
 Technology peripherals
AI
A surprising approach to temporal redundancy: a new way to reduce the computational cost of visual Transformers
Technology peripherals
AI
A surprising approach to temporal redundancy: a new way to reduce the computational cost of visual Transformers
A surprising approach to temporal redundancy: a new way to reduce the computational cost of visual Transformers

Transformer was originally designed for natural language processing tasks, but has now been widely used in vision tasks. Vision Transformer has demonstrated excellent accuracy in multiple visual recognition tasks and achieved state-of-the-art performance in tasks such as image classification, video classification, and target detection
Visual A major disadvantage of Transformer is its high computational cost. Typical convolutional networks (CNN) require tens of GFlops per image, while visual Transformers often require an order of magnitude more, reaching hundreds of GFlops per image. When processing video, this problem is even more severe due to the huge amount of data. The high computational cost makes it difficult for visual Transformers to be deployed on devices with limited resources or strict latency requirements, which limits the application scenarios of this technology, otherwise we would already have some exciting applications.
In a recent paper, Matthew Dutson, Yin Li, and Mohit Gupta, three researchers at the University of Wisconsin-Madison, first proposed that temporal redundancy can be used between subsequent inputs. Reduce the cost of visual Transformer in video applications. They also released the model code, which includes the PyTorch module used to build the Eventful Transformer.

- ##Paper address: https://arxiv.org/pdf/2308.13494.pdf
- Project address: http://wisionlab.com/project/eventful-transformers
Time redundancy: First Suppose there is a visual Transformer that can process a video sequence frame by frame or video clip by video clip. This Transformer may be a simple frame-by-frame processing model (such as an object detector) or an intermediate step of a spatiotemporal model (such as the first step of ViViT's decomposed model). Unlike the language processing Transformer, where one input is a complete sequence, the researchers here provide multiple different inputs (frames or video clips) to the Transformer over time.
Natural videos contain significant temporal redundancy, i.e. the differences between subsequent frames are small. Nonetheless, deep networks, including Transformers, typically compute each frame “from scratch.” This method discards potentially relevant information obtained through previous reasoning, which is extremely wasteful. Therefore, these three researchers imagined: Can the intermediate calculation results of previous calculation steps be reused to improve the efficiency of processing redundant sequences?
