

LeCun deeply disappointed with self-driving unicorn fraud

Do you think this is an ordinary self-driving video?
 Picture
Picture
This content needs to be rewritten into Chinese without changing the original meaning
None of the frames is "real".
 Picture
Picture
Different road conditions, various weather conditions, and more than 20 situations can be simulated, and the effect is just like the real thing.
 Picture
Picture
The world model has once again made a great contribution! LeCun enthusiastically retweeted this after seeing it.
 Picture
Picture
According to the above effect, which is brought by the latest version of GAIA-1
The scale of this project has reached 9 billion parameters, through 4,700 hours of driving video training, successfully achieved the effect of inputting video, text or operations to generate self-driving videos
The most direct benefit is that it can better predict future events, 20 A variety of scenarios can be simulated, further improving the safety of autonomous driving and reducing costs.
 Picture
Picture
Our creative team bluntly stated that this will completely change the rules of the autonomous driving game!
So how is GAIA-1 implemented?
The bigger the scale, the better
GAIA-1 is a generative world model with multiple modes
By utilizing video, text and actions as input, the system Realistic driving scene videos can be generated, with fine control over autonomous vehicle behavior and scene characteristics
Videos can be generated by using only text prompts
 Picture
Picture
The model principle is similar to that of a large language model, that is, predicting the next mark
The model can use vector quantization representation to discrete video frames, and then predict future scenes, which is converted into a prediction sequence The next token in . The diffusion model is then used to generate high-quality videos from the language space of the world model.
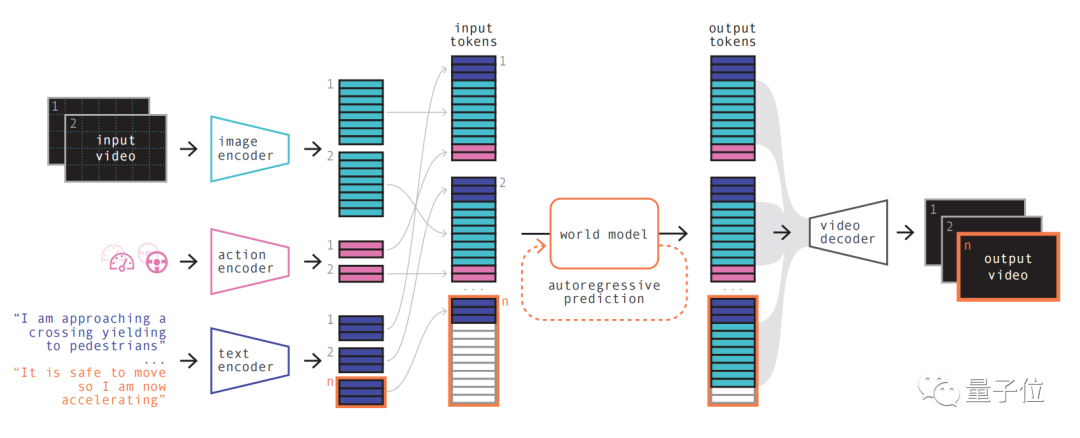
The specific steps are as follows:
 Picture
Picture
The first step is simple to understand, which is to recode and arrange and combine various inputs.
By using specialized encoders to encode various inputs and project different inputs into a shared representation. Text and video encoders separate and embed inputs, while operational representations are individually projected into a shared representation. These encoded representations are temporally consistent.
After the arrangement, the key part of the world model appears.
As an autoregressive Transformer, it can predict the next set of image tokens in the sequence. And it not only takes into account the previous image token, but also takes into account the contextual information of the text and operation.
The content generated by the model not only maintains the consistency of the image, but also remains consistent with the predicted text and actions
The team introduced that the size of the world model in GAIA-1 is 6.5 billion parameters. It was trained for 15 days on 64 blocks of A100.
Finally, use the video decoder and video diffusion model to convert these tokens back to videos.
The importance of this step is to ensure the semantic quality, image accuracy and temporal consistency of the video
GAIA-1’s video decoder has a scale of 2.6 billion parameters and is trained using 32 A100s Coming in 15 days.
