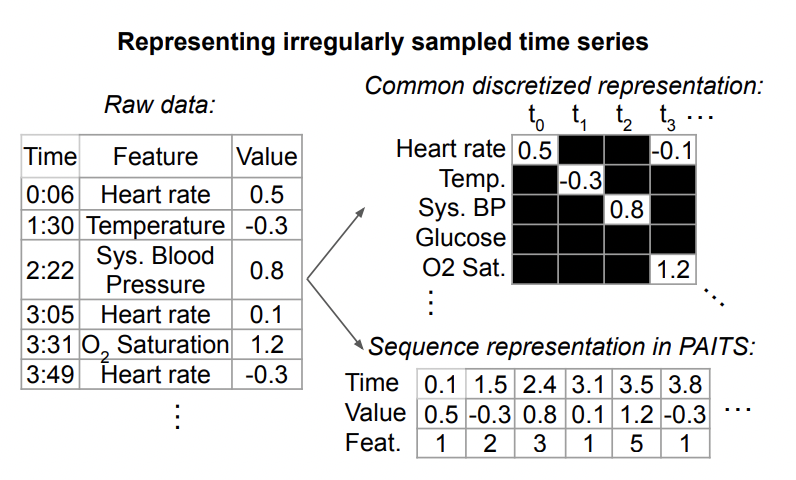
1. Definition of irregular time series data
The following is a representation of irregular time series data, as shown below shown. Each time series consists of a set of triples. Each triple contains three fields: time, value, and feature, which respectively represent the sampling time, value, and other features of each element in the time series. In addition to these triples, each sequence also includes other static features that do not change over time, as well as a label for each time series
 Picture
Picture
Generally, the common structure of this irregular time series modeling method is to embedding the above triple data separately, splicing them together, and inputting them into models such as transformer. In this way, the information at each moment and the time at each moment are integrated. The representations are fused together and fed into the model to make predictions for subsequent tasks.
 Picture
Picture
In the task of this article, the data used includes not only the data with labels, but also the data without labels, which is used to do Unsupervised pre-training.
2. Method overview
The pre-training method in this article refers to the experience in the field of natural language processing and mainly covers two aspects
The design of the pre-training task: In order to process Irregular time series require the design of appropriate pre-training tasks so that the model can learn effective representations from unsupervised data. This article mainly introduces two pre-training tasks based on prediction and reconstruction.
Design of data enhancement methods: In this study, a data enhancement method for unsupervised learning was designed, including adding noise and adding random masks. etc.
In addition, the article also introduces an algorithm for different distribution data sets to explore the optimal unsupervised learning method
3. Pre-training task design
This article proposes two pre-training tasks on irregular time series, namely Forecasting pretraining and Reconstruction pretraining.
In Forecasting pretraining, for each feature in the time series, its value is predicted based on the preorder sequence of a time window of a certain size. The characteristics here refer to the features in the triplet. Since each feature may appear multiple times in a time window, or may not appear at all, the value of the first occurrence of this feature is used as the label for pre-training. The input data includes original series and enhanced time series.
In reconstruction pre-training, first, for an original time series, an enhanced sequence is generated through some data enhancement method, and then the enhanced sequence is used as input, and the encoder generates a representation vector, and then The input is fed into a decoder to restore the original time series. The article uses a mask to guide which parts of the sequence need to be restored. If the mask is all 1, the entire sequence is restored.
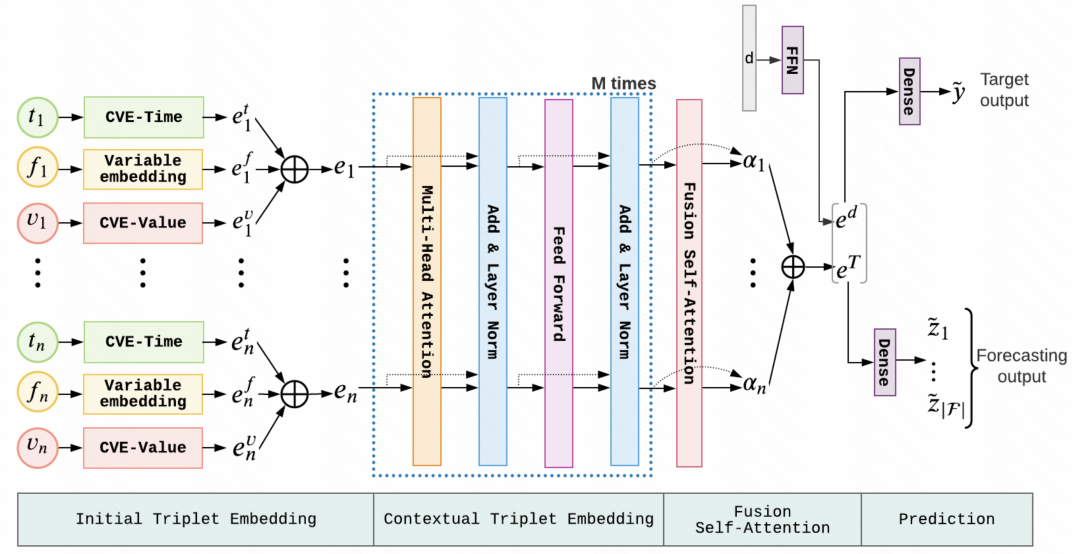
After obtaining the pre-training parameters, it can be directly applied to the downstream finetune task. The entire The pretrain-finetune process is shown in the figure below.