Adaptive inference: For visual Transformers, and deep networks in general, the cost of inference is often dictated by the architecture. However, in real applications, available resources may change over time, for example due to competing processes or power changes. As a result, there may be a need to modify the model calculation cost at runtime. One of the main design goals set by the researchers in this new effort was adaptability—their approach allowed for real-time control over computational costs. Figure 1 below (bottom) gives an example of modifying the computational budget during video processing.
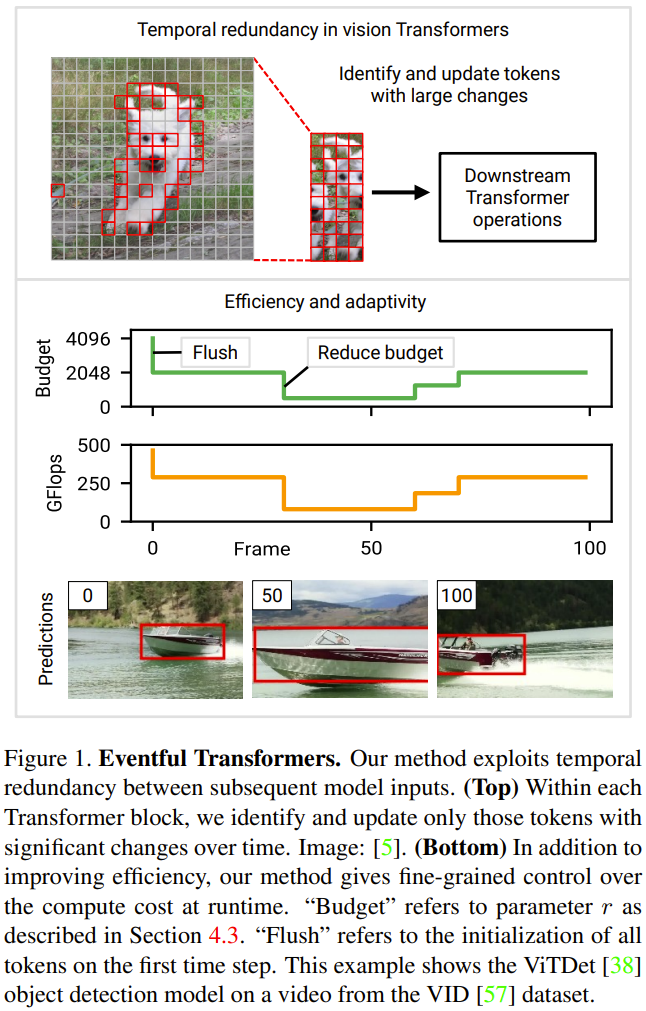
Event-based Transformer: This article proposes an event-based Transformer that can utilize the temporal redundancy between inputs to achieve efficient and adaptive reasoning. The term eventization is inspired by event cameras, sensors that discretely record images as the scene changes. The event-based Transformer tracks token-level changes over time and selectively updates the token representation and self-attention map at each time step. The event-based Transformer module contains a gating module to control the number of update tokens
This method is suitable for existing models (usually without retraining), and is suitable for for many video processing tasks. The researchers also conducted experiments to demonstrate that the Eventful Transformer can be used on the best existing models while greatly reducing computational costs and maintaining the original accuracy
Eventful Transformer
Rewritten content: The goal of this research is to accelerate the visual Transformer for video recognition. In this scenario, the visual Transformer needs to repeatedly process video frames or video clips. Specific tasks include video target detection and video action recognition. The key idea proposed is to exploit temporal redundancy, i.e., reuse calculation results from previous time steps. The following will describe in detail how to modify the Transformer module to have the ability to sense time redundancy
Token Gating: Detecting Redundancy
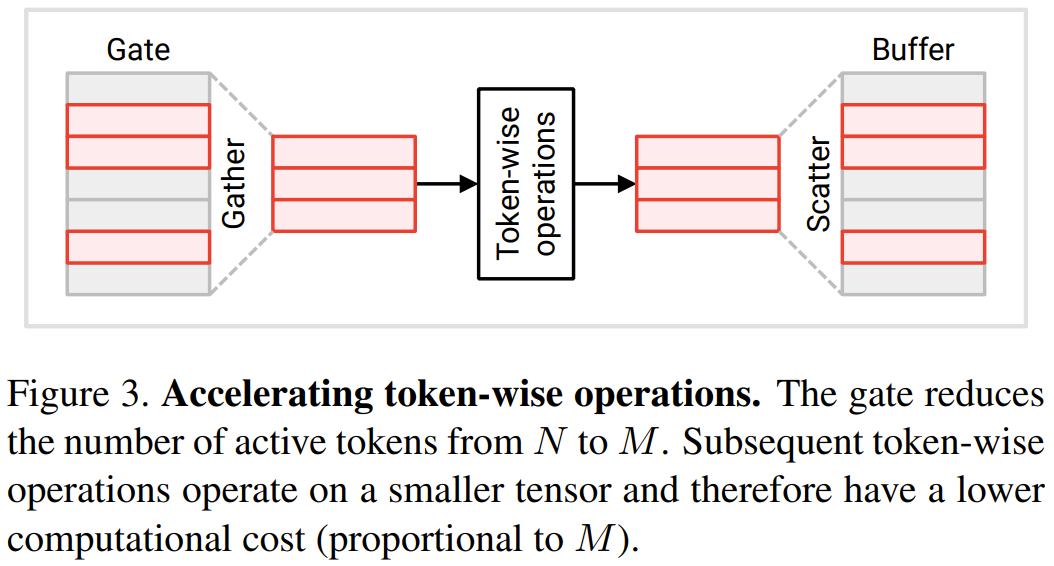
This section will introduce two new modules proposed by researchers: token gate and token buffer. These modules enable the model to identify and update tokens that have significantly changed since the last update
Gate module: This gate selects a portion M from the input token N and sends it to the downstream layer to perform calculations . It maintains a reference token set in its memory, denoted as u. This reference vector contains the value of each token at the time of its most recent update. At each time step, each token is compared with its corresponding reference value, and the token that is significantly different from the reference value is updated.
