
 Technology peripherals
AI
When submitting your paper to Nature, ask about GPT-4 first! Stanford actually tested 5,000 articles, and half of the opinions were the same as those of human reviewers
Technology peripherals
AI
When submitting your paper to Nature, ask about GPT-4 first! Stanford actually tested 5,000 articles, and half of the opinions were the same as those of human reviewers
When submitting your paper to Nature, ask about GPT-4 first! Stanford actually tested 5,000 articles, and half of the opinions were the same as those of human reviewers

Is
GPT-4 capable of doing paper review?
Researchers from Stanford and other universities really tested it.
They threw thousands of articles from Nature, ICLR and other top conferences to GPT-4, let it generate review comments (including modification suggestions and so on) , and then combined them with the opinions given by humans Compare.
After investigation, we found that:
More than 50% of the opinions proposed by GPT-4 are consistent with at least one human reviewer;
And more than 82.4% of the authors found the opinions provided by GPT-4 very helpful
What enlightenments can this research bring us? ?
The conclusion is:
There is still no substitute for high-quality human feedback; but GPT-4 can help authors improve first drafts before formal peer review.

automatic pipeline.
It can analyze the entire paper in PDF format, extract titles, abstracts, figures, table titles and other content to create prompts and then let GPT-4 provide review comments. Among them, the opinions are the same as the standards of each top conference, and include four parts: The importance and novelty of the research, as well as the reasons for possible acceptance or rejection and suggestions for improvement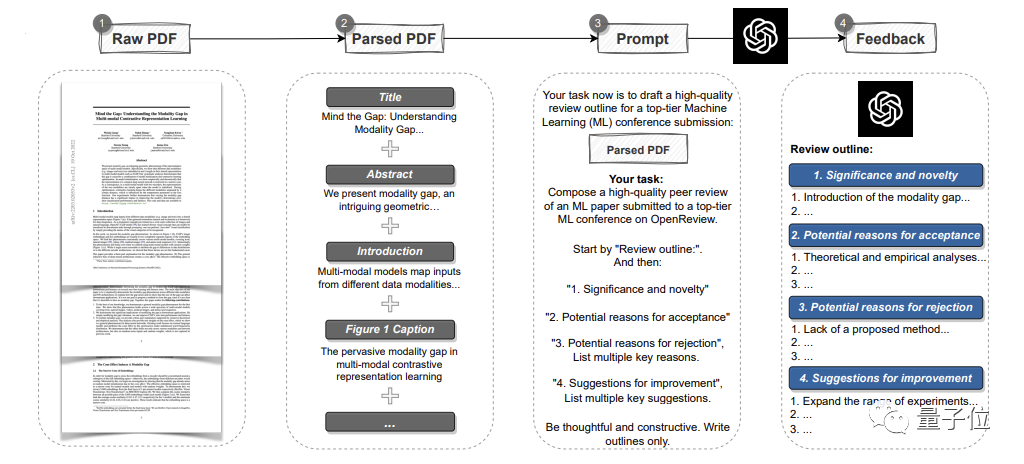
two aspects.
First comes the quantitative experiment:
Read existing papers, generate feedback, and conduct systematic comparisons with real human opinions to identify overlaps PartHere, the team selected 3096 articles from the main issue of Nature and major sub-journals, and 1709 articles from the ICLR Machine Learning Conference(including last year and this year), totaling 4805 articles.