 Picture
Picture
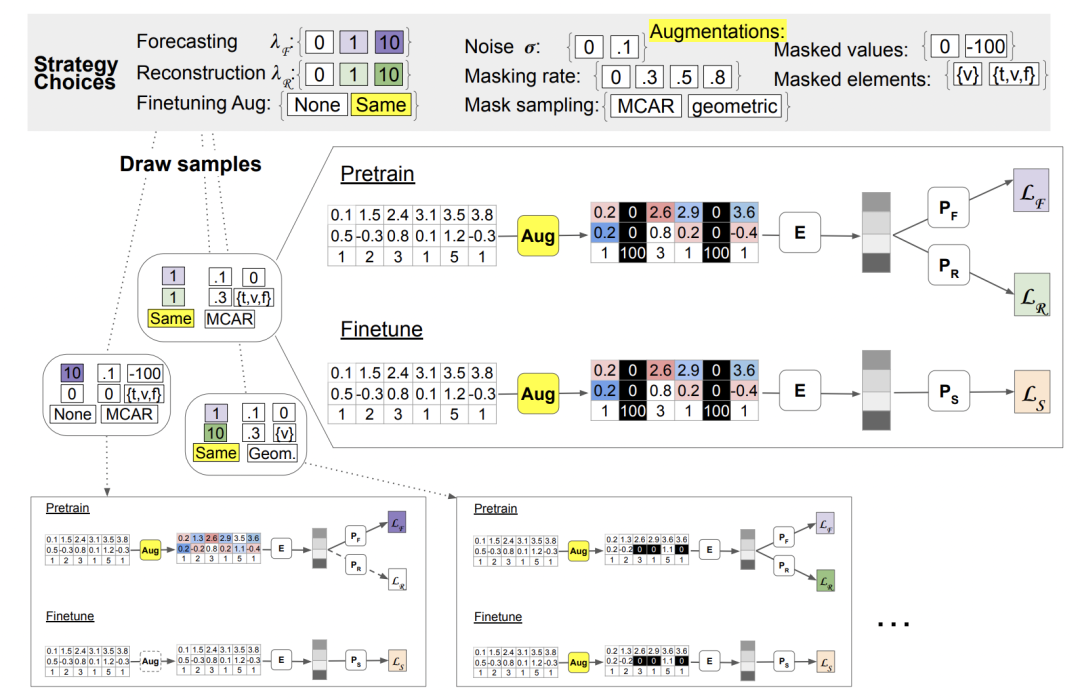
4. Data enhancement method design
In this article, we propose two data enhancement methods. The first method is to add noise, by introducing some random interference into the data to increase the diversity of the data. The second method is random masking, which encourages the model to learn more robust features by randomly selecting parts of the data to mask. These data enhancement methods can help us improve the performance and generalization ability of the model
For each value or time point of the original sequence, the noise can be increased by adding Gaussian noise. The specific calculation method is as follows:
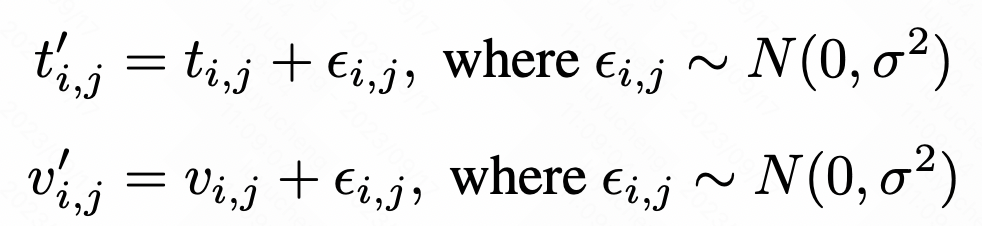 Picture
Picture
The random mask method draws on the ideas in NLP, by randomly selecting time, feature, value and other elements for random masking and replacement, and constructing the enhanced sequentially.