Now mark the current input of this gate as c. At each time step, follow the following process to update the gate's status and determine its output (see Figure 2 below):
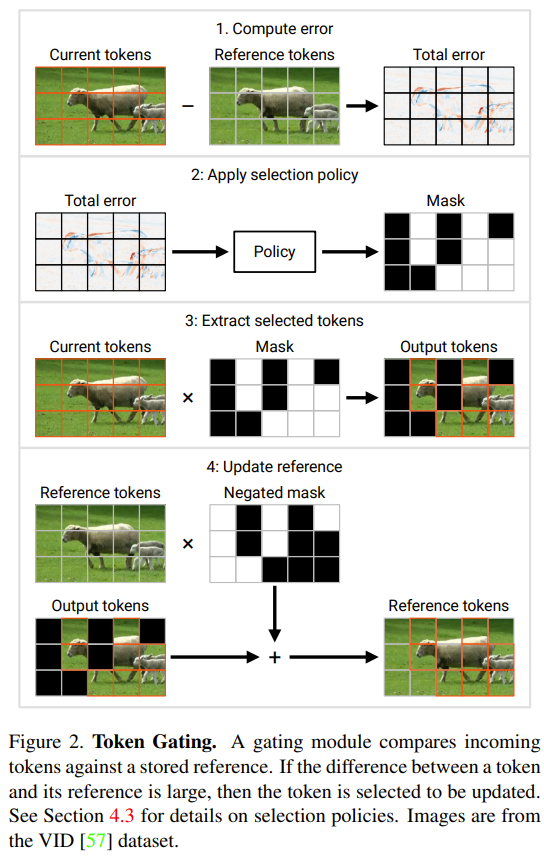
1. Calculate the total error e = u − c.
2. Use a selection strategy for error e. The selection strategy returns a binary mask m (equivalent to a token index list), indicating which M tokens should be updated.
3. Extract the token selected by the above strategy. This is described in Figure 2 as the product c × m; in practice it is achieved by performing a "gather" operation along the first axis of c. The collected tokens are recorded here as 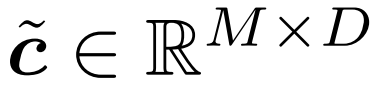 , which is the output of the gate.
, which is the output of the gate.
4. Update the reference token to the selected token. Figure 2 describes this process as 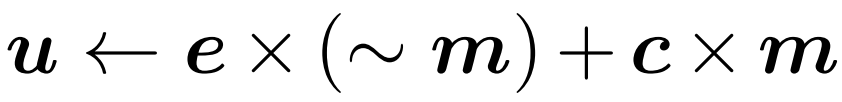 ; the operation used in practice is "scatter". In the first time step, the gate updates all tokens (initializing u ← c and returning c˜ = c).
; the operation used in practice is "scatter". In the first time step, the gate updates all tokens (initializing u ← c and returning c˜ = c).
Buffer module: The buffer module maintains a state tensor 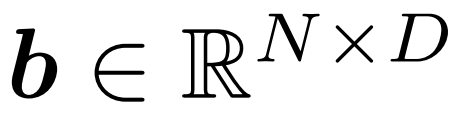 , which tracks each input token
, which tracks each input token
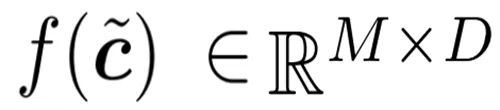 , the buffer disperses the tokens from f (c˜) to their corresponding positions in b. It then returns the updated b as its output, see Figure 3 below.
, the buffer disperses the tokens from f (c˜) to their corresponding positions in b. It then returns the updated b as its output, see Figure 3 below.
#The researchers paired each gate with the buffer behind it. The following is a simple usage pattern: the output of the gate
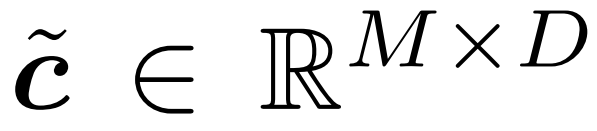 is passed to a series of operations f (c˜) for each token; then the resulting tensor
is passed to a series of operations f (c˜) for each token; then the resulting tensor 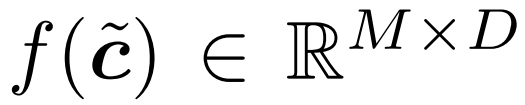 Passed to a buffer, which will restore the full shape.