Among them, Nature papers involved a total of 8,745 human review comments; ICLR meetings involved 6,506 comments.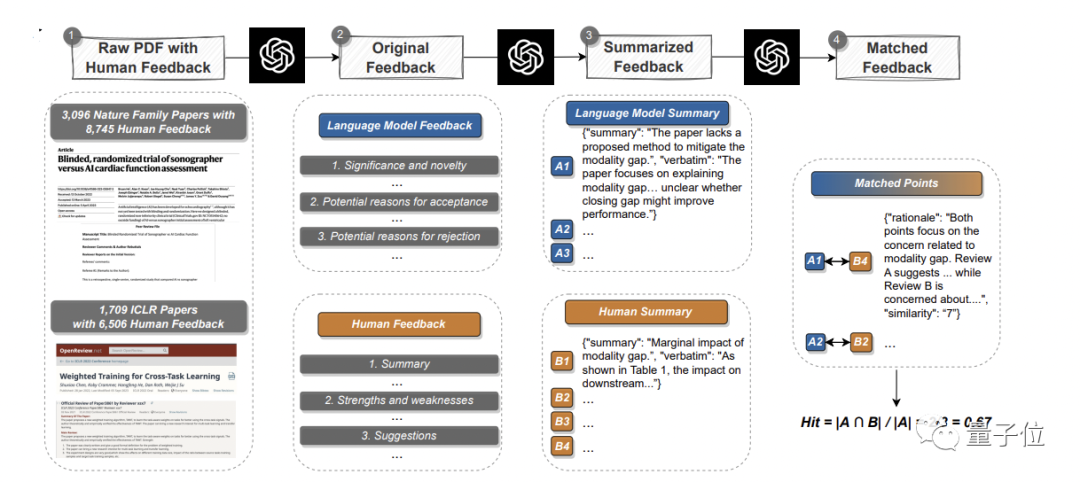
1. GPT-4 opinions significantly overlap with the real opinions of human reviewers
Overall, in the Nature paper, GPT-4 has 57.55% opinions consistent with at least one human reviewer; in ICLR, this number is as high as 77.18%.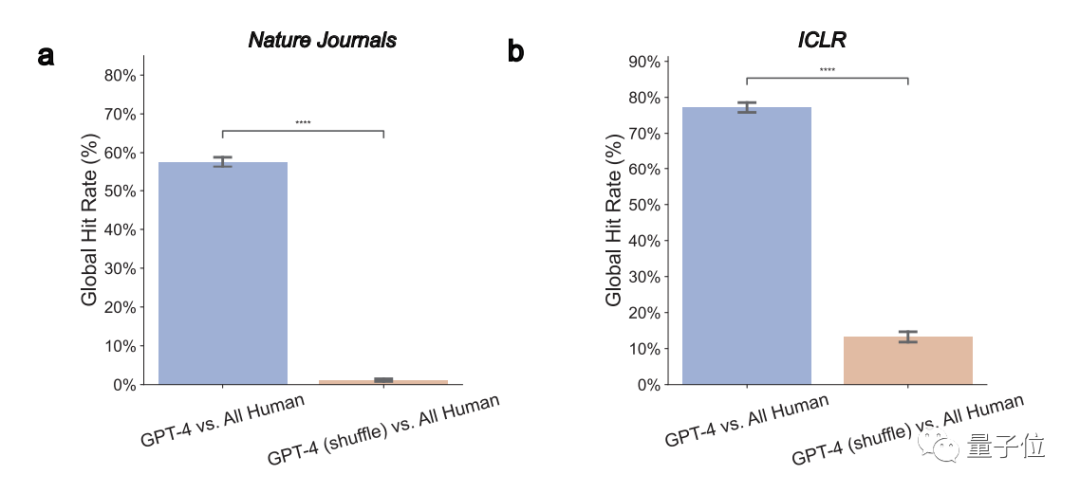
(oral, spotlight, or directly rejected)found that:
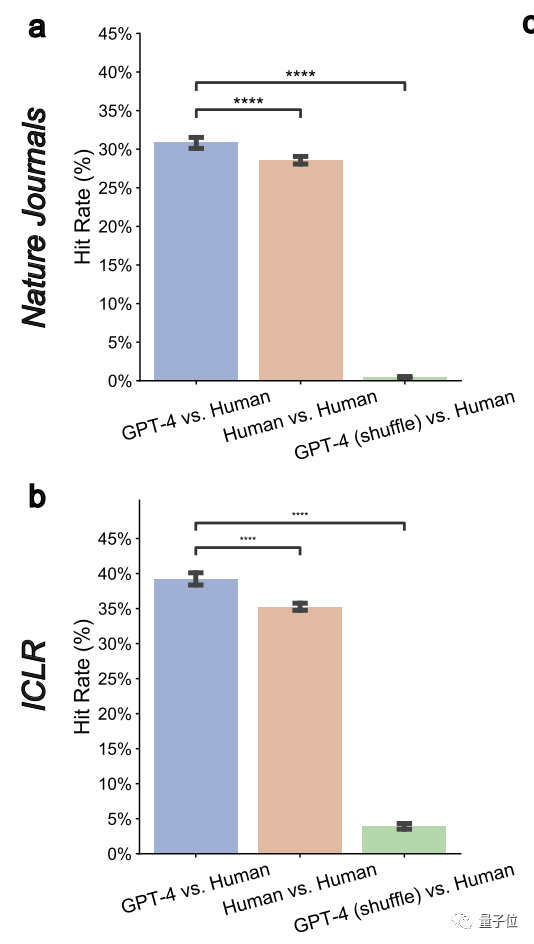
For weaker papers, the overlap rate between GPT-4 and human reviewers is expected to increase. From the current more than 30%, it can be increased to close to 50%This shows that GPT-4 has a high discriminating ability and can identify papers with poor qualityThe author also said that , those papers that require more substantial modifications before they can be accepted are in luck. You can try the modification opinions given by GPT-4 before officially submitting them.2. GPT-4 can provide non-universal feedback
The so-called non-universal feedback means that GPT-4 will not give a universal feedback that is applicable to multiple papers. review comments. Here, the authors measured a "pairwise overlap rate" metric and found that it was significantly reduced to 0.43% and 3.91% on both Nature and ICLR. This shows that GPT-4 has a specific goal3, and can reach agreement with human opinions on major and universal issues
Generally speaking, those comments that appear earliest and are mentioned by multiple reviewers often represent important and common problems
Here, the team also found that LLM is more likely to identify multiple Common problems or defects unanimously recognized by the reviewers
The overall performance of GPT-4 is acceptable
4. The opinions given by GPT-4 emphasize some aspects that are different from humans
The study found that GPT-4 was 7.27 times more likely than humans to comment on the meaning of the research itself, and 10.69 times more likely to comment on the novelty of the research.