It is worth mentioning that GAIA-1 is not only similar in principle to large language models, but also shows the characteristics of improved generation quality as the model scale expands
Picture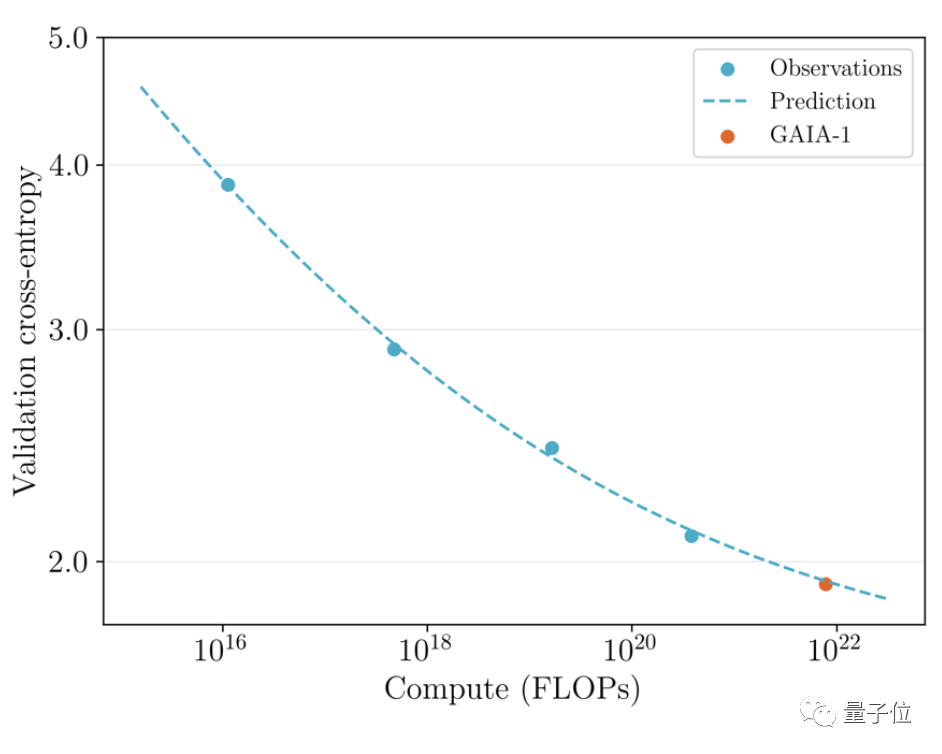 The team compared the previously released early version in June with the latest effect
The team compared the previously released early version in June with the latest effect
The latter is 480 times larger than the former.
You can intuitively see that the video has been significantly improved in details, resolution, etc.
Picture From the perspective of practical application, the emergence of GAIA-1 has also brought some impact. Its main creative team said that this will change Rules for autonomous driving
From the perspective of practical application, the emergence of GAIA-1 has also brought some impact. Its main creative team said that this will change Rules for autonomous driving
 Picture
Picture
The reason can be explained from three aspects:
- Safety
- Comprehensive training data
- Long Tail Scenario
First of all, in terms of safety, the world model can simulate the future and give AI the ability to realize its own decisions, which is critical to the safety of autonomous driving.
Secondly, training data is also very important for autonomous driving. The data generated is more secure, cost-effective, and infinitely scalable
Generative AI can solve one of the long-tail scenario challenges facing autonomous driving. It can handle more edge scenarios, such as encountering pedestrians crossing the road in foggy weather. This will further improve the capabilities of autonomous driving
Who is Wayve?
GAIA-1 was developed by British self-driving startup Wayve
Wayve was founded in 2017. Investors include Microsoft and others, and its valuation has reached unicorn.
The founders are Alex Kendall and Amar Shah, both of whom have PhDs in machine learning from the University of Cambridge
 Picture
Picture
On the technical route, like Tesla, Wayve advocates the use of purely visual solutions using cameras, abandoning high-precision maps very early and firmly following the "instant perception" route.
Not long ago, another large model LINGO-1 released by the team also attracted widespread attention
This autonomous driving model can generate commentary in real time during driving, thus further improving the model's accuracy. Explainability
In March this year, Bill Gates also took a test drive in Wayve’s self-driving car.