Passed to a buffer, which will restore the full shape.
Reconstruct the redundant-aware Transformer
In order to take advantage of the above time redundancy, the researcher proposed a A modification scheme to the Transformer module. Figure 4 below shows the design of the Eventful Transformer module. This method can speed up operations on individual tokens (such as MLP) as well as query-key-value and attention-value multiplication.
In the Transformer module that operates on each token, many operations are performed on each token, which means they do not involve information exchange between tokens, including linear transformations in MLP and MSA. In order to save computational costs, the researchers stated that token-oriented operations on tokens not selected by the gate can be skipped. Due to the independence between tokens, this does not change the result of the operation on the selected token. See Figure 3.
Specifically, the researchers used a continuous sequence of a pair of gate-buffers when processing the operations of each token, including W_qkv transformation, W_p transformation and MLP. It should be noted that before skip connection, they also added a buffer to ensure that the tokens of the two addition operands can be correctly aligned
For the operation cost of each token Proportional to the number of tokens. By reducing the number from N to M, the downstream operation cost per token will be reduced by N/M times
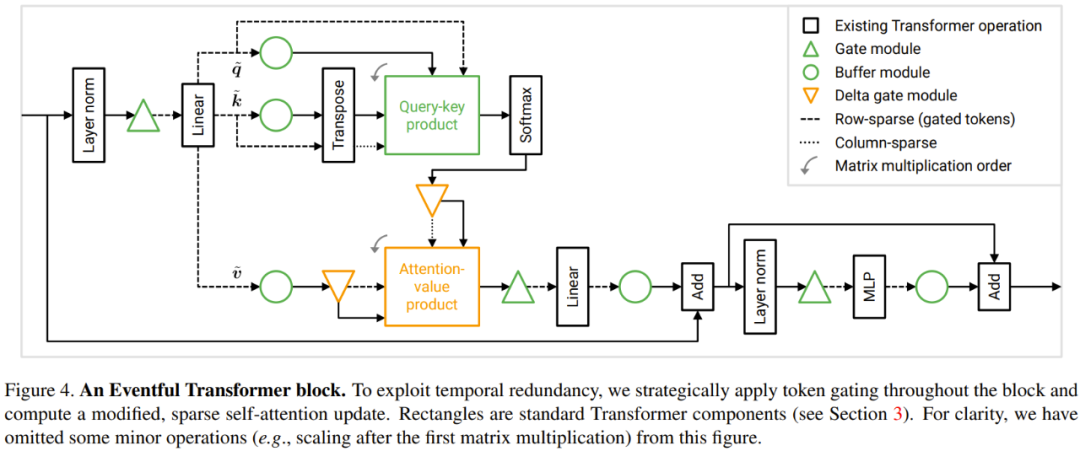
Now let's look at the query-key-value product B = q k The result of ^T
Figure 5 below shows the method of sparsely updating a part of the elements in the query-key-value product B.
The overall cost of these updates is 2NMD, compared to the cost of computing B from scratch, which is N^2D. Note that the cost of the new method is proportional to M, the number of tokens chosen. When M
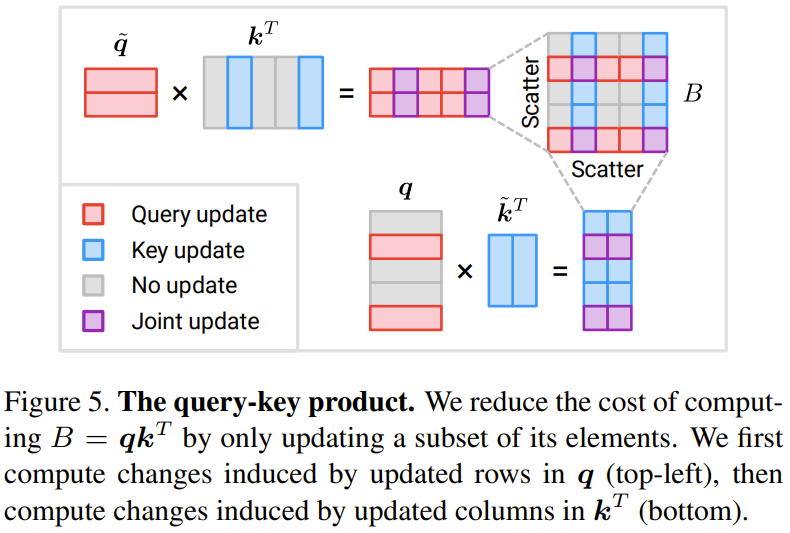
Attention - product of values: The researcher proposed this An update strategy based on delta Δ is proposed.