Both GPT-4 and humans often recommend additional experiments, but humans focus more on ablation experiments, and GPT-4 recommends trying them on more data sets.
The authors stated that these findings indicate that GPT-4 and human reviewers place different emphasis on various aspects, and that cooperation between the two may bring potential advantages.
Beyond quantitative experiments is user research.
A total of 308 researchers in the fields of AI and computational biology from different institutions participated in this study. They uploaded their papers to GPT-4 for review
The research team collected their opinions on Real feedback from GPT-4 reviewers.
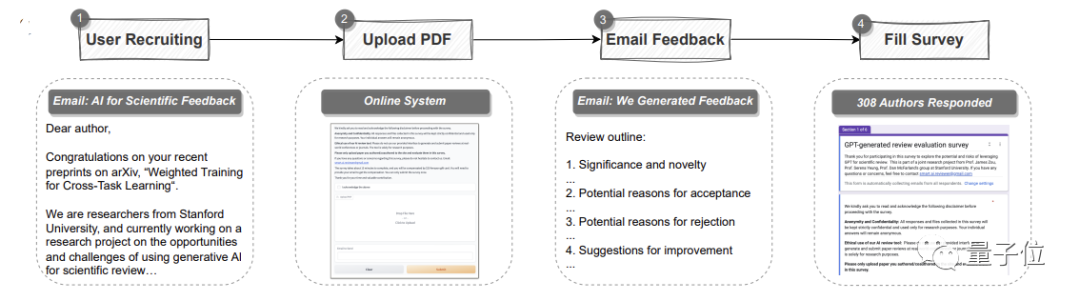
Overall, More than half (57.4%) of participants found the feedback generated by GPT-4 helpful , including giving some points that humans can’t think of.
and 82.4% of those surveyed found it more beneficial than at least some human reviewer feedback.
In addition, more than half of the people (50.5%) expressed their willingness to further use large models such as GPT-4 to improve the paper.
One of them said that it only takes 5 minutes for GPT-4 to give the results. This feedback is really fast and is very helpful for researchers to improve their papers.
Of course, the author emphasizes:
The capabilities of GPT-4 also have some limitations
The most obvious one is that it focuses more on the "overall layout", Missing In-depth advice on specific technology areas (e.g. model architecture).
Therefore, as the author’s final conclusion states:
High-quality feedback from human reviewers is very important before formal review, but we can test the waters first to make up for the experiment and construction details may be missed
Of course, they also remind:
In the formal review, the reviewer should still participate independently and not rely on any LLM.