 Picture
Picture
Paper address: https://www.php.cn/link/1f8c4b6a0115a4617e285b4494126fbf
Reference link:
[1]https://www.php.cn/link/85dca1d270f7f9aef00c9d372f114482[2]https://www.php.cn/link/a4c22565dfafb162a17a7c357ca9e0be
The above is the detailed content of LeCun deeply disappointed with self-driving unicorn fraud. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Written previously, today we discuss how deep learning technology can improve the performance of vision-based SLAM (simultaneous localization and mapping) in complex environments. By combining deep feature extraction and depth matching methods, here we introduce a versatile hybrid visual SLAM system designed to improve adaptation in challenging scenarios such as low-light conditions, dynamic lighting, weakly textured areas, and severe jitter. sex. Our system supports multiple modes, including extended monocular, stereo, monocular-inertial, and stereo-inertial configurations. In addition, it also analyzes how to combine visual SLAM with deep learning methods to inspire other research. Through extensive experiments on public datasets and self-sampled data, we demonstrate the superiority of SL-SLAM in terms of positioning accuracy and tracking robustness.
 Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
In the past month, due to some well-known reasons, I have had very intensive exchanges with various teachers and classmates in the industry. An inevitable topic in the exchange is naturally end-to-end and the popular Tesla FSDV12. I would like to take this opportunity to sort out some of my thoughts and opinions at this moment for your reference and discussion. How to define an end-to-end autonomous driving system, and what problems should be expected to be solved end-to-end? According to the most traditional definition, an end-to-end system refers to a system that inputs raw information from sensors and directly outputs variables of concern to the task. For example, in image recognition, CNN can be called end-to-end compared to the traditional feature extractor + classifier method. In autonomous driving tasks, input data from various sensors (camera/LiDAR
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
 Tesla finally takes action! Will self-driving taxis be unveiled soon? !
Apr 08, 2024 pm 05:49 PM
Tesla finally takes action! Will self-driving taxis be unveiled soon? !
Apr 08, 2024 pm 05:49 PM
According to news on April 8, Tesla CEO Elon Musk recently revealed that Tesla is committed to developing self-driving car technology. The highly anticipated unmanned self-driving taxi Robotaxi will be launched on August 8. Official debut. The data editor learned that Musk's statement on Previously, Reuters reported that Tesla’s plan to drive cars would focus on the production of Robotaxi. However, Musk refuted this, accusing Reuters of having canceled plans to develop low-cost cars and once again publishing false reports, while making it clear that low-cost cars Model 2 and Robotax
 Tesla Dojo supercomputing debut, Musk: The computing power of AI training by the end of the year will be approximately equal to 8,000 NVIDIA H100 GPUs
Jul 24, 2024 am 10:38 AM
Tesla Dojo supercomputing debut, Musk: The computing power of AI training by the end of the year will be approximately equal to 8,000 NVIDIA H100 GPUs
Jul 24, 2024 am 10:38 AM
According to news from this website on July 24, Tesla CEO Elon Musk (Elon Musk) stated in today’s earnings conference call that the company is about to complete the largest artificial intelligence training cluster to date, which will be equipped with 2 Thousands of NVIDIA H100 GPUs. Musk also told investors on the company's earnings call that Tesla would work on developing its Dojo supercomputer because GPUs from Nvidia are expensive. This site translated part of Musk's speech as follows: The road to competing with NVIDIA through Dojo is difficult, but I think we have no choice. We are now over-reliant on NVIDIA. From NVIDIA's perspective, they will inevitably increase the price of GPUs to a level that the market can bear, but
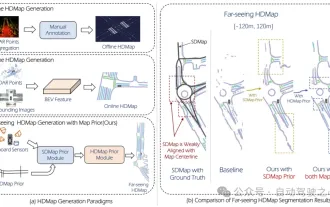 Mass production killer! P-Mapnet: Using the low-precision map SDMap prior, the mapping performance is violently improved by nearly 20 points!
Mar 28, 2024 pm 02:36 PM
Mass production killer! P-Mapnet: Using the low-precision map SDMap prior, the mapping performance is violently improved by nearly 20 points!
Mar 28, 2024 pm 02:36 PM
As written above, one of the algorithms used by current autonomous driving systems to get rid of dependence on high-precision maps is to take advantage of the fact that the perception performance in long-distance ranges is still poor. To this end, we propose P-MapNet, where the “P” focuses on fusing map priors to improve model performance. Specifically, we exploit the prior information in SDMap and HDMap: on the one hand, we extract weakly aligned SDMap data from OpenStreetMap and encode it into independent terms to support the input. There is a problem of weak alignment between the strictly modified input and the actual HD+Map. Our structure based on the Cross-attention mechanism can adaptively focus on the SDMap skeleton and bring significant performance improvements;