Figure 6 shows a newly proposed method to efficiently calculate three incremental terms
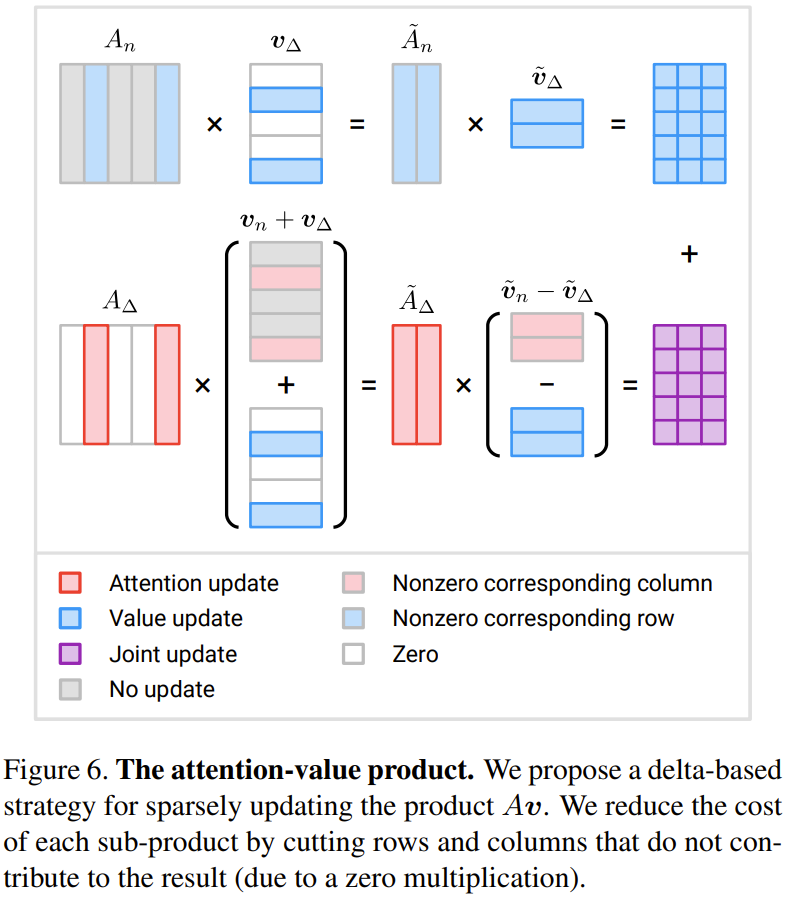
When M is less than half of N, the amount of calculation can be reduced
token selection strategy
One of Eventful Transformer The most important design is its token selection strategy. Given a gate error tensor e, the goal of such a policy is to generate a mask m indicating the tokens that should be updated. Specific strategies include:
Top-r strategy: This strategy selects r tokens with the largest error e (the L2 norm is used here).