One author is all Chinese
This studyThere are three authors, all of whom are Chinese, and all come from the School of Computer Science at Stanford University.

They are:
- Liang Weixin, a doctoral student at the school and also the Stanford AI Laboratory(SAIL)member. He holds a master's degree in electrical engineering from Stanford University and a bachelor's degree in computer science from Zhejiang University.
- Yuhui Zhang, also a doctoral student, researches on multi-modal AI systems. Graduated from Tsinghua University with a bachelor's degree and from Stanford with a master's degree.
- Cao Hancheng is a fifth-year doctoral candidate at the school, majoring in management science and engineering. He has also joined the NLP and HCI groups at Stanford University. Previously graduated from the Department of Electronic Engineering of Tsinghua University with a bachelor's degree.
Paper link: https://arxiv.org/abs/2310.01783
The above is the detailed content of When submitting your paper to Nature, ask about GPT-4 first! Stanford actually tested 5,000 articles, and half of the opinions were the same as those of human reviewers. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1382
1382
 52
52

 Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
The CentOS shutdown command is shutdown, and the syntax is shutdown [Options] Time [Information]. Options include: -h Stop the system immediately; -P Turn off the power after shutdown; -r restart; -t Waiting time. Times can be specified as immediate (now), minutes ( minutes), or a specific time (hh:mm). Added information can be displayed in system messages.
 What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
Backup and Recovery Policy of GitLab under CentOS System In order to ensure data security and recoverability, GitLab on CentOS provides a variety of backup methods. This article will introduce several common backup methods, configuration parameters and recovery processes in detail to help you establish a complete GitLab backup and recovery strategy. 1. Manual backup Use the gitlab-rakegitlab:backup:create command to execute manual backup. This command backs up key information such as GitLab repository, database, users, user groups, keys, and permissions. The default backup file is stored in the /var/opt/gitlab/backups directory. You can modify /etc/gitlab
 How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
Complete Guide to Checking HDFS Configuration in CentOS Systems This article will guide you how to effectively check the configuration and running status of HDFS on CentOS systems. The following steps will help you fully understand the setup and operation of HDFS. Verify Hadoop environment variable: First, make sure the Hadoop environment variable is set correctly. In the terminal, execute the following command to verify that Hadoop is installed and configured correctly: hadoopversion Check HDFS configuration file: The core configuration file of HDFS is located in the /etc/hadoop/conf/ directory, where core-site.xml and hdfs-site.xml are crucial. use
 How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
Enable PyTorch GPU acceleration on CentOS system requires the installation of CUDA, cuDNN and GPU versions of PyTorch. The following steps will guide you through the process: CUDA and cuDNN installation determine CUDA version compatibility: Use the nvidia-smi command to view the CUDA version supported by your NVIDIA graphics card. For example, your MX450 graphics card may support CUDA11.1 or higher. Download and install CUDAToolkit: Visit the official website of NVIDIACUDAToolkit and download and install the corresponding version according to the highest CUDA version supported by your graphics card. Install cuDNN library:
 Centos install mysql
Apr 14, 2025 pm 08:09 PM
Centos install mysql
Apr 14, 2025 pm 08:09 PM
Installing MySQL on CentOS involves the following steps: Adding the appropriate MySQL yum source. Execute the yum install mysql-server command to install the MySQL server. Use the mysql_secure_installation command to make security settings, such as setting the root user password. Customize the MySQL configuration file as needed. Tune MySQL parameters and optimize databases for performance.
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 Centos8 restarts ssh
Apr 14, 2025 pm 09:00 PM
Centos8 restarts ssh
Apr 14, 2025 pm 09:00 PM
The command to restart the SSH service is: systemctl restart sshd. Detailed steps: 1. Access the terminal and connect to the server; 2. Enter the command: systemctl restart sshd; 3. Verify the service status: systemctl status sshd.
 How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
A complete guide to viewing GitLab logs under CentOS system This article will guide you how to view various GitLab logs in CentOS system, including main logs, exception logs, and other related logs. Please note that the log file path may vary depending on the GitLab version and installation method. If the following path does not exist, please check the GitLab installation directory and configuration files. 1. View the main GitLab log Use the following command to view the main log file of the GitLabRails application: Command: sudocat/var/log/gitlab/gitlab-rails/production.log This command will display product