The following figure shows the effects of the above two types of data enhancement methods:
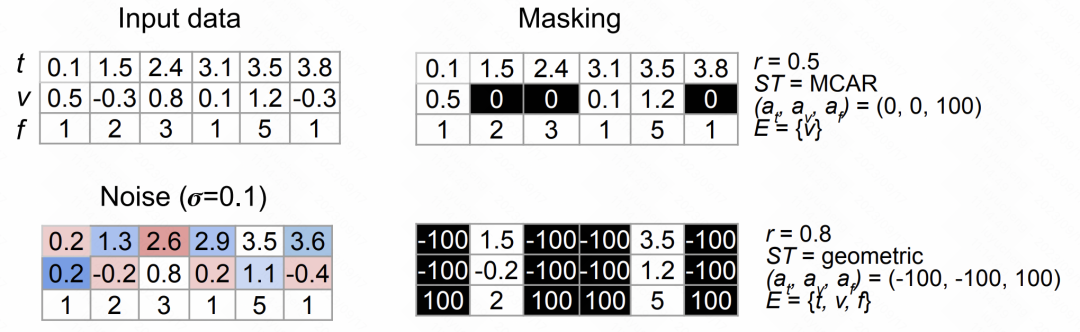 Picture
Picture
In addition, the article will Different combinations of training methods, etc. are used to search for the optimal pre-training method from these combinations for different time series data.
5. Experimental results
In this article, experiments were conducted on multiple data sets to compare the effects of different pre-training methods on these data sets. It can be observed that the pre-training method proposed in the article has achieved significant performance improvement on most data sets
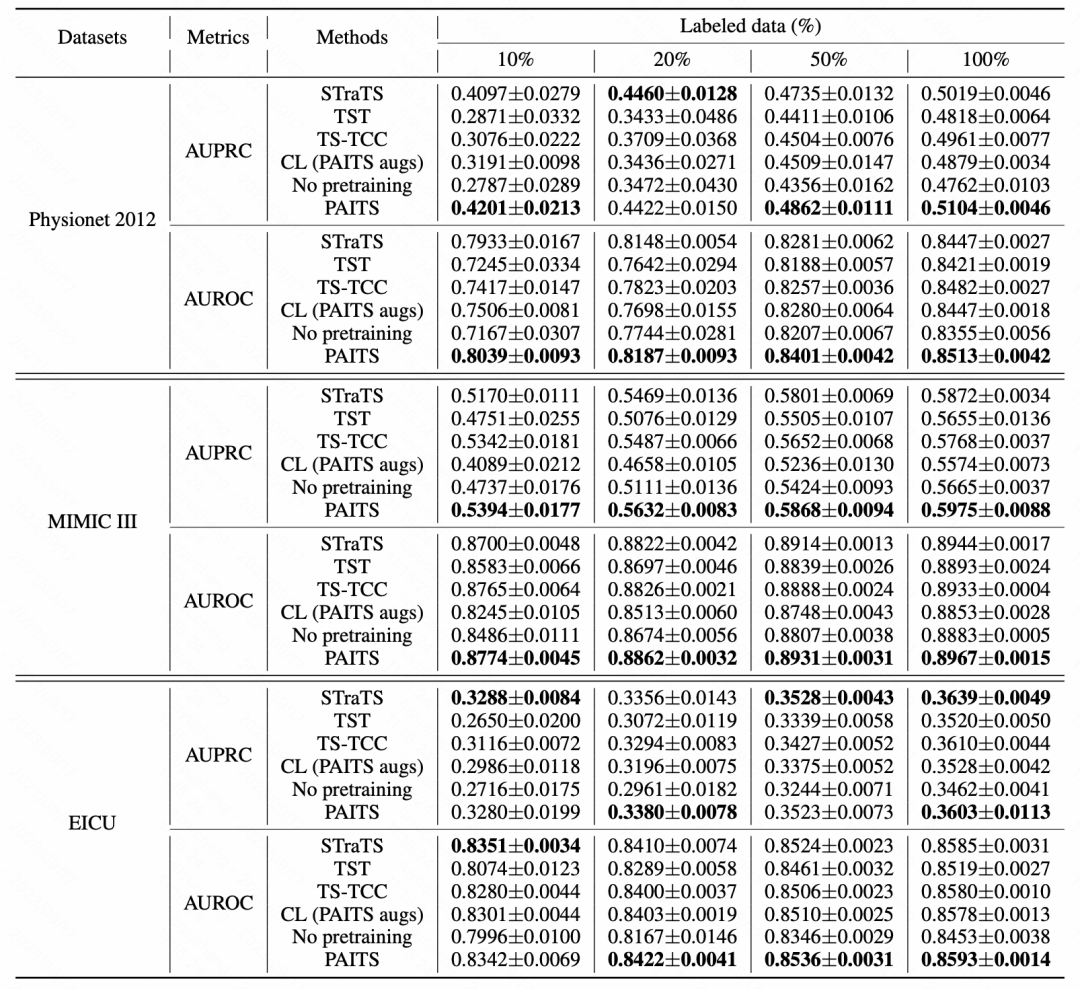 picture
picture
The above is the detailed content of Google: New method for learning time series representation with non-equal frequency sampling. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Sesame Open Door Exchange Web Page Login Latest version gateio official website entrance
Mar 04, 2025 pm 11:48 PM
Sesame Open Door Exchange Web Page Login Latest version gateio official website entrance
Mar 04, 2025 pm 11:48 PM
A detailed introduction to the login operation of the Sesame Open Exchange web version, including login steps and password recovery process. It also provides solutions to common problems such as login failure, unable to open the page, and unable to receive verification codes to help you log in to the platform smoothly.