Threshold strategy: This strategy will select all tokens whose norm of error e exceeds the threshold h
Rewritten content: Others Strategy: Better accuracy-cost trade-offs can be achieved by adopting more sophisticated token selection strategies, such as using a lightweight policy network to learn the strategy. However, training the decision-making mechanism of the policy may face difficulties because the binary mask m is usually non-differentiable. Another idea is to use the importance score as reference information for selection. However, these ideas still require further investigation
Experiments
The researchers conducted an experimental evaluation of the newly proposed method, specifically applied to video targets Detection and video action recognition tasks
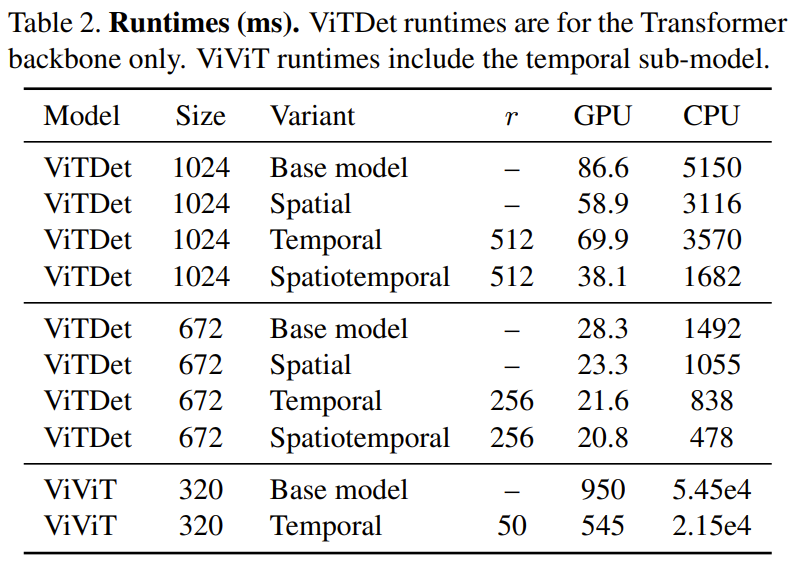
Figure 7 below shows the experimental results of video target detection. where the positive axis is the computational savings rate and the negative axis is the relative reduction in mAP50 score for the new method. It can be seen that the new method achieves significant computational savings with a small sacrifice of accuracy.
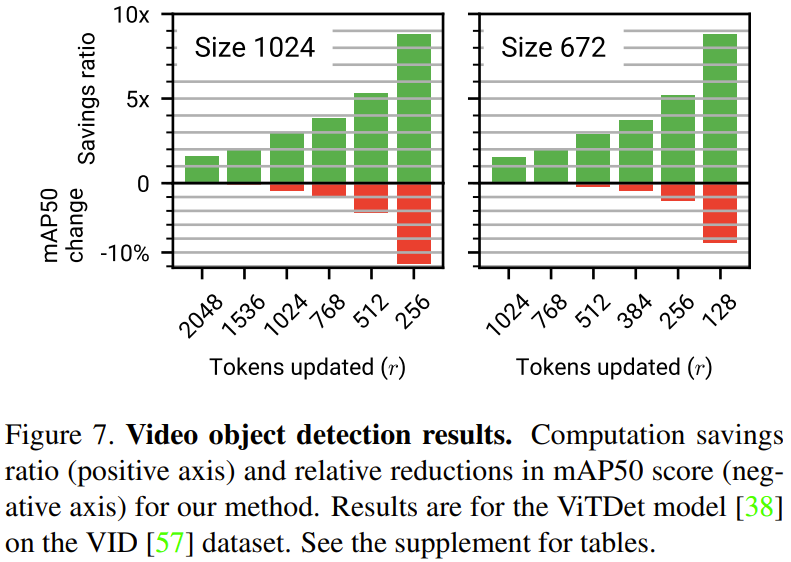
Figure 8 below shows the method comparison and ablation experimental results for the video target detection task
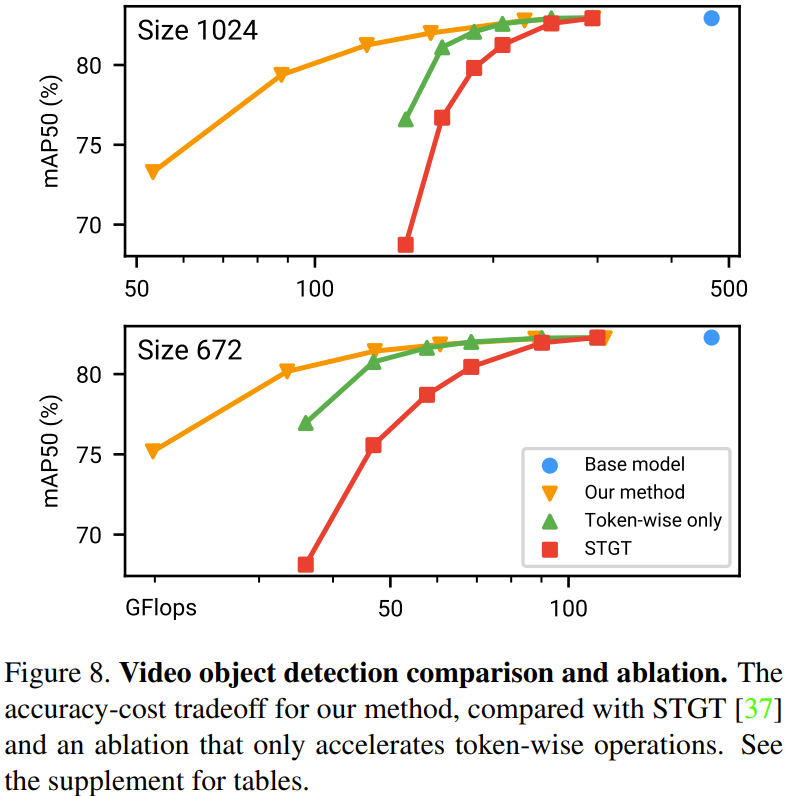
Figure 9 below shows the experimental results of video action recognition.
