

The impact of data scarcity on model training


The impact of data scarcity on model training requires specific code examples
In the fields of machine learning and artificial intelligence, data is one of the core elements of training models. However, a problem we often face in reality is data scarcity. Data scarcity refers to the insufficient amount of training data or the lack of annotated data. In this case, it will have a certain impact on model training.
The problem of data scarcity is mainly reflected in the following aspects:
- Overfitting: When the amount of training data is insufficient, the model is prone to overfitting. Overfitting means that the model overly adapts to the training data and cannot generalize well to new data. This is because the model does not have enough data samples to learn the distribution and characteristics of the data, causing the model to produce inaccurate prediction results.
- Underfitting: Compared with overfitting, underfitting means that the model cannot fit the training data well. This is because the amount of training data is insufficient to cover the diversity of the data, resulting in the model being unable to capture the complexity of the data. Underfitted models often fail to provide accurate predictions.
How to solve the problem of data scarcity and improve the performance of the model? The following are some commonly used methods and code examples:
- Data augmentation (Data Augmentation) is a common method to increase the number of training samples by transforming or expanding existing data. Common data enhancement methods include image rotation, flipping, scaling, cropping, etc. The following is a simple image rotation code example:
from PIL import Image
def rotate_image(image, angle):
rotated_image = image.rotate(angle)
return rotated_image
image = Image.open('image.jpg')
rotated_image = rotate_image(image, 90)
rotated_image.save('rotated_image.jpg')- Transfer learning (Transfer Learning) uses already trained models to solve new problems. By using already learned features from existing models, better training can be performed on scarce data sets. The following is a code example of transfer learning:
from keras.applications import VGG16 from keras.models import Model base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3)) x = base_model.output x = GlobalAveragePooling2D()(x) x = Dense(1024, activation='relu')(x) predictions = Dense(num_classes, activation='softmax')(x) model = Model(inputs=base_model.input, outputs=predictions) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
- Domain Adaptation (Domain Adaptation) is a method of transferring knowledge from the source domain to the target domain. Better generalization capabilities can be obtained by using some domain-adaptive techniques, such as self-supervised learning, domain adversarial networks, etc. The following is a code example of domain adaptation:
import torch
import torchvision
import torch.nn as nn
source_model = torchvision.models.resnet50(pretrained=True)
target_model = torchvision.models.resnet50(pretrained=False)
for param in source_model.parameters():
param.requires_grad = False
source_features = source_model.features(x)
target_features = target_model.features(x)
class DANNClassifier(nn.Module):
def __init__(self, num_classes):
super(DANNClassifier, self).__init__()
self.fc = nn.Linear(2048, num_classes)
def forward(self, x):
x = self.fc(x)
return x
source_classifier = DANNClassifier(num_classes)
target_classifier = DANNClassifier(num_classes)
source_outputs = source_classifier(source_features)
target_outputs = target_classifier(target_features)Data scarcity has a non-negligible impact on model training. Through methods such as data augmentation, transfer learning, and domain adaptation, we can effectively solve the problem of data scarcity and improve the performance and generalization ability of the model. In practical applications, we should choose appropriate methods based on specific problems and data characteristics to obtain better results.
The above is the detailed content of The impact of data scarcity on model training. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