 Sesame Open Door Exchange Web Page Registration Link Gate Trading App Registration Website Latest
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange Web Page Registration Link Gate Trading App Registration Website Latest
Feb 28, 2025 am 11:06 AM
This article introduces the registration process of the Sesame Open Exchange (Gate.io) web version and the Gate trading app in detail. Whether it is web registration or app registration, you need to visit the official website or app store to download the genuine app, then fill in the user name, password, email, mobile phone number and other information, and complete email or mobile phone verification.
 Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download Address
Feb 28, 2025 am 10:51 AM
Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download Address
Feb 28, 2025 am 10:51 AM
It is crucial to choose a formal channel to download the app and ensure the safety of your account.
 Top 10 recommended for crypto digital asset trading APP (2025 global ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 recommended for crypto digital asset trading APP (2025 global ranking)
Mar 18, 2025 pm 12:15 PM
This article recommends the top ten cryptocurrency trading platforms worth paying attention to, including Binance, OKX, Gate.io, BitFlyer, KuCoin, Bybit, Coinbase Pro, Kraken, BYDFi and XBIT decentralized exchanges. These platforms have their own advantages in terms of transaction currency quantity, transaction type, security, compliance, and special features. For example, Binance is known for its largest transaction volume and abundant functions in the world, while BitFlyer attracts Asian users with its Japanese Financial Hall license and high security. Choosing a suitable platform requires comprehensive consideration based on your own trading experience, risk tolerance and investment preferences. Hope this article helps you find the best suit for yourself
 Tutorial on how to register, use and cancel Ouyi okex account
Mar 31, 2025 pm 04:21 PM
Tutorial on how to register, use and cancel Ouyi okex account
Mar 31, 2025 pm 04:21 PM
This article introduces in detail the registration, use and cancellation procedures of Ouyi OKEx account. To register, you need to download the APP, enter your mobile phone number or email address to register, and complete real-name authentication. The usage covers the operation steps such as login, recharge and withdrawal, transaction and security settings. To cancel an account, you need to contact Ouyi OKEx customer service, provide necessary information and wait for processing, and finally obtain the account cancellation confirmation. Through this article, users can easily master the complete life cycle management of Ouyi OKEx account and conduct digital asset transactions safely and conveniently.
 The latest download address of Bitget in 2025: Steps to obtain the official app
Feb 25, 2025 pm 02:54 PM
The latest download address of Bitget in 2025: Steps to obtain the official app
Feb 25, 2025 pm 02:54 PM
This guide provides detailed download and installation steps for the official Bitget Exchange app, suitable for Android and iOS systems. The guide integrates information from multiple authoritative sources, including the official website, the App Store, and Google Play, and emphasizes considerations during download and account management. Users can download the app from official channels, including app store, official website APK download and official website jump, and complete registration, identity verification and security settings. In addition, the guide covers frequently asked questions and considerations, such as
 How to register and download the latest app on Bitget official website
Mar 05, 2025 am 07:54 AM
How to register and download the latest app on Bitget official website
Mar 05, 2025 am 07:54 AM
This guide provides detailed download and installation steps for the official Bitget Exchange app, suitable for Android and iOS systems. The guide integrates information from multiple authoritative sources, including the official website, the App Store, and Google Play, and emphasizes considerations during download and account management. Users can download the app from official channels, including app store, official website APK download and official website jump, and complete registration, identity verification and security settings. In addition, the guide covers frequently asked questions and considerations, such as
 Why is Bittensor said to be the 'bitcoin' in the AI track?
Mar 04, 2025 pm 04:06 PM
Why is Bittensor said to be the 'bitcoin' in the AI track?
Mar 04, 2025 pm 04:06 PM
Original title: Bittensor=AIBitcoin? Original author: S4mmyEth, Decentralized AI Research Original translation: zhouzhou, BlockBeats Editor's note: This article discusses Bittensor, a decentralized AI platform, hoping to break the monopoly of centralized AI companies through blockchain technology and promote an open and collaborative AI ecosystem. Bittensor adopts a subnet model that allows the emergence of different AI solutions and inspires innovation through TAO tokens. Although the AI market is mature, Bittensor faces competitive risks and may be subject to other open source