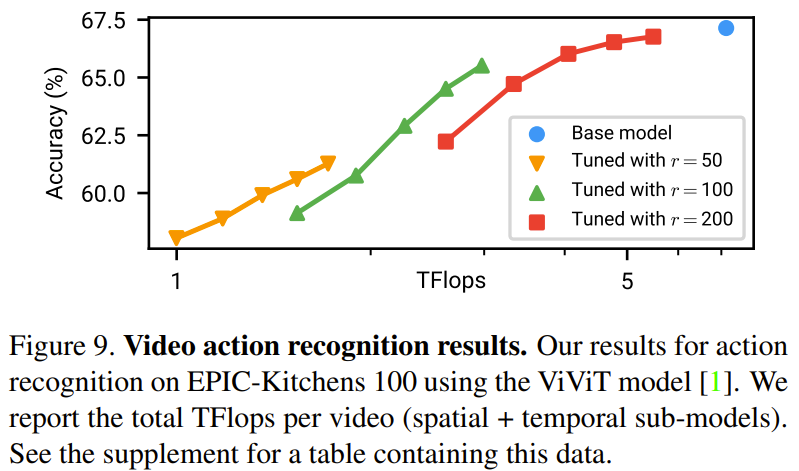
In Table 2 below, the time results (in milliseconds) are shown for running on one CPU (Xeon Silver 4214, 2.2 GHz) and one GPU (NVIDIA RTX3090). It can be observed that the temporal redundancy on the GPU brings a 1.74 times speed improvement, while the improvement on the CPU reaches 2.47 times
For more technical details and experimental results, please refer to the original paper.
The above is the detailed content of A surprising approach to temporal redundancy: a new way to reduce the computational cost of visual Transformers. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
DDREASE is a tool for recovering data from file or block devices such as hard drives, SSDs, RAM disks, CDs, DVDs and USB storage devices. It copies data from one block device to another, leaving corrupted data blocks behind and moving only good data blocks. ddreasue is a powerful recovery tool that is fully automated as it does not require any interference during recovery operations. Additionally, thanks to the ddasue map file, it can be stopped and resumed at any time. Other key features of DDREASE are as follows: It does not overwrite recovered data but fills the gaps in case of iterative recovery. However, it can be truncated if the tool is instructed to do so explicitly. Recover data from multiple files or blocks to a single
 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
 The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
Recently, the military circle has been overwhelmed by the news: US military fighter jets can now complete fully automatic air combat using AI. Yes, just recently, the US military’s AI fighter jet was made public for the first time and the mystery was unveiled. The full name of this fighter is the Variable Stability Simulator Test Aircraft (VISTA). It was personally flown by the Secretary of the US Air Force to simulate a one-on-one air battle. On May 2, U.S. Air Force Secretary Frank Kendall took off in an X-62AVISTA at Edwards Air Force Base. Note that during the one-hour flight, all flight actions were completed autonomously by AI! Kendall said - "For the past few decades, we have been thinking about the unlimited potential of autonomous air-to-air combat, but it has always seemed out of reach." However now,