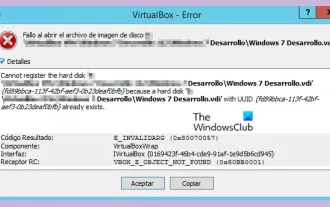 VBOX_E_OBJECT_NOT_FOUND(0x80bb0001)VirtualBox error
Mar 24, 2024 am 09:51 AM
VBOX_E_OBJECT_NOT_FOUND(0x80bb0001)VirtualBox error
Mar 24, 2024 am 09:51 AM
When trying to open a disk image in VirtualBox, you may encounter an error indicating that the hard drive cannot be registered. This usually happens when the VM disk image file you are trying to open has the same UUID as another virtual disk image file. In this case, VirtualBox displays error code VBOX_E_OBJECT_NOT_FOUND(0x80bb0001). If you encounter this error, don’t worry, there are some solutions you can try. First, you can try using VirtualBox's command line tools to change the UUID of the disk image file, which will avoid conflicts. You can run the command `VBoxManageinternal
 How effective is receiving phone calls using airplane mode?
Feb 20, 2024 am 10:07 AM
How effective is receiving phone calls using airplane mode?
Feb 20, 2024 am 10:07 AM
What happens when someone calls in airplane mode? Mobile phones have become one of the indispensable tools in people's lives. It is not only a communication tool, but also a collection of entertainment, learning, work and other functions. With the continuous upgrading and improvement of mobile phone functions, people are becoming more and more dependent on mobile phones. With the advent of airplane mode, people can use their phones more conveniently during flights. However, some people are worried about what impact other people's calls in airplane mode will have on the mobile phone or the user? This article will analyze and discuss from several aspects. first
 WeChat's large-scale recommendation system training practice based on PyTorch
Apr 12, 2023 pm 12:13 PM
WeChat's large-scale recommendation system training practice based on PyTorch
Apr 12, 2023 pm 12:13 PM
This article will introduce WeChat’s large-scale recommendation system training based on PyTorch. Unlike some other deep learning fields, the recommendation system still uses Tensorflow as the training framework, which is criticized by the majority of developers. Although there are some practices using PyTorch for recommendation training, the scale is small and there is no actual business verification, making it difficult to promote early adopters of business. In February 2022, the PyTorch team launched the official recommended library TorchRec. Our team began to try TorchRec in internal business in May and launched a series of cooperation with the TorchRec team. Over the course of several months of trialling, we found that TorchR
 File Inclusion Vulnerabilities in Java and Their Impact
Aug 08, 2023 am 10:30 AM
File Inclusion Vulnerabilities in Java and Their Impact
Aug 08, 2023 am 10:30 AM
Java is a commonly used programming language used to develop various applications. However, just like other programming languages, Java has security vulnerabilities and risks. One of the common vulnerabilities is the file inclusion vulnerability (FileInclusionVulnerability). This article will explore the principle, impact and how to prevent this vulnerability. File inclusion vulnerabilities refer to the dynamic introduction or inclusion of other files in the program, but the introduced files are not fully verified and protected, thus
 How to turn off the comment function on TikTok? What happens after turning off the comment function on TikTok?
Mar 23, 2024 pm 06:20 PM
How to turn off the comment function on TikTok? What happens after turning off the comment function on TikTok?
Mar 23, 2024 pm 06:20 PM
On the Douyin platform, users can not only share their life moments, but also interact with other users. Sometimes the comment function may cause some unpleasant experiences, such as online violence, malicious comments, etc. So, how to turn off the comment function of TikTok? 1. How to turn off the comment function of Douyin? 1. Log in to Douyin APP and enter your personal homepage. 2. Click "I" in the lower right corner to enter the settings menu. 3. In the settings menu, find "Privacy Settings". 4. Click "Privacy Settings" to enter the privacy settings interface. 5. In the privacy settings interface, find "Comment Settings". 6. Click "Comment Settings" to enter the comment setting interface. 7. In the comment settings interface, find the "Close Comments" option. 8. Click the "Close Comments" option to confirm closing comments.
 The impact of data scarcity on model training
Oct 08, 2023 pm 06:17 PM
The impact of data scarcity on model training
Oct 08, 2023 pm 06:17 PM
The impact of data scarcity on model training requires specific code examples. In the fields of machine learning and artificial intelligence, data is one of the core elements for training models. However, a problem we often face in reality is data scarcity. Data scarcity refers to the insufficient amount of training data or the lack of annotated data. In this case, it will have a certain impact on model training. The problem of data scarcity is mainly reflected in the following aspects: Overfitting: When the amount of training data is insufficient, the model is prone to overfitting. Overfitting refers to the model over-adapting to the training data.
 What problems will bad sectors on the hard drive cause?
Feb 18, 2024 am 10:07 AM
What problems will bad sectors on the hard drive cause?
Feb 18, 2024 am 10:07 AM
Bad sectors on a hard disk refer to a physical failure of the hard disk, that is, the storage unit on the hard disk cannot read or write data normally. The impact of bad sectors on the hard drive is very significant, and it may lead to data loss, system crash, and reduced hard drive performance. This article will introduce in detail the impact of hard drive bad sectors and related solutions. First, bad sectors on the hard drive may lead to data loss. When a sector in a hard disk has bad sectors, the data on that sector cannot be read, causing the file to become corrupted or inaccessible. This situation is especially serious if important files are stored in the sector where the bad sectors are located.
 How to use Python to train models on images
Aug 26, 2023 pm 10:42 PM
How to use Python to train models on images
Aug 26, 2023 pm 10:42 PM
Overview of how to use Python to train models on images: In the field of computer vision, using deep learning models to classify images, target detection and other tasks has become a common method. As a widely used programming language, Python provides a wealth of libraries and tools, making it relatively easy to train models on images. This article will introduce how to use Python and its related libraries to train models on images, and provide corresponding code examples. Environment preparation: Before starting, you need to ensure that you have installed
